
本文约3600字,建议阅读5分钟本文介绍了阿里淘宝搜索的最新工作模块。大家好,我是kaiyuan。最近大模型LLM的各类信息有种乱花渐欲迷人眼的感觉,刷几篇KDD'23的文章冷静一下。
今天分享阿里淘宝搜索的最新工作,发表在KDD'23上:Rethinking the Role of Pre-ranking in Large-scale E-Commerce Searching System[1]。【整体思路非常清晰样,用的评估指标、模型框架等,同样可以应用在向量召回模块】。

论文对电商搜索粗排模块进行重新定位,提出了新的离在线一致性更高的评价指标,并基于此优化全域多目标学习框架(All-Scenario-based Multi-Objective Learning framework,ASMOL ),AB测试结果GMV提升1.2%。
目前大厂的搜索系统基本是多阶段级联架构,如下图,主要由召回、粗排、精排、重排等部分组成。
召回:该模块主要目标是从海量候选池中尽可能召回所有相关的商品,通常会有多种召回路,比如文本召回、个性化X2I召回、U2I向量召回、多模态召回、图召回等等;商品量级一般从 ~ ;
粗排:位于全链路承上启下的关键位置,目标是对召回的商品先做一次过滤,避免给精排太大的压力;商品量级一般从 ~
精排/重排:模型相对更复杂,更关注对商品的精准预估排序,再通过机制策略后最终展示给用户;商品量级一般从 ~

粗排作为承上启下的模块,受限于算力等因素,模型主要有两种演进路线:
双塔结构:以DSSM为代表,用户侧和商品侧信息分别喂入不同的DNN,得到各自embedding后点积作为打分。双塔分离的结构好处是在面对海量候选集时可以保证线上快速serving,但同时受限于双塔,无法使用一些更复杂的交叉特征和交叉建模,导致模型表达能力弱。关于双塔更多细节推荐塔哥的文章:久别重逢话双塔[2]
交叉结构:另一种路线是精排的轻量级退化版本,通过特征选择、知识蒸馏、网络结构压缩等方式达到交互模型作用在粗排,如FSCD、COLD、AutoFAS等。
虽然模型结构有不同的演进路线,但粗排的目标近年来一直是比较明确的: 聚焦在如何对齐精排的排序能力上 ,一些评估指标也以AUC、精排一致性为主。甚至有些团队的粗排模型训练数据仍和精排保持一致,这会带来严重的SSB问题(下文会具体介绍)。同时, 疯狂地拟合精排,虽然短期会带来部分收益,但从长期看会带来严重的马太效应 。
其实,跳出这个怪圈,我们没必要把粗排架得那么高,粗排模块只需要 从大量的候选中找到一个效率最优的商品集合即可 ,对这些商品的排序只是一个附加要求(不然要精排干啥呢 对吧)。
重定义评估指标:全域Hitrate
做过召回的同学都清楚,离在线指标对齐是一个非常头疼的问题。由于召回模块位于整体搜索链路的最底层,中间存在各个模块的复杂逻辑,到最终曝光给用户,离线指标的收益很难与在线转化指标很好地对应。
