从零搭建运行Tensorflow版pointNet++模型全流程及常见问题解决
- 一、Ubuntu18系统安装及初始化
- 二、源码和数据集下载
- 三、搭建pointNet++所需环境(Anaconda、Cuda、cuDNN、Pytorch、Python)
- 四、运行pointNet++
- 五、运行中的常见问题解决
-
- 1.报错:{NotFoundError}libcudart.so.10.0: cannot open shared object file: No such file or directory
- 2.报错:{NotFoundError}/home/sdg/code/pointnet2-master/tf.ops/sampling/tf.sampling_so.s0:( undefined symbol: _ZM10temsorflow120pDefBuilder4AttrESs
- 3.报错:FileNotFoundError: [Errno 2] No such file or directory:'/home/sdg/code/pointnet2-master/data/modelnet40_normal_resampled/shape_names.txt'
- 4.报错:{AttributeError}module 'provider' has no attribute 'rotate_point_cloud'
- 5.报错:failed to allocate 64.00M (67108864 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory
本次采用的是Tensorflow版的pointNet++模型
服务器环境是Ubuntu18/python3.7/cuda10.0/cudnn7.4/tensorflow-gpu1.4/g++5
参考:零基础复现pointNet++模型教程和pointnet++ pointnet2代码运行 保姆级教程
一、Ubuntu18系统安装及初始化
参考:Ubuntu18系统安装及初始化(SSH服务、网络配置)
如果安装的是Ubuntu16系统,可以执行以下命令升级到Ubuntu18:
