花下猫语:Cython 是一门结合了 Python 及 C 语言特性的编程语言,常用于编写 Python 扩展模块,是一种常见的提升 Python 性能的手段。古明地觉大佬连载的《Cython从入门到精通》系列,十分推荐!这里分享的文章,介绍了 Cython 最新版本的相关特性。
来源:古明地觉的编程教室
关于 Cython,我们目前已经详细介绍了它的语法以及使用方式,不过版本是 0.29。而前一段时间,Cython 发布了 3.0 版本,那么它和 0.29 版本相比都发生了哪些变化呢?
本次就来聊一聊其中的一些比较大的变化。

变量支持非 ASCII 字符

在 0.29 以及之前的版本中,Cython 要求变量名必须是 ASCII 字符,但在 3.0 版本中,这一限制被取消了。
先来看看 0.29 版本。
# 文件名:cython_test.pyx
cpdef str 你好世界():
return "Hello World"如果我们尝试编译这个文件,那么会报错。
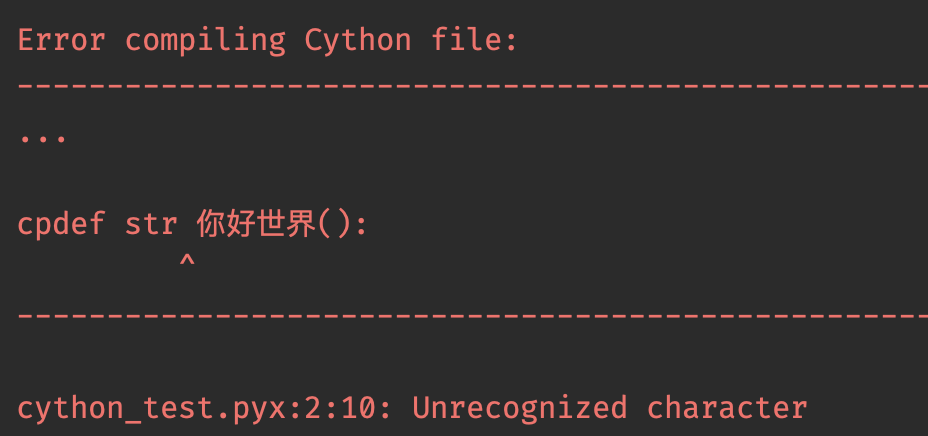
告诉我们标识符不合法,但如果使用 Cython3.0 编译的话,那么结果没有任何问题。
使用 3.0 版本。
import pyximport
pyximport.install(language_level=3)
import cython_test
print(cython_test.你好世界()) # Hello World可以看到使用 3.0 版本的 Cython 没有任何问题,所以 0.29 和 3.0 之间的一个区别就是 3.0 支持使用非 ASCII 字符(比如中文)定义变量。
但说实话,这个功能没太大用,因为在开发中也基本不会用中文给变量命名。

开启 generator_stop

对于生成器而言,return 的本质就是向外抛出一个 StopIteration 异常,代表这个生成器结束了。
def gen():
yield 1
yield 2
yield 3
return "结束啦"
g = gen()
print(g.__next__()) # 1
print(g.__next__()) # 2
print(g.__next__()) # 3
try:
g.__next__()
except StopIteration as e:
print(e.value) # 结束啦但在 Python 3.7 版本之前,我们也可以手动引发一个 StopIteration。
def gen1():
yield 1
yield 2
yield 3
return "结束啦"
def gen2():
yield 1
yield 2
yield 3
raise StopIteration("结束啦")在 3.7 以前,上面的两个生成器函数是等价的,但这就产生了一个问题。举个例子:
def gen():
yield 1
yield 2
# 只是单纯地抛出一个 StopIteration
# 但在 Python 3.7 之前,它等价于 return "middle value"
raise StopIteration("middle value")
yield 3
return "结束啦"所以为了消除这样的误会,从 Python 3.7 开始,结束生成器一律通过 return。至于生成器内部引发的 StopIteration 则会被转化为 RuntimeError。
而在 Python 3.7 之前如果想开启这一功能,需要通过 __future__ 来实现。
from __future__ import generator_stop然后重点来了,如果你使用的是 Cython 3.0,并且以 py3 的模式编译,那么即使解释器版本低于 3.7,这一功能默认也是开启的。
说实话,这个功能对我们来说,也没有什么用。

