文章目录
痛点
不太熟悉互联网企业的人士,往往将其想象成超现代风格的内部流程,一切都自动化,达到科幻电影的程度;但是真实在行业中摸爬滚打过几年的人士,会体会到流程自动化是一个过程,现实中由于工期紧张、历史习惯、实施成本等因素,流程中保留了大量手工操作。
以Shopee的DoD(Dev on duty)值班流程为例子,系统微服务的设计风格,每个开发组负责维护其中一个模块,可能用户感知到的一个页面,可能对应很多后台模块(背后是多个开发组)。作为一个跨国公司,Shopee的业务分散在很多个国家,不是每个国家的运营人员对这种分工都非常熟悉,往往first call会搞错,虽然我们规定了first call的组负责转发支持请求,但是这样往往耽误时间,特别是深夜值班,得把人从睡梦中叫醒后发现又不是该人负责;又或是大促期间的值班,这样的转发也耗费时间,耽误一分钟就损失XXXXXX元钱。
项目缘起
为了解决这个问题,之前我们靠人工的办法,编写了一个长达200页的ppt,详细介绍了DoD的流程和分工。但是问题是,这套ppt要讲解也是要成本的,而且效果不好,特别是还要涉及跨境的团队,还有翻译、培训组织等一堆的事情。
今年随着chatgpt的流行,我们开始考虑使用人工智能的方式回答一线员工发现问题的first call,减轻ppt培训成本,减少失误率,且能够自动进行语言的翻译。也就是如下几种能力,最终自动找到对应的负责团队:
- 跨语言能力
- 模糊语义理解能力
- 推理能力
考虑到企业信息安全,根据Shopee的指引,这套系统必须部署在企业内部。
技术选型
要实现如上系统,考虑有两套技术方案:
fine-tuning
用白话说是在chatgpt等巨人的肩膀上,采用标准模型,加上自己数据,自己炼丹。
大模型训练结束后,参数固定,模型内部蕴含的知识也固定。想要让模型增加知识,可以通过微调改变模型参数实现。
微调是以预训练LLM为基底,预训练模型是在大量通用数据集上训练,微调则是在少量特定领域数据集上训练,通过较低的成本获取特定领域的知识。
具体微调流程为:构建微调数据集 → SFT(supervised fine tuning,有监督微调) → RLHF(reinforcement learning & human feedback)
该方案优点是模型对领域知识理解更正确,效果更好;缺点是需要开源模型,需要收集数据并进行加工,微调大模型也需要较高的显卡成本,总体来说成本较高,且微调后模型推理效果不能保证。
few shot prompt engineering
用白话说就是直接chatgpt等LLM本身,但是其缺乏企业内部知识(比如那个200页的ppt),怎么办呢?就是采用langchain等编程手段,在对话上下文中提供信息。
在openAI的gpt-2论文中,就定义LLM本质上few-shot/zero-shot learning,具备很强的泛化能力。
只需要在提示词(prompt)中清楚地阐明上下文,即使训练集中不包含相关知识,模型也能对上下文正确理解和分析。
具体流程为: 构建外部知识库 → 相关知识匹配 → few shot prompt构建 → LLM推理
该方案优点是不需要训练,拓展性强,可使用现有大模型产品,如chatgpt、new bing等;缺点是LLM对外部知识理解较差,构建知识库需要一定成本等。
两个方案各有优缺点,不过方案一更费钱,那时的Shopee,节约成本是压倒一切的纲领,所以经过技术评审,毫无悬念采用了方案二。所以如果有新人问我啥是技术选型,我看要提醒一下他/她别被这个名字给骗了,很多时候决定选型的是技术之外的因素。
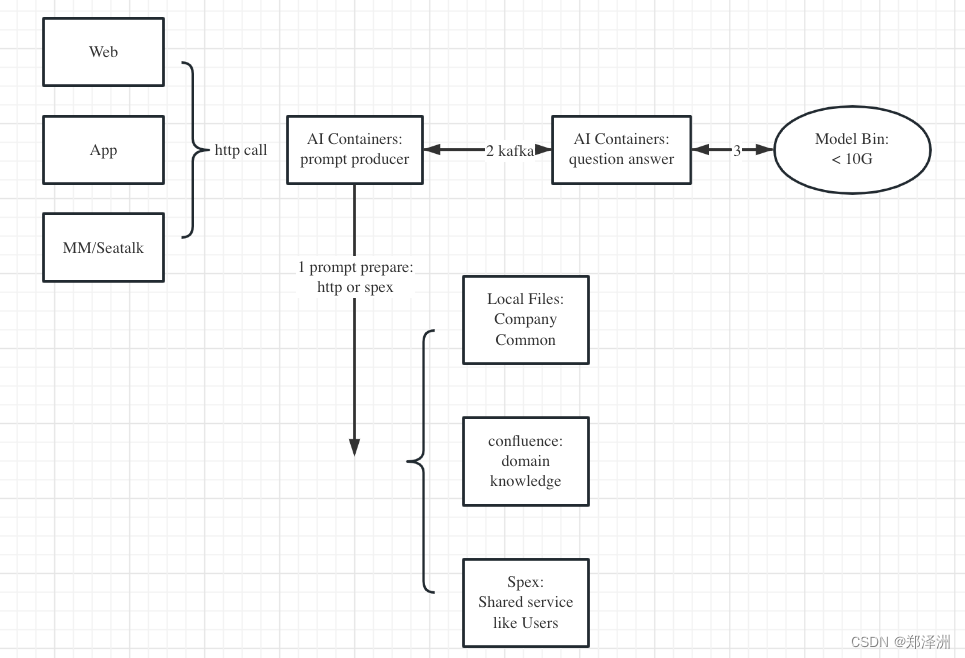
选定方案的特征描述
LLM是无状态的,这个一个模型文件大概10G不到,可以只读入container。理论上虽然消耗cpu,业务高峰期可以横向扩展container保证响应时间。
基本上是一个后端应用,采用python或者golang搭建,使用库文件的方式在本地调用大语言模型LLM,开放http接口的api给调用方使用
新建应用,代码提交到gitlab,采用CICD进行部署
模型赛马
方案二确定下来之后,到底该用哪个LLM呢,这里才到了真正技术发挥决策作用的地方,我们成立了一个小组,招募了对AI和LLM有兴趣的同事,每个人带着自己看好的LLM,分配给每个人计算资源,最后用数据说话,看哪个LLM的性能更好,消耗更少
各自分头选定模型(gpt4all, chatGLM, FLAN T-5, Alpaca),然后用数据集合测试,看看实际性能
| 姓名 | 模型 | 特点 | 资料 |
|---|---|---|---|
| zezhou | chatgpt2(后来发现不行);gpt4all offline | free, local run, No GPU required | https://gpt4all.io/index.html https://github.com/nomic-ai/gpt4all |
| jinhao | chatGLM | https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/INSTALL.md | |
| zouxuan Yap | FLAN T-5 | https://medium.com/@koki_noda/try-language-models-with-python-google-ais-flan-t5-ba72318d3be6 | |
| Yunyuan Yu | Alpaca | https://beebom.com/how-run-chatgpt-like-language-model-pc-offline/ | |
| 最后经过比较,决定采用gpt4all |
gpt4all调优
这部分会比较技术细节一些,涉及部署时的踩坑,和运行时调优。如果产品的同事要只看效果可以直接跳到最后一部分。
部署时踩坑
最早用chatgpt2的时候,发现始终安装不了,所以最终才决定用gpt4all。其原因是python版本问题