sudo apt update
sudo apt upgrade
sudo apt dist-upgrade
sudo apt autoremove
sudo do-release-upgrade
二、源码和数据集下载
1.pointNet++源码
下载地址:https://github.com/charlesq34/pointnet2
将下载pointnet2-master.zip文件拷贝到服务器,然后执行unzip pointnet2-master.zip
2.ModelNet40数据集(XYZ and normal from mesh, 10k points)
下载地址:modelnet40_normal_resampled.zip
将下载的数据集文件拷贝到pointnet2-master程序中的data目录下,执行unzip modelnet40_normal_resampled.zip命令解压数据集
3.h5格式的ModelNet40数据集(XYZ and normal from mesh,2048 points)
下载地址modelnet40_ply_hdf5_2048.zip
将下载的数据集文件拷贝到pointnet2-master程序中的data目录下,执行unzip modelnet40_ply_hdf5_2048.zip命令解压数据集
三、搭建pointNet++所需环境(Anaconda、Cuda、cuDNN、Pytorch、Python)
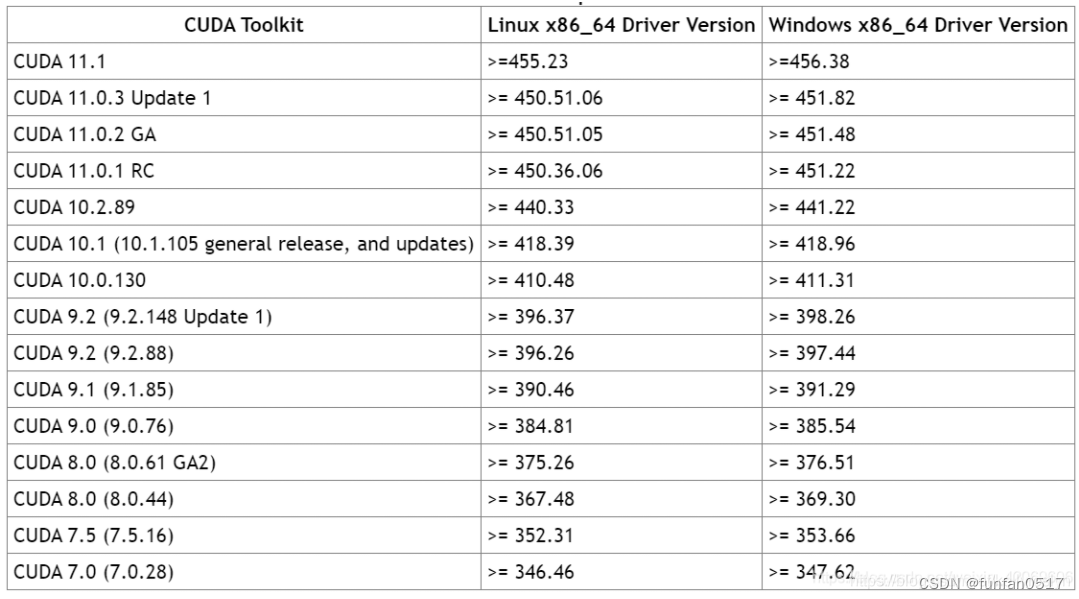
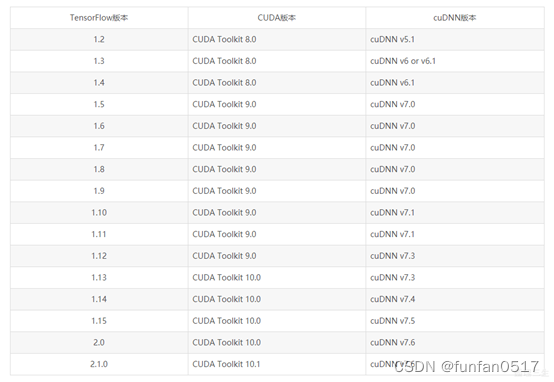
结合自身显卡硬件,根据下图进行显卡驱动、cuda、cudnn、tensorflow版本的搭配
本次选择的环境为/cuda10.0/cudnn7.4/tensorflow-gpu1.4
1.显卡驱动下载安装
可以参考:Ubuntu物理机显卡驱动安装的几种方式
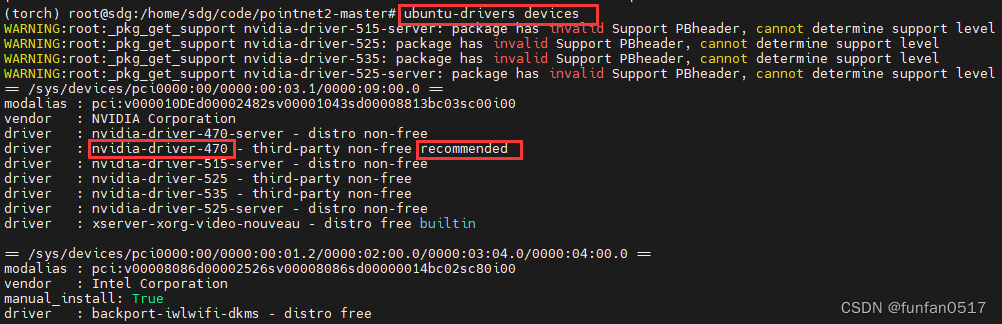
(1)查看适合本显卡的驱动:ubuntu-drivers devices
(2)添加驱动源:sudo add-apt-repository ppa:graphics-drivers/ppa
