什么是数据探索?
简介
数据探索是在具有较为良好的样本后,对样本数据进行解释性的分析工作。它是数据挖掘较为前期的部分。数据探索并不需要应用过多的模型算法,相反,它更偏重于定义数据的本质、描述数据的形态特征并解释数据的相关性。通过数据探索的结果,我们能够更好的开展后续的数据挖掘与数据建模工作。
数据探索要弄清楚这些问题:样本数据长什么样子?有什么特点?数据之间有没有关系?样本数据是否能满足建模需求?
步骤
1、缺失值处理
data.isnull().sum()
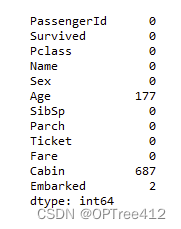
我们来查看缺失值的情况:age缺失了177个,Cabin缺失了687个,Embarked缺失了2个,
- 删除:可以根据总样本数量确定缺失值率,一般来说大部分情况下缺失值率超过80%左右考虑删除,不超过80%的酌情考虑。
- 均值/中值填充(imputation):填充是一种用估计值来补填缺失值的方法,,目标是利用从有效数据集中识别的关系来帮助评估缺失值,均值/模型/中值填充方法是最常用的方法之一,它通过对包括该变量的所有已知值的平均值或中值(定量属性)或模型(定性属性)进行分析来替换给定属性的丢失数据,可以分为两种类型:
注意:需要考虑到缺失值处理如果使用均值会受极值影响,使用中位数可能受到极度有偏数据的影响- 一般填补:通过计算该变量下所有非缺失值的平均值或中值来补全缺失值,像上一表中manpower存在缺失值,我们使用其他的非确实只来填充
- 相似样本填充:这种情况通过分别计算Male和Femal的平均值为29.7和25来分别填充male和femal的缺失值
2、number数据和非number数据
先说一下number型数据,一般比较常见的是两种情况:float型和int型,一般来说int型数据大部分情况下属于有序离散特征,比如常见的年级,1~6年级从小到大,这类特征会比较特殊一些,因为你既可以把它当作number型的连续特征也可以当作非number型的类别特征来处理,具体展开与否取决于使用的算法、特征取值的数量大小等,对于逻辑回归这类算法比较常见的做法是展开增强lr的表达能力,高维空间更容易线性可分。
