C语言的数据类型
一、概述
编程语言为抽象这个物理世界提供了依据,其中对于描述物理世界的情况提供了一个叫做数据类型的名字,这种数据类型是我们人类能够认识的东西,就像数字,字母,字符之类的。
C语言中也提供了数据类型这种说法,就像下面的图片里面猴子,我们用C语言描述图片里面的猴子,就可以用 C语言里面的 字符串 数据类型来描述:
char * imageDescription = "两只猴子,一个大猴子,一个小猴子";

下面是我对 C语言里面的数据类型的理解使用参悟。
二、基础数据类型
1. 整数
C语言里面的整数类型标识符就是:int, long, long long,short,就行 0,-1,-23,4235 等等,也就是不带小数的整数。最常用的是 int。 long, long long适合大场景的整数 ,相对于整数只是存的数值范围比较大而已,属性基本一致,后面我都是用int来举例代表整数的。short 就是使用时相对较小的索引范围值而已。在后面会有一个专门的表去归纳这些变量的内存模型。
C语言里面的整数用处很多,因为计算内部都是用二进制表示数据的,里面的数据本质上都是整数的,浮点数也是用二进制整数去描述的。整数有很多的性质都十分有用,比如整数除法的结果也是整数等等。整数在计算之外的最大用处就是索引,在数组、循环、判断、地址索引等场景都是用的整数去做的。
1. 计算
声明一个 int 变量也很简单的,直接是 int 变量名;如果没初始化默认是给的一个随机值,一定要记得初始化哈。因为在像循环的时候,总是得从一个有效的开始索引进行索引,如果没设置好值,这就会出问题,就会出现段错误。
C语言整数一个很有用的计算就是 除法, 而且 取余 运算只能 整数 哦
就像下面,除法会把除出来的数的小数部分给抛掉,只保留整数部分
// 声明变量并初始化,初始化就使用 =
int i = 0;
i = 1 / 2; //i = 0
取余 运算也是很简单的
int i = 11;
i = i / 2; //i = 0
对应 最经典便是 个十百位
#include <stdio.h>
int main()
{
int numA, numB, numC, numD;
printf("请输入一个三位数: ");
scanf("%d", &numA);
numA = (int)numA;
numD = numA % 10;
numC = (numA / 10) % 10;
numB = numA / 100;
printf("这个三位数的个十百分别为:%d %d %d",numD, numC, numB);
return 0;
}
2. 索引
数组的本质其实就是一个数据表,一维数组就是单行表,二维数组就是多行表,整数在索引的时候其实就可以当一个表示位置的强大工具。
就像下面的一个二维数据表就是用的 行 - 列 来确定位置的,这里用浮点数明显就是不行的。
表[ 行索引 ][ 列索引 ] 来确定一个位置的值
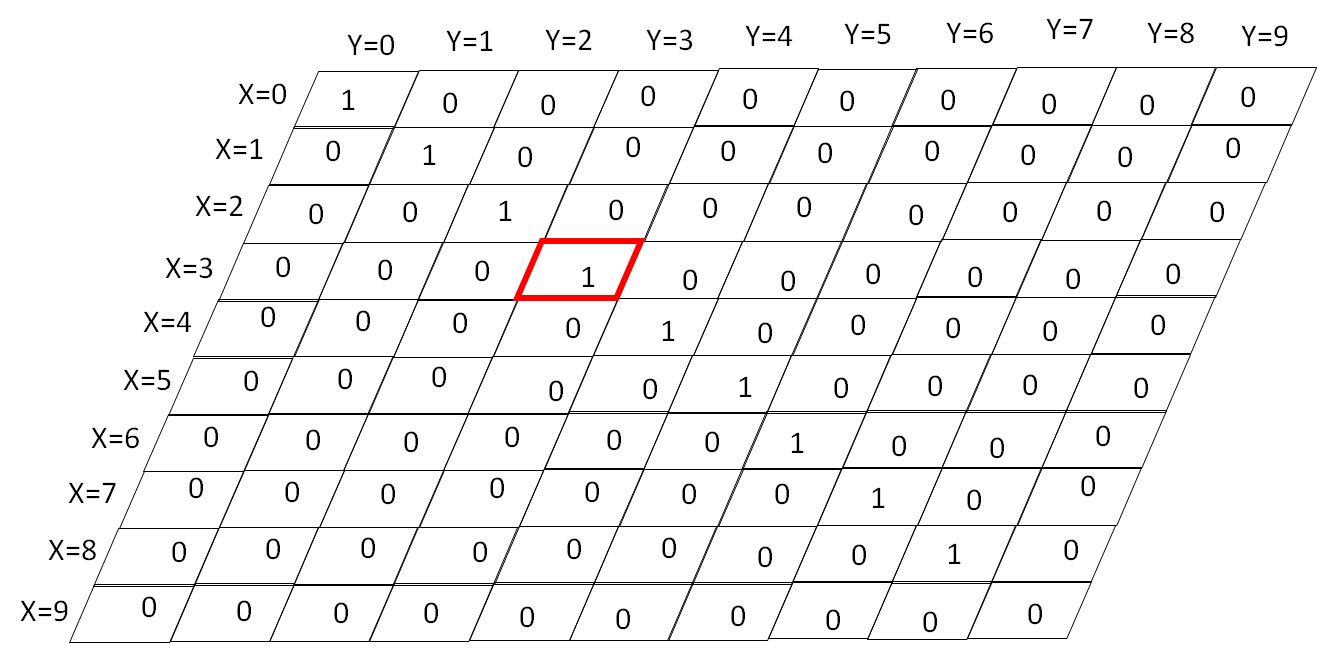
int martx[3][3] = {
{
0, 1, 2}, {
4, 5, 6}, {
7, 8, 9}};
对于上面的 martx 数组, 我们要取得 第 2 行,第 1 列的数据就是使用 martx[1][0] 。
最灵活的莫过于 对这个 索引 的变化。
2. 浮点数
浮点数其实就是 小数,对了科学计数法的写法也是浮点数类型哈。
在C语言里面的 浮点数的类型就是 float, double 两个类型,其实就是一个精度低,精度高的区别,一般使用double的多些。