(3)更新软件源:sudo apt-get update
(4)安装系统推荐的显卡驱动:sudo apt-get install nvidia-driver-470
(5)安装 nvidia-cuda-toolkit 工具:sudo apt-get install nvidia-cuda-toolkit
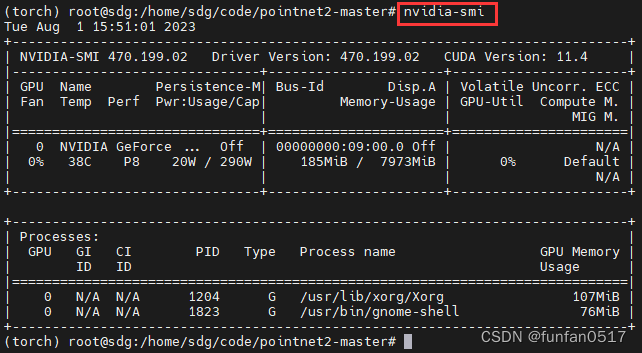
(6)测试显卡驱动是否安装成功:nvidia-smi
2.Anaconda和Cuda的安装配置
Anaconda和Cuda安装配置可以参考:Ubuntu搭建Pytorch环境(Anaconda、Cuda、cuDNN、Pytorch、Python、Pycharm、Jupyter),注意Cuda的版本即可,我用的cuda10.0
3.cudnn的安装配置
如果安装cudnn的过程中出现了如下报错:libcudnn7-doc_7.4.2.24-1+cuda10.0_amd64.deb 并非 Debian 格式的包文件
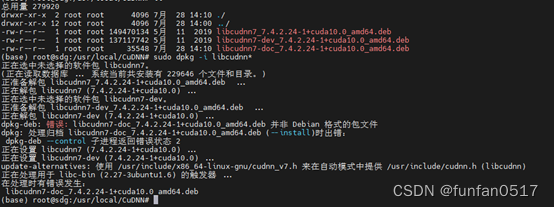
原因是第三个包的安装源损坏了,建议按以下步骤安装cudnn7.4:
(1)先切换到/usr/local目录下,然后创建一个目录CuDNN
cd /usr/local
mkdir CuDNN
cd CuDNN
(2)前往https://developer.nvidia.com/rdp/cudnn-archive下载所需文件
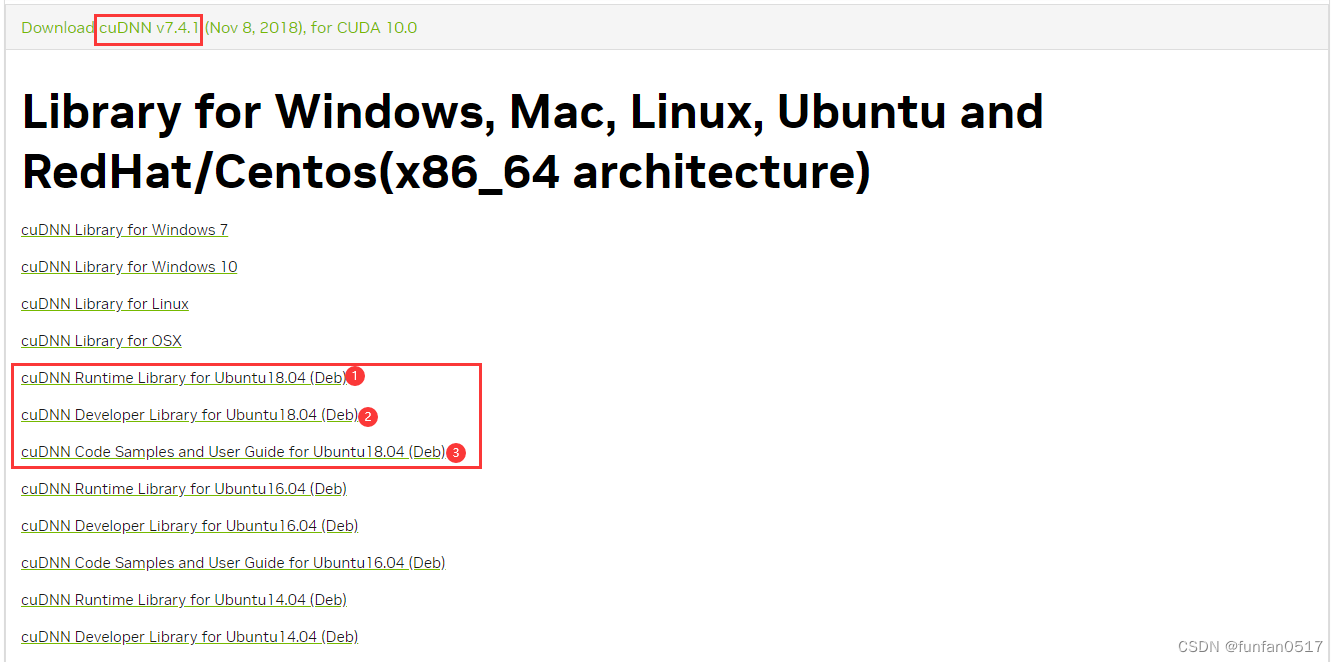
(3)将下载文件拷贝到/usr/local/CuDNN/目录下

运行以下命令安装CUDNN7.4.2,这里安装顺序一定要如下所示:
sudo dpkg -i libcudnn7_7.4.2.24-1+cuda10.0_amd64.deb
sudo dpkg -i libcudnn7-dev_7.4.2.24-1+cuda10.0_amd64.deb
sudo dpkg -i libcudnn7-doc_7.4.2.24-1+cuda10.0_amd64.deb
(4)把文件复制到/usr/local/cuda/include文件夹下面,并修改权限:
