一、LSTM原理
长短时记忆网络(Long Short-Term Memory,LSTM)是一种用于处理序列数据的循环神经网络(RNN)变体,设计用来解决传统RNN在处理长序列数据时的梯度消失、长期依赖等问题。LSTM引入了门控机制,允许网络有选择地记忆、遗忘和更新信息,从而更好地捕捉序列中的长期依赖关系。下面详细解释LSTM的原理:
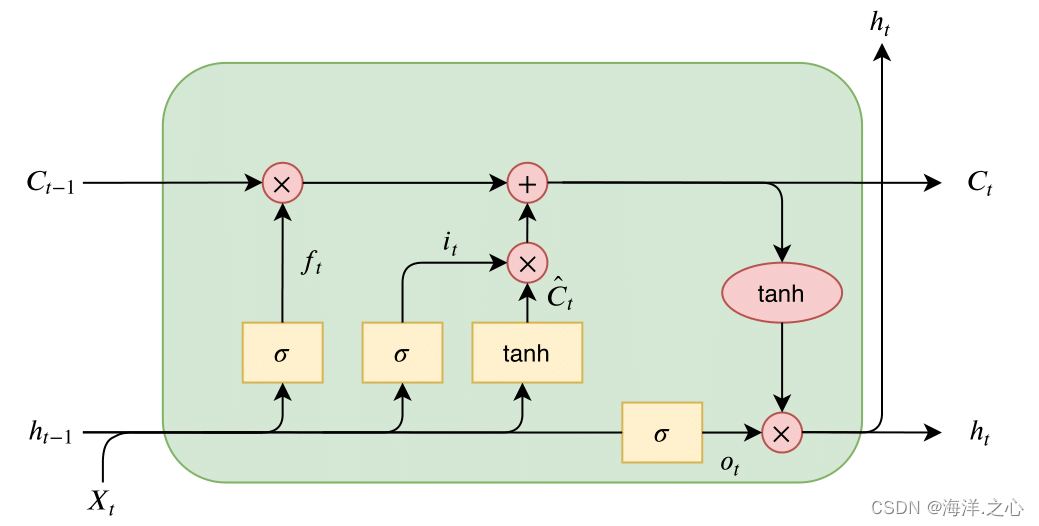
LSTM的基本结构包括三个关键的门控单元:遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate),以及一个细胞状态(Cell State)。这些门控机制可以控制信息的流动和存储,使LSTM能够更好地处理序列数据。
-
细胞状态(Cell State): 细胞状态是LSTM的核心,用于存储长期的记忆信息。在整个序列的每个时间步都会传递细胞状态。细胞状态的更新受到遗忘门和输入门的影响。
-
遗忘门(Forget Gate): 遗忘门决定了在当前时间步要从细胞状态中丢弃哪些信息。它使用sigmoid激活函数来计算一个介于0和1之间的值,表示要遗忘的信息的比例。遗忘门的输入包括前一个时间步的隐藏状态和当前时间步的输入。
-
输入门(Input Gate): 输入门决定了当前时间步要将哪些新的信息加入到细胞状态中。它通过sigmoid激活函数来计算一个权重值,表示要添加的信息的比例。然后,通过tanh激活函数计算候选值,代表要添加的新信息。输入门的输出和候选值相乘,得到要添加到细胞状态的信息。
-
更新细胞状态: 更新细胞状态是通过遗忘门和输入门的输出来更新细胞状态的。遗忘门的输出会遗忘一些信息,输入门的输出会添加一些新的信息。将遗忘门的输出和输入门的输出结合起来,就可以得到更新后的细胞状态。
-
输出门(Output Gate): 输出门决定了要从细胞状态中输出哪些信息到隐藏状态和输出。类似于遗忘门和输入门,输出门使用sigmoid激活函数来计算一个权重值,然后将细胞状态通过tanh激活函数映射到一个范围内的值,两者相乘得到当前时间步的隐藏状态。
综上所述,LSTM通过门控机制实现了对细胞状态的更新和信息的流动控制,使其能够更好地处理长序列数据中的长期依赖关系。LSTM在处理时间序列、自然语言处理、语音识别等任务中具有出色的性能,因为它能够有效地捕捉序列中的模式和上下文信息。
二、公式推导
LSTM(长短时记忆网络)的公式推导包括遗忘门、输入门、候选细胞状态、更新细胞状态、输出门和隐藏状态的计算。以下是LSTM的公式推导过程,以便更好地理解其内部运行机制。

假设当前时间步为t,细胞状态为C_t,隐藏状态为h_t,输入为x_t(可能包括当前时间步的输入和前一个时间步的隐藏状态),遗忘门为f_t,输入门为i_t,候选细胞状态为~C_t,输出门为o_t。
-
遗忘门(Forget Gate):
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = σ(W_f · [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
其中, σ σ σ表示sigmoid激活函数, W f W_f Wf和 b f b_f bf是遗忘门的权重和偏置。 -
输入门(Input Gate)和候选细胞状态(Candidate Cell State):
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t = σ(W_i · [h_{t-1}, x_t] + b_i) it=σ(Wi⋅[ht−1,xt]+bi)
~ C t = t a n h ( W C ⋅ [ h t − 1 , x t ] + b C ) C_t = tanh(W_C · [h_{t-1}, x_t] + b_C) Ct=tanh(WC⋅[ht−1,xt]+bC)
其中, W i 、 W C 、 b i W_i、W_C、b_i Wi、WC、bi和 b C b_C bC分别是输入门和候选细胞状态的权重和偏置。 -
更新细胞状态(Updated Cell State):
C t = f t ∗ C t − 1 + i t ∗ C t C_t = f_t * C_{t-1} + i_t * ~C_t Ct=ft∗Ct−1+it∗ Ct -
输出门(Output Gate):
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t = σ(W_o · [h_{t-1}, x_t] + b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