默认以 py3 的模式编译

在 Cython 0.29 的时候,默认是以 Python2 的语义编译 .pyx 的,如果希望以 Python3 的语义进行编译,那么需要将 language_level 参数指定为 3,否则就会抛出警告。

但从 Cython 3.0 开始,默认则是以 Python3 的语义进行编译,如果希望兼容 Python2,那么需要显式地将该参数指定为 2。
除了极端情况,我们完全不需要兼容 Python2,因为会失去 Python3 的很多优秀特性。

__init_subclass__ 的问题

之前介绍过 __init_subclass__ 这个魔法方法,它在一些简单的场景下可以替代元类,举个例子。
class Base:
def __init_subclass__(cls, **kwargs):
"""
钩子函数,当该类被继承时会自动触发此函数
注意:cls 不是当前的 Base,而是继承 Base 的类
"""
for attr, val in kwargs.items():
type.__setattr__(cls, attr, val)
class Girl(Base, name="古明地觉", address="地灵殿"):
pass
print(Girl.name) # 古明地觉
print(Girl.address) # 地灵殿需要注意的是,__init_subclass__ 这个函数是被 classmethod 隐式装饰的,当然我们也可以显式地装饰它。
class Base:
@classmethod
def __init_subclass__(cls, **kwargs):
for attr, val in kwargs.items():
type.__setattr__(cls, attr, val)在 Python 代码中,上面两种做法都是可以的。但如果是在 Cython 里面,则必须要显式装饰,否则就会出现参数错误,因为 Cython 不会帮你隐式装饰。
下面举例说明:
# 文件名:cython_test.pyx
class Base:
def __init_subclass__(cls, **kwargs):
for attr, val in kwargs.items():
type.__setattr__(cls, attr, val)我们将 Base 类的定义移动到了 pyx 文件中,然后来导入它。
import pyximport
pyximport.install(language_level=3)
from cython_test import Base
try:
class Girl(Base):
pass
except TypeError as e:
print(e)
"""
__init_subclass__() takes exactly 1 positional argument (0 given)
"""告诉我们 __init_subclass__ 需要一个位置参数,如果想解决这一点,那么使用 classmethod 显式装饰一下即可。
但以上都是 Cython 0.29 版本以及之前才会出现的问题,如果是 Cython 3.0,那么表现和纯 Python 代码是一样的,也会隐式装饰。