对于这个的使用其实并不会太过多的考虑,但是要考虑到一个就是在 他和其他数据运算的时候,有他就会让数据的类型往浮点数靠
就像 7+7.32 的结果 就是浮点型
但 7+7 的结果就是 整型
3. 字符
4. 字符串
5. 指针
指针就是一个数据类型,专门存放其他变量的地址的一个类型。指针是一个很大内容,有兴趣可以看看我的笔记
指针入门基础
C的动态内存管理
指针与函数
指针和数组
指针与字符串
三、特殊数据类型
1. 枚举
enum
2. 共用体
uion
2. struct结构体
struct结构体 C语言给我们提供的一个开放的定义自己的 数据类型 的一个强大工具,我们可以用 struct 去描述一个数据结构,在这个结构里面用的就是上面提到的数据类型,当然也是包括在结构体内再存结构体的。
举个例子:我们用一个结构体描述一个位于屏幕上的圆的数据。
这个圆有半径,圆有相对屏幕左上角坐标位置,圆还有外围圆的线宽,外围线的颜色,内圆的填充颜色等数据。
1. 定义结构体
struct 结构体名称{内部类型} ;
在使用的时候就是把 struct 结构体名称 当成一个自定义的类型使用就好,就像 int 一样的使用。
那定义一个这样的圆可以这么写
// 颜色结构体
struct color{
short red;
short green;
short blue;
};
// 位置
struct point{
int x;
int y;
}
// circule
struct circule{
int Radius;
struct point Point;
struct color OuterColor;
struct color InnerColor;
}
但是这种写法可能有点夯长,那我们就可以用 typedef 来把这个结构体命名一样,命名成我们更加可读的 变量类型名称。
typedef 类型 自己想要的类型名
可以就把上面的代码改写一下
struct color{
short red;
short green;
short blue;
};
//定义别名
typedef struct color ST_Color;
// 位置
struct point{
int x;
int y;
};
typedef struct point ST_Point;
// circule
struct circule{
int Radius;
ST_Point Point;
ST_Color OuterColor;
ST_Color InnerColor;
};
typedef struct circule ST_Circule;
当然我们还可以直接用 typedef 去简化定义,在什么结构体的时候就给命别名
typedef struct color{
short red;
short green;
short blue;
} ST_Color;
2. 使用结构体
结构体的使用同样也是很简单的,就和普通的类型一样,只是在访问结构体内部成员的时候要用 ‘.’ 符号访问而已
下面我就声明一个圆形的结构体
// 声明结构体
ST_Circule m_circlue;
ST_Circule *p_circle = NULL;
// 初始化结构体
m_circlue.Radius = 10;
m_circlue.Point = {
0,0}; //这种是是用列表初始化
m_circlue.InnerColor = {
12,23,34};
m_circlue.OuterColor.blue = 12; //这种是每个单独的去初试化