其中, W o W_o Wo和 b o b_o bo是输出门的权重和偏置。 -
隐藏状态(Hidden State):
h t = o t ∗ t a n h ( C t ) h_t = o_t * tanh(C_t) ht=ot∗tanh(Ct)
通过上述公式,LSTM可以根据输入和前一个时间步的隐藏状态,计算遗忘门、输入门、候选细胞状态、更新细胞状态、输出门和隐藏状态。这些门控机制允许LSTM有选择地保留、遗忘和更新信息,从而更好地捕捉长序列数据中的长期依赖关系。这种结构使得LSTM在许多序列数据处理任务中表现出色,特别是在需要捕捉上下文和模式的任务中。
三、梯度反向传播
LSTM的梯度反向传播(Backpropagation Through Time,BPTT)是一种训练算法,用于更新LSTM模型中的参数,以便模型能够适应训练数据并学习序列数据的模式。在BPTT中,梯度会沿着时间步反向传播,从当前时间步到第一个时间步,然后根据梯度下降法更新模型的参数。
反向传播(Backpropagation)是神经网络训练中的核心算法,用于计算损失函数对网络参数的梯度,从而通过梯度下降法更新参数。下面我将以一个简单的全连接神经网络为例,推导反向传播的公式。
假设我们有一个具有一个隐藏层的全连接神经网络,其中输入层有 n n n个神经元,隐藏层有 m m m个神经元,输出层有 k k k个神经元。对于每个神经元 i i i,其输入为 x i x_i xi,输出为 a i a_i ai,权重为 w i w_i wi,偏置为 b i b_i bi,激活函数为 s i g m o i d sigmoid sigmoid。我们使用均方误差作为损失函数 J J J。
网络结构如下:
- 输入层: x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1,x2,…,xn
- 隐藏层: z 1 , z 2 , … , z m z_1, z_2, \ldots, z_m z1,z2,…,zm
- 输出层: y 1 , y 2 , … , y k y_1, y_2, \ldots, y_k y1,y2,…,yk
推导步骤如下:
-
前向传播: 计算输入层到隐藏层的加权和,然后通过激活函数得到隐藏层的输出,最后计算隐藏层到输出层的加权和,通过激活函数得到输出层的输出。
- 隐藏层输入: z j = ∑ i = 1 n w i j x i + b j z_j = \sum_{i=1}^n w_{ij}x_i + b_j zj=∑i=1nwijxi+bj
- 隐藏层输出: a j = s i g m o i d ( z j ) a_j = sigmoid(z_j) aj=sigmoid(zj)
- 输出层输入: u k = ∑ j = 1 m v j k a j + c k u_k = \sum_{j=1}^m v_{jk}a_j + c_k uk=∑j=1mvjkaj+ck
- 输出层输出: y k = s i g m o i d ( u k ) y_k = sigmoid(u_k) yk=sigmoid(uk)
-
计算损失: 计算均方误差损失函数:
J = 1 2 ∑ k = 1 k ( y k − t k ) 2 J = \frac{1}{2}\sum_{k=1}^k (y_k - t_k)^2 J=21∑k=1k(yk−tk)2
其中, t k t_k tk是真实标签。 -
反向传播: 计算输出层到隐藏层和隐藏层到输入层的梯度,然后利用链式法则计算损失对权重和偏置的梯度。
- 输出层误差: δ k = ( y k − t k ) y k ( 1 − y k ) \delta_k = (y_k - t_k)y_k(1 - y_k) δk=(yk−tk)yk(1−yk)
- 隐藏层误差: δ j = ∑ k = 1 k δ k v j k a j ( 1 − a j ) \delta_j = \sum_{k=1}^k \delta_k v_{jk}a_j(1 - a_j) δj=∑k=1kδkvjkaj(1−aj)
-
更新参数: 使用梯度下降法更新权重和偏置:
- 权重更新: w i j → w i j − α δ j x i w_{ij} \rightarrow w_{ij} - \alpha \delta_j x_i wij→wij−αδjxi
- 偏置更新: b j → b j − α δ j b_j \rightarrow b_j - \alpha \delta_j bj→bj−αδj
其中, α \alpha α是学习率,用于控制参数更新的步幅。
这个推导过程只是一个简化的例子,实际神经网络可能更复杂,涉及到多层、多种激活函数等。然而,基本的思想是一致的:通过计算梯度并将其传播回网络,可以更新网络参数以最小化损失函数。