类型注解延迟解析

先说一下类型注解,Python 从 3.5 开始支持类型注解。
class A:
pass
def foo(a: A, b: str, c: int):
pass
print(foo.__annotations__)
"""
{'a': <class '__main__.A'>, 'b': <class 'str'>, 'c': <class 'int'>}
"""像 FastAPI、Pydantic 等框架都高度依赖 Python 的类型注解功能,然后需要注意的是,类型注解在定义函数的时候就被解析了,所以下面这种做法就会出问题:
class A:
@classmethod
def create_instance(cls) -> A:
pass
"""
NameError: name 'A' is not defined
"""定义类 A,它内部有一个 create_instance 类方法,通过类型注解表示该方法会返回一个 A 的实例对象。但这个类在定义的时候却报错了,原因就是 Python 在解析的时候,A 这个类还没有来得及创建。
所以从 Python3.7 开始,便又引入了类型注解延迟解析:
# 3.7 开始支持类型注解延迟解析,但必须导入 annotations
# 而 3.10 开始则不再需要,会变成默认行为
from __future__ import annotations
class A:
# 解释器在解析 foo 的时候,B 还没有定义
# 不过没有关系,因为类型注解会被延迟解析
def foo(self, b: B):
pass
class B:
pass
# 启用延迟类型注解后,Python 会把类型提示存储为字符串
# 所以 value 不再是 <class '__main__.B'>,而是字符串 "B"
print(A.foo.__annotations__) # {'b': 'B'}
# 当调用 typing.get_type_hints() 时才进行解析
import typing
print(typing.get_type_hints(A.foo)) # {'b': <class '__main__.B'>}如果你不想使用 __future__ 的话,那么也可以换一种方式。
class A:
def foo(self, b: "B"):
pass
class B:
pass
print(A.foo.__annotations__) # {'b': 'B'}
import typing
print(typing.get_type_hints(A.foo)) # {'b': <class '__main__.B'>}在声明的时候直接指定为字符串即可,这样即便 Python 版本低于 3.10,也是可以的。
然后类型注解在 Cython 中也是支持的,只不过在 Cython 中我们更习惯使用 C 风格定义变量。
# 在定义 C 级变量的时候,必须使用 C 风格进行变量声明
cdef str name = "古明地恋"
# 注意:不可以写成 cdef name: str = "古明地恋",这是错误的语法
# 但在函数中是可以的
# `类型 变量` 属于 C 风格,比如 list data
# `变量: 类型` 属于 Python 风格,比如 target: int
cpdef Py_ssize_t search(list data, target: int):
if target in data:
return data.index(target)
return -1然后是返回值的问题,如果使用 cdef、cpdef 定义函数,那么返回值类型声明必须写在 cdef、cpdef 后面。
cpdef list foo():
return [1, 2, 3, 4, 5]
# 但 cpdef foo() -> list: 这么做是不合法的,会编译错误
"""
Return type annotation is not allowed in cdef/cpdef signatures
"""
# 事实上 cdef 和 cpdef 后面如果不指定类型,那么默认是 object
# 这种做法只能用在 def 定义的函数中
def bar() -> tuple:
return 1, 2, 3最后在 Cython 中同样也支持延迟类型注解。
# 文件名: cython_test.pyx
class A:
def foo(self, b: "B"):
pass
class B:
pass如果是 Cython 0.29,那么必须写成 "B",否则会出现 NameError。但从 Cython 3.0 开始,即使不写成字符串的形式,也没有任何问题。
但说实话,在 Cython 中声明变量,最好使用 C 风格的方式。也就是类型 变量的方式,而不要使用变量: 类型。

仅限位置参数

在 Python 中,可以强制要求某些参数只能通过关键字参数或位置参数的方式进行传递。
# 这里的 * 表示参数 c 和 d 必须通过关键字参数的方式传递
# 所以即便非默认参数 d 在默认参数 c 的后面也没有关系
def foo(a, b, *, c=123, d):
pass
# / 要求它前面的参数(这里是 a 和 b) 必须通过位置参数的方式传递
def bar(a, b, /, c, d):
pass但 Cython 在 0.29 的时候,只支持仅限关键字参数(*),不支持仅限位置参数(/)。而 Cython 在 3.0 的时候,这两者则都支持。

赋值表达式

这是 Python3.8 新增的一个功能,可以在表达式当中完成赋值。
import re
date = "2020-03-04"
match = re.search(r"(\d{4})-(\d{2})-(\d{2})", date)
if match is not None:
year, month, day = match.groups()
print(year, month, day) # 2020 03 04
# 通过赋值表达式,可以将赋值和比较一步完成
if (match := re.search(r"(\d{4})-(\d{2})-(\d{2})", date)) is not None:
year, month, day = match.groups()
print(year, month, day) # 2020 03 04赋值表达式是我个人比较喜欢的一个功能,但 Cython 在 0.29 以及之前是不支持的,从 3.0 开始才支持。