m_circlue.OuterColor.red = 23;
m_circlue.OuterColor.green = 34;
//在使用结构体指针的时候,为了区分是指针所有还是用的变量名索引,在访问结构体成员变量的时候会用 -> 来区分
p_circle = &m_circlue;
printf("m_circlue-Radius: %d", p_circle->Radius);
3. 内存布局
结构体内存大小理论上是和其内部所有成员内存大小之和。而且成员的内存排列顺序一定是定义顺序。

理论上讲结构体的各个成员在内存中是连续存放的,和数组非常类似,但是,结构体的占用内存的总大小不一定等于全部成员变量占用内存大小之和。在编译器的具体实现中,为了提高内存寻址的效率,各个成员之间可能会存在缝隙。
就像 ST_Circule 的理论大小是 24 字节。就是连续的。
在结构体里面其实是并非完全的内存连续,就是其实是有内存对齐的。
默认的字节对齐原则
首先引出一个概念自然对齐(naturally aligned),是指数据的起始地址是该数据类型大小的倍数。结构体的对齐是指其中的每个数据成员都是自然对齐的,要达到这个效果可能需要在成员之间进行必要的字节填充。比如一下struct:
struct Struct {
char c1; // 1B
uint64_t n1; // 8B
};
在默认情况下需要在c1后面填充7个字节,才能保证n1是自然对齐的。此时sizeof(DemoStruct)==16
C/C++ struct通常的对齐原则如下:
保序:
在保序的基础上保证每个成员是自然对齐的,如果前一个成员紧接着的地址不满足对齐要求,则增加填充。
最后一个成员后面也可能会增加填充,这样能保证创建struct数组时,数组中的每个struct仍然是对齐的。
结构体嵌套时,递归的按照结构体中最大的那个成员对齐。(注意不是最大的结构体,而是结构体总最大的那个成员)
pragma pack(1)抹除填充
我们可以通过#pragma pack(1)来强制struct不增加填充,比如如下struct:
#pragma pack(1)
struct DemoPackStruct {
char c1; // 1B
uint64_t n1; // 8B
};
由于强制改成了1字节对齐,所以上述结构体中无需填充。此时sizeof(DemoPackStruct)==9。
这么做的主要目的就是节省内存,以损失访存效率为代价。可能还有一个作用是方便数据结构的网络传输,比如直接免去序列化过程将整个数据结构通过网络发送,但这么做并不保险,因为不同机器之间存在字节序的问题(大端/小端,endianness)。
当然也可以给指定更大的pack值,以强制struct按更大的字节对齐,比如以下数据结构 sizeof(DemoPack2Struct)==10:
#pragma pack(2)
struct DemoPack2Struct {
char c1; // 1B
uint64_t n1; // 8B
};
使用pack需要注意以下几点:
pack(n)的值必须是2的指数,比如n可以是1,2,4等
pack只能用于减少sturct的padding,不能用于增加padding。比如一个struct中最大的成员是8字节,那么pack(16)不起任何作用。
#pragma pack()影响这条语句之后的所有struct声明,可通过pack(push), pack(pop)保存和恢复之前默认的pack