sudo cp /usr/include/cudnn.h /usr/local/cuda/include
sudo chmod a+x /usr/local/cuda/include/cudnn.h
(5)检测是否安装成功的测试命令:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2

4.python环境及tensorflow依赖库的安装配置
(1)激活默认的虚拟环境(base环境):source activate
(2)基于python3.7创建名为torch的虚拟环境:conda create -n torch python=3.7
(3)切换到创建的torch虚拟环境:conda activate torch
(4)安装python3-pip库:sudo apt-get install python3-pip
如果安装python3-pip库时报如下错误:下列软件包未满足的依赖关系
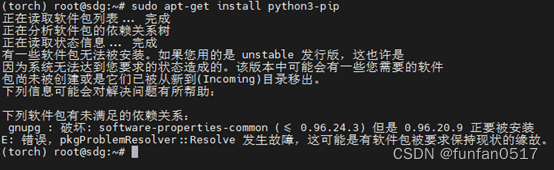
可以使用aptitude安装代替apt-get,aptitude 在处理依赖问题上更加智能:
apt-get install aptitude
sudo aptitude install python3-pip
(5)安装其他依赖库:pip install numpy scipy matplotlib pylint
(6)安装tensorflow:pip install tensorflow-gpu==1.14.0
安装后执行python -c 'import tensorflow as tf; print(tf.__version__)'测试能否使用GPU,出现 tensorflow版本信息即可
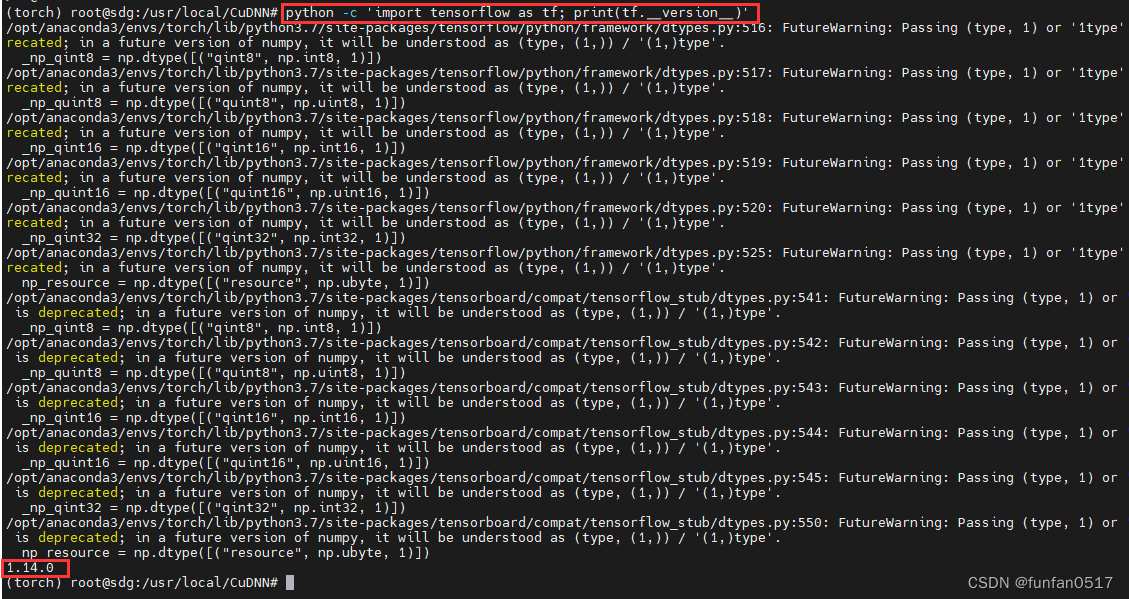
注意:本步骤有警告属于正常现象,强迫症可以根据提示将响应文件后面括号中的“1”改为“(1,)”,这是因为python本班的问题引起的,可以不用处理
如果测试tensorflow时出现以下报错:TypeError: Descriptors cannot not be created directly.
