作者 | 小书童 编辑 | 江大白
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【模型部署】技术交流群
本文只做学术分享,如有侵权,联系删文

导读
CUDA是CV领域模型部署优化的必备。本文基于RTX3090,学习Tensor Core的使用方法,最后实验证明,手写的CUDA矩阵乘法顺利地将fp16的矩阵乘法优化到了cublas的性能,希望本文对读者有所帮助!
1. Introduction
最近研究了一下Nvidia GPU搭载的Tensor Core,开始手写半精度浮点类型(half or fp16)的矩阵乘法算子(c = a * b,其中a、b、c均为fp16类型),并尝试将其优化到cublas的性能水平。
本文源代码参见nicolaswilde/cuda-tensorcore-hgemm (github.com)。
下图是我在RTX3090上测试得到的我自己手写的几个kernel和CUBALS_GEMM_DFALT在M = N = K(256 ~ 16384)下的性能对比,其中加粗蓝色是cublas、加粗绿色是我优化的最终版本、四条灰色曲线是优化的几个中间版本。可以看到,myHGEMMAlignedV5性能基本超过CUBALS_GEMM_DFALT,实现了优化目标。
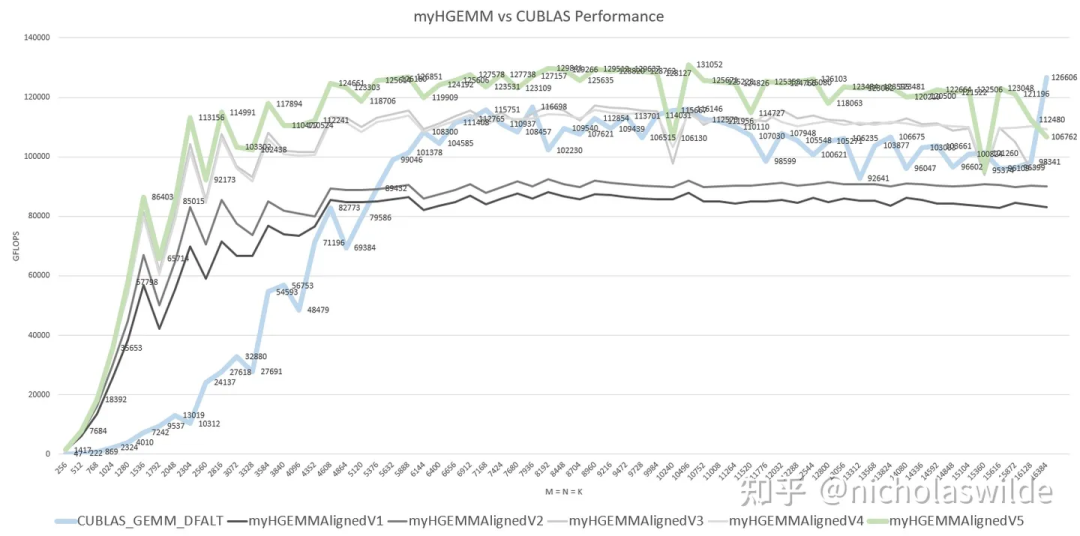
RTX3090共有82个SM,每个SM有4个Tensor Core,每个Tensor Core有256 FLOP/Cycle的fp16算力,实测RTX3090最高运行在1.9GHz左右,因此其fp16峰值算力约为82 * 4 * 256 * 1.9G ~ 159 TFLOPS。我的HGEMM Kenel最高跑到了131 TFLOPS,约为峰值算力的82%。
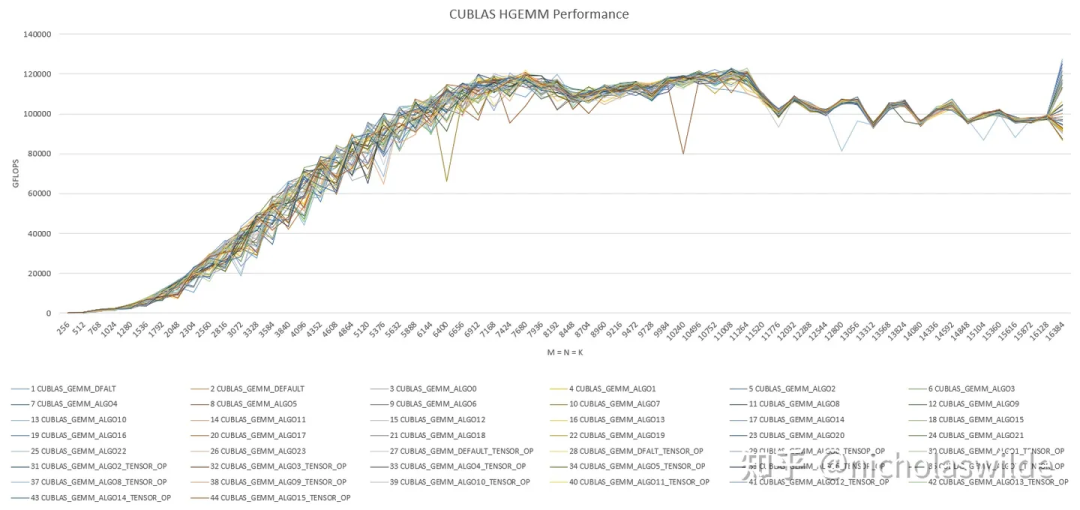
关于cublas,cublas中的cublasGemmEx可以指定参加矩阵乘法运算的数据类型,并且可以指定40多种算法,下图是cublas在M = N = K(256 ~ 16384)的性能表现,最高可以达到126 TFLOPS。从性能曲线上看我严重怀疑这40多种算法最后调用的是相同的kernel可是我又没有证据:
本文使用RTX 3090进行测试,以尝试一下Ampere这代最新架构的GPU。
别问我RTX 3090多少钱买的,本买不起,从某云GPU平台租的2块钱/小时,前后花了我100多大洋...言归正传,从Tensor Core讲起。对Tensor Core已经有所了解的同学们可以直接跳到第四节。
2. Tensor Core
Nvidia从Volta这代GPU开始引入Tensor Core,其目的是用于加速以AI推理和训练为代表的、以大规模矩阵乘法或类矩阵乘法为典型负载的这么一类应用。
毕竟CUDA Core的运算能力有限,在矩阵乘法这种典型的计算密集型的负载上会有大量的访存带宽浪费,Tensor Core的加入就能够在计算矩阵乘法时利用起GPU动辄大几百GB/s的内存带宽。
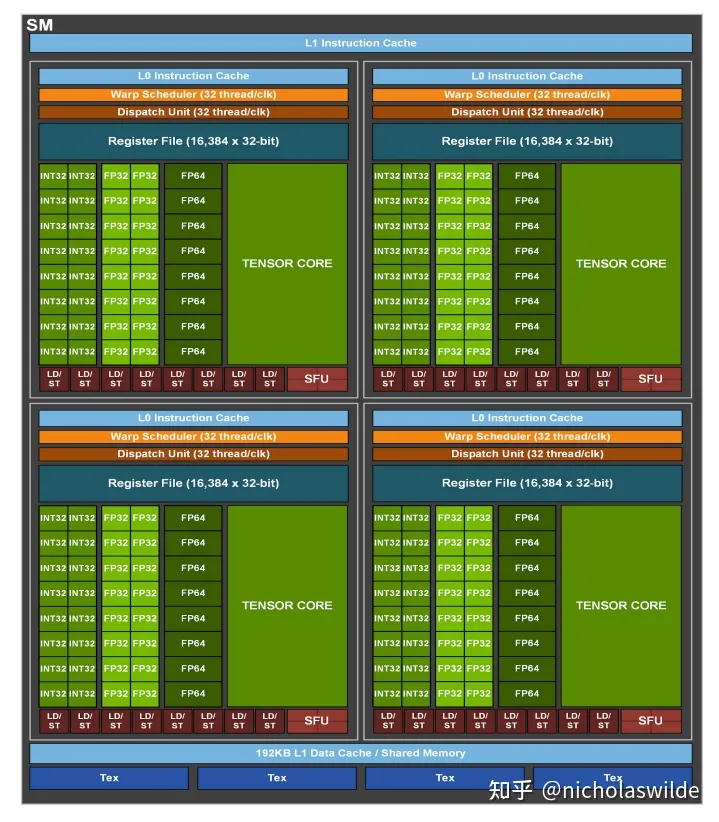
下图是Ampere A100中每个SM的结构图,可以看到Tensor Core实际上就是SM Block中的一个功能部件,同原本的CUDA Core处于相同地位。
当然也有些许的区别:例如INT32的向量指令,一个Warp中32个线程分别在16个INT32的运算部件中执行;而Tensor Core指令则是32个线程合作,取32个线程的操作数共同在一个Tensor Core中完成矩阵乘法操作。
Volta架构中的Tensor Core这里略去不讲,个人猜测是由于物理设计的原因,Volta的Tensor Core在寄存器中还要分Thread Group,同一数据还要存储两次,看起来非常不简洁,关心Volta Tensor Core的可以读一读ISPASS2019的这篇论文《Modeling Deep Learning Accelerator Enabled GPUs》。
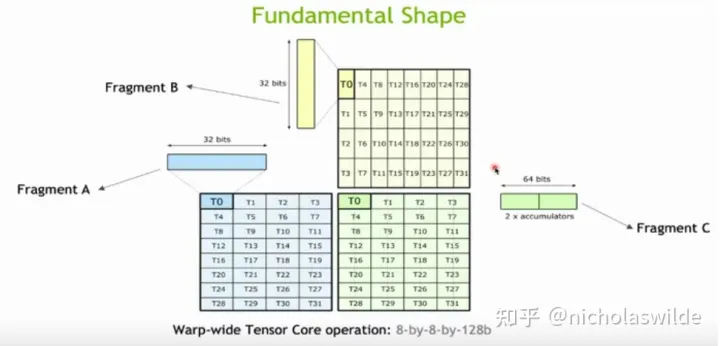
从Turing这一代开始,矩阵元素在寄存器中的摆放方式就非常规整,下图是一个8 - 8 - 128bit的矩阵乘法的示意图。
Turing Tensor Core支持(u)int8和fp16的数据类型,Ampere Tensor Core进一步支持了bf16和tf32数据类型,还有一些不常用的INT4、INT2、INT1。以本文中测试的half(也就是fp16)为例,下图中这个最基本的Tensor Core操作计算了一个8x8x8的矩阵乘法。
Turing Tensor Core为了减少指令数目并缓解寄存器压力,一条Tensor Core指令可以支持16x8x8的fp16的矩阵乘法,对应的SASS指令也就是HMMA.1688,其寄存器排布如下图所示:
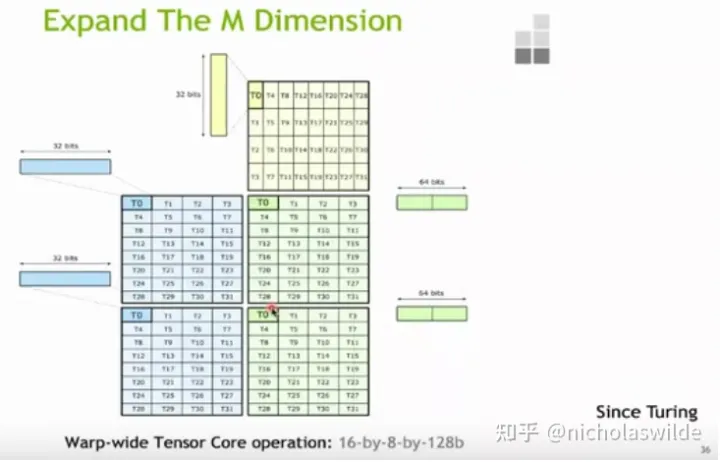
Ampere Tensor Core一条Tensor Core指令可以支持16x8x16的fp16的矩阵乘法,因此我们后续反汇编查看到指定compute capability = 86的SASS代码中清一色的都是HMMA.16816指令了。
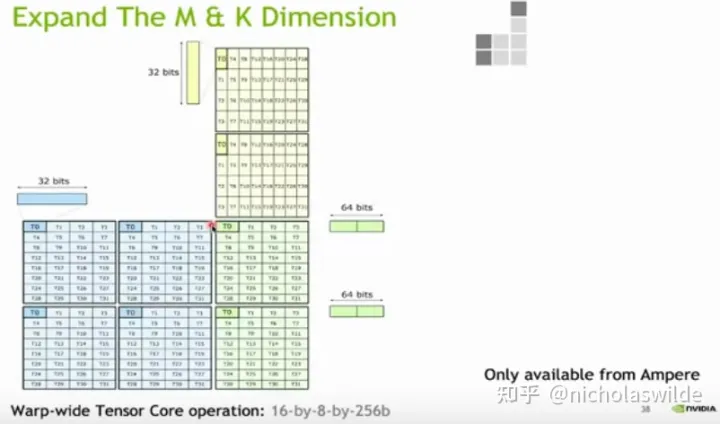
从Volta第一次引入Tensor Core开始,到Ampere的Tensor Core,基本的演进除了数据类型的增加,更重要的是峰值性能的增加。
V100一个SM Block中的两个Tensor Core每拍一共可以计算128个乘累加;而A100一个SM Block中只有一个Tensor Core,每拍可以计算256个乘累加,也就是全流水8拍执行一条HMMA.16816;然而!Sadly,rtx 30系列显卡的Tensor Core竟然阉割了,每拍只有128个乘累加,全流水16拍执行一条HMMA.16816,这样一来rtx 3090一共82个SM,每个SM有4个Tensor Core,标称Boost Clock 1.695GHz,因此峰值性能为82 * 4 * 256 * 1.695G ~ 142 TFLOPS。

3. Tensor Core的编程方法
3.1 C++ API
CUDA C++中包装了Tensor Core的高级API,.../CUDA/v??.?/include/crt/mma.h中定义了这些API。
具体地来说,需要声明matrix_a/matrix_b/accumulator这三种矩阵的fragment(一个fragment对应一个warp的所有线程的某一个或几个寄存器),使用load_matrix_sync和store_matrix_sync将矩阵写入寄存器或将矩阵写回shared memory或global memory,使用mma_sync来调用Tensor Core计算矩阵乘法。
For example:
nvcuda::wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::row_major> frag_a;
nvcuda::wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> frag_a;
nvcuda::wmma::fragment<wmma::accumulator, 16, 16, 16, half> frag_c;
nvcuda::wmma::fill_fragment(frag_c, 0.0);
nvcuda::wmma::load_matrix_sync(frag_a, (shared memory or global memory pointer), (stride_a));
nvcuda::wmma::load_matrix_sync(frag_b, (shared memory or global memory pointer), (stride_b));
nvcuda::wmma::mma_sync(frag_c, frag_a, frag_b, frag_c);
