目录
52、vector是怎么存储的?
- vector底层的数组中存放的
string对象的地址- 因为需要保证随机访问,但是string本身无法立即确定其大小,所以无法直接存放string对象,而是采取存放地址的方式
53、epoll的底层原理
53.1 对比select和poll
epoll的工作方式非常高效
- select和poll是使用线性方式检测socket集合是否需要处理的,而epoll是基于红黑树来管理待检测集合的
- select和poll每次都需要线性的扫描整个集合,但是epoll是回调的方式,可以直接获知那些集合有需要响应
- select和poll需要对返回的集合进行判断才会知道哪些文件描述符是就绪的,epoll可以直接得到就绪的文件描述符集合
- epoll没有最大文件描述符的限制,仅仅受限于系统能打开的文件描述符的限制
三个操作函数
- 创建
- 添加和维护管理
- 检测是否存在有就绪的文件描述符
#include <sys/epoll.h>
// 创建epoll实例,通过一棵红黑树管理待检测集合
int epoll_create(int size);
// 管理红黑树上的文件描述符(添加、修改、删除)
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 检测epoll树中是否有就绪的文件描述符
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
对于int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 联合体, 多个变量共用同一块内存
typedef union epoll_data {
void *ptr;
int fd; // 通常情况下使用这个成员, 和epoll_ctl的第三个参数相同即可
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// epfd 就是创建的epfd实体
// op 用于指定执行什么管理操作,是删除、添加、还是修改
// fd 用于指定要添加的socket是啥
// event 是一个结构体,用来指定fd相关事件以及一些用户数据,事件的话有EPOLLIN:读事件、EPOLLOUT:写事件、EPOLLERR:异常事件
对于int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
// epfd 是epoll对象实例
// events 是返回的就绪状态的文件描述符
// maxevents 表示 结构体的容量
// 0-> 不等待 -1-> 一直等待
53.2 ET和LT的工作模式
LT是指水平触发: 这是默认的工作方式,如果文件描述符需要被响应,相应的事件就会被触发,如果我们不处理,或者没有处理完全,就会继续触发
ET是指边沿触发: 这是比较高校的方式,如果文件描述符需要被响应,相应的事件只会被触发一次,不管我们处理与否
- 循环接受数据,希望能够一次处理完全
- 因此需要使用非阻塞的函数,收发数据,特别是接受
54、进程、线程、协程的理解和他们的通信方式
54.1 进程的含义
- 进程是操作系统进行资源分配的基本单位;它可以申请和拥有系统资源,是一个动态的概念;
- 进程拥有自己的地址空间,也即拥有自己独立的内存空间,不同的进程之间需要IPC也即进程间通信(管道、信号、消息队列、共享内存、信号量、Socket);
- 由于每一个进程都拥有属于自己的系统资源,因此上下文切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大;进程切换由操作系统完成。
54.2 线程的含义
- 线程是进程的一个执行实体,是CPU调度的基本单位;线程自己基本上不拥有系统资源,只拥有一些在运行中必不可少的资源(PC、寄存器、栈)
- 同属于一个进程的线程共享进程所拥有的全部资源; 线程之间的通向主要靠共享内存、全局变量等
- 相比进程线程的切换只需要保存和恢复PC、寄存器、栈,因此开销较小;线程的切换由操作系统完成。
54.3 协程的含义
- 协程是一种用户态的轻量级线程,协程的调度完全由用户控制,不需要进入内核态;
- 协程拥有的资源更少,有自己的寄存器和栈,协程切换只需要保护好这些资源即可,协程的上下文切换开销最小,速度最快;
- 协程可以不加锁的访问全局变量(因为协程的调度由用户控制,不会出现读写竞争,因此可以不加锁———我自己的理解)
54.4 进程间通信IPC
https://www.cnblogs.com/zhuminghui/p/15405591.html
进程间的通信要经过内核
常用的IPC方式有:管道、消息队列、共享内存、信号量、信号、socket等
为什么需要通信呢?