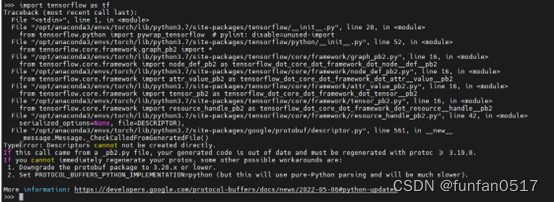
先输入pip uninstall protobuf将现有版本的卸载
然后输入pip install protobuf==3.19.0重新安装对应版本
5.gcc5和g++5的安装配置
(1)安装gcc5和g++5:sudo apt install gcc-5 g++-5
(2)查看gcc和g++的版本信息:
gcc -v
g++ -v
查看版本发现gcc和g++还是指向gcc7和g++7,所以需要手动修改一下软链接
(3)进入/usr/bin目录,备份旧的软链接:
cd /usr/bin
sudo mv gcc gcc_backup
sudo mv g++ g++_backup
(4)创建新的软链接
sudo ln -s gcc-5 gcc
sudo ln -s g++-5 g++
(5)再查看gcc和g++的版本信息会发现已经是5了
gcc -v
g++ -v
四、运行pointNet++
1.修改tf的脚本文件
(1)进入/pointnet2-master/tf_ops/目录,修改以下文件
vi tf_ops/sampling/tf_sampling_compile.sh
vi tf_ops/grouping/tf_grouping_compile.sh
vi tf_ops/3d_interpolation/tf_interpolate_compile.sh
(2)以tf_sampling_compile.sh为例,原内容为
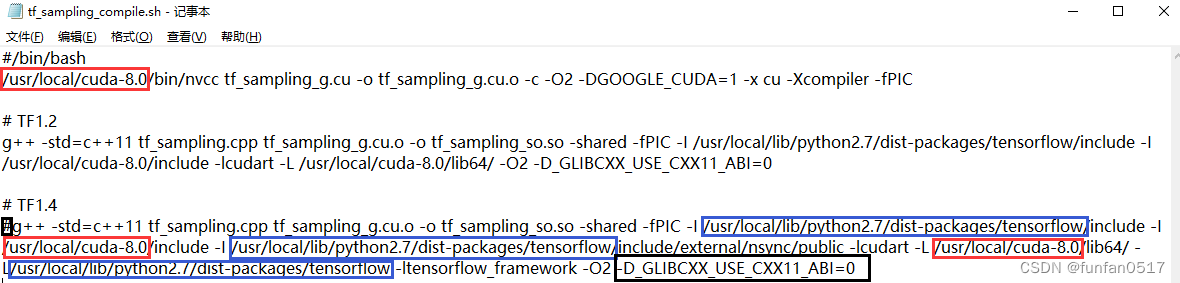
(3)修改内容如下:
1.本次使用的是tensorflow1.14,将TF1.2的内容注释掉,将TF1.4的注释放开
2.本次使用的gcc5版本,如果gcc版本大于 4,则编译脚本中不需要选项-D_GLIBCXX_USE_CXX11_ABI = 0,将其删除掉
3.查看自己安装的cuda和tensorflow的路径
- cuda的路径:根据自己安装的版本进行替换/usr/local/cuda-${ VERSION},我的是/usr/local/cuda-10.0
- tensorflow的路径:执行
python -c 'import tensorflow as tf; print(tf.sysconfig.get_lib())'命令,输出的即为tensorflow的路径,我的是/opt/anaconda3/envs/torch/lib/python3.7/site-packages/tensorflow
按照以下方式替换脚本中的cuda路径和tensorflow路径
| 原内容 | 替换后内容 |
|---|---|
| /usr/local/cuda-8.0 | /usr/local/cuda-10.0 |