nvcuda::wmma::store_matrix_sync((shared memory or global memory pointer), frag_c, (stride_c), wmma::mem_row_major);这里不同compute capability的GPU支持不同大小的fragment,具体的可以查看《CUDA C++ Programming Guide》。
3.2 PTX指令
在《Parallel Thread Execution ISA》中,9.7.13.3节和9.7.13.4节分别给出了两种指令:wmma指令和mma指令,个人感觉这两类指令可以说是非常类似,其中wmma指令更像是Volta架构的遗留产物。
wmma指令包括:
// wmma.load
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride};
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride};
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride};
// wmma.store
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride};
// wmma.mma
wmma.mma.sync.aligned.alayout.blayout.shape.dtype.ctype d, a, b, c; // fp16
wmma.mma.sync.aligned.alayout.blayout.shape.s32.atype.btype.s32{.satfinite} d, a, b, c; // int8 uint8
wmma.mma.sync.aligned.alayout.blayout.shape.f32.atype.btype.f32 d, a, b, c; // bf16
wmma.mma.sync.aligned.alayout.blayout.shape.f32.atype.btype.f32 d, a, b, c; // tf32
wmma.mma.sync.aligned.alayout.blayout.shape{.rnd}.f64.f64.f64.f64 d, a, b, c; // fp64
wmma.mma.sync.aligned.row.col.shape.s32.atype.btype.s32{.satfinite} d, a, b, c; // int4 uint4
wmma.mma.op.popc.sync.aligned.row.col.shape.s32.atype.btype.s32 d, a, b, c; // int1mma指令包括:// mma
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c; // fp16
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c; // fp16
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c; // fp16
mma.sync.aligned.m16n8k4.row.col.f32.tf32.tf32.f32 d, a, b, c; // bf16 tf32
mma.sync.aligned.m16n8k8.row.col.f32.atype.btype.f32 d, a, b, c; // bf16 tf32
mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32 d, a, b, c; // bf16 tf32
mma.sync.aligned.shape.row.col{.satfinite}.s32.atype.btype.s32 d, a, b, c; // int8 uint8
mma.sync.aligned.shape.row.col{.satfinite}.s32.atype.btype.s32 d, a, b, c; // int4 uint4
mma.sync.aligned.shape.row.col.s32.b1.b1.s32.bitOp.popc d, a, b, c; // int1
// load matrix
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];wmma和mma指令中的矩阵运算指令可以说是非常相似了,但是load指令有所不同:wmma.load指令对矩阵的每行都按照stride访问,而ldmatrix指令则可以对每4个线程对应的元素指定一个地址,所以ldmatrix的访问方式更加灵活,矩阵元素在shared memory中的排放就可以灵活地调整以避免bank conflict。
3.3 SASS指令
不管使用C++ API还是嵌入式的PTX指令,最终都要编译成SASS机器码,fp16类型对应的上述的矩阵load和矩阵乘法均被编译成LSDM指令和HMMA指令。
4. 一个简单的Tensor Core HGEMM Kernel
从计算访存比的角度来说,计算访存比跟(1 / BM + 1 / BN)成正比,也就是说为了让访存带宽不成为瓶颈,我们倾向于让BM和BN越大越好;但是由于BM * BN的accumulator要存放在寄存器中,寄存器数目限制了BM和BN不能无限大。
关于BK的取值,首先BK至少需要是nvcuda::wmma::fragment中定义矩阵的K维度的整数倍;当BK太小(例如取BK = 16)时,核心循环中HMMA指令占比不高,一些循环相关的地址计算的指令会导致性能下降;当BK >= 32时,因为BK不影响计算访存比,我们发现性能基本不会再随BK而提高了;另外还有(BM + BN) * BK还受到shared memory大小的约束。
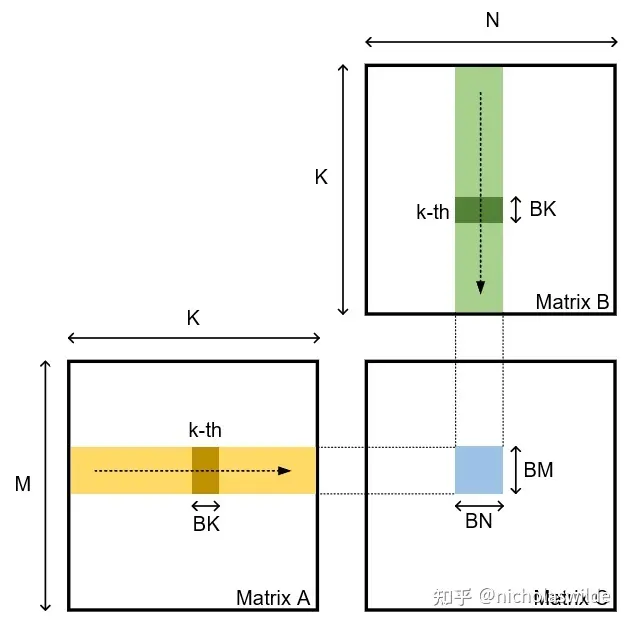
这里我们取BM = 128,BN = 256,BK = 32,thread_per_block = 256。
这样每次K循环中,256个线程每个线程需要取16个矩阵A的元素,取32个矩阵B的元素;8个warp每个warp负责计算64x32x64的矩阵乘法。
为了方便起见假设M/N/K对齐到128/256/32,也就是没有处理corner case。这份代码调用的C++ wmma的API,代码如下:
__global__ void myHGEMMAlignedV1(
half * __restrict__ a, half * __restrict__ b, half * __restrict__ c,
const int M, const int N, const int K) {
const int BM = 128;
const int BN = 256;
const int BK = 32;
int bx = blockIdx.x;
int by = blockIdx.y;
int tid = threadIdx.x;
int wid = tid >> 5;
const int APAD = 8;
const int BPAD = 8;
__shared__ half s_a[BM][BK + APAD];
__shared__ half s_b[BK][BN + BPAD];
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::row_major> frag_a[2][4];
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> frag_b[2][4];
wmma::fragment<wmma::accumulator, 16, 16, 16, half> frag_c[4][4];
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::fill_fragment(frag_c[i][j], 0.0);
}
}
int load_a_smem_m = (tid >> 2) << 1;
int load_a_smem_k = (tid & 3) << 3;
int load_b_smem_k = (tid >> 5) << 2;
int load_b_smem_n = (tid & 31) << 3;
