上次我们讲到了基于数组的数据结构ArrayList,这次我们来讲关于链表的实现LinkedList
ArrayList和LinkedList的区别:
1、ArrayList是基于数组实现的动态数组,其实容量是固定好的,每次增加数据都需要进行扩容。
2、LinkedList是基于链表实现,数据存储在节点中,增加内容只需要新建结点(Node),通过尾部结点指向下一个新建结点。完全不需要考虑容量问题。
优缺点:
1、ArrayList因为底层是通过数组实现,所以查询效率高,只要通过下标就可以查找到目标对象,具有随机访问的功能。客观上但是插入数据需要移动大量的尾部数据,插入效率低,查询效率高。
2、LinkedList底层链表实现,实现了真正意义上的动态集合,但是不具备随机访问能力,查询结点需要移动指针,查询效率低。但是插入数据只需要改变结点指向,不需要移动任何数据,插入数据效率极高。
结点
链表的底层都是一个一个结点,关于结点以下表示
public class Node{
//结点中存储的对象
private Object data;
//指向下一个结点对象
private Node next;
public Node(Object obj,Node next){
this.data=obj;
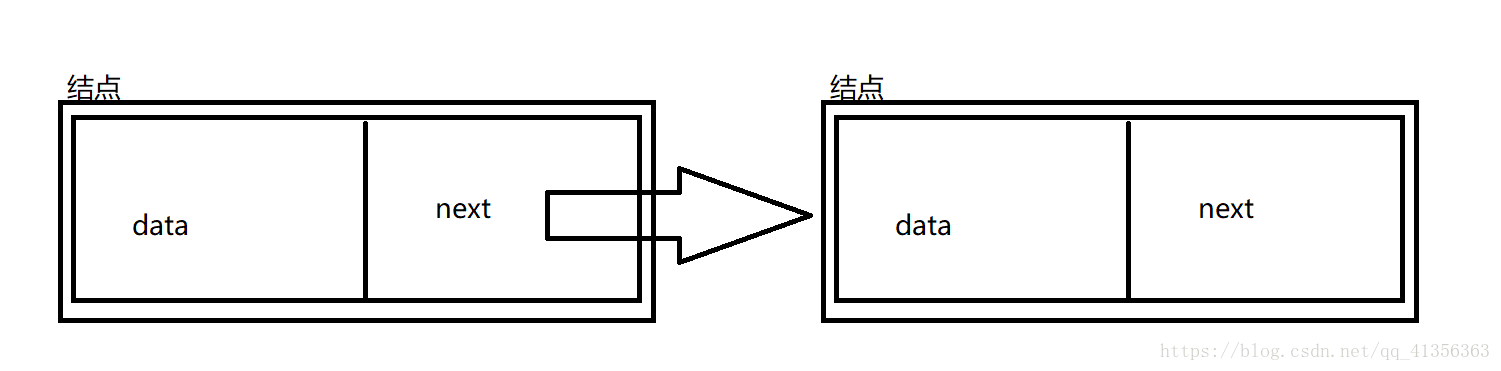
结点(Node)内具有两个属性,Data和Next,Data就是当前结点所存储的内容,Next代表下一个结点,可以通过代码看出,Next本身就是结点。抽象的来看,结点就是一个大箱子,箱子分成两个区域,在Next的区域又可以放一个同等的箱子,类似于Java重复递归的过程。然后我们的第一个箱子就是我们所说Head(头结点),通过下标查询结点类似于拆开下标数值的箱子量。
链表
现在,关于链表我们已经有了初步的认识,通过下面的图片帮你快速理解。
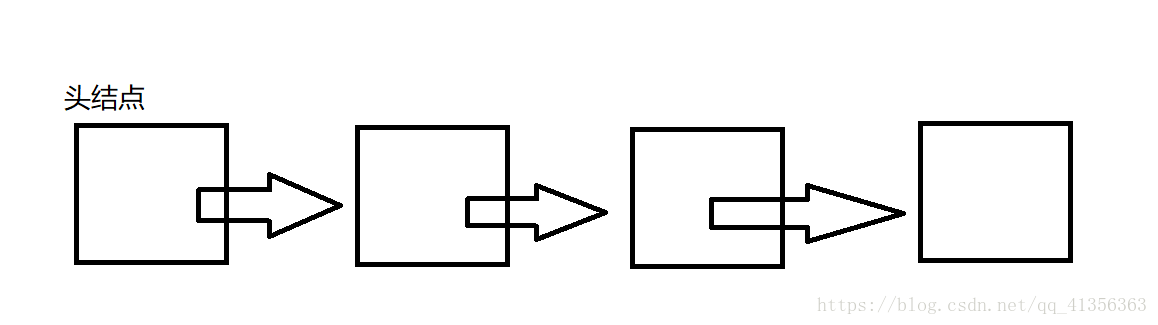
链表是由一个个结点指向它的下一个结点所产生的集合,结构与锁链相似。
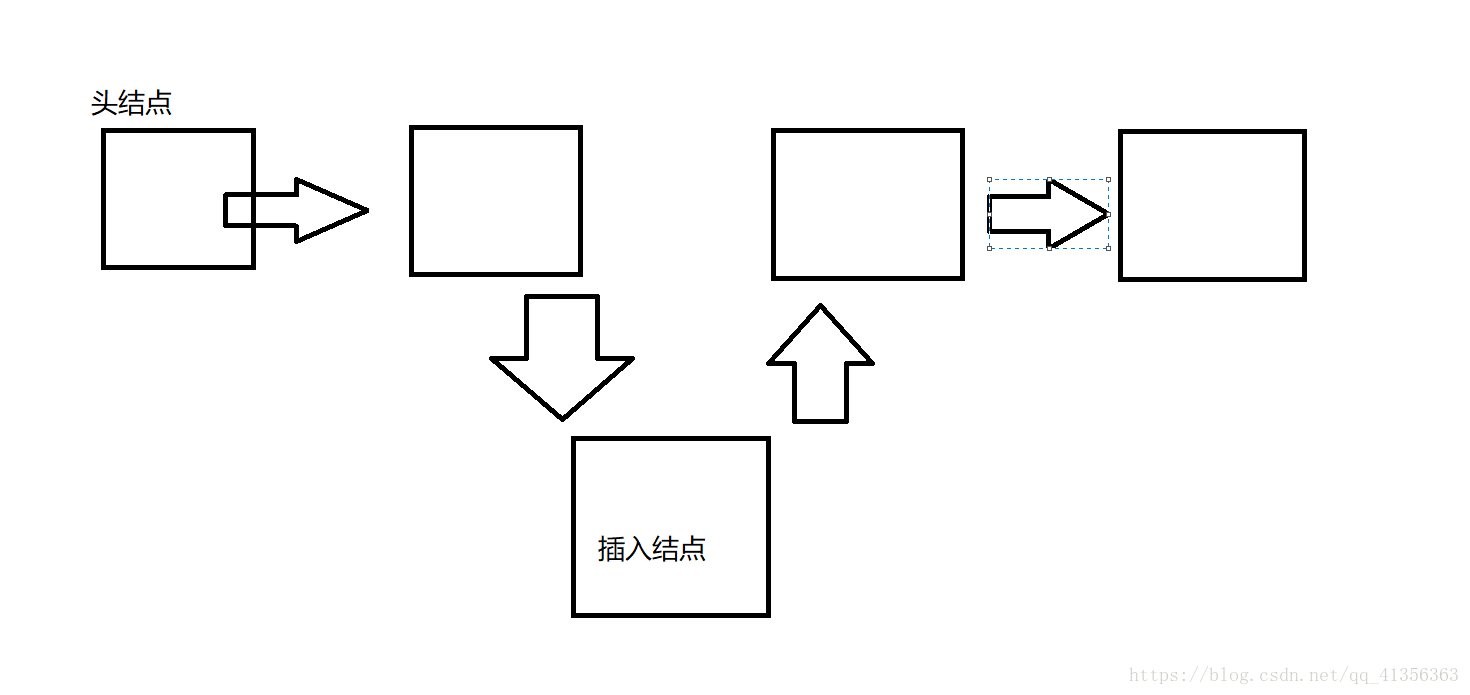
我们插入数据只需要 更改它的其中一个节点指向就可以完成数据插入
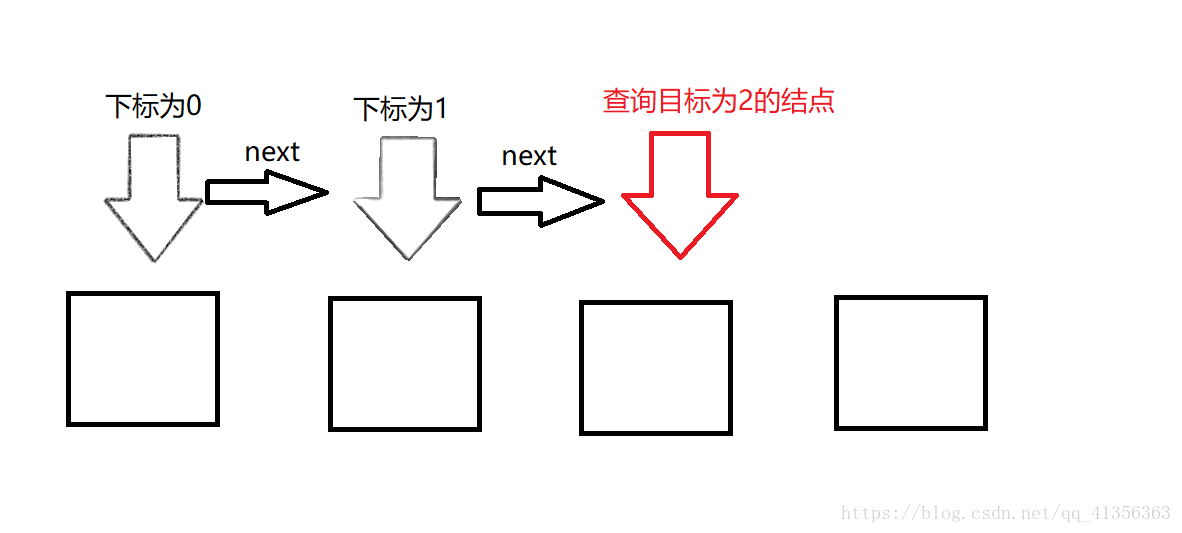
查询结点是通过指针从头结点开始向后移动,查询到指定位置下标时,将结点返回出来。通俗的讲就是通过Next的向下递归,指到下标数值时,即为查询的结点。
接下来我们上代码:
package com.Shaw;
import javax.xml.crypto.Data;
public class MyLinkList {
private int size;
private Node head;
public class Node {
private Object data;
private Node next;
public Node(Object data, Node next) {
