Ubuntu本地部署Nebula图数据库
操作系统:Ubuntu 20.04
硬件架构:x86_64
软件版本:nebula-graph-3.0.2、nebula-graph-studio-3.2.3
官网:https://nebula-graph.com.cn/
安装Nebula Graph核心服务
-
访问官方手册,按教程使用以下指令下载并安装nebula-graph安装包:
wget https://oss-cdn.nebula-graph.com.cn/package/3.0.2/nebula-graph-3.0.2.ubuntu2004.amd64.deb sudo dpkg -i nebula-graph-3.0.2.ubuntu2004.amd64.deb -
使用以下命令启动nebula-graph服务:
sudo /usr/local/nebula/scripts/nebula.service start all若要停止nebula-graph服务,把start改成stop即可:
sudo /usr/local/nebula/scripts/nebula.service stop all -
使用以下命令查看nebula-graph服务状态:
sudo /usr/local/nebula/scripts/nebula.service status all正常输出:
[INFO] nebula-metad(02b2091): Running as 26601, Listening on 9559 [INFO] nebula-graphd(02b2091): Running as 26644, Listening on 9669 [INFO] nebula-storaged(02b2091): Running as 26709, Listening on 9779
安装Nebula客户端
Nebula有两种免费客户端:Nebula Console和Nebula Graph Studio。其中Nebula Console是命令行工具,使用nGQL命令操作,无法可视化,因此这里不作展开,可参阅手册与github页。
下面介绍如何安装Nebula Graph Studio。
- 首先使用