粗排也同样面临这样的问题,介绍全域hitrate之前,先来看看常规的评价指标。粗排位于全链路的中间,需要同时考虑 「召回->粗排」 以及 「粗排-> 精排」 两阶段的损失,才能做好承上启下的工作,单看任何一部分都是片面的。
启下:粗排->精排损失衡量
精排更注重商品的排序精度,因此以下粗排指标也类似
AUC :曝光空间下的AUC,有购买行为的商品作为正例。淘宝搜索一页请求会出10个商品,通常使用AUC@10来衡量,精排模型也使用该指标,因此可以借此评估粗排和精排的一致性程度;
粗排hitrate@10 :粗排越头部的商品能带来更多搜索场景内成交,说明粗排排序能力更强,与精排能力更接近;
曝光商品粗排总分与精排效率分数的NDCG/逆序对 :对相同商品集合,粗排打分和精排打分的排序差异,差异越小,说明两者越接近。
承上:召回->粗排损失衡量
承上阶段,粗排需要更多关注商品集合的好坏,这与召回的目标是一致的,通常使用hitrate@k来衡量。
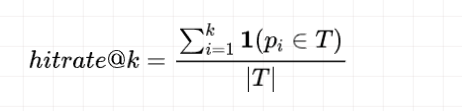
分母是所有正例集合(可以是点击/加购/购买等), 分子是粗排top商品集合和正例集合的交集。
但不同于各召回分支,曝光商品完全来自于粗排输出,因此粗排输出集合的hitrate肯定是100%,在该指标上,新模型肯定是打不过线上基线的。
全域hitrate:场景内纠偏
既然场景内hitrate(In-Scenario Purchase Hitrate@k,ISPH@k )是有偏的,一个直观的想法就是补充更多其他场景的正例来纠偏,称为全域hitrate(All-Scenario Purchase Hitrate@k,ASPH@k),具体地,可以引入推荐、广告、购物车等非搜索场景成交的样本。
但由于非搜索场景不存在query,作者通过相关性作为关联条件,将用户在场景外的成交item,关联到用户在场景内的query上,且要求场景内query和场景外成交item组成的query-item对满足一定的相关性条件。
基于上述的指标(ISPH@k和ASPH@k),作者对淘宝搜索各个模块的现状进行了分析和对比,也可由此探索优化的上限空间。
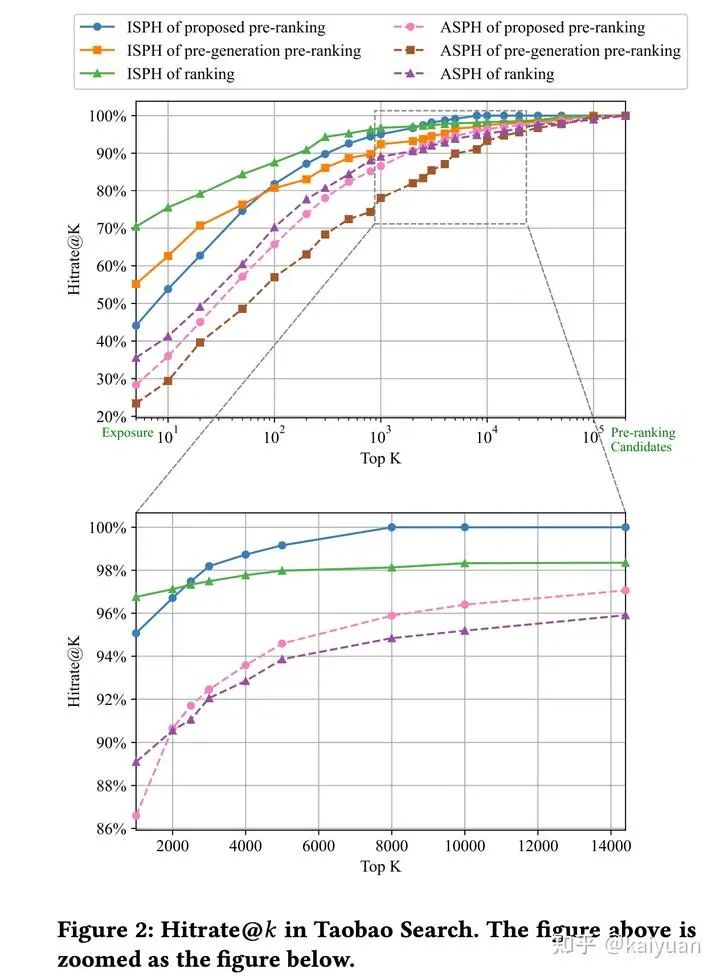
论文新提出的 粗排模型在打分商品集合数量超过2000时,模型能力已经超过精排,且随着集合的扩大,gap越大,说明粗排不能盲目对齐模仿精排 。
那么一个问题是,如何验证全域hitrate指标的有效性? 对粗排输出集合总数为2500和3000分别进行A/B测试,如果 ISPH@k评估有效,则输出3000个的在线业务指标应该更高。如果 ASPH@k有效,则结论相反。在线结果表明,输出3000个商品的业务指标比输出2500个的更低,这进一步证实了ASPH@k 指标的有效性。