放宽对装饰器的语法限制

在 Python 3.9 之前,我们像下面这种方式使用装饰器是不允许的。
from functools import wraps
class Button:
def __init__(self, n):
self.n = n
def deco(self, func):
@wraps(func)
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
buttons = [Button(i) for i in range(1, 10)]
@buttons[0].deco
def foo():
pass这么做会出现语法错误:
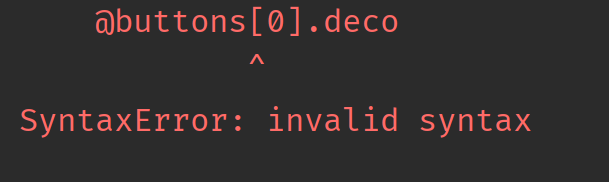
我们必须这么做:
@eval("buttons[0].deco")
def foo():
pass
# 或者
button = buttons[0]
@button.deco
def bar():
pass@buttons[0].deco 这种方式从 Python3.9 才开始支持,同样的,Cython 0.29 版本也不支持在 .pyx 中使用这种语法,但 Cython 3.0 开始则支持了。
如果使用 Cython 3.0,那么即使 Python 版本低于 3.9 也是可以的。因为 pyx 文件的语法解析是由 Cython 编译器完成的,和 Python 解释器无关。

异常传播

在介绍 Cython 异常处理的时候说过,如果函数的返回值类型是 C 类型,那么函数里面的异常会被无视掉。
cpdef Py_ssize_t foo():
raise ValueError("抛个异常")在函数中我们手动引发了一个 ValueError。
import pyximport
pyximport.install(language_level=3)
import cython_test
cython_test.foo()
print("正常执行")
"""
ValueError: 抛个异常
Exception ignored in: 'cython_test.foo'
Traceback (most recent call last):
File "...", line 5, in <module>
cython_test.foo()
ValueError: 抛个异常
正常执行
"""但是在调用的时候,异常并没有中止程序。
补充一点:所谓的异常,本质上就是解释器发现程序在某一步出错了,然后将异常信息写到 stderr 当中,并中止程序,比如索引越界。
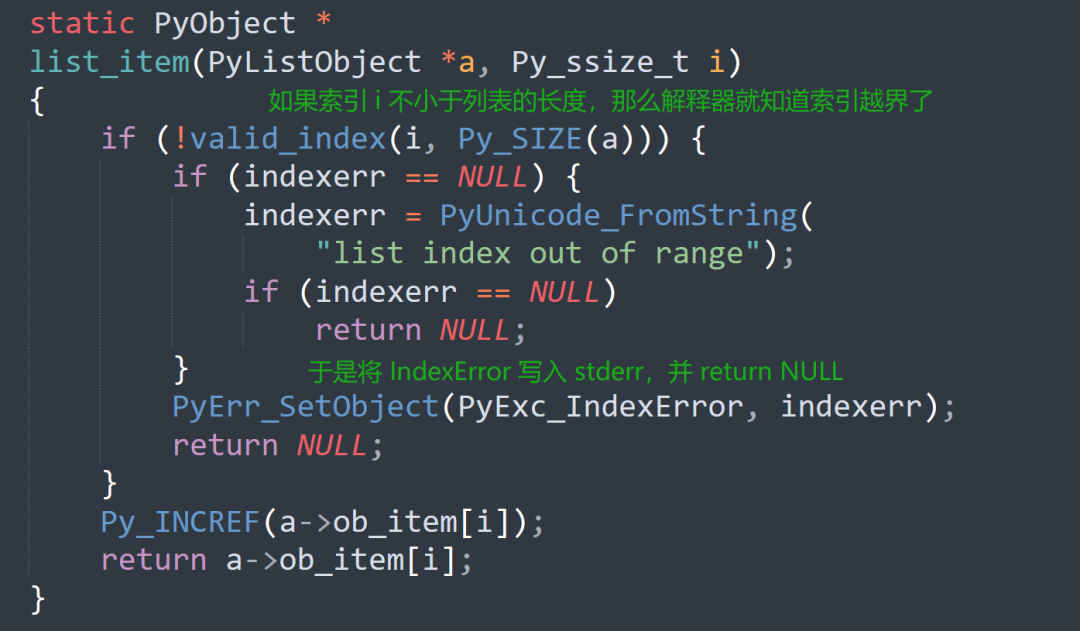
但对于 Cython 而言,当返回值是 C 的类型时,异常会被忽略掉。如果希望它能像 Python 一样,将异常抛出来,那么需要通过 except 子句。
cpdef Py_ssize_t foo() except ? -1:
raise ValueError("抛个异常")此时异常就可以正确抛出来了,这也是我们希望的结果。但在 Cython3.0 的时候,即使不使用 except 子句,异常也会正常抛出。
不过注意:except 子句只能用 cdef、cpdef 定义的函数中,并且只有返回值是 C 的类型时,才需要使用 except 子句。如果返回值是 Python 类型,那么是不需要使用 except 子句的(异常依旧会正常抛出),使用了反而会编译错误。
比如将上面的 Py_ssize_t 改成 list 重新编译一下,看看报的什么错。