int load_a_gmem_m = by * BM + load_a_smem_m;
int load_b_gmem_n = bx * BN + load_b_smem_n;
int load_a_gmem_addr = OFFSET(load_a_gmem_m, load_a_smem_k, K);
int load_b_gmem_addr = OFFSET(load_b_smem_k, load_b_gmem_n, N);
int comp_c_frag_m = wid & 1;
int comp_c_frag_n = wid >> 1;
for (int bk = 0; bk < K / BK; bk++) {
FLOAT4(s_a[load_a_smem_m ][load_a_smem_k]) = FLOAT4(a[load_a_gmem_addr ]);
FLOAT4(s_a[load_a_smem_m + 1][load_a_smem_k]) = FLOAT4(a[load_a_gmem_addr + K]);
FLOAT4(s_b[load_b_smem_k ][load_b_smem_n]) = FLOAT4(b[load_b_gmem_addr ]);
FLOAT4(s_b[load_b_smem_k + 1][load_b_smem_n]) = FLOAT4(b[load_b_gmem_addr + N]);
FLOAT4(s_b[load_b_smem_k + 2][load_b_smem_n]) = FLOAT4(b[load_b_gmem_addr + 2 * N]);
FLOAT4(s_b[load_b_smem_k + 3][load_b_smem_n]) = FLOAT4(b[load_b_gmem_addr + 3 * N]);
load_a_gmem_addr += BK;
load_b_gmem_addr += BK * N;
__syncthreads();
wmma::load_matrix_sync(frag_a[0][0], &s_a[comp_c_frag_m * 64 ][ 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][1], &s_a[comp_c_frag_m * 64 + 16][ 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][2], &s_a[comp_c_frag_m * 64 + 32][ 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][3], &s_a[comp_c_frag_m * 64 + 48][ 0], BK + APAD);
wmma::load_matrix_sync(frag_a[1][0], &s_a[comp_c_frag_m * 64 ][16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][1], &s_a[comp_c_frag_m * 64 + 16][16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][2], &s_a[comp_c_frag_m * 64 + 32][16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][3], &s_a[comp_c_frag_m * 64 + 48][16], BK + APAD);
wmma::load_matrix_sync(frag_b[0][0], &s_b[ 0][comp_c_frag_n * 64 ], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][1], &s_b[ 0][comp_c_frag_n * 64 + 16], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][2], &s_b[ 0][comp_c_frag_n * 64 + 32], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][3], &s_b[ 0][comp_c_frag_n * 64 + 48], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][0], &s_b[16][comp_c_frag_n * 64 ], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][1], &s_b[16][comp_c_frag_n * 64 + 16], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][2], &s_b[16][comp_c_frag_n * 64 + 32], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][3], &s_b[16][comp_c_frag_n * 64 + 48], BN + BPAD);
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::mma_sync(frag_c[i][j], frag_a[0][i], frag_b[0][j], frag_c[i][j]);
wmma::mma_sync(frag_c[i][j], frag_a[1][i], frag_b[1][j], frag_c[i][j]);
}
}
__syncthreads();
}
int store_c_gmem_m = by * BM + comp_c_frag_m * 64;
int store_c_gmem_n = bx * BN + comp_c_frag_n * 64;
int store_c_gmem_addr = OFFSET(store_c_gmem_m, store_c_gmem_n, N);
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::store_matrix_sync(&c[store_c_gmem_addr + i * 16 * N + j * 16], frag_c[i][j], N, wmma::mem_row_major);
}
}
}其中需要注意的地方是,为了避免LDSM指令从shared memory中取数时发生bank conflict,因此shared memory中每行矩阵后面都加了16 Bytes的pad,有兴趣的同学可以画一画矩阵在shared memory中的排布,思考一下为什么每行加16 Bytes就可以避免bank conflict。
这里避免bank conflict的方式非常naive,会造成shared memory的浪费(虽然shared memory也够用了)。
CUTLASS中采用了这样一种排布方式:https://developer.download.nvidia.cn/video/gputechconf/gtc/2019/presentation/s9593-cutensor-high-performance-tensor-operations-in-cuda-v2.pdf,可以在不额外增加shared memory占用的情况下,同时避免读写shared memory时的冲突。
这种方法因为在load矩阵时需要为每四个线程指定一个shared memory的地址,不能使用stride访问,所以编程时C++ API和PTX的wmma指令都不适用,需要使用PTX中的ldmatrix指令。
5. Global Memory到Shared Memory的异步拷贝
在Ampere架构以前,global memory到shared memory的数据拷贝需要寄存器的参与,即先从global memory加载到寄存器,再从寄存器写到shared memory;Ampere架构引入了global memory到shared memory的异步拷贝的特性,不需要在寄存器中转数据,还有利于节省中间寄存器的使用。