| /usr/local/lib/python2.7/dist-packages/tensorflow | /opt/anaconda3/envs/torch/lib/python3.7/site-packages/tensorflow |
(4)修改后的内容为:

2.编译输出so文件
(1)执行以下命令得到libtensorflow_framework.so文件(根据自己的tensorflow目录修改)
cd /opt/anaconda3/envs/torch/lib/python3.7/site-packages/tensorflow/
cp libtensorflow_framework.so.1 libtensorflow_framework.so
不执行这一步,可能会在编译时出现以下报错:/usr/bin/ld: 找不到 -ltensorflow_framework collect2: error: ld returned 1 exit status

(2)执行以下命令,编译输出so文件(根据自己pointnet2-master的目录修改)
cd /home/sdg/code/pointnet2-master/tf_ops/grouping/
chmod 777 tf_grouping_compile.sh
sh tf_grouping_compile.sh
cd /home/sdg/code/pointnet2-master/tf_ops/sampling/
chmod 777 tf_sampling_compile.sh
sh tf_sampling_compile.sh
cd /home/sdg/code/pointnet2-master/tf_ops/3d_interpolation/
chmod 777 tf_interpolate_compile.sh
sh tf_interpolate_compile.sh
不执行chmod 和cd 命令,会出现如下报错:gcc: error: tf_sampling_g.cu: 没有那个文件或目录

(3)编译完成后,会得到对应的.cu.o和.so文件

3.修改pointNet++源码
由于python2与python3的语法上的不同,需要将代码中的xrange替换为range,print后面的加括号
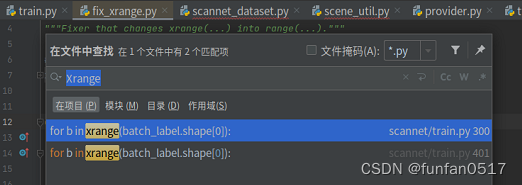
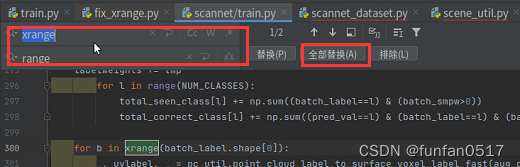
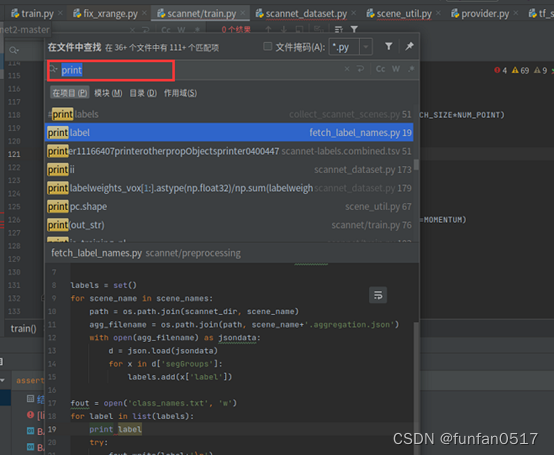
4.运行训练模型
(1)切换到对应的虚拟环境:conda activate torch
(2)执行训练模型:python train.py