this.data = data;
this.next = next;
}
}
//在尾部添加数据
public void add(Object obj) {
Node node = new Node(obj, null);
if (head == null) {
head = node;
} else {
Node temp = head;
for (int i = 0; i < size - 1; i++) {
temp = temp.next;
}
temp.next = node;
}
size++;
}
//查询元素
public Object get(int index) {
CheckIndex(index);
Node temp = head;
for (int i = 0; i <index; i++) {
temp = temp.next;
}
return temp.data;
}
//修改元素
public void set(int index, Object obj) {
CheckIndex(index);
Node temp = head;
for (int i = 0; i < index; i++) {
temp = temp.next;
}
temp.data = obj;
}
//删除结点
public void remove(int index) {
CheckIndex(index);
Node temp = head;
//删除头结点需要设置新的头结点
if (index == 0) {
temp=head;
head=head.next;
temp.data=null;
temp.next=null;
}
//删除结点时需要从删除的结点前一个位置开始更改下标
else {
for (int i = 0; i < index - 1; i++) {
temp = temp.next;
}
Node prev=temp;
Node remove=temp.next;
prev.next=remove.next;
remove.next=null;
remove.data=null;
//方便垃圾回收
remove = null;
remove = null;
}
size--;
}
public String toString() {
StringBuffer sb = new StringBuffer();
sb.append("LinkedList Size:");
sb.append(size);
sb.append("\n");
Node temp = head;
for (int i = 0; i < size; i++) {
sb.append(temp.data);
if (i != size - 1) {
sb.append("->");
}
temp = temp.next;
}
sb.append("->NULL");
return sb.toString();
}