(至于为什么维度越高越容易线性可分,注意这里说的是维度越高,线性可分的概率越大,不是说维度越高就一定越线性可分,https://en.wikipedia.org/wiki/Cover%27s_theorem 计算学习理论中的cover定理证明了维度越高则线性可分的概率越高,假设一个极端的情况就是n个样本当我们扩展到n+1维的时候则必然存在线性可分平面
异常值的观察与处理:
常见的就是用箱形图和小提琴图来肉眼观察
为什么要处理异常值?
异常值可以大幅改变数据分析和统计建模的结果,数据集中的异常值会有很多不利影响:
- 增加错误方差,降低模型的拟合能力
- 如果异常值是非随机分布的,它们可以降低正态性
- 与真实值可能存在偏差
- 它们也可以影响回归,方差分析等统计模型假设的基本假设。
- 为了更加深刻的理解异常值的影响,下面举一个例子对有/无异常值的数据集进行对比,观察会出现什么情况:
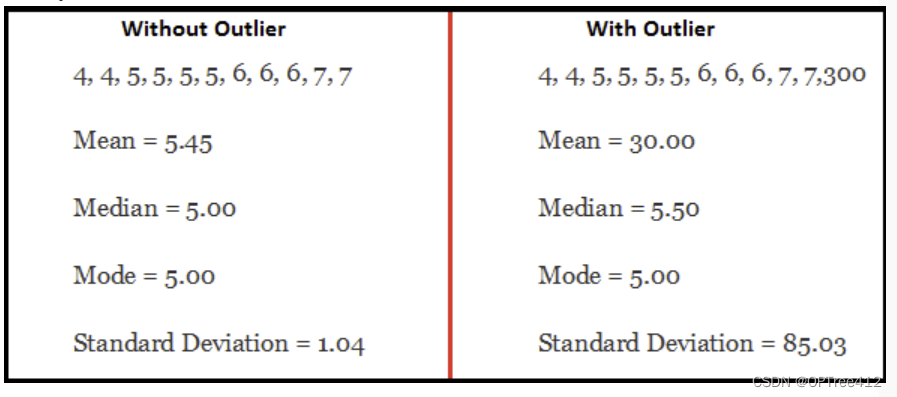
如上图所示,具有异常值的数据集,具有显著不同的平均值和标准偏差。 在无异常值的情况下平均值是5.45。 但随着异常值的加入平均值上升到30,这将彻底改变估计。
箱型图
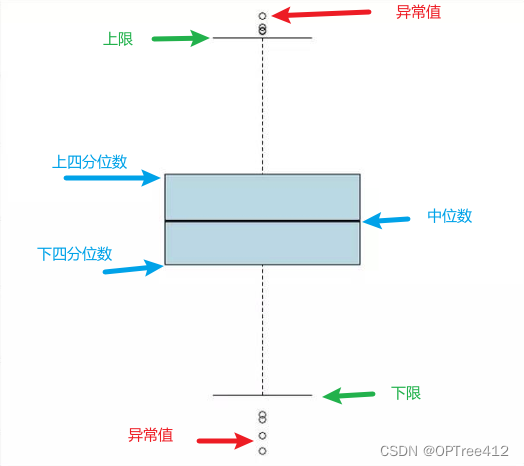
箱型图介绍
箱形图是一种用作显示一组数据分散情况资料的统计图。在各种领域也经常被使用,常见于品质管理,快速识别异常值。箱形图最大的优点就是不受异常值的影响,能够准确稳定地描绘出数据的离散分布情况,同时也利于数据的清洗。箱形图不受异常值的影响,这很重要。
箱型图样式
- 箱子的上下边界(蓝色箭头),分别是数据的上四分位数(Q3)和下四分位数(Q1)。这意味着箱子包含了50%的数据。因此,箱子的宽度在一定程度上反映了数据的波动程度。中位数(Q3)
- 在箱子的上方和下方各有一条线(绿色箭头)。有时候代表着最大最小值,有时候会有一些点“冒出去”。
箱线图和正态分布的关系
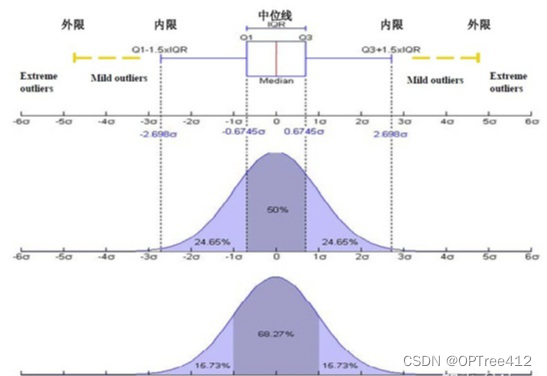
五大因数
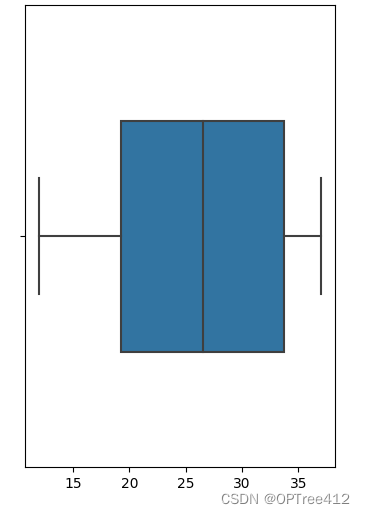
我们一组序列数为例:12,15,17,19,20,23,25,28,30,33,34,35,36,37讲解这五大因“数”。
箱型图
