Stability AI 刚刚发布了新版本的稳定扩散图像生成模型。这个名为SDXL的新版本比以前的版本进行了多项改进,这可能使其成为迄今为止最好的开源文本到图像生成模型。

相对于稳定扩散 2.1 的改进
尽管 SDXL 与其前身一样是潜在扩散模型 (LDM),但其创建者对模型结构进行了更改,以解决以前版本中的问题。让我们更详细地看看这些改进:
使用更大 U-Net 的两阶段图像生成
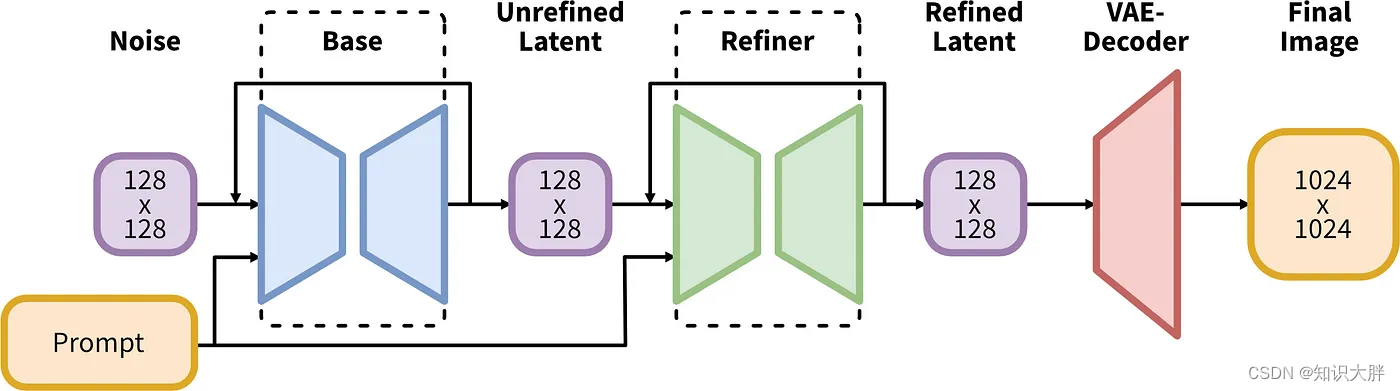
该模型有一个两步系统,可以从噪声中生成潜在特征。首先,基础 U-Net 创建一个潜在特征图,并将其传递给另一个经过训练的 U-Net,以细化和完善其输入的特征。U-Net 的大小也从 Stable Diffusion 2.1 中的 865M 参数分别增加到 SDXL 中的 3.5B 和 6.6B。
允许 U-Net 根据我们的提示调节其输出的交叉注意力层也进行了重新洗牌,以产生更好的结果。
防止裁剪和模糊的机制
之前版本的稳定扩散存在裁剪问题。由于训练数据集使用数据增强技术来增加输入的可变性,因此以前的模型意外地包含了数据中观察到的裁剪行为。为了防止这种情况发生,SDXL 接受裁剪和目标分辨率值,使我们能够控制要应用于生成图像的裁剪程度(如果有)以及特征细节级别,具体取决于我们生成的分辨率图像。