Global memory到shared memory的异步拷贝,cuda cooperative_groups和pipeline中均有C++ API的支持,但是该接口cooperative_groups::memcpy_async(group, p_smem, p_gmem, size)仅支持了连续数据的拷贝,而矩阵乘法算子中加载的数据并不连续,需要间隔stride访问,因此我使用了PTX嵌入式汇编。
PTX指令中的异步拷贝指令共有四条,除了指定dst、src和size,还可以指定L1和L2 cache的一些行为:
cp.async.ca.shared.global{.level::cache_hint}{.level::prefetch_size}
[dst], [src], cp-size{, src-size}{, cache-policy} ;
cp.async.cg.shared.global{.level::cache_hint}{.level::prefetch_size}
[dst], [src], 16{, src-size}{, cache-policy} ;
cp.async.ca.shared.global{.level::cache_hint}{.level::prefetch_size}
[dst], [src], cp-size{, ignore-src}{, cache-policy} ;
cp.async.cg.shared.global{.level::cache_hint}{.level::prefetch_size}
[dst], [src], 16{, ignore-src}{, cache-policy} ;
.level::cache_hint = { .L2::cache_hint }
.level::prefetch_size = { .L2::64B, .L2::128B, .L2::256B }
cp-size = { 4, 8, 16 }异步拷贝指令后需要使用cp.async.commit_group指令+cp.async.wait_group指令,或者cp.async.wait_all指令来等待指定的拷贝指令完成数据拷贝。
我们把GEMM Kernel中矩阵A和矩阵B global memory到shared memory的数据拷贝替换成异步拷贝:
__global__ void myHGEMMAlignedV2(
half * __restrict__ a, half * __restrict__ b, half * __restrict__ c,
const int M, const int N, const int K) {
const int BM = 128;
const int BN = 256;
const int BK = 32;
int bx = blockIdx.x;
int by = blockIdx.y;
int tid = threadIdx.x;
int wid = tid >> 5;
const int APAD = 8;
const int BPAD = 8;
__shared__ half s_a[BM][BK + APAD];
__shared__ half s_b[BK][BN + BPAD];
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::row_major> frag_a[2][4];
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> frag_b[2][4];
wmma::fragment<wmma::accumulator, 16, 16, 16, half> frag_c[4][4];
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::fill_fragment(frag_c[i][j], 0.0);
}
}
int load_a_smem_m = (tid >> 2) << 1;
int load_a_smem_k = (tid & 3) << 3;
int load_b_smem_k = (tid >> 5) << 2;
int load_b_smem_n = (tid & 31) << 3;
int s_a_base_addr = __cvta_generic_to_shared(s_a[0]);
int s_b_base_addr = __cvta_generic_to_shared(s_b[0]);
int load_a_smem_addr_0 = s_a_base_addr + OFFSET(load_a_smem_m, load_a_smem_k, BK + APAD) * sizeof(half);
int load_a_smem_addr_1 = load_a_smem_addr_0 + (BK + APAD) * sizeof(half);
int load_b_smem_addr_0 = s_b_base_addr + OFFSET(load_b_smem_k, load_b_smem_n, BN + BPAD) * sizeof(half);
int load_b_smem_addr_1 = load_b_smem_addr_0 + (BN + BPAD) * sizeof(half);
int load_b_smem_addr_2 = load_b_smem_addr_0 + 2 * (BN + BPAD) * sizeof(half);
int load_b_smem_addr_3 = load_b_smem_addr_0 + 3 * (BN + BPAD) * sizeof(half);
int load_a_gmem_m = by * BM + load_a_smem_m;
int load_b_gmem_n = bx * BN + load_b_smem_n;
int load_a_gmem_addr = OFFSET(load_a_gmem_m, load_a_smem_k, K);
int load_b_gmem_addr = OFFSET(load_b_smem_k, load_b_gmem_n, N);
int comp_c_frag_m = wid & 1;
int comp_c_frag_n = wid >> 1;
for (int bk = 0; bk < K / BK; bk++) {
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_a_smem_addr_0), "l"(&a[load_a_gmem_addr ]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_a_smem_addr_1), "l"(&a[load_a_gmem_addr + K]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_0), "l"(&b[load_b_gmem_addr ]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_1), "l"(&b[load_b_gmem_addr + N]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_2), "l"(&b[load_b_gmem_addr + 2 * N]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_3), "l"(&b[load_b_gmem_addr + 3 * N]));
load_a_gmem_addr += BK;
load_b_gmem_addr += BK * N;
asm ("cp.async.commit_group;\n" ::);
asm ("cp.async.wait_group 0;\n" ::);