chatgpt-2是n年前的项目,所以用的tensorflow都是老版本的1.15,而我现在机器上是3.11了,只能安装最新的tensorflow结果报错
所以python环境很重要,各位实验时,可以用pyenv在自己mac机器上,安装好py2到py3的各个版本
python3.9 header缺失 – 安装下缺失的就行
如下信息最关键的是Python.h No Such file
Running setup.py install for regex … error
ERROR: Command errored out with exit status 1:
command: /data/venv-gpt-2/bin/python3 -u -c ‘import sys, setuptools, tokenize; sys.argv[0] = ‘"’"’/tmp/pip-install-yz_lezij/regex/setup.py’“'”‘; file=’“'”‘/tmp/pip-install-yz_lezij/regex/setup.py’“'”‘;f=getattr(tokenize, ‘"’“‘open’”’“‘, open)(file);code=f.read().replace(’”‘"’\r\n’“'”‘, ‘"’"’\n’“'”‘);f.close();exec(compile(code, file, ‘"’“‘exec’”’"‘))’ install --record /tmp/pip-record-inx4miu7/install-record.txt --single-version-externally-managed --compile --install-headers /data/venv-gpt-2/include/site/python3.9/regex
后来搜索stackoverflow,也可以问chatgpt,安装好缺失的部分就行
运行时参数调优
普通4核服务器上运行很慢,只能每次回答单个人问题,还要等个20秒。于是参考gpt4all官方文档,从如下方面入手调整:
- CPU核数加大,实测16核情况下,可以在5秒内出答案,基本符合了应用需求
- 限制回答长度,我们的需求简单,只要回答团队名称就可以,减少长度可以显著提升速度
- 优化程序结构,预加载
- 流式输出(提升了用户体验,但是没有缩短时间)
- prompt工程,因为我们需求单一,就是弄清楚是哪个team来解决DoD问题,所以团队资料部分可以写死代码中加载
代码分析
项目代码
项目最核心的代码脱敏后示例如下(部分变量和文件重命名了):
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import GPT4All
from langchain.chains import RetrievalQA
import time
from flask import Flask, request
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
app = Flask(__name__)
markdown_path = "./test.md"
loader = UnstructuredMarkdownLoader(markdown_path)
documents = loader.load()
print("loaded documents")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=64)
texts = text_splitter.split_documents(documents)
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
db = Chroma.from_documents(texts, embeddings, persist_directory="db")
print("embeddings")
callbacks = [StreamingStdOutCallbackHandler()]
model_path = "/data/gpt4all/ggml-gpt4all-j-v1.3-groovy.bin"
llm = GPT4All(model=model_path, n_ctx=128, backend="gptj", verbose=False, n_threads=15, callbacks=callbacks, n_predict=48)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever(search_kwargs={"k": 3}),
return_source_documents=True,
verbose=False,
)
def print_hi(question):
res = qa(question)
print("answer")
print(time.time())
print(res["result"])
return res["result"]
@app.route('/', methods=['POST'])
def echo():
data = request.get_data(as_text=True)
print(data)
res = print_hi(data)
return res
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
app.run(host='0.0
库代码
代码中使用了langchain和llama,趁项目机会,分析其核心功能代码:
| 接口名 | 功能 | 开源替代 |
|---|---|---|
| /v1/embeddings | 提取文本片段的特征 | HuggingfaceEmbedding |
| /v1/completions | 补齐文本,回答问题 | chatGLM |