五、运行中的常见问题解决
1.报错:{NotFoundError}libcudart.so.10.0: cannot open shared object file: No such file or directory
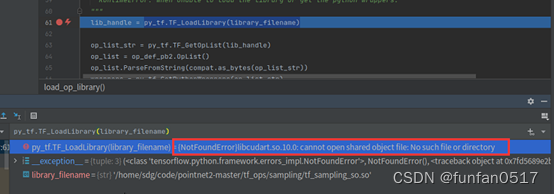
报错原因:anaconda和cuda的环境变量有问题
解决方案:检查anaconda和cuda的目录,添加相关环境变量

2.报错:{NotFoundError}/home/sdg/code/pointnet2-master/tf.ops/sampling/tf.sampling_so.s0:( undefined symbol: _ZM10temsorflow120pDefBuilder4AttrESs
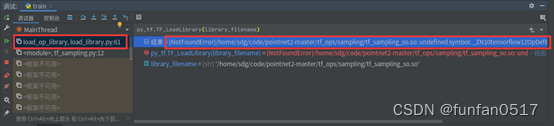
报错原因:如果gcc版本大于 4,则编译脚本中不需要选项-D_GLIBCXX_USE_CXX11_ABI = 0。
解决方案:将上面3个编译脚本中的-D_GLIBCXX_USE_CXX11_ABI = 0删掉
3.报错:FileNotFoundError: [Errno 2] No such file or directory:‘/home/sdg/code/pointnet2-master/data/modelnet40_normal_resampled/shape_names.txt’

报错原因:找不到相关文件
解决方案:将data/modelnet40_normal_resampled/下的modelnet40_shape_names.txt文件改名为shape_names.txt即可
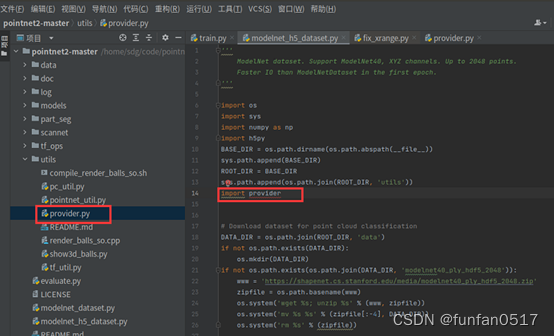
4.报错:{AttributeError}module ‘provider’ has no attribute ‘rotate_point_cloud’

错误原因:python文件命名与使用的第三方库一样导致的错误。源码中有provider.py文件了,不需要装provider库
解决方案:卸载装的provider库(pip uninstall provider),import provider报红不影响运行
5.报错:failed to allocate 64.00M (67108864 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory
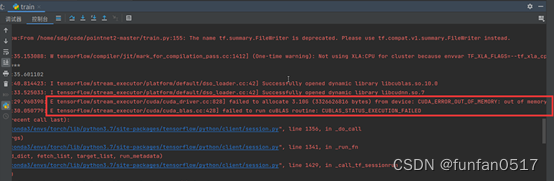
报错原因:显卡显存不足
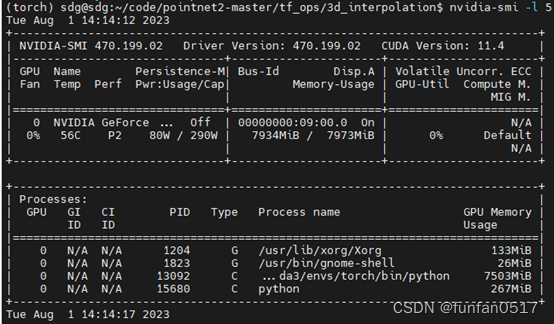
解决方案:更换显卡(推荐24G显存)