转载请注明: https://www.cnblogs.com/Ethan-Code/p/16619091.html
内核的内存分区
32位机中的虚拟内存大小为4GB,其中0~3GB用于用户空间,3~4GB用于内核空间。
内核的内存空间只有1G,这一部分内存在进程中共享,与用户空间隔离,用户空间不能访问。
内核空间在虚拟内存上分为三个区间:从低到高分别是:
- ZONE_DMA(16M)
- ZONE_NORMAL(16~896M)
- ZONE_HIGHMEM(896~1024M)
各区间具体与物理内存映射如下:

从这张图可以明显看到,虚拟地址3G~3G+896M的虚拟内存,直接线性映射到物理地址0~896M的物理内存上。因此这上面的内存映射效率很高。
而 3.896G~4G 的虚拟地址称为高端内存,分为非连续内存区、永久内核映射区和固定映射区三个部分。
ZONE_DMA
ZONE_DMA: 16M 线性映射区(3~3.016G)
该区域的物理页面专门供I/O设备的DMA使用。
需要单独管理DMA的物理页面的原因:
- DMA使用物理地址访问内存,不经过MMU
- 需要连续的缓冲区
为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区域用于DMA。
例如dma_alloc_coherent函数获取的内存就是ZONE_DMA内存,并且保证一致性。
关于缓存一致性问题感兴趣可参考:https://www.cnblogs.com/Ethan-Code/p/16652513.html
ZONE_NORMAL
ZONE_NORMAL:880M 线性映射区(3.016~3.896G)
该区域的物理页面是内核能够直接使用的,比如内核程序中代码段、全局变量以及kmalloc获取的堆内存等。
从此处获取内存一般是连续的,但是不能太大。
kmalloc申请的是直接线性映射的连续物理内存,因为是直接映射不需要建立页表,所以效率较高,缺点是只能分配小内存。
ZONE_HIGHMEM
ZONE_HIGHMEM:128M 高端内存(3.896~4G)
区域比较复杂可细分为三部分:
1. 非连续内存区
非连续内存区,也可以叫动态映射区,也可以叫vmalloc分区。
可以将物理内存上不连续的页框映射到连续的内核虚拟地址上,主要应用于大容量的内存分配。
采用这种方式分配内存的主要优点是避免了外部碎片,而缺点是必须打乱内核页表,而且访问速度较连续分配的物理页框慢。
函数vmalloc即是通过该部分虚拟地址来映射物理内存页,它是按页分配的,与kmalloc的直接映射截然不同。
问题:非连续内存区只有128M,vmalloc是如何分配大内存的?
当内核想访问高于896M的物理地址时,可以调用**vmalloc**在0xF8000000(3G) ~ 0xFFFFFFFF(4G)虚拟地址空间中取(借用)一部分与物理内存页框建立映射,即填充内核PTE页表。访问完成之后由内核释放,以便其它进程访问。
采用这128M的虚拟空间,建立临时地址映射(借用其他的空闲虚拟地址来访问物理内存)完成了对所有高于896M物理内存的访问。实现了使用有限的地址空间,访问所有所有物理内存。
例如内核想访问2G开始的一段大小为1MB的物理内存(如0×80000000 ~ 0x800FFFFF)。访问之前先找到一段1MB大小的空闲虚拟地址空间(如0xF8700000 ~ 0xF87FFFFF),用这1MB的逻辑地址空间映射到物理地址空间0×80000000 ~ 0x800FFFFF的内存。