优化方案
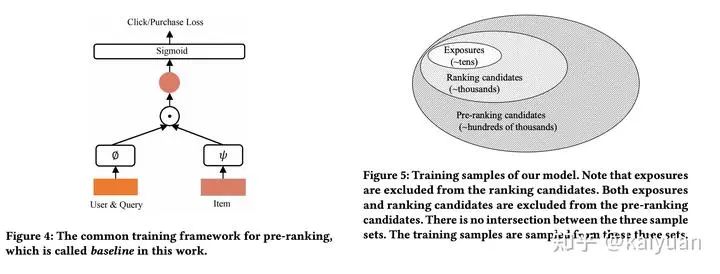
在介绍优化方案之前,提一下传统的粗排模型设计。
模型:双塔,pointwise学习,sigmoid损失学习CTR和CVR,最终生效CTR*CVR
样本:来自曝光空间,曝光点击为正样本,曝光未点为负样本
淘宝新版粗排模型大图如下所示。主要优化点包括训练样本构造、全域样本学习、精排模型蒸馏、多目标损失函数优化等等,下面分别具体介绍。
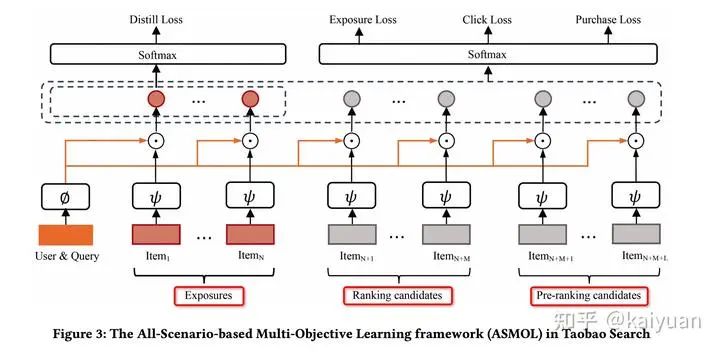
训练样本&标签
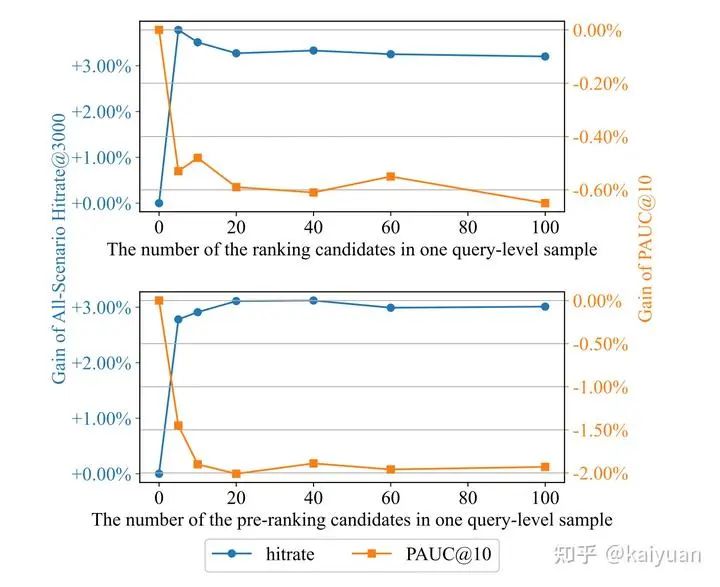
不同于一般排序模型,这里的粗排训练样本使用的是user&query(请求)维度的,一条record内会包含多个正样本和负样本。包含了以下几种:
曝光样本(Exposure,Ex):一条请求中直接展示给用户的商品,不论是否点击或购买等,一共N个;
精排样本(Ranking Candidates,RC):在线serving时粗排模块送给精排的样本集合(且未曝光),一般几千个,会随机从中采样M个;
粗排样本(Pre-Ranking Candidates,PRC):在线serving时召回模块送给粗排的样本集合(且未被粗排选中),一般数十万,会随机从中采样L个。
前面提到了粗排评估指标: 全域成交hitrate ,一个直接优化的方式就是 引入全域成交样本,将其添加到曝光样本中 ,同时将曝光、点击和成交标签都设为1。同时,将之前全域有成交行为但被作为负例的样本修正标签,将其成交标签置为1。
精排样本和粗排样本会作为所有任务的负样本,目的是为了让粗排模型保持训练和预测空间的一致性,避免严重的SSB问题。

只使用曝光样本的模型效果最差 ,因为在线serving时,对训练没见到过的候选商品无法做出精准预估,这会使得粗排输出集合效果不好;
对比三、四行,PRC作为简单负样本,RC作为困难负样本, 加上困难负样本对模型效果帮助更大;
此外,不同负样本的配比也会对效果产生影响。
蒸馏精排
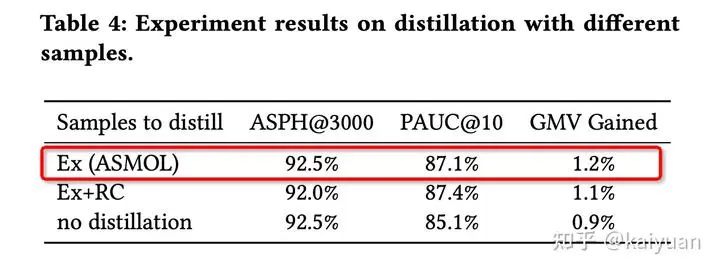
粗排模型想要获得更好的预估精度,学习精排是一个十分常见的思路,业界也已经有非常多的成功落地方案。通过知识蒸馏的方式学习精排,有几个好处:
一方面可以提高精排模型和粗排模型的一致性,使粗排模型排出来的商品更容易被精排模型接受;
另一方面,由于精排模型输入特征和模型结构都比粗排模型复杂,因此引入蒸馏任务可以提高粗排的能力。
论文采用的是对精排模型产出的CTR和CTCVR打分进行学习,