import matplotlib.pyplot as plt
import seaborn as sns
data = [12,15,17,19,20,23,25,28,30,33,34,35,36,37]
fig = plt.figure(figsize=(4, 6)) # 指定绘图对象宽度和高度
sns.boxplot(data,orient="v", width=0.5) # 画箱式图
plt.show()
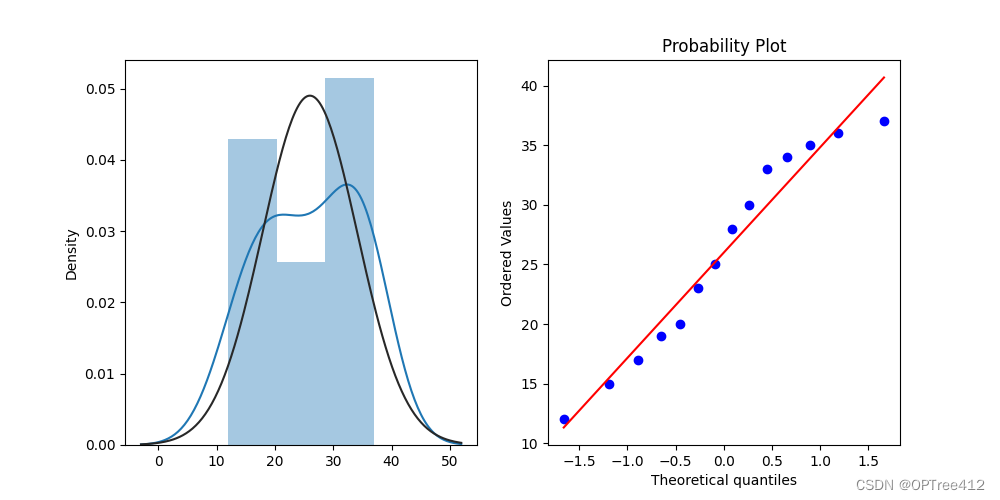
数据分布直方图和Q-Q图查看数据是否近似于正态分布
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
data = [12,15,17,19,20,23,25,28,30,33,34,35,36,37]
plt.figure(figsize=(10,5))
ax=plt.subplot(1,2,1)
sns.distplot(data,fit=stats.norm) # 数据分布直方图
ax=plt.subplot(1,2,2)
res = stats.probplot(data, plot=plt) # Q-Q图
plt.show()
1、下四分位数Q1
(1)确定四分位数的位置。Qi所在位置=i(n+1)/4,其中i=1,2,3。n表示序列中包含的项数。
(2)根据位置,计算相应的四分位数。
例:
Q1所在的位置=(14+1)/4=3.75,
Q1=0.25×第三项+0.75×第四项=0.25×17+0.75×19=18.5;
2、中位数(第二个四分位数)Q2
中位数,即一组数由小到大排列处于中间位置的数。若序列数为偶数个,该组的中位数为中间两个数的平均数。
例:
Q2所在的位置=2(14+1)/4=7.5,
Q2=0.5×第七项+0.5×第八项=0.5×25+0.5×28=26.5
3、上四分位数Q3
计算方法同下四分位数。
例中:
Q3所在的位置=3(14+1)/4=11.25,
Q3=0.75×第十一项+0.25×第十二项=0.75×34+0.25×35=34.25。
4、上限
上限是非异常范围内的最大值。
首先要知道什么是四分位距如何计算的?