2. 永久内核映射区
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。
在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。
通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来pkmap_page_table 寻找这个页表。
通过 kmap(),可以把一个 page 映射到这个空间来。
由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,应该及时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。
3. 固定映射区
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为固定映射空间。
在这个空间中,有一部分用于高端内存的临时映射。
这块空间具有如下特点:
- 每个CPU 占用一块空间
- 在每个CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。
通过 kmap_atomic() 可实现临时映射。
具体内核内存分布如下:

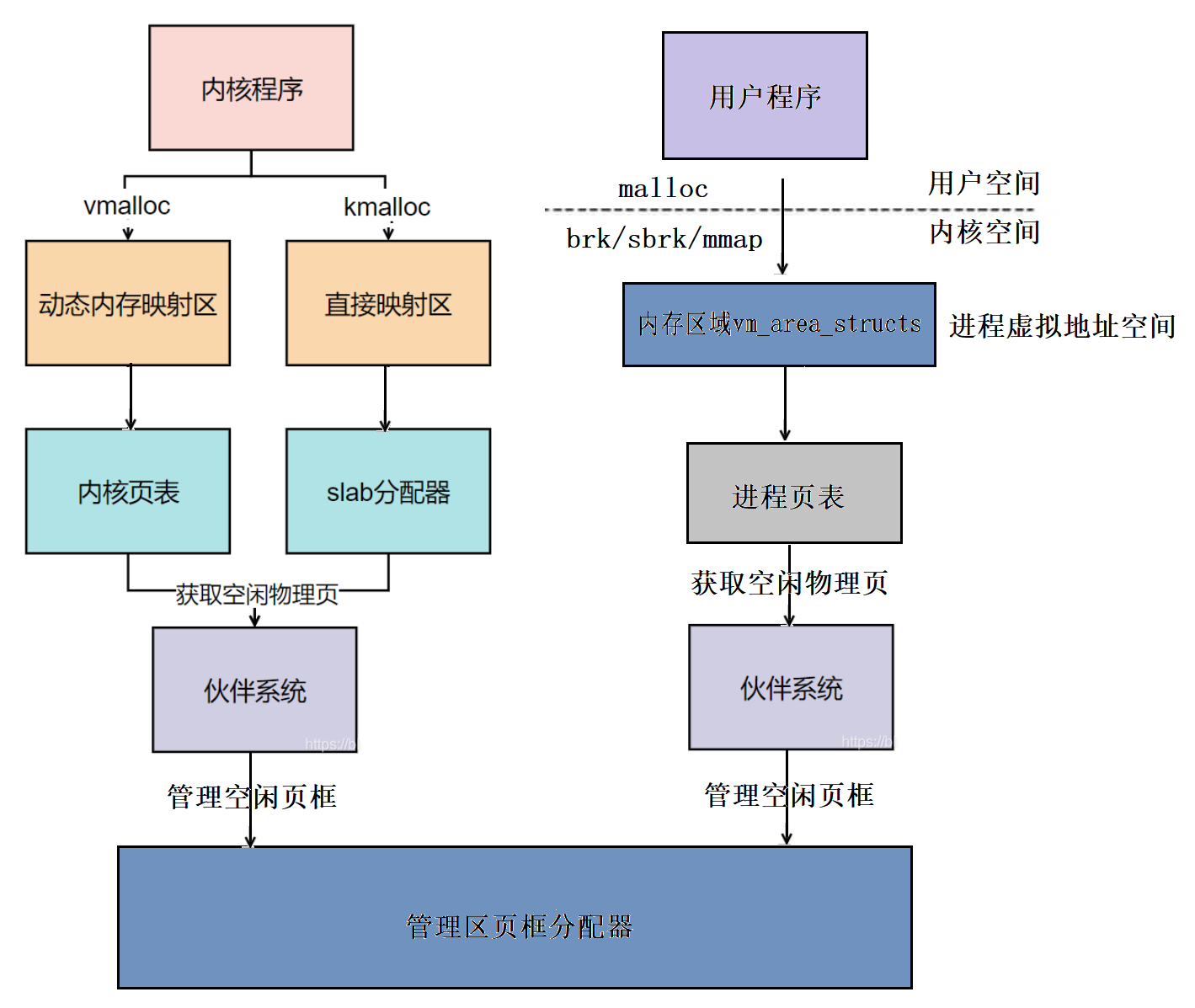
kmalloc与vmalloc的区别
-
kmalloc分配连续的小内存,分配的是内核的线性映射区(线性映射的896M里),分配内存是基于slab。
-
vmalloc分配虚拟地址上连续、物理地址上不连续的内存。每次分配需要建立PTE内核页表,开销较大。
vmalloc的原理非常巧妙,从上面我们知道内核的非连续内存区很小,只占128M高端内存的一部分,那么它是怎样实现分配和访问大内存的呢?其实它的实现分为两步:
- 调用
get_vm_area()函数申请一个合法的虚拟内存地址。 - 调用
vmalloc_area_pages()函数把虚拟内存地址映射到物理内存地址。
kmalloc()与vmalloc() 都是在内核代码中提供给其他子系统用来分配内存的函数。
一般情况下在驱动程序中都是调用kmalloc()来给数据结构分配内存。
只有硬件设备才需要物理地址连续的内存,因为硬件设备往往存在于MMU之外,根本不了解虚拟地址,因此为了性能上的考虑,内核中一般使用 kmalloc()
而vmalloc()用在为活动的交换区分配数据结构,为某些I/O驱动程序分配缓冲区,或为模块分配空间。
只有在需要获得大块内存时才使用vmalloc(),例如当模块被动态加载到内核当中时,就把模块装载到由vmalloc()分配的内存上。
参考:https://www.cnblogs.com/hongzhunzhun/p/4533960.html
https://www.lxlinux.net/1652.html
https://blog.csdn.net/hardworkba/article/details/10365135
https://blog.csdn.net/chen1540524015/article/details/73719410
kmalloc与vmalloc的区别
vmalloc的原理与实现