链表结构
概念
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。

通过理解概念有了一个大概模型,就是每块空间都有自己独立的数据内容,他们之间联系就是通过前面保存后面地址,后面每一个依次类推。所以最后一个的下一个没有指向。实际是置空
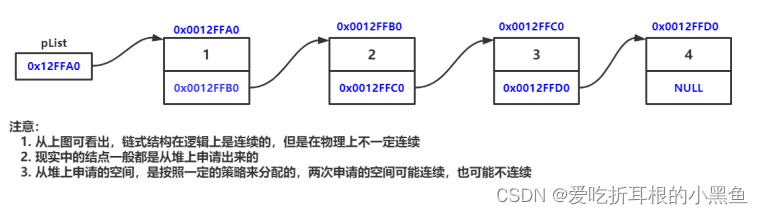
每一个空间都数据还有下一个地址。为了便于管理就可以使用结构体。结构体内部就是保存地址和数据。
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;
struct SListNode* next;
}SListNode;
虽然结构简单不复杂,但是对于指针使用及其前后迭代关系就是学好链表关键。
链表类型
链表在数据结构中,可以有很好过渡性。他自己可以实现增删查找。还可以为以后实现数据结构哈希桶子结构,图的邻接表。作为这些数据结构领头大佬旁支,基础。类型也是具有多样化。单是结构就有8种。每一种都有自己的优势。
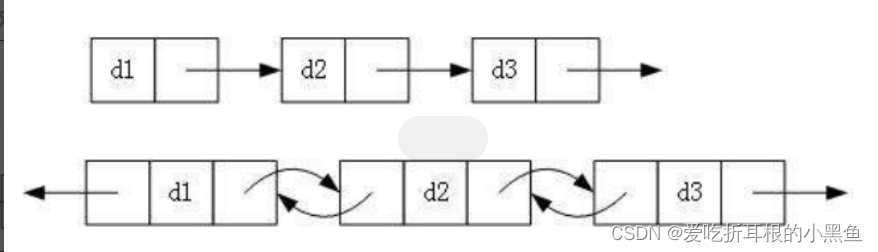
1、单向还是双向
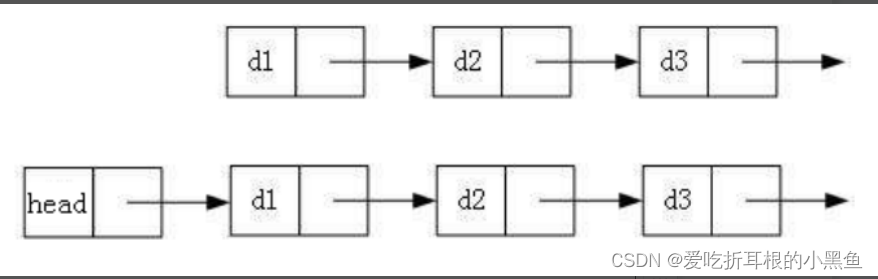
2、是否带头
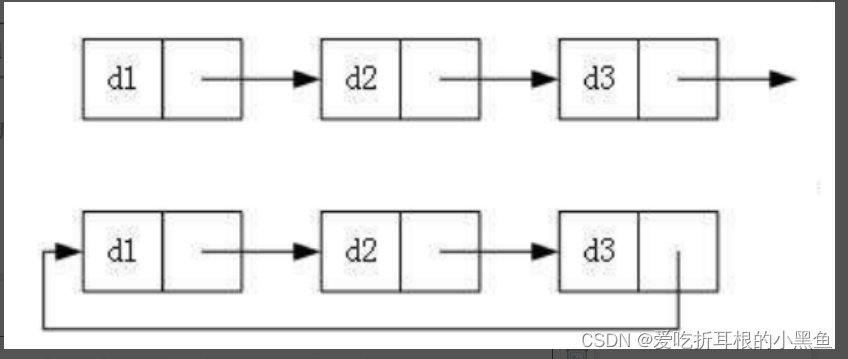
3、是否循环
组合就可以得到不带头单向不循环,带头双向循环……等。
虽然组合比较多,但是实用就可决定只有以上2种。也可以说这是这些结构中比较经典的结构。
结构实现
1、单链表
单链表实现就是对于指针的运用,迭代。一旦理解。就会发现链表难度并没有想象中难么晦涩难懂。在代码中实现增删插改。可以在实现时注意指针的指向内容变化,还有指针类型。这样会让我们在调试时,多一份心平气和,少一点崩溃挠头。
直接看代码:
创建节点
SListNode* BuySListNode(SLTDateType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
尾插
void SListPushBack(SListNode** pplist, SLTDateType x)
{
SListNode* newnode = BuySListNode(x);
SListNode* tail = NULL;
if ((*pplist) == NULL)
{
*pplist = newnode;
}
else
{
tail = *pplist;
//找尾
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}
尾删
void SListPopBack(SListNode** pplist)
{
assert(*pplist);
//一个节点单独判断
if ((*pplist)->next == NULL)
{
free(*pplist);
*pplist = NULL;
}
else
{
SListNode* tail = *pplist;
SListNode* pre = NULL;
while (tail->next)
{
pre = tail;
tail = tail->next;
}
free(tail->next);
pre->next = NULL;
}
}
打印
void SListPrint(SListNode* plist)
{
SListNode* cur = plist;
while (cur != NULL)
{
printf("%d-> ", cur->data);
cur = cur->next;
}
printf("\n");
}
头插
void SListPushFront(SListNode** pplist, SLTDateType x)
{
SListNode* newhead = BuySListNode(x);
newhead->next = *pplist;
*pplist = newhead;
}
头删
void SListPopFront(SListNode** pplist)
{
assert(*pplist);
SListNode* next = (*pplist)->next;
free(*pplist);
*pplist = next;
}
总结:
在单链表中,对于链表操作需要改变什么就需要传什么指针,对于节点是一个结构体指针。结构体指针不会改变结构体内容。所以实现传址调用。还有删除需要判断是否链表为空,避免空指针出现。
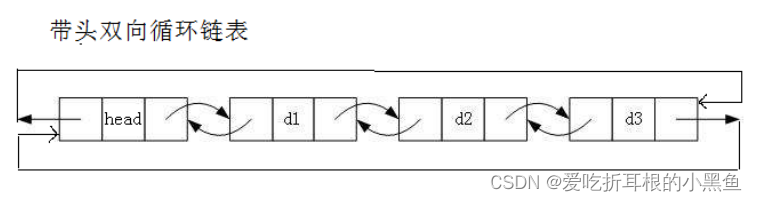
2、带有双向循环链表
实现比较简单。这个主要取决于它自身结构优势。
typedef int LTDataType;
typedef struct ListNode
{
LTDataType _data;
struct ListNode* _next;
struct ListNode* _prev;
}ListNode;