sudo /usr/local/nebula/scripts/nebula.service start all命令确保已经启动nebula-graph服务; - 访问官网,下载最新版本的Nebula Graph Studio,并使用
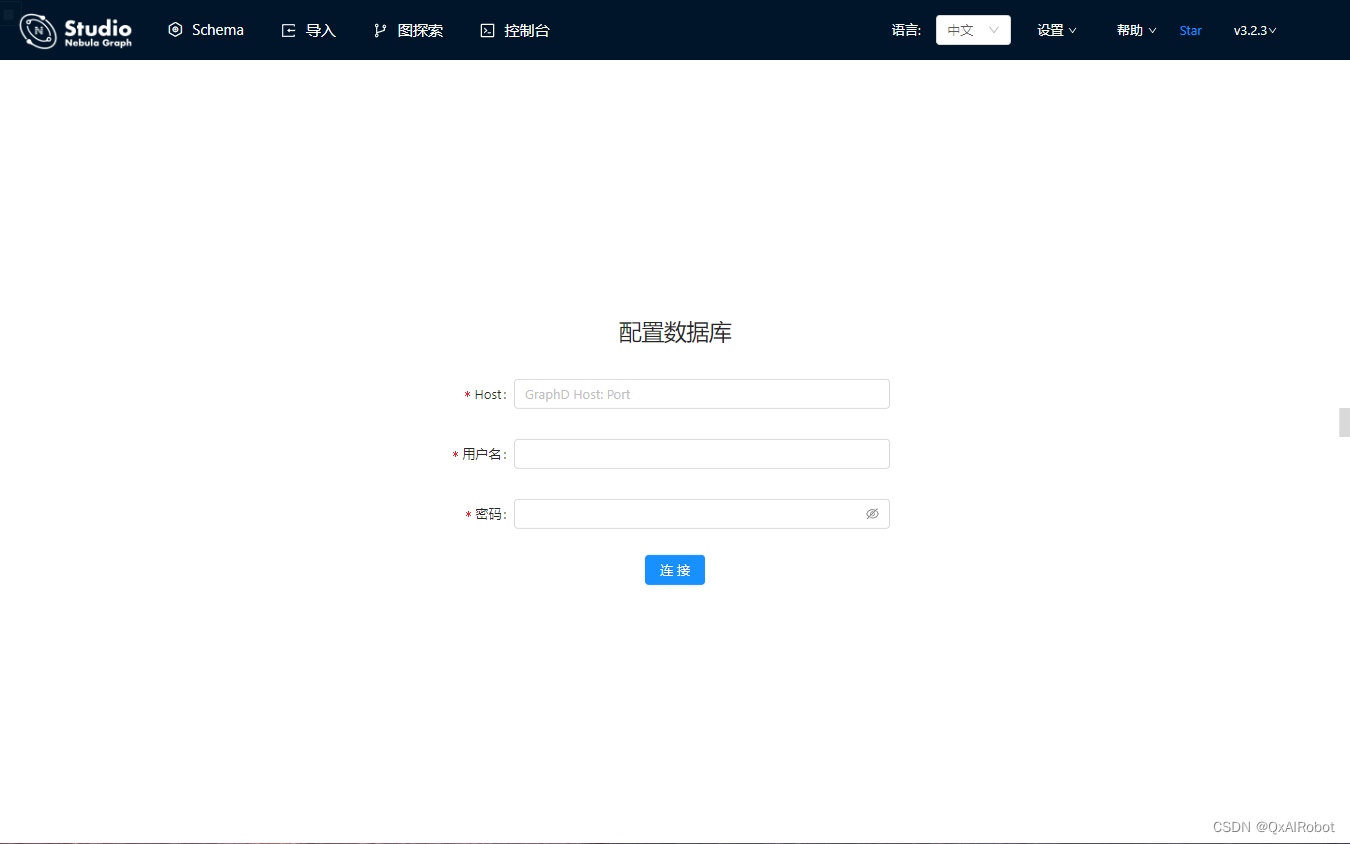
sudo dpkg -i 安装包路径命令安装; - 打开浏览器,访问http://127.0.0.1:7001,如果看到登录界面,代表安装成功。
使用Nebula Graph Studio客户端
-
首先需要准备数据,这里使用官方的示例数据,访问basketballplayer,下载并解压csv格式的原始数据表;
-
在浏览器中登录Nebula Graph Studio,输入Host:
127.0.0.1:9669,用户名:root,密码随便输入,登录; -
点击“Schema”标签,点击加号,创建一个图空间,名称为
basketballplayer,vid type选择FIXED_STRING,长度为64,描述随意添加,最后点击下方的创建;

-
创建完毕后返回“Schema”标签的图空间列表,在
basketballplayer最右侧的“操作”栏,单击扳手图标进入设置,在左侧分别为标签、边类型和索引,先创建标签; -
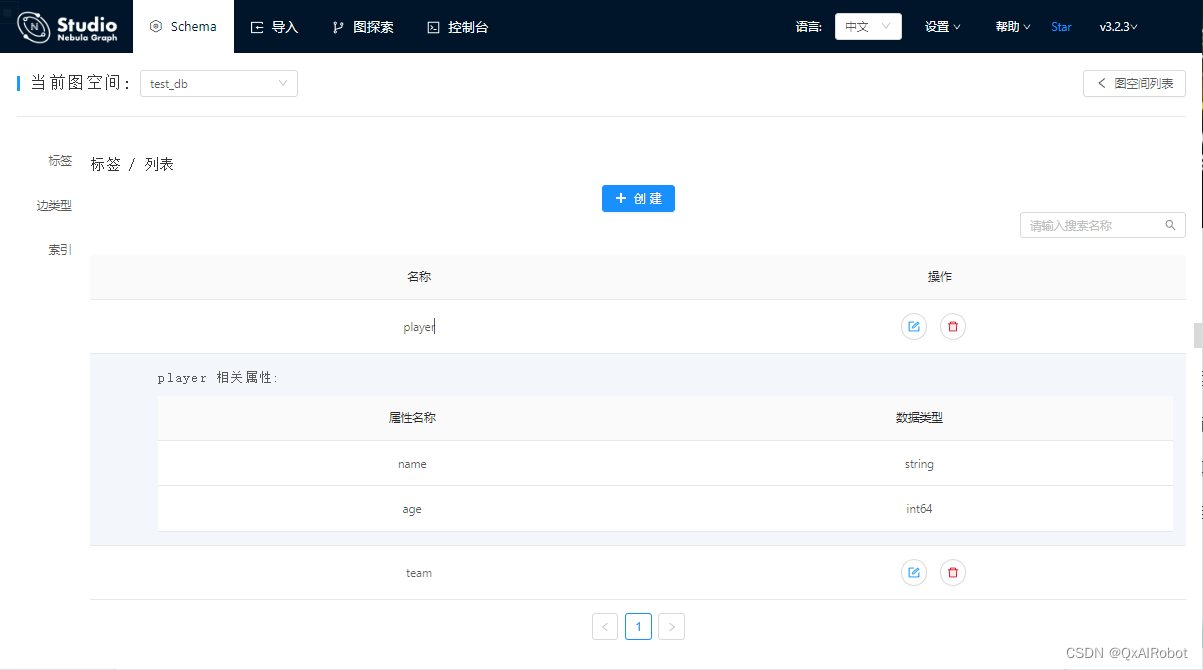
在“标签 / 列表”中点击“创建”,名称输入
player,添加两个属性,分别为string类型的name和``int类型的age`,点击最下方的“创建”;
-
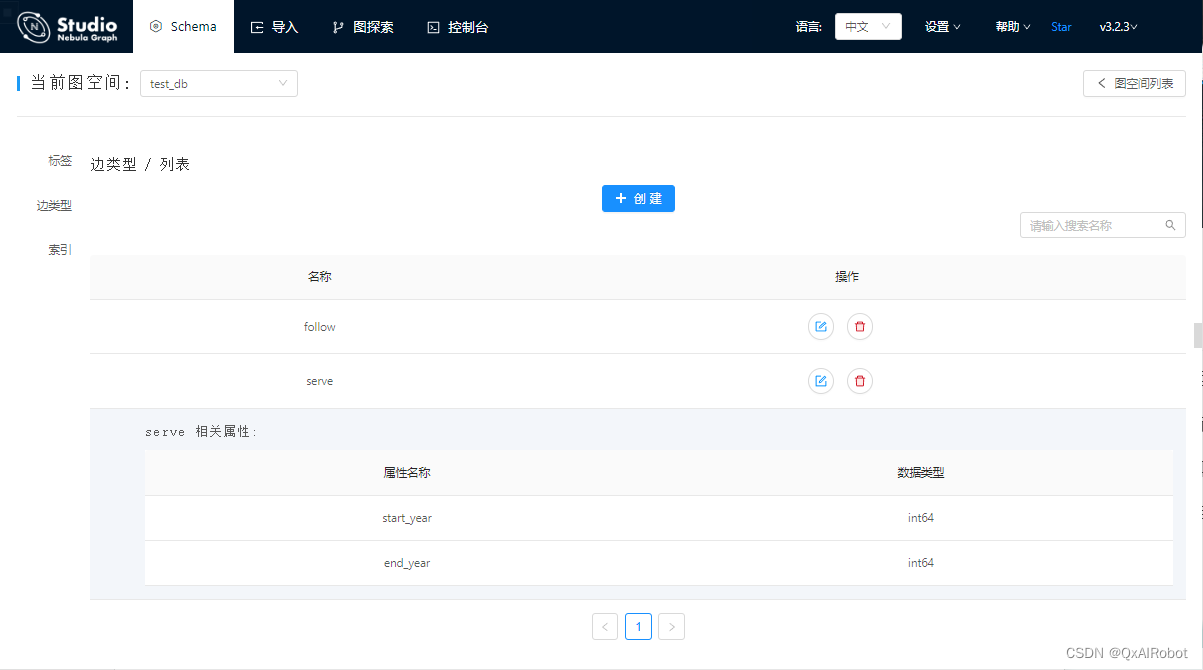
切换到“边类型 / 列表”,这里需要创建两种边,第一个名称为
follow,属性为``int类型的degree;第二个名称为serve,属性为两个int类型的start_year和end_year`;
-
切换到“导入”标签,选择刚创建的
basketballplayer图空间,下一步,在右侧点击“上传文件”,选择刚刚解压的文件,全部上传; -
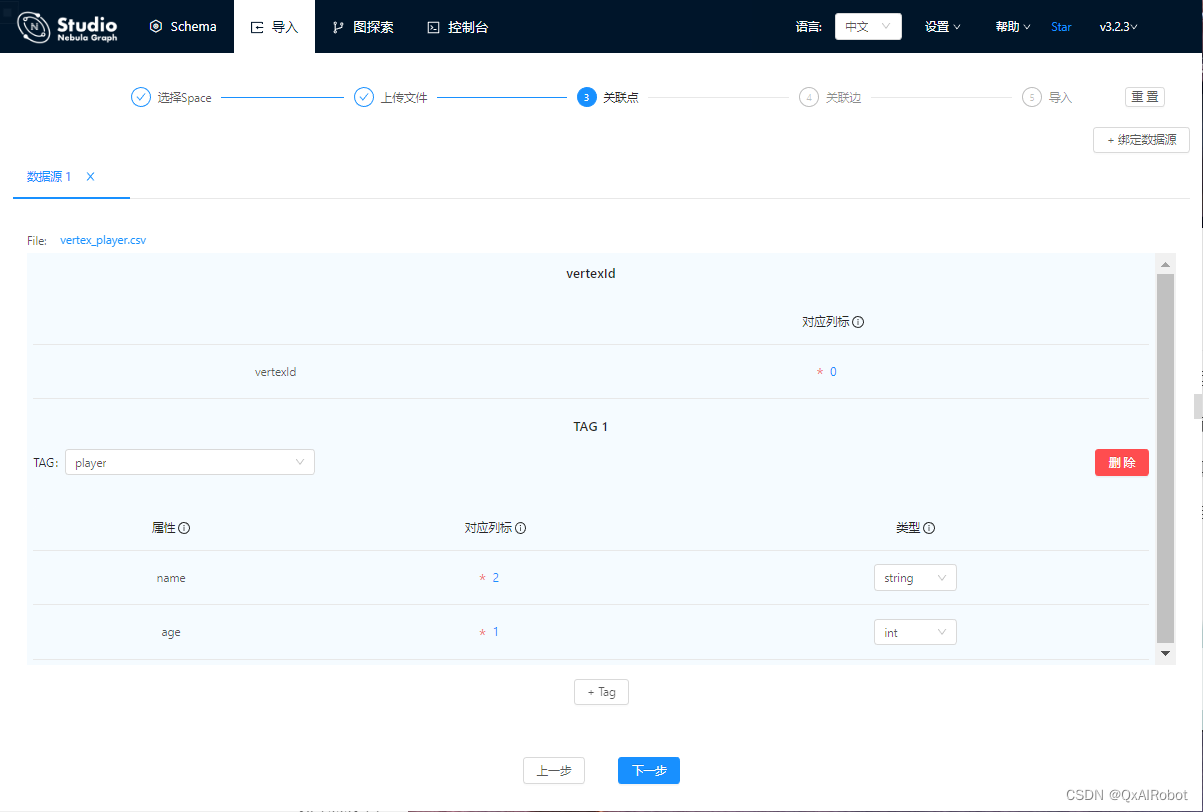
下一步为关联点,先在右上角绑定数据源:vertex_player.csv,确认后出现“数据源1”,点下方的”+Tag“,其中