- 因为不同的进程之间地址空间是独立的,如果需要协作,则就需要特殊的方式进行通信也即IPC通信
54.4.1、管道(pipe)
匿名管道是半双工的、单向的、如果需要相互通信,就需要创建两个管道,并且只能在由亲缘关系的进程间使用。亲缘关系如父子进程。
有名管道也是半双工的、单向的,但是可以允许无亲缘关系的进程之间通信。
缺点:管道通信方式效率低,不适合进程间频繁地交换数据。
54.4.2、消息队列
消息队列是保存在内核中的消息链表,所以消息队列的生命周期是跟随内核与操作系统的。
消息体是用户自定义的数据类型,消息的发送方和接受方必须约定好消息体的数据类型,因此每个消息体都是有固定格式和大小的存储块。
-
两个进程之间通信就像发邮件,你来一封,我回一封
-
优点:解决了信号传递信息少、管道只能曾在无格式的字节流以及缓冲区大小有限的缺点; -
缺点:通信不及时,消息体大小有限制、会发生用户态和内核态之间的频繁拷贝过程
54.4.3、共享内存
共享内存是两个进程都能访问到的一块内存空间,因此如果一个进程写入了数据,另一个进程立即就能看到。因此效率非常高,也是所有的IPC中最快的一种。
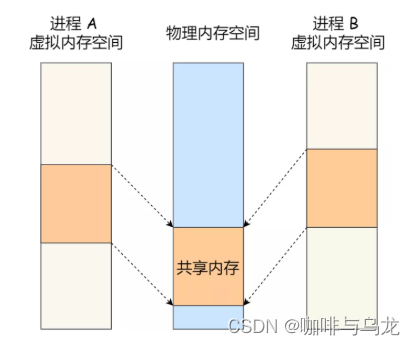
54.4.4、信号量
信号量主要是用于和共享内存进行合作,保证共享资源的互斥与同步,用于防止数据访问的冲突与覆盖问题
54.4.5、信号
Linux内部定义了几十种信号,分别代表不同的意义。可以在任何时候发送一个信号给进程,用来告诉某个进程某事件发生。
-
信号来源主要是
硬件来源和软件来源 -
当一个进程收到一个信号后,一般有三种处理方式
- 执行Linux给每一个信号提供的默认操作
- 捕捉信号,执行我们自己定义的处理函数
- 忽略不处理
54.4.6、Socket
可以用于不同设备上不同进程间的通信。
54.5 线程间通信方式
线程通信的主要目的是线程同步,所以没有像进程中用于交换数据的通信机制
主要是锁机制,如互斥锁、读写锁、条件变量、信号量
55、define宏定义的用法
-
防止一个头文件被重复包含
#ifndef HEAD_H #define HEAD_H // 头文件内容 #endif -
求两个数的最大值和最小值
本质就是用一句话、一行代码、一个表达式实现该宏的功能,并且该表达式的结果就是宏的目标
#define MAX(x, y) ((x) > (y) ? (x) : (y)) #define MIN(x, y) ((x) > (y) ? (y) : (x)) // 宏函数的调用 cout << MAX(10, 100) << endl; // 100 -
返回数组元素的个数
#define ARR_SIZE(arr) (sizeof((arr)) / sizeof((arr[0]))) // 调用 int arr[15] = { 0}; cout << ARR_SIZE(arr) << endl; // 15 -
得到一个变量的地址
#define GET_PTR(var) ((void *)&(var)) // 调用 double d = 100.11; cout << GET_PTR(d) << endl; // 0x72fdc8 -
从指定的地址获取一个字节或者int
#define MEM_B(ptr) (*((char *)(ptr))) // 获取一个字节 #define MEM_INT(ptr) (*((int *)(ptr))) // 从一块地址上去一个int -
将一个字母转换为大写字母
#define UPCASE(c) (((c) <= ('z') && (c) >= ('a')) ? ((char)((c) - ('a') + ('A'))) : (c)) cout << UPCASE('a') << endl; // A cout << UPCASE('A') << endl; // A
56、关于数组与指针、数组名的各项细节
-
数组名本身有数组属性,可以直接对数组名进行
sizeof求数组大小;赋值之后就不存在了这种属性了// 数组名本身有数组属性 int arr[15] = { 0}; cout << size(arr) << endl; // 60 // 如果将数组名传递到函数中就不带有数组属性了,将退化为一个指针 cout << func1(arr) << endl; // 如果调用下面的函数,就会丧失数组属性 int func1(int arrp[]) { return sizeof(arrp); // 退化为指针后,sizeof得到的仅仅是指针大小 } -
32位机指针的大小是4个字节、64位机指针的大小是8个字节
-
数组名的用法上更类似于一个
指针常量,也即指针的指向不能改变,指向数组的首地址int arr[10] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; arr++; // 不合法---->因为数组名arr是一个指针常量,自身是不可以改变的 int a = *(arr + 1); // 等价于arr[1]; int* ptr = arr; //通过赋值操作,用一个普通的指针指向了数组arr的首地址 ptr++; // 合法 ++ptr; // 合法 int* ptr2 = &arr[0]; // 等价于 int* ptr = arr; 结果都是使得一个普通指针指向了数组的首地址 -
数组的首地址与数组的第一个元素的起始地址是等价的
int arr[3] = { 1, 2, 3}; // arr指向数组的首地址 // &arr[0]指向数组第一个元素的起始地址 // 两者是同一个位置 -
指针的移动与运算
-
指针和指针只能进行相减运算(得到的是间隔了多少个元素),不能进行乘、除、加等运算
-
指针只能加上一个常量
int arr[10] = { 0}; int * p = arr; *(p + 9) 指向最后一个元素 等价于 arr[9] 同样也等价于*(arr + 9) 在编译器中,arr[i]的访问过程就是转化为 *(arr + i)然后访问的
-
-
关于指针数组与
数组指针// 声明一个指针数组,该数组有10个元素,其中每个元素都是一个指向 int 类型对象的指针 int *arr[10]; // 声明一个数组指针,该指针指向一个 int 类型的一维数组 int (*arr)[10];
57、编译的具体过程
-
编译过程具体可分为4步
预处理—编译—汇编—链接 -
预处理
- 展开头文件、展开宏定义、删除注释
- gcc命令:
gcc -E ... - 生成的中间文件为
.i文件,依旧是源代码
-
编译
- 将
.i文件编译成.s文件;也即源代码文件转化为汇编代码 - gcc命令:
gcc -S ... - 生成的中间文件为
.s文件,是汇编代码 - 主要的编译优化就是发生在这个阶段
- 将
-
汇编
- 将
.s文件逐行翻译成.o文件;也即从汇编翻译成二进制机器码 - gcc命令:
gcc -c ... - 生成的中间文件为
.o文件
- 将
-
链接
- 这个阶段 GCC 调用链接器对程序需要调用的库以及多个
.o文件之间进行链接,生成可执行的二进制文件 - gcc命令:直接
gcc + 源文件编译即可,不需要其他参数 - 默认生成
a.out文件,也可以使用-o 文件名,自定义生成的文件的名字(该命令也可以用于上述的几个阶段)
- 这个阶段 GCC 调用链接器对程序需要调用的库以及多个