__syncthreads();
wmma::load_matrix_sync(frag_a[0][0], &s_a[comp_c_frag_m * 64 ][ 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][1], &s_a[comp_c_frag_m * 64 + 16][ 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][2], &s_a[comp_c_frag_m * 64 + 32][ 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][3], &s_a[comp_c_frag_m * 64 + 48][ 0], BK + APAD);
wmma::load_matrix_sync(frag_a[1][0], &s_a[comp_c_frag_m * 64 ][16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][1], &s_a[comp_c_frag_m * 64 + 16][16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][2], &s_a[comp_c_frag_m * 64 + 32][16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][3], &s_a[comp_c_frag_m * 64 + 48][16], BK + APAD);
wmma::load_matrix_sync(frag_b[0][0], &s_b[ 0][comp_c_frag_n * 64 ], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][1], &s_b[ 0][comp_c_frag_n * 64 + 16], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][2], &s_b[ 0][comp_c_frag_n * 64 + 32], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][3], &s_b[ 0][comp_c_frag_n * 64 + 48], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][0], &s_b[16][comp_c_frag_n * 64 ], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][1], &s_b[16][comp_c_frag_n * 64 + 16], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][2], &s_b[16][comp_c_frag_n * 64 + 32], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][3], &s_b[16][comp_c_frag_n * 64 + 48], BN + BPAD);
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::mma_sync(frag_c[i][j], frag_a[0][i], frag_b[0][j], frag_c[i][j]);
wmma::mma_sync(frag_c[i][j], frag_a[1][i], frag_b[1][j], frag_c[i][j]);
}
}
__syncthreads();
}
int store_c_gmem_m = by * BM + comp_c_frag_m * 64;
int store_c_gmem_n = bx * BN + comp_c_frag_n * 64;
int store_c_gmem_addr = OFFSET(store_c_gmem_m, store_c_gmem_n, N);
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::store_matrix_sync(&c[store_c_gmem_addr + i * 16 * N + j * 16], frag_c[i][j], N, wmma::mem_row_major);
}
}
}这里需要注意嵌入式的PTX汇编中,shared memory的指针需要特殊处理一下。
因为用&smem[...]这样得到的是generic的指针(8字节),直接该8字节值作为shared memory的地址可能会超出shared memory的地址范围,所以需要使用__cvta_generic_to_shared()或者将该8字节值与上0xFFFFFF,使该指针指向shared memory的地址空间。
详情参见:Problem about PTX instruction cp.async.ca.shared.global - CUDA Programming and Performance - NVIDIA Developer Forums。
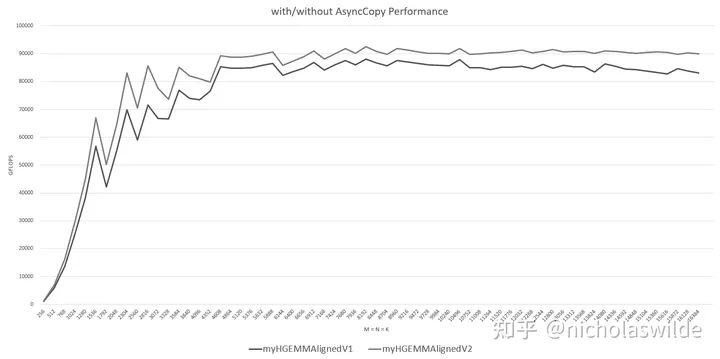
Global Memory到Shared Memory异步拷贝的加入大概带来了5 TFLOPS ~ 10 TFLOPS的性能提升:
6. Double Buffer
Double Buffer的目的是,在从global memory向shared memory加载下一次计算使用的数据时,刚好进行本次计算,以掩盖访存延迟。
其实我也没有非常清楚double buffer的算子最好应该怎么写,下面的代码只是我自己尝试的一种测出来有性能提升的写法,另外我看到nvidia forum上有使用C++ API中的pipeline来实现double buffer的。
__global__ void myHGEMMAlignedV3(
half * __restrict__ a, half * __restrict__ b, half * __restrict__ c,
const int M, const int N, const int K) {
const int BM = 128;
const int BN = 256;
const int BK = 32;
int bx = blockIdx.x;
int by = blockIdx.y;
int tid = threadIdx.x;
int wid = tid >> 5;
const int APAD = 8;
const int BPAD = 8;
extern __shared__ half smem[];
half *s_a = smem;
half *s_b = smem + 2 * BM * (BK + APAD);
int s_a_db_offset = BM * (BK + APAD);
int s_b_db_offset = BK * (BN + BPAD);
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::row_major> frag_a[2][4];
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> frag_b[2][4];
wmma::fragment<wmma::accumulator, 16, 16, 16, half> frag_c[4][4];
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::fill_fragment(frag_c[i][j], 0.0);
}
}
int load_a_smem_m = (tid >> 2) << 1;
int load_a_smem_k = (tid & 3) << 3;
int load_b_smem_k = (tid >> 5) << 2;
int load_b_smem_n = (tid & 31) << 3;
int s_a_base_addr = __cvta_generic_to_shared(s_a);
int s_b_base_addr = __cvta_generic_to_shared(s_b);
int load_a_smem_addr_0 = s_a_base_addr + OFFSET(load_a_smem_m, load_a_smem_k, BK + APAD) * sizeof(half);