vertexId选择”column0“,TAG选择player,属性name和age分别对应选择”column2“和”column1“;完成后继续右上角绑定数据源:vertex_team.csv,按刚刚的步骤完成选择;
-
下一步为关联边,先在右上角绑定数据源:edge_server.csv,确认后出现“Edge1”,类型选
server,然后srcId、dstId、start_year、end_year分别选”column0“、”column1“、”column2“、”column3“,rank不用选,忽略即可;完成后继续右上角绑定数据源:edge_follow.csv,按刚刚的步骤完成选择; -
最后一步为导入,点击”导入“后,可以在log标签看到导入过程,我的导入日志如下:
# basketballplayer导入LOG 2022/04/19 11:16:36 [INFO] clientmgr.go:28: Create 10 Nebula Graph clients 2022/04/19 11:16:36 [INFO] reader.go:64: Start to read file(0): /usr/local/nebula-graph-studio/data/upload/vertex_player.csv, schema: < :VID(string),player.age:int,player.name:string > 2022/04/19 11:16:36 [INFO] reader.go:64: Start to read file(1): /usr/local/nebula-graph-studio/data/upload/vertex_team.csv, schema: < :VID(string),team.name:string > 2022/04/19 11:16:36 [INFO] reader.go:180: Total lines of file(/usr/local/nebula-graph-studio/data/upload/vertex_player.csv) is: 51, error lines: 0 2022/04/19 11:16:36 [INFO] reader.go:180: Total lines