四分位距IQR=Q3-Q1,那么上限=Q3+1.5IQR
5、下限
下限是非异常范围内的最小值。
下限=Q1-1.5IQR
怎么移除异常值
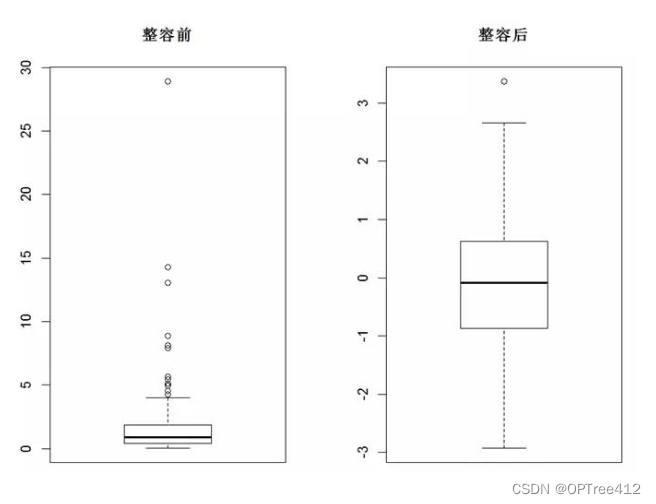
但是要注意,不是所有的数据都适合画箱线图,
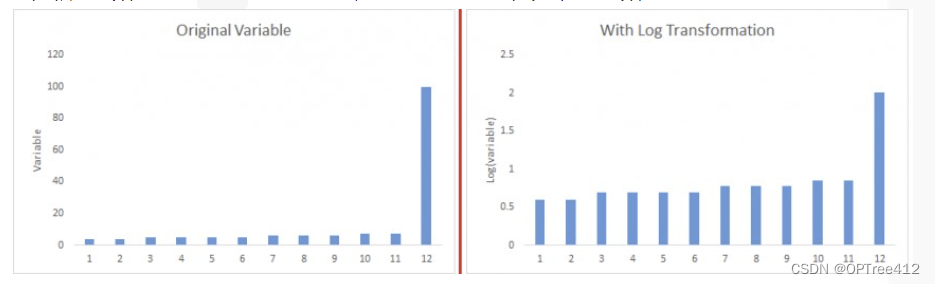
- 转换:如果你画出的箱线图是这样的,那么可以尝试做对数变换。数据取
对数log会减轻由于极值引起的变化。对于各种不对称分布、非正态分布和异方差现象等有奇效。
- 删除观察值:如果是由输入误差、数据处理误差或者异常值很小,我们可以直接将它们删除
- 填充:像处理缺失值那样,我们可以对异常点进行修改,使用平均值、中值或其他的一些填补方法。在填补之前我们需要分析异常值是自然的异常值还是人为造成的。如果是人为造成的那就可以进行填充,也可以使用预测模型来填充。
- 区别对待:如果存在大量的异常值,我们应该在统计模型中分别对待它们, 其中一个方法将它们分为两个不同的组并为两组建立单个模型,然后再将其输出合并。
特征工程
什么是特征工程
特征工程是从现有数据中提取更多有效信息的手段,在不增加数据的前提下,如何让现有的数据更有用。我们需要将这些信息挖掘出来,让我们的模型变得更好。这个从数据中提取有价值的信息的小练习就是特征工程。
特征工程主要分为2步:
- 变量的转换
- 变量/特征的创建
变量的转换
在数据建模过程中,变换是指通过函数来替换变量,例如,通过平方/立方根或对数x替换变量x就是一个变换。
换句话说,转换是一个改变变量的分布或关系的过程。
- 我们想改变一个变量的
比例或标准化一个变量的值,以便更好的理解。 如果数据具有不同的缩放比例(scale),那么这个转换是必须的并且这个转换并不会更改变量分布。 - 当我们将数据从复杂的非线性关系转化为线性关系时,与非线性或弯曲关系相比,变量之间存在线性关系更容易理解, 转换有助于我们将非线性关系转换为线性关系。 散点图常被用来查找两个连续变量之间的关系,通这些转换也可以改善预测的结果。
log是一种常用的转换方式。
对称的分布要好于倾斜的分布,因为它容易解释和做出推论,一些建模技术需要变量服从正态分布,所以,当我们有一个偏斜的分布,我们可以进行减少倾斜的变换。 对于向右倾斜分布,我们取变量的平方/立方根或对数。对于向左倾斜的分布,我们取变量的平方/立方或指数。
变量转换的一般方法
有各种各样的变量转换方法, 如前面所讨论的其中一些包括平方根,立方根,对数,合并,倒数等等。 下面来看看这些方法的细节,突出说明这些转换方法的利弊:
- log:对变量取对数,常被用来在分布图上更改变量分布形状。 它通常用于向右倾斜的分布。这种方法的缺点是,它也不能应用于零值或负值的变量。
- 平方/立方根:变量的平方根和立方根具有对变量分布有波形的影响。但它并没有对数变换那么重要。 立方根变换有自己的优势, 它可以应用于负值包括零。平方根可以应用于包括零的正值。
- 分箱(离散):常被用来对变量进行分类,它可以基于原始值、百分比或频率等对变量进行转换,具体需要基于具体的业务,例如,我们可以将收入分为三类:高,中,低。 我们还可以根据多个变量对变量进行分箱。