grep (缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹配行。
语法 Usage: grep [OPTION]... PATTERNS [FILE]...
例子:
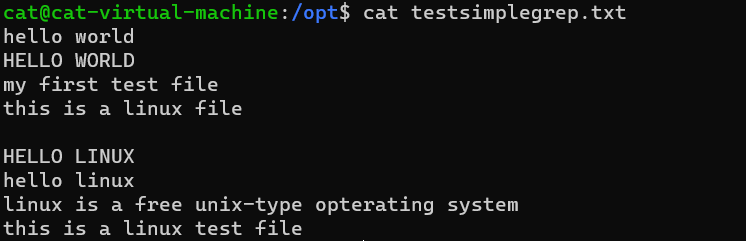
这是一个简单的文件,里面一些简单的内容。
输出hello 所在行的内容

grep 'hello' testsimplegrep.txt
忽略大小写输出带有hello的行
grep -i 'hello' testsimplegrep.txt

Pattern selection and interpretation(可选的模式以及解释)

-E 和 -e:
-e 只能传递一个参数,如果需要传递多个参数需要些多次-e
例如: grep -e 'HELLO' -e 'test' testsimplegrep.txt

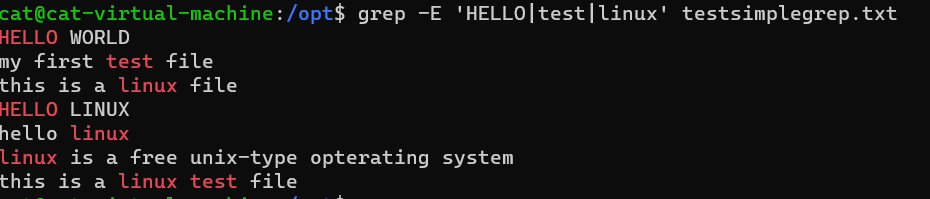
如果使用-E, 多个参数之间用|隔开即可
语法: grep -E 'HELLO|test|linux' testsimplegrep.txt | 表示或者 (or) 的意思
grep -F的使用:
查看文件内容如下
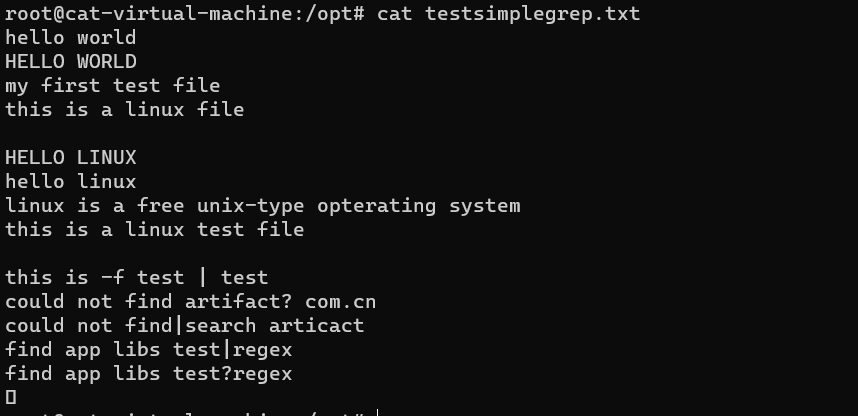
grep -F 表示将grep命令视为使用固定字符串(fixed strings)而不是正则表达式来匹配模式。在这种模式下,grep会按照严格的文本匹配进行搜索,而不是使用正则表达式中的特殊字符。这通常比正则表达式更快速。
在使用-F选项时,需要注意模式字符串中不能包含正则表达式的元字符,例如圆括号、星号等。grep会将模式字符串视为普通文本来匹配。
先来看一下用-E 的结果:grep -E 'test|rege' testsimplegrep.txt

再来看下-F 的结果: grep -F 'test|rege' testsimplegrep.txt

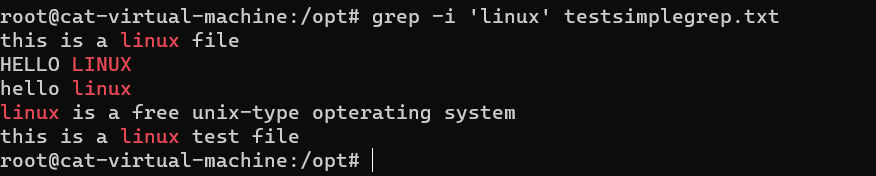
-i:忽略大小写
grep -i 'linux' testsimplegrep.txt, 看到大写LINUX 和小写linux 都查出来了
-n:显示关键字所在的行
grep -n 'linux' testsimplegrep.txt

-c: 显示关键字显示的次数
grep -c 'linux' testsimplegrep.txt

Context control:
-B, --before-context=NUM print NUM lines of leading context
-A, --after-context=NUM print NUM lines of trailing context
-C, --context=NUM print NUM lines of output context
用于在给定文件或文件集中搜索模式或文本字符串,并显示包含该模式的行以及指定数量的匹配行之前的行数。
grep 命令的 -B 选项表示“before(之前)”,并指定在匹配行之前要显示多少行。
grep -i 'unix-type' testsimplegrep.txt -B 1

当B = 1时,查询结果后多显示1行,当B =2 时,查询结果后多显示俩行。

-A (after)同理,显示结果后,往后显示n行;
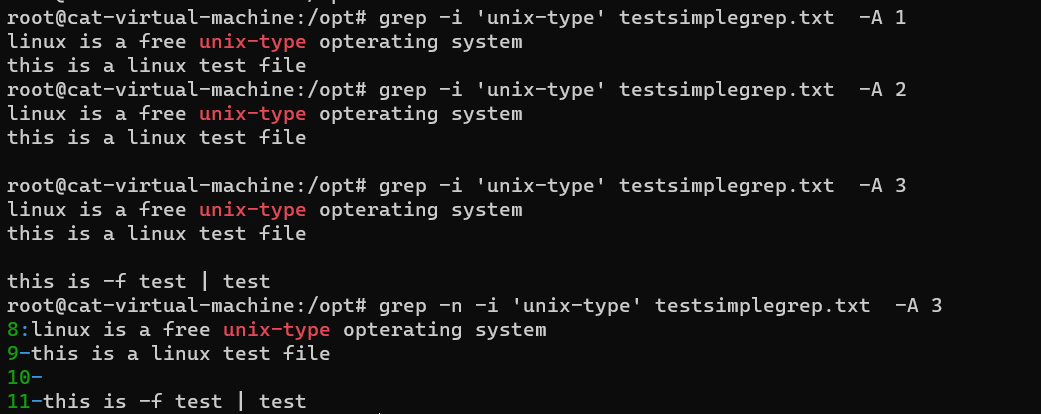
-C 是从查询到的结果,上下文显示n行
grep -n -i 'unix-type' testsimplegrep.txt -C 1: 上线文显示1行
grep -n -i 'unix-type' testsimplegrep.txt -C 2 上线文显示2行