of file(/usr/local/nebula-graph-studio/data/upload/vertex_team.csv) is: 30, error lines: 0 2022/04/19 11:16:36 [INFO] reader.go:64: Start to read file(3): /usr/local/nebula-graph-studio/data/upload/edge_serve.csv, schema: < :SRC_VID(string),:DST_VID(string),serve.start_year:int,serve.end_year:int > 2022/04/19 11:16:36 [INFO] reader.go:64: Start to read file(2): /usr/local/nebula-graph-studio/data/upload/edge_follow.csv, schema: < :SRC_VID(string),:DST_VID(string),follow.degree:int > 2022/04/19 11:16:36 [INFO] reader.go:180: Total lines of file(/usr/local/nebula-graph-studio/data/upload/edge_follow.csv) is: 81, error lines: 0 2022/04/19 11:16:36 [INFO] reader.go:180: Total lines of file(/usr/local/nebula-graph-studio/data/upload/edge_serve.csv) is: 152, error lines: 0 2022/04/19 11:16:36 [INFO] statsmgr.go:62: Done(/usr/local/nebula-graph-studio/data/upload/vertex_player.csv): Time(0.01s), Finished(51), Failed(0), Read Failed(0), Latency AVG(1183us), Batches Req AVG(1335us), Rows AVG(3721.61/s) 2022/04/19 11:16:36 [INFO] statsmgr.go:62: Done(/usr/local/nebula-graph-studio/data/upload/vertex_team.csv): Time(0.01s), Finished(81), Failed(0), Read Failed(0), Latency AVG(844us), Batches Req AVG(989us), Rows AVG(5633.51/s) 2022/04/19 11:16:36 [INFO] statsmgr.go:62: Done(/usr/local/nebula-graph-studio/data/upload/edge_follow.csv): Time(0.02s), Finished(299), Failed(0), Read Failed(0), Latency AVG(1058us), Batches Req AVG(1201us), Rows AVG(17351.25/s) 2022/04/19 11:16:36 [INFO] statsmgr.go:62: Done(/usr/local/nebula-graph-studio/data/upload/edge_serve.csv): Time(0.02s), Finished(314), Failed(0), Read Failed(0), Latency AVG(1068us), Batches Req AVG(1211us), Rows AVG(18177.00/s) -
导入完成后,切换到”图探索“标签,点击”开始探索“->“样本导入“,会随机出现几个节点,选择任意节点,在右侧的”拓展条件“面板,将”方向“设为”双向“,步数设为2,点击”拓展“,即可看到图的效果。
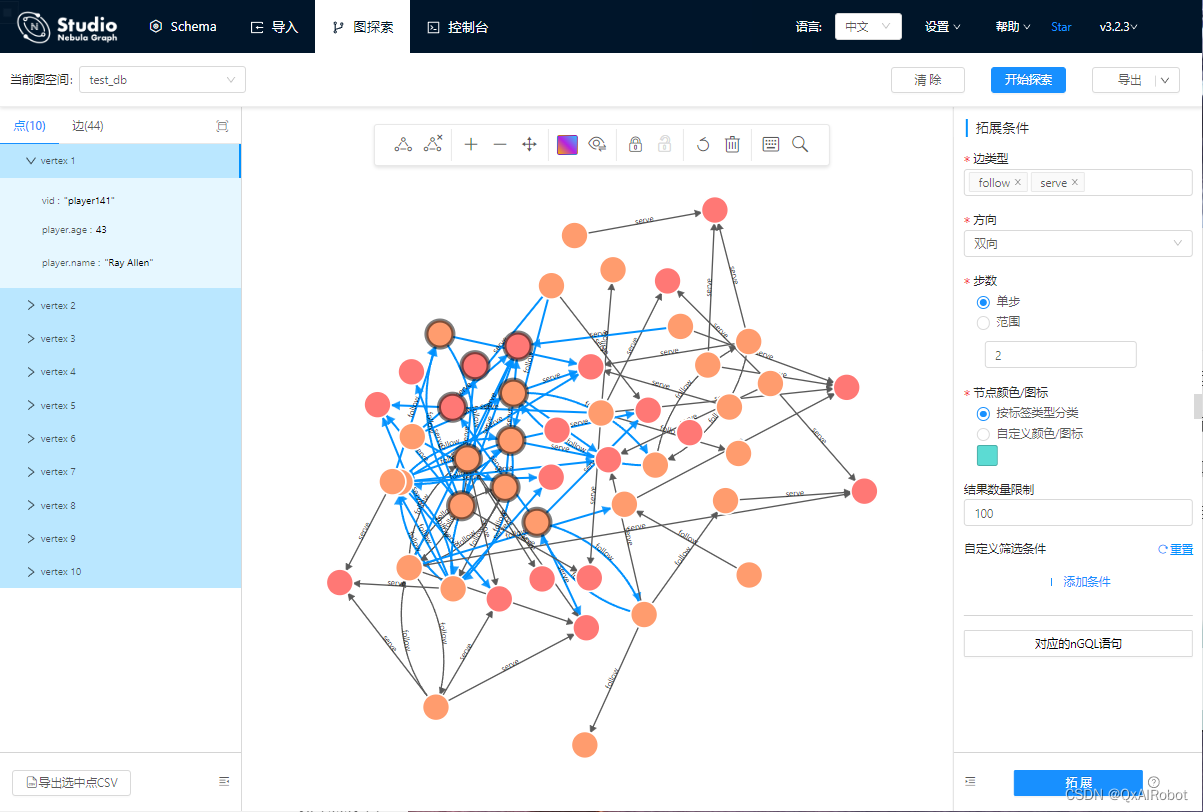
如果步数设置过大,可能会导致计算溢出进而系统崩溃。此时需要在终端运行
sudo /usr/local/nebula/scripts/nebula.service start all重启系统。
后面我会再写一篇在Nebula中导入和测试twitter2010社交关注数据集的文章,敬请关注!