int load_a_smem_addr_1 = load_a_smem_addr_0 + (BK + APAD) * sizeof(half);
int load_b_smem_addr_0 = s_b_base_addr + OFFSET(load_b_smem_k, load_b_smem_n, BN + BPAD) * sizeof(half);
int load_b_smem_addr_1 = load_b_smem_addr_0 + (BN + BPAD) * sizeof(half);
int load_b_smem_addr_2 = load_b_smem_addr_0 + 2 * (BN + BPAD) * sizeof(half);
int load_b_smem_addr_3 = load_b_smem_addr_0 + 3 * (BN + BPAD) * sizeof(half);
int load_a_gmem_m = by * BM + load_a_smem_m;
int load_b_gmem_n = bx * BN + load_b_smem_n;
int load_a_gmem_addr = OFFSET(load_a_gmem_m, load_a_smem_k, K);
int load_b_gmem_addr = OFFSET(load_b_smem_k, load_b_gmem_n, N);
int comp_c_frag_m = wid & 1;
int comp_c_frag_n = wid >> 1;
{
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_a_smem_addr_0), "l"(&a[load_a_gmem_addr ]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_a_smem_addr_1), "l"(&a[load_a_gmem_addr + K]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_0), "l"(&b[load_b_gmem_addr ]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_1), "l"(&b[load_b_gmem_addr + N]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_2), "l"(&b[load_b_gmem_addr + 2 * N]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_3), "l"(&b[load_b_gmem_addr + 3 * N]));
asm ("cp.async.commit_group;\n" ::);
asm ("cp.async.wait_group 0;\n" ::);
__syncthreads();
}
for (int bk = 1; bk < K / BK; bk++) {
int smem_sel = (bk & 1) ^ 1;
int smem_sel_next = ((bk - 1) & 1) ^ 1;
load_a_gmem_addr += BK;
load_b_gmem_addr += BK * N;
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_a_smem_addr_0 + smem_sel_next * s_a_db_offset * (int)sizeof(half)), "l"(&a[load_a_gmem_addr ]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_a_smem_addr_1 + smem_sel_next * s_a_db_offset * (int)sizeof(half)), "l"(&a[load_a_gmem_addr + K]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_0 + smem_sel_next * s_b_db_offset * (int)sizeof(half)), "l"(&b[load_b_gmem_addr ]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_1 + smem_sel_next * s_b_db_offset * (int)sizeof(half)), "l"(&b[load_b_gmem_addr + N]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_2 + smem_sel_next * s_b_db_offset * (int)sizeof(half)), "l"(&b[load_b_gmem_addr + 2 * N]));
asm ("cp.async.ca.shared.global [%0], [%1], 16;\n" :
: "r"(load_b_smem_addr_3 + smem_sel_next * s_b_db_offset * (int)sizeof(half)), "l"(&b[load_b_gmem_addr + 3 * N]));
wmma::load_matrix_sync(frag_a[0][0], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 ) * (BK + APAD) + 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][1], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 16) * (BK + APAD) + 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][2], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 32) * (BK + APAD) + 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][3], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 48) * (BK + APAD) + 0], BK + APAD);
wmma::load_matrix_sync(frag_a[1][0], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 ) * (BK + APAD) + 16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][1], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 16) * (BK + APAD) + 16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][2], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 32) * (BK + APAD) + 16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][3], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 48) * (BK + APAD) + 16], BK + APAD);
