文章目录
一、相关文章
有关pytorch中自动求导的文章
初步认识:
https://www.cnblogs.com/cocode/p/10746347.html
这两篇比较详细:
https://www.cnblogs.com/charleechan/p/12255191.html
https://zhuanlan.zhihu.com/p/51385110
举例子:
http://blog.sina.com.cn/s/blog_573ef4200102xcxr.html
二、大致思路
(一)主要原理
Pytorch会对变量的计算过程形成一个动态计算图(DAG)记录计算的全过程。自动求导时,即根节点对叶子节点进行自动求导。
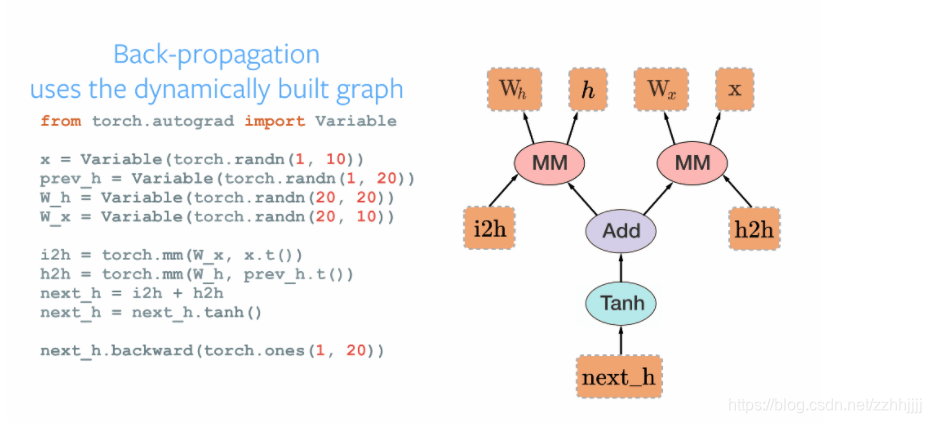
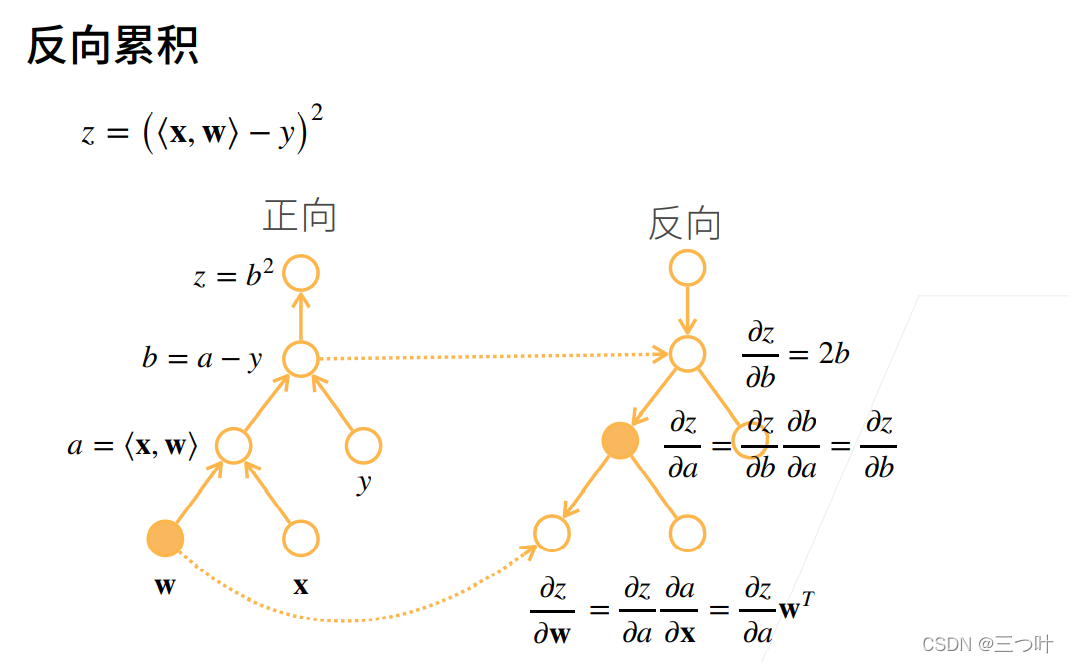
(二)关键过程
- 要追踪所有对于某张量的操作,设置其 .requires_grad 为True即可。
- 要计算对某张量的梯度,得到某Tensor后对其调用 .backward(),这个张量的所有梯度将会自动积累到 .grad 属性。
- 要阻止张量跟踪历史记录,可以调用 .detach() 方法将其与计算历史记录分离,并禁止跟踪它将来的计算记录。
(三)以z对x求导为例
- 初始化时设置x的requires_grad为True
- 调用z.backward()
- 查看x.grad即可
注意:
需要保证x为 计算图叶子节点(可通过x.is_leaf查看),z为计算图根节点
若非叶子节点,可以通过.retain_grad()保存梯度
(四)对 z.backward() 的一点解释
- 如果你要求导的是一个标量,那么gradients默认为None,所以前面可以直接调用 z.backward() 就行了
- 如果你要求导的是一个张量,那么gradients应该传入一个Tensor。
一般来说,我是对标量求导,比如在神经网络里面,我们的loss会是一个标量,那么我们让loss对神经网络的参数w求导,直接通过loss.backward()即可。
但是,有时候我们可能会有多个输出值,比如loss=[loss1,loss2,loss3],那么我们可以让loss的各个分量分别对x求导,这个时候就采用:
loss.backward(torch.tensor([[1.0,1.0,1.0,1.0]]))
如果你想让不同的分量有不同的权重,那么就赋予gradients不一样的值即可,比如:
loss.backward(torch.tensor([[0.1,1.0,10.0,0.001]]))
(五) 将某些计算移动到计算图之外
有时,我们希望将某些计算移动到记录的计算图之外。 例如,假设 y 是作为 x 的函数计算的,而z则是作为y和x的函数计算的。 想象一下,我们想计算 z 关于 x 的梯度,但由于某种原因,我们希望将 y 视为一个常数, 并且只考虑到 x 在 y 被计算后发挥的作用。
在这里,我们可以分离y来返回一个新变量 u,该变量与y具有相同的值, 但丢弃计算图中如何计算y的任何信息。 换句话说,梯度不会向后流经 u 到 x。 因此,下面的反向传播函数计算 z = u ∗ x z=u*x z=u∗x 关于 x 的偏导数,同时将u作为常数处理, 而不是 z = x ∗ x ∗ x z=x*x*x z=x∗x∗x关于x的偏导数。
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
---------------------
tensor([True, True, True, True])
三、遇到问题
问题1:非计算图叶子节点
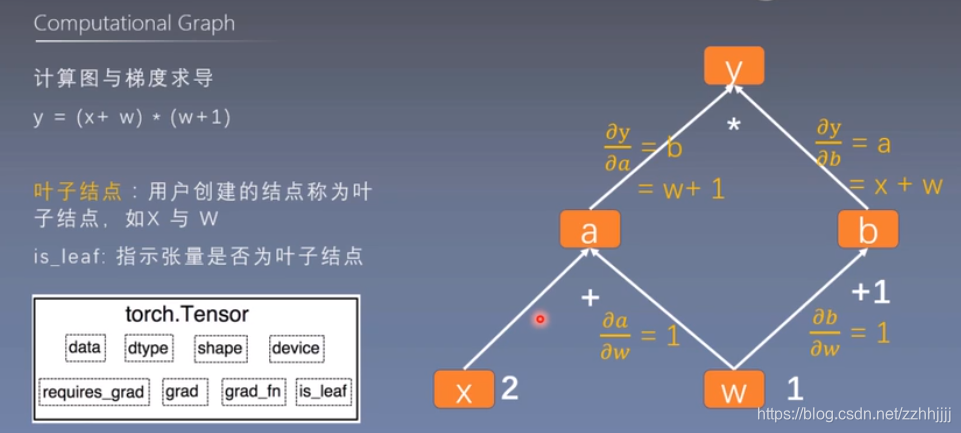
x = torch.ones(1, requires_grad=True)*3
y = torch.ones(1, requires_grad=True)*4
z = torch.pow(x, 2) + 3*torch.pow(y, 2)
z.backward()
print(x.grad) # x = 3 时, dz/dx=2x=2*3=6
print(y.grad) # y = 4 时, dz/dy=6y=6*4=24
报错:
UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won’t be populated during autograd.backward(). If you indeed want the gradient for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations.
