一、 groupby 依据某列分组; groupby 依据多列分组;
二、应用 mean sum count std median size max min等函数聚合数据;
三、transform 不改变数据形状(相当于计算后替换原来的每一个元素)
一、分组

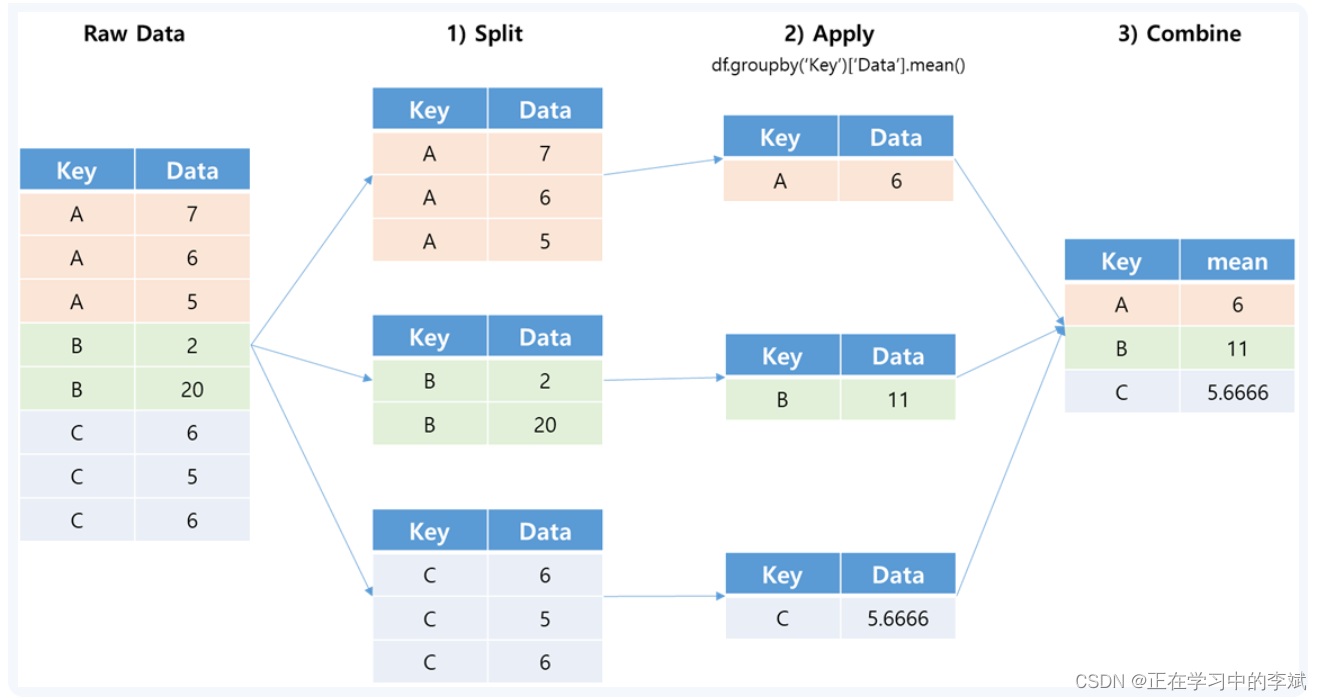
分组功能主要利用pandas的groupby函数。虽然分组功能用其他函数也可以完成,但是groupby函数是相对来说比较方便的。这个函数有很多神奇的功能,熟练后功能十分强大。groupby函数的官方参数说明如下:

import pandas as pd
import glob
# 获取该目录下的所有文件
files = glob.glob('../../data/03表格数据处理Pandas/C3.7 数据的分组与聚合/*')
# 利用 concat 将所有数据拼接成一个大的 df
df = pd.concat([pd.read_csv(f) for f in files])
# 删除列(值全为空);删除行(存在任意空值)
df = df.dropna(axis='columns', how='all').dropna(axis='index', how='any')
# 