wmma::load_matrix_sync(frag_b[0][0], &s_b[smem_sel * s_b_db_offset + comp_c_frag_n * 64 ], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][1], &s_b[smem_sel * s_b_db_offset + comp_c_frag_n * 64 + 16], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][2], &s_b[smem_sel * s_b_db_offset + comp_c_frag_n * 64 + 32], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][3], &s_b[smem_sel * s_b_db_offset + comp_c_frag_n * 64 + 48], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][0], &s_b[smem_sel * s_b_db_offset + 16 * (BN + BPAD) + comp_c_frag_n * 64 ], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][1], &s_b[smem_sel * s_b_db_offset + 16 * (BN + BPAD) + comp_c_frag_n * 64 + 16], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][2], &s_b[smem_sel * s_b_db_offset + 16 * (BN + BPAD) + comp_c_frag_n * 64 + 32], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][3], &s_b[smem_sel * s_b_db_offset + 16 * (BN + BPAD) + comp_c_frag_n * 64 + 48], BN + BPAD);
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::mma_sync(frag_c[i][j], frag_a[0][i], frag_b[0][j], frag_c[i][j]);
wmma::mma_sync(frag_c[i][j], frag_a[1][i], frag_b[1][j], frag_c[i][j]);
}
}
asm ("cp.async.commit_group;\n" ::);
asm ("cp.async.wait_group 0;\n" ::);
__syncthreads();
}
int smem_sel = ((K / BK) & 1) ^ 1;
wmma::load_matrix_sync(frag_a[0][0], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 ) * (BK + APAD) + 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][1], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 16) * (BK + APAD) + 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][2], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 32) * (BK + APAD) + 0], BK + APAD);
wmma::load_matrix_sync(frag_a[0][3], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 48) * (BK + APAD) + 0], BK + APAD);
wmma::load_matrix_sync(frag_a[1][0], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 ) * (BK + APAD) + 16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][1], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 16) * (BK + APAD) + 16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][2], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 32) * (BK + APAD) + 16], BK + APAD);
wmma::load_matrix_sync(frag_a[1][3], &s_a[smem_sel * s_a_db_offset + (comp_c_frag_m * 64 + 48) * (BK + APAD) + 16], BK + APAD);
wmma::load_matrix_sync(frag_b[0][0], &s_b[smem_sel * s_b_db_offset + comp_c_frag_n * 64 ], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][1], &s_b[smem_sel * s_b_db_offset + comp_c_frag_n * 64 + 16], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][2], &s_b[smem_sel * s_b_db_offset + comp_c_frag_n * 64 + 32], BN + BPAD);
wmma::load_matrix_sync(frag_b[0][3], &s_b[smem_sel * s_b_db_offset + comp_c_frag_n * 64 + 48], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][0], &s_b[smem_sel * s_b_db_offset + 16 * (BN + BPAD) + comp_c_frag_n * 64 ], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][1], &s_b[smem_sel * s_b_db_offset + 16 * (BN + BPAD) + comp_c_frag_n * 64 + 16], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][2], &s_b[smem_sel * s_b_db_offset + 16 * (BN + BPAD) + comp_c_frag_n * 64 + 32], BN + BPAD);
wmma::load_matrix_sync(frag_b[1][3], &s_b[smem_sel * s_b_db_offset + 16 * (BN + BPAD) + comp_c_frag_n * 64 + 48], BN + BPAD);
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::mma_sync(frag_c[i][j], frag_a[0][i], frag_b[0][j], frag_c[i][j]);
wmma::mma_sync(frag_c[i][j], frag_a[1][i], frag_b[1][j], frag_c[i][j]);
}
}
int store_c_gmem_m = by * BM + comp_c_frag_m * 64;
int store_c_gmem_n = bx * BN + comp_c_frag_n * 64;
int store_c_gmem_addr = OFFSET(store_c_gmem_m, store_c_gmem_n, N);
#pragma unroll
for (int i = 0; i < 4; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
wmma::store_matrix_sync(&c[store_c_gmem_addr + i * 16 * N + j * 16], frag_c[i][j], N, wmma::mem_row_major);