告诉我们使用 except 子句的函数返回了一个 Python 对象。
可能有人好奇这是什么原因呢?首先底层的 C 函数如果返回的是 PyObject *,那么正常执行时,返回值一定会指向一个合法的 Python 对象。如果执行出错,那么返回值就是 NULL。所以解释器在看到返回值是 NULL 时,就知道一定出错了,于是将 stderr 中的异常输出出来提示开发者即可。
如果返回的是 C 的类型,比如返回一个索引。如果函数执行出错,那么会返回 -1(作为哨兵)。但解释器在看到 -1 时,它并不知道这个 -1 是函数执行出错时返回的,还是正常执行、返回值本身就是 -1。所以此时需要检测异常回溯栈,看看里面有没有异常发生。
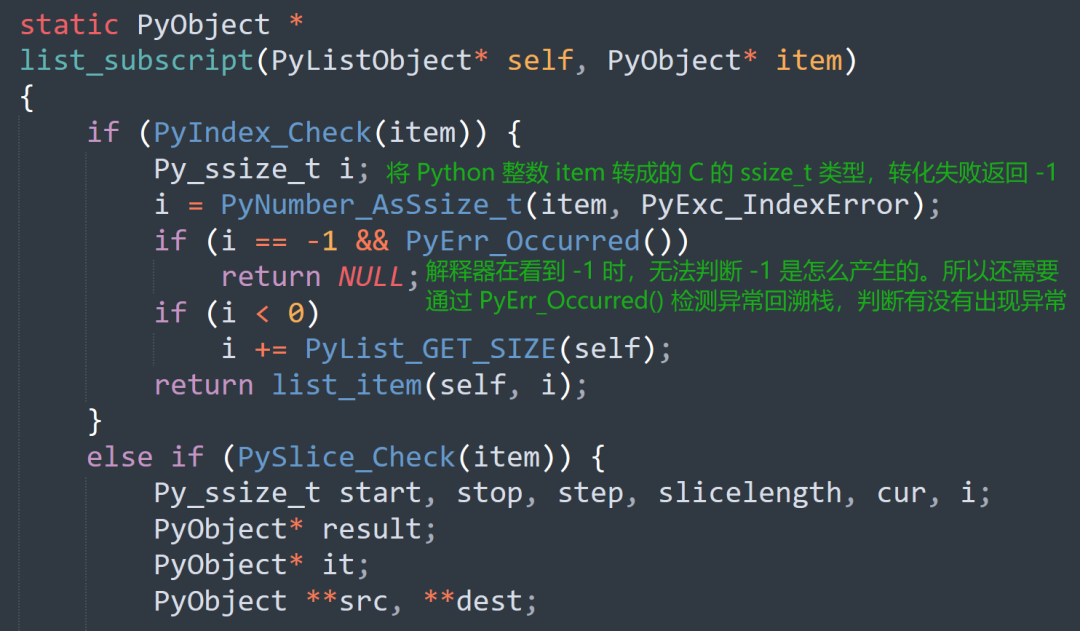
对于 Cython 而言也是如此,如果返回值是 Python 类型,那么根据返回值即可判断有没有出现异常。但如果返回的是 C 类型,那么通过返回值就无法判断是否有异常发生,而通过 except ? -1 就是告诉 Cython:返回值是 C 类型时,你还要去检测一下异常回溯栈,如果有异常,你要抛出来。
以上是 Cython0.29 版本时的做法,但从 Cython3.0 开始,我们就不再需要 except 子句了。即使返回值是 C 类型,Cython 也会检测回溯栈。
不过问题来了,如果我们能确保一个函数不会发生异常,那么可不可以不去检测是否有异常发生呢?答案是可以的。
cpdef Py_ssize_t foo() noexcept:
pass通过 noexcept 子句告诉 Cython,这个函数不会出现异常,所以生成的 C 代码不要做任何有关异常的处理。但如果出现异常了,那么异常会被忽略掉。
再次强调:无论是 except 还是 noexcept,针对的都是返回值为 C 类型的函数,如果返回值是 Python 类型,那么不需要这两个子句。因为对于 Python 类型而言,通过返回值(是否为 NULL)即可判断是否有异常发生,而不需要花费额外的代价去检测异常回溯栈。

