爬虫实战的JS逆向,就像是做侦探。很多时候,我们要尝试不同方式和手段寻找线索,不能放过蛛丝马迹,通过仔细观察和比较,然后顺藤摸瓜,找到加密入口。再调试JS代码的时候,需要保持清晰的目标和方向感,大胆尝试,才能获得结果。如果用好以下技巧,将能给我们带来眼前一亮,以及柳暗花明又一村的感觉。
抓包:
大部分网站通过浏览器就可以完成抓包,针对复杂的可以考虑利用Fiddle、Charlse等三方软件。
加密入口:
1.搜索关键词
比如“sign”,”sign:“, ”sign :“, ”sign=“,”sign =“
另外JSON.parse(, JSON.stringify, encrypt(, decrypt(都是可选关键词,有时会有意想不到的效果。
应该说搜索关键词可以解决80%以上的加密入口。
但不是万能的。
2、XHR断点,也是一个不错的选择。
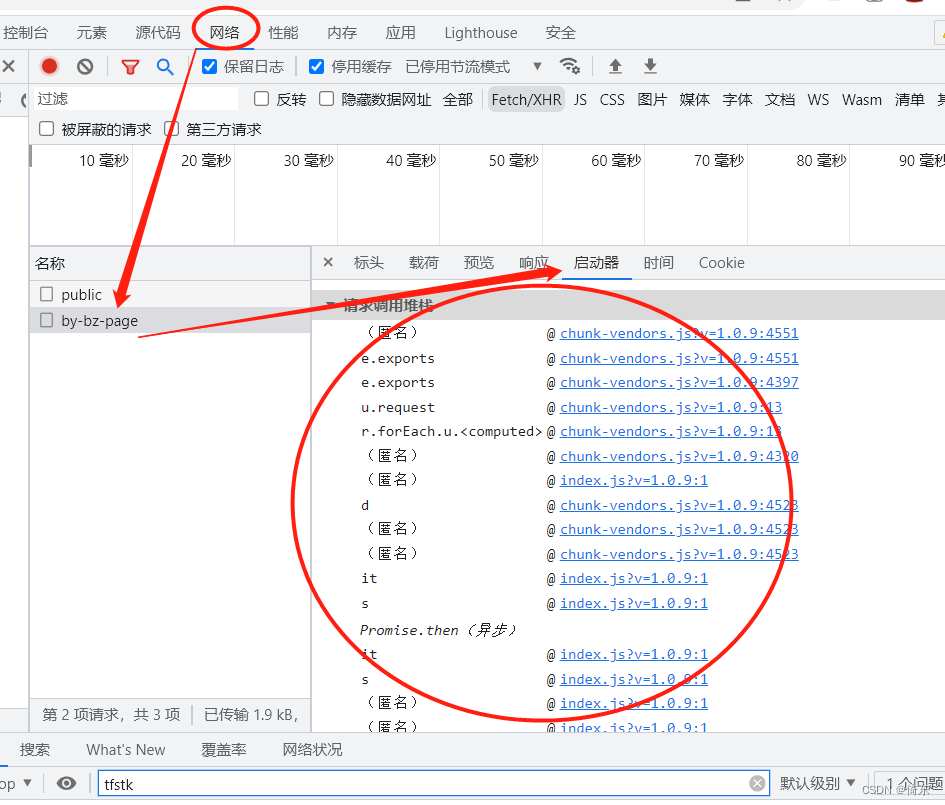
3、浏览器调试界面下点击Network下的某个请求,然后在右边的启动器中调试请求调用堆栈。
4、事件监听器断点,例如画布,脚本等。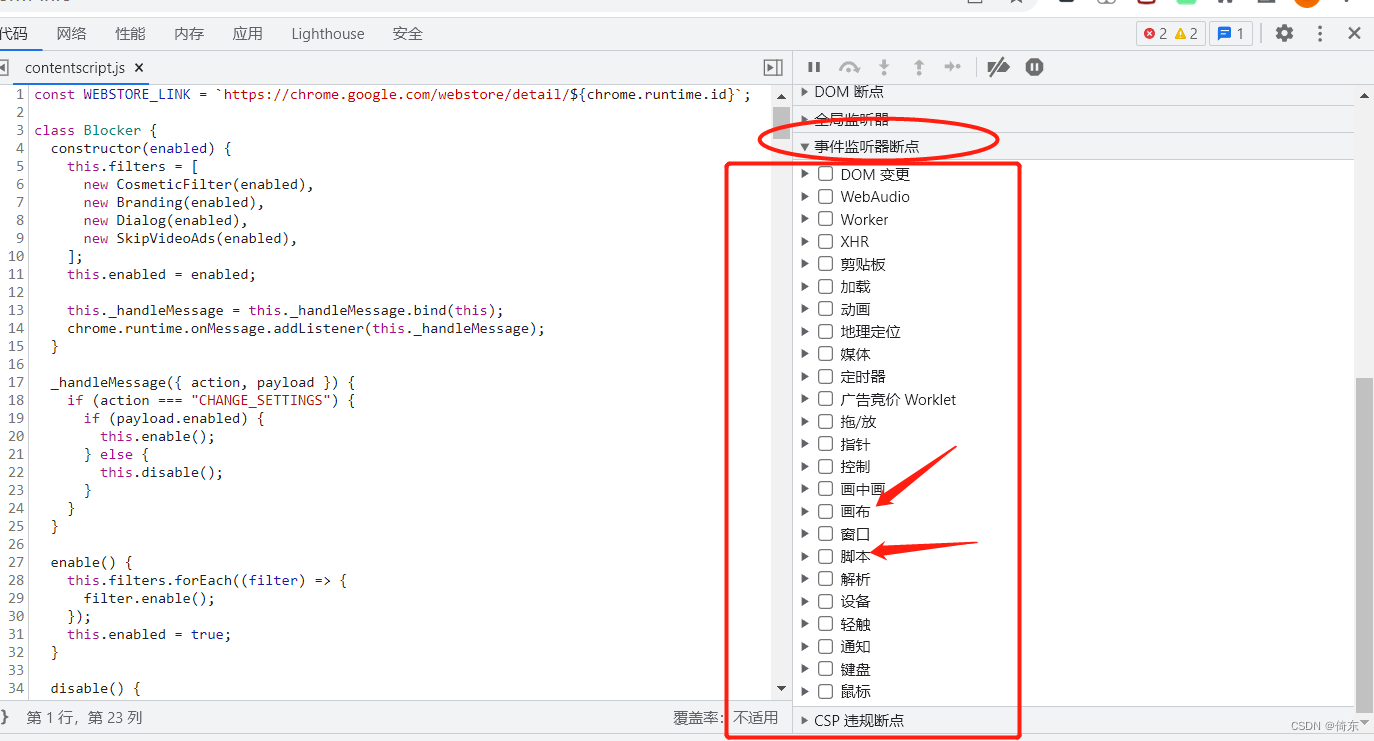
5、代码调试:本地覆盖、代码段都是可以尝试的,还有全扣代码到Pycharm,然后尝试调用某个函数来实现加密或解密。
出现报错时,根据提示补充环境或者直接从浏览器调试中获得数据,把某个参数写死。
有些报错,可以尝试直接注释掉相应代码,不会影响结果。
如果JS代码可以得到结果但是程序不会终止,或者Python调用代码时一直得不到结果,很有可能是JS代码里有定时器函数作祟,可以hook以下函数,比如:
null=function(){}
setTimeout=null
setInterval=null
6、验证加密结果是否与浏览器一致时,可以尝试hook Math.random、Date.getTime、Date.Now等函数,类似上述hook定时器的代码。
Math.random=function(){return 0.123456}
Date.getTime=function(){return 0.123456}
7. 无限debugger,右键,点击永不停止。
不断更新中......
也欢迎各位大佬把你们的经验之谈留言在评论区,我来补充完善,分享给大家。