原因:x,y在最开始有一步乘法的计算,已经不再是计算图的叶子节点
x = torch.ones(1, requires_grad=True)*3
y = torch.ones(1, requires_grad=True)*4
print(x.is_leaf)
------
False
通过查看x的is_leaf属性,为False
初始化时,去掉乘法操作,is_leaf为True
x = torch.ones(1, requires_grad=True)
y = torch.ones(1, requires_grad=True)
print(x.is_leaf)
------
True
解决方案(具体问题具体分析,下面只是一些可行方案):
解1:
设置retain_grad(),可以保留梯度
import torch
from torch.autograd import Variable
x = Variable(torch.ones(1)*3, requires_grad=True)
y = Variable(torch.ones(1)*4, requires_grad=True)
print(x.is_leaf)
x = torch.ones(1, requires_grad=True)*3 # 初始化是有乘法运算,此时x已经不是计算图叶子节点
y = torch.ones(1, requires_grad=True)*4
print(x.is_leaf)
x.retain_grad()
y.retain_grad()
z = torch.pow(x, 2) + 3*torch.pow(y, 2)
z.backward()
print(x.grad) # x = 3 时, dz/dx=2x=2*3=6
print(y.grad) # y = 4 时, dz/dy=6y=6*4=24
解2:
from torch.autograd import Variable
x = Variable(torch.ones(1)*3, requires_grad=True)
y = Variable(torch.ones(1)*4, requires_grad=True)
print(x.is_leaf)
z = torch.pow(x, 2) + 3*torch.pow(y, 2)
z.backward()
print(x.grad) # x = 3 时, dz/dx=2x=2*3=6
print(y.grad) # y = 4 时, dz/dy=6y=6*4=24
-----------
True
tensor([6.])
tensor([24.])
解3:
with torch.no_grad(): 加上 原地操作
import torch
x = torch.ones(1, requires_grad=True)
y = torch.ones(1, requires_grad=True)
with torch.no_grad():
x *= 3
y *= 4
z = torch.pow(x, 2) + 3*torch.pow(y, 2)
z.backward()
print(x.is_leaf)
print(x)
print(y)
print(x.grad)
类似问题:https://stackoverflow.com/questions/65532022/lack-of-gradient-when-creating-tensor-from-numpy
问题2:梯度不自动清零(.grad.zero()的使用)
import torch
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
for i in range(3):
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
结果:
tensor([5.])
tensor([10.])
tensor([15.])
添加w.grad.zero_()后:
import torch
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
for i in range(3):
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
w.grad.zero_()
结果:
tensor([5.])
tensor([5.])
tensor([5.])