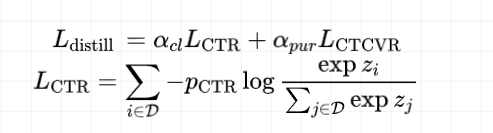
实验结果表明,只在曝光样本上进行蒸馏,粗排模型指标更好(也从另一角度证明,精排对于其未见过的样本打分是不精准的,如果再在这部分进行蒸馏学习,会带来一些噪声 )。
学习任务
样本的组织形式是list-wise的,故损失函数选用list-wise ranking loss,针对曝光、点击、购买分别建模
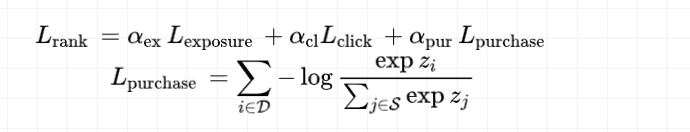
但是当一条样本中有超过一个正例时,直接使用softmax的形式会使得正-正样本之间产生不合理的比较。参考Circle-Loss,对损失函数进行了优化:
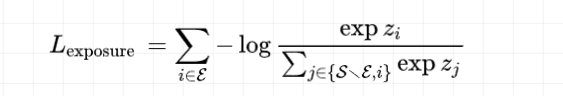
最终会加上上一节的蒸馏损失一起计算总损失
总结
文章一大半篇幅在分析粗排评估指标以及验证粗排模块在搜索全链路中的定位,分析清楚问题、优化指标,已经成功一大半了。模型优化也没有让人感觉是那种花里胡哨无法落地的强行讲故事,能落地且有效果,强烈推荐相关方向的同学一读!
最后,简单罗列下一些重点:
离在线指标一致性是召回粗排同学一直面临的难题 ,论文提出 全域成交hitrate 指标,可以更好地无偏地分析离在线一致性。
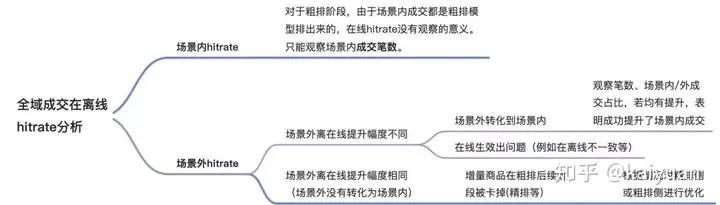 from:承上启下:基于全域漏斗分析的主搜深度统一粗排
from:承上启下:基于全域漏斗分析的主搜深度统一粗排
全域成交hitrate不仅可以指导粗排的优化,也可以作为精排、重排等模块的迭代参考 。可以对全链路每个模块计算该指标,从前往后分析每一阶段的损失与提升空间。
精排不是万能的,粗排不可盲目对齐学习它 。目前精排都是在曝光空间学习的,对于位于腰部的商品打分未必由于粗排(或许可以通过修正精排学习空间来解决,但同时也会带来精排对头部商品的预估能力变差,是一个跷跷板问题)
召回粗排模型的负样本很重要,正负样本的配置也同样重要 。通过负采样来解决SSB问题应该是一个常识了,但具体如何实现可能与业务更相关,没有绝对的标准答案,需要做大量实验去探索。
粗排模型优化的目标首先是集合整体的质量,其次才是商品间的排序 。
基于上一条,召回粗排模型,listwise+softmax的学习方式优于pointwise+sigmoid 。可以同时学习正样本之间、正负样本以及负样本之间的区别差异。
对于召回粗排而言,Hitrate 比 AUC 更可靠 。当两者出现冲突时,实验证明应优先相信hitrate。
softmax对多个正样本损失的优化,可以学习下,比直接暴力对logits乘上N要优雅;
精排蒸馏可以考虑加入精排顺序的学习;
文中对于user塔和item塔的细节放在了附录,是比较常见但有效的建模思路
编辑:王菁