自定义 Numpy ufunc

Numpy 的 ufunc(通用函数)指的是能够对数组进行元素级别操作的函数,ufunc 是向量化操作的核心,它能够使我们在不编写循环的情况下对数组的每个元素进行计算。
而在 Cython3.0 的时候新增了一个装饰器 cython.ufunc,可以很轻松地自定义 Numpy 的 ufunc。
cimport cython
import numpy as np
# 装饰成 Numpy 函数时,必须使用 cdef 定义
@cython.ufunc
cdef int add(x, y):
return x + y
arr1 = np.array([1, 2, 3])
arr2 = np.array([1, 2, 3])
print(add(arr1, arr2))
print(np.add(arr1, arr2))
"""
[2 4 6]
[2 4 6]
"""
# 因为规定了返回值是 int 类型,所以浮点数会被强制转化为整数
# 如果希望返回值和输入的 Numpy 数组保持一致,那么将返回值类型指定为 object 即可
arr1 = np.array([1.1, 2.2, 3.3])
arr2 = np.array([1.1, 2.2, 3.3])
print(add(arr1, arr2))
print(np.add(arr1, arr2))
"""
[2 4 6]
[2.2 4.4 6.6]
"""
@cython.ufunc
cdef str to_string(x):
return str(x) * 3
print(to_string(np.array([1, 2, 3])))
"""
['111' '222' '333']
"""当前逻辑都比较简单,直接使用 Numpy 提供的函数即可,但如果需求比较复杂,自定义 ufunc 就方便多了。
cimport cython
import re
import numpy as np
@cython.ufunc
cdef tuple find_ymd(x):
if (match := re.search(r"(\d{4})-(\d{2})-(\d{2})", x)) is not None:
y, m, d = match.groups()
else:
y, m, d = -1, -1, -1
return int(y), int(m), int(d)
dates = np.array([
"2021-01-01",
"2022-02-02",
"2023-03-03",
"0123456789"
])
print(find_ymd(dates))
"""
[(2021, 1, 1) (2022, 2, 2) (2023, 3, 3) (-1, -1, -1)]
"""怎么样,是不是很简单呢?定义的函数只需要处理在元素级别的操作,通过 ufunc 装饰之后调用,会自动作用在数组的每个元素上。
注意:cython.ufunc 只能装饰 cdef 定义的 C 函数,但是装饰之后可以被外界的 Python 访问。当然啦, Numpy 本身也提供了定义 ufunc 的操作,可以了解一下。
另外 Numpy 底层是 C 实现的,在 Cython 使用 Numpy 同样依赖它提供的 C API,但有一部分 API 在现如今的 Numpy 中已经被废弃了(但还可以用)。
而 Cython3.0 默认仍在使用老的 API,只是编译的时候会抛出警告。
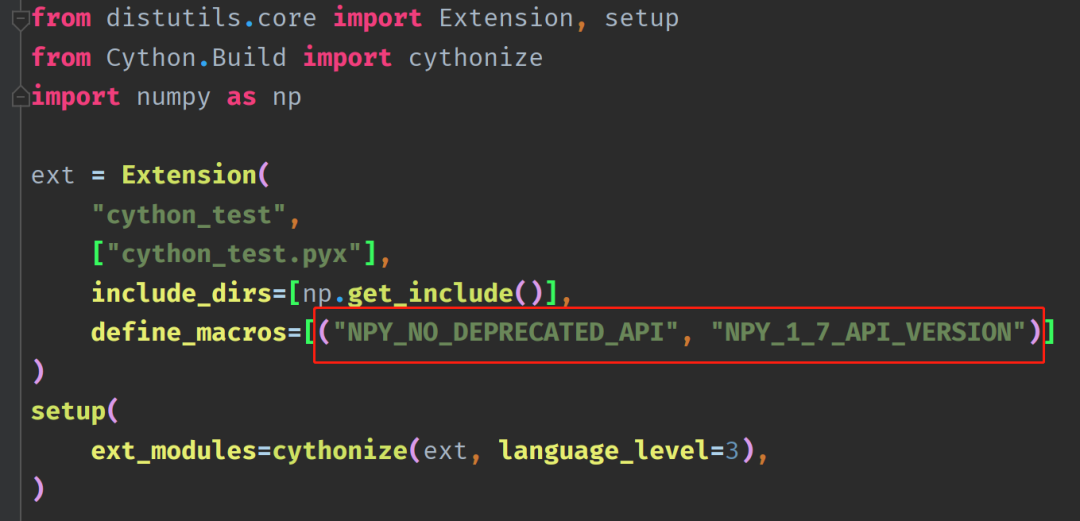