private void CheckIndex(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException();
}
}
public int size() {
return size;
}
}
来测试效果
1、增加方法
public static void main(String[] args) {
MyLinkList list = new MyLinkList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
System.out.println(list.toString());
}结果为:
LinkedList Size:4
1->2->3->4->NULL
2、删除方法:
public static void main(String[] args) {
MyLinkList list = new MyLinkList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
System.out.println(list.toString());
list.remove(0);
System.out.println("删除下标为0的结点后:\n"+list.toString());
}结果为:
LinkedList Size:4
1->2->3->4->NULL
删除下标为0的结点后:
LinkedList Size:3
2->3->4->NULL
3、修改方法
public static void main(String[] args) {
MyLinkList list = new MyLinkList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
System.out.println(list.toString());
list.set(0,0);
System.out.println("修改下标为0的结点后:\n"+list.toString());
}结果为:
LinkedList Size:4
1->2->3->4->NULL
修改下标为0的结点为0后:
LinkedList Size:4
0->2->3->4->NULL
4、查询方法
public static void main(String[] args) {
MyLinkList list = new MyLinkList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
System.out.println(list.toString());
Object o = list.get(0);
System.out.println("查询下标为0的结点:"+o);
}结果为:
LinkedList Size:4
1->2->3->4->NULL
查询下标为0的结点:1
以上就是链表的单向链表操作,下一章我会补充上关于双向链表的文章