双指针优势。
ListNode* Init()
{
ListNode* new = ListCreate(-1);
new->_next = new;
new->_prev = new;
return new;
}
从他初始化就不难看出。实现链表带头优势。还有该链表结束条件。在头结点的next指向头节点便是链表为空处理。代码如下:
// 创建返回链表的头结点.
ListNode* ListCreate(LTDataType x)
{
ListNode* newnode= (ListNode*)malloc(sizeof(ListNode));
if (newnode == NULL)
{
perror("fail");
exit(-1);
}
newnode->_data = x;
newnode->_next = NULL;
newnode->_prev = NULL;
return newnode;
}
// 双向链表销毁
void ListDestory(ListNode* pHead)
{
assert(pHead);
assert(pHead->_next != pHead);
ListNode* tail = pHead->_prev;
ListNode* tailprev = tail->_prev;
tailprev->_next = pHead;
pHead->_prev = tailprev;
free(tail);
}
// 双向链表打印
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->_next;
while (cur!=pHead)
{
printf("%d ", cur->_data);
cur = cur->_next;
}
printf("\n");
}
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* newnode = ListCreate(x);
ListNode* first = pHead->_next;
first->_prev = newnode;
newnode->_next = first;
newnode->_prev = pHead;
pHead->_next = newnode;
}
// 双向链表头删
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(pHead->_next != pHead);
ListNode* first = pHead->_next;
ListNode* sconed = first->_next;
free(first);
sconed->_prev = pHead;
pHead->_next = sconed;
}
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* node = ListCreate(x);
ListNode* tail = pHead->_prev;
tail->_next = node;
node->_prev = tail;
node->_next = pHead;
pHead->_prev = node;
}
// 双向链表尾删
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(pHead->_next != pHead);
ListNode* tail = pHead->_prev;
ListNode* tailprev = tail->_prev;
tailprev->_next = pHead;
pHead->_prev= tailprev;
free(tail);
}
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* node = ListCreate(x);
ListNode* prev = pos->_prev;
prev->_next = node;
node->_prev = prev;
node->_next = pos;
pos->_prev = node;
}
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* prev = pos->_prev;
ListNode* next = pos->_next;
prev->_next = next;
next->_prev = prev;
free(pos);
}
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* cur = pHead->_next;
while (cur != pHead)
{
if (cur->_data != x)
{
cur = cur->_next;
}
return cur;
}
}
总结:
代码实现比较轻松,比较单链表实现同样功能更加通俗易通。而且结构设计本身就比较完美。