可以通过 NPY_NO_DEPRECATED_API 宏,来消除这些警告,并让 Cython 不再使用那些在 Numpy 1.7+ 版本中已经被废弃的 API。

变量私有化

在 Python 的类中,对于以双下划线开头、非双下划线结尾的属性,解释器会自动在开头加上 _类名,表示它是一个私有属性(尽管不是真正的私有)。但对于 Cython 定义的静态类而言却不是这样,它定义的名称都是所见即所得,不会在背后做一些花里胡哨的工作。
cdef class A:
# 外界可以访问、也可以修改
cdef public str __name
# 外界只能访问、但无法修改
cdef readonly int __age
# 外界即无法访问、也无法修改
cdef str address
def __init__(self):
self.__name = "古明地觉"
self.__age = 17
self.address = "地灵殿"对于静态类而言,属性是否私有,是通过 public 和 readonly 控制的,我们测试一下。
import pyximport
pyximport.install(language_level=3)
import cython_test
a = cython_test.A()
print(a.__name)
"""
古明地觉
"""
a.__name = "古明地恋"
print(a.__name)
"""
古明地恋
"""
print(a.__age)
"""
17
"""
try:
a.__age = 18
except AttributeError as e:
print(e)
"""
attribute '__age' of 'cython_test.A' objects is not writable
"""
# __name 和 __age 虽然以双下划线开头
# 但对于静态类而言,名称是所见即所得
try:
a.address
except AttributeError as e:
print(e)
"""
'cython_test.A' object has no attribute 'address'
"""
# address 属性因为没有使用 public 或 readonly 对外暴露
# 所以它是绝对的私有,如果不想让外界访问,那么外界是绝对访问不到的以上是 0.29 版本的 Cython,但如果是 Cython3.0,对于那些双下划线开头的属性,会像 Python 一样,将名字偷偷给你换掉。
比如我们将上面的文件用 3.0 版本的 Cython 编译一下,然后进行测试。
import pyximport
pyximport.install(language_level=3)
import cython_test
a = cython_test.A()
# 在 Cython3.0 的时候,和 Python 表现一样
# 这里需要通过 _A__name 和 _A_age 访问
print(a._A__name)
"""
古明地觉
"""
print(a._A__age)
"""
17
"""
# 真正的私有,依旧无法访问
try:
a.address
except AttributeError as e:
print(e)
"""
'cython_test.A' object has no attribute 'address'
"""个人觉得这一点变化虽然比较大,但对我们的影响并不大,因为我们不会在外界使用双下划线开头(非双下划线结尾)的属性或方法。