}
}
}这里需要注意的是,double buffer会用到两倍的shared memory,当使用的shared memory超过48 KB时,需要使用dynamic shared memory,即extern 「shared」 half smem[];这样声明一块动态共享内存,调用kernel时需要指定动态共享内存大小,且smem的寻址方式需要按照一维数组来使用:
const int BM = 128, BN = 256, BK = 32;
dim3 blockDim(256);
int BX = (N + BN - 1) / BN;
int BY = (M + BM - 1) / BM;
dim3 gridDim(BX, BY);
cudaFuncSetAttribute(gemmBK32WmmaAsyncDSMemDB, cudaFuncAttributeMaxDynamicSharedMemorySize, 98304);
unsigned int dsmem = 2 * (BM * (BK + 8) + BK * (BN + 8)) * sizeof(half);
gemmBK32WmmaAsyncDSMemDB<<<gridDim, blockDim, dsmem>>>(a, b, c, M, N, K);Double Buffer的效果可谓是立竿见影,带来了大概20 TFLOPS ~ 25 TFLOPS的提升:
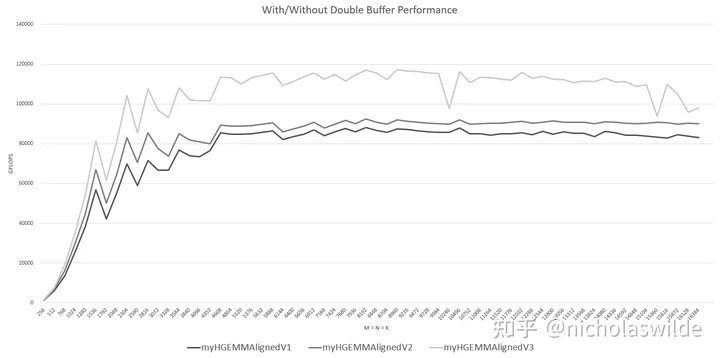
7. 提高L2 Cache的局部性
RTX3090一共有82个SM,经过计算gemmBK32WmmaAsyncDSMemDB这个kernel每个SM只能容纳一个block,当大规模矩阵乘法的block数目超过82时,会按照gridDim.z -> gridDim.y -> gridDim.x这样的循环顺序进行调度。
例如当M = N = K = 16384时,矩阵C会被分块成128 * 64个Tile,如果按照正常的调度顺序,先调度矩阵C第一行64个Tile对应的block加上第二行的前18个block,这样虽然矩阵A的局部性很好,但是矩阵B的访存局部性极差。
我们现在希望第一次先调度第一行到第五行的前16个block,加上第六行的前2个block,这样矩阵A和矩阵B的局部性就得到了平衡。
修改一下调用kernel时的代码,利用其默认的调度顺序,加上gridDim.z这一维,这里NSPLIT就代表矩阵C的一行一次调度到NSPLIT这么多就转到下一行:
const int BM = 128, BN = 256, BK = 32;
dim3 blockDim(256);
int BX = (N + BN - 1) / BN;
int BY = (M + BM - 1) / BM;
const int NSPLIT = 4096;
int split_num = (N + NSPLIT - 1) / NSPLIT;
dim3 gridDim((BX + split_num - 1) / split_num, BY, split_num);
cudaFuncSetAttribute(gemmBK32WmmaAsyncDSMemDB, cudaFuncAttributeMaxDynamicSharedMemorySize, 98304);
unsigned int dsmem = 2 * (BM * (BK + 8) + BK * (BN + 8)) * sizeof(half);
gemmBK32WmmaAsyncDSMemDB<<<gridDim, blockDim, dsmem>>>(a, b, c, M, N, K);相应地修改kernel:
__global__ void myHGEMMAlignedV4(
half * __restrict__ a, half * __restrict__ b, half * __restrict__ c,
const int M, const int N, const int K) {
// ...
// int bx = blockIdx.x; // 原来是这样
int bx = blockIdx.z * gridDim.x + blockIdx.x; // 现在是这样
if (bx >= N / BN || by >= M / BM)
return;
// ...
}想法很丰满,现实很骨感,测试发现NSPLIT = 256时性能很差,而NSPLIT = 512/1024/2048/4096/8192时和myHGEMMAlignedV3相差无几,只有在接近16384的几个样本点性能表现明显更好。
为了让优化代码不要白写,我最终选取了NSPLIT = 4096:
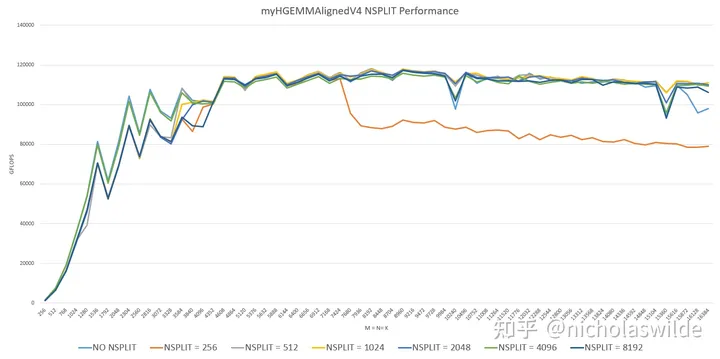
8. 给编译器一些发挥的空间
事实上优化到myHGEMMAlignedV3这里添加了double buffer之后,就已经达到并大致超过了cublas。最后让编译器给主循环进行循环展开,看看能再有多大的性能提升:
__global__ void myHGEMMAlignedV4(
half * __restrict__ a, half * __restrict__ b, half * __restrict__ c,
const int M, const int N, const int K) {
// ...
#pragma unroll 32
for (int bk = 1; bk < K / BK; bk++) {
// ...
}
// ...
}测试结果如下图所示,循环展开比不循环展开时又提高了约15 TFLOPS,基本全面超过cublas。在M = N = K > 4096时,循环展开到8之后性能基本不会再有提升;但MNK较小时,直到展开32次仍然还有提升。

9. At last
至此就是本次文章的全部内容,学习了一下Tensor Core的使用方法,并顺利地将fp16的矩阵乘法优化到了cublas的性能。当然,其中一部分性能还来自于我假设MNK都是对齐的,没有判断corner case。
总体性能图:
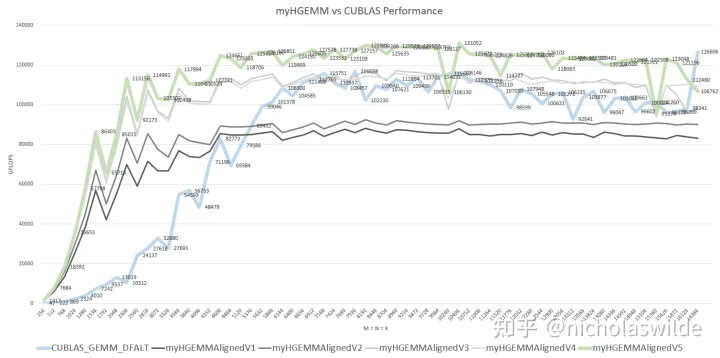
10. Reference
[1].《NVIDIA A100 Tensor Core GPU Architecture》Whitepaper
[2].《NVIDIA AMPERE GA102 GPU ARCHITECTURE》Whitepaper
[3].《NVIDIA TESLA V100 GPU ARCHITECTURE》Whitepaper
[4].《CUDA C++ Programming Guide v11.5》
[5].《Parallel Thread Execution ISA Application Guide v7.5》
[6].CUDA SGEMM矩阵乘法优化笔记——从入门到cublas - 知乎 (zhihu.com)
[7].NVIDIA GeForce RTX 3090 Specs | TechPowerUp GPU Database
[8].《Modeling Deep Learning Accelerator Enabled GPUs》
[9].看搭载了第三代Tensor Core的A100如何实现吞吐性能翻倍_哔哩哔哩_bilibili
[10].https://developer.nvidia.com/blog/controlling-data-movement-to-boost-performance-on-ampere-architecture/
[11].https://github.com/NVIDIA/cutlass
[12].https://developer.download.nvidia.cn/video/gputechconf/gtc/2019/presentation/s9593-cutensor-high-performance-tensor-operations-in-cuda-v2.pdf
[13].https://forums.developer.nvidia.com
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