为什么要有embeddings接口?物有异名,最早marketing的搜索,是精确匹配到关键字,但是自然语言是丰富多样的,比如我要找一下气质"自然淡雅"的衣服,正好衣服广告词中也有这几个字,于是能匹配,但是用户也可能会用"小清新"去搜索,就搜索不到了。所以embeddings接口是通过"名"提取出"物"
具体算法参考:
https://time.geekbang.org/column/article/644795 有了 OpenAI 的 Embedding 接口,我们就可以把一段文本的语义表示成一段向量。而向量之间是可以计算距离的,如果向量距离少于某个阈值,就认为这两个名指的是同一个物
物有异名应对方案:
- 通过维护一个同义词表,好处是实现简单,坏处是维护麻烦
- 通过调用本地的embedding库 HuggingfaceEmbedding (比起推理,embedding其实要简单点,具备本地运行的可能)
效果展示
例子1
curl -X POST -d "according to the test.md, if I can not arrange shipment, which API may I refer to?" http://localhost:5000
If you are unable to arrange shipment for an order, you can refer to the API `/api/v2/logistic/ship_order` to initiate logistics for the order. This API will allow you to arrange pickup, drop
例子2
if I want to arrange shipment, which API should I call?
To arrange shipment, you should call the api/v2/logisticsship\_order/ship\_order. Use this api to initiate logistics including arrange pickup, dropoff or shipment for non-integrated logistic channels.
Here's an example of how to call the api/v2/logisticsship\_order/ship\_order API to initiate shipment logistics:
POST /api/v2/logisticsship_order/ship_order
{
“address”: “123 Main St”,
“pickup_address”: “456 Smith Ave”,
“dropoff_address”: “789 Baker Ave”,
“pickup_time”: “11:00”,
“dropoff_time”: “14:00”,
“pickup_method”: “Standard Delivery”,
“dropoff_method”: “Express Delivery”
}
Note: This is just an example and the actual implementation may vary based on the 3PL service provider and the requirements of your shipment logistics. It is always recommended to consult with your 3PL service provider or contact their support team for specific assistance.
附录:所用的公司内部API文档例子:
#api/v2/logistics/get_shipping_parameter
Use this api to get the parameter "info_needed" from the response to check if the order has pickup or dropoff or no integrate options. This api will also return the addresses and pickup time id options for the pickup method. For dropoff, it can return branch id, sender real name etc, depending on the 3PL requirements.
#/api/v2/logistics/ship_order
Use this api to initiate logistics including arrange pickup, dropoff or shipment for non-integrated logistic channels. Should call v2.logistics.get_shipping_parameter to fetch all required param first. It's recommended to initiate logistics one hour after the orders were placed since there is one-hour window buyer can cancel any order without request to seller.
#/api/v2/logistics/create_shipping_document
Use this api to create shipping document task for each order or package and this API is only available after retrieving the tracking number.