volatile 修饰符

在 C 中有一个变量修饰符 volatile,它负责在多线程的时候保证变量可见性,什么意思呢?
我们知道 CPU 会将数据从内存读到自身的寄存器中,但相对于寄存器来说,CPU 从内存读取数据的速度还是不够快。所以在寄存器和内存之间还存在着缓存,也就是 L1、L2、L3 Cache。
数据会按照从内存、L3 缓存、L2 缓存、L1 缓存、寄存器的顺序进行传输,同理 CPU 在读数据的时候也会先从 L1 缓存当中找,没有则去 L2 缓存,还没有则去 L3 缓存,最后是内存。
每次从更低级的缓存或内存中读取数据时,都会将数据复制到更高级的缓存中,以便下次能够更快地访问。并且每个核心独有一个 L1 和 L2 缓存,所有核心共用一个 L3 缓存,但这样就会存在一些变量可见性问题。
假设有一个变量 n,它会被两个线程同时读取,这两个线程在两个核上并行执行。因为缓存原理,变量 n 可能分别在两个核的 L2 或 L1 缓存,这样读取速度最快,但会存在一个线程修改之后另一个线程不知道情况,因为 L1 和 L2 缓存是每个核心独有的。
所以 volatile 关键字就是负责预防这种情况,对于被 volatile 修饰的的变量,每次 CPU 需要读取时,都至少要从 L3 读取,并且 CPU 计算结束后,也立刻回写到 L3 当中。这样读写速度虽然减慢了一些,但是避免了变量在每个 core 的 L1、L2 缓存中被单独操作而其它 core 不知道的情况。
而从 Cython 3.0 开始,已经支持 volatile 修饰符了,在 0.29 以及之前是不支持的。
# volatile 修饰的必须是 C 类型的变量
cdef volatile int a = 123如果不和 C/C++ 的线程进行交互,那么 volatile 基本用不上。

小结

以上就是 Cython3.0 的一些比较重大的变化,我觉得有必要单独说一说。至于 Cython 内部还有一些微小变化,但由于不影响我们的实际使用,这里就不说了,感兴趣可以查阅官网。
在编码层面 Cython0.29 和 Cython3.0 差别并不是太大,升级之后不需要做过多调整。当然啦,如果新特性你用不上的话,那么也可以不升级。
总之赋值表达式、自定义 Numpy ufunc,以及 volatile 修饰符的支持,还是值得体验的。

Python猫技术交流群开放啦!群里既有国内一二线大厂在职员工,也有国内外高校在读学生,既有十多年码龄的编程老鸟,也有中小学刚刚入门的新人,学习氛围良好!想入群的同学,请在公号内回复『交流群』,获取猫哥的微信(谢绝广告党,非诚勿扰!)~
还不过瘾?试试它们
如果你觉得本文有帮助
请慷慨分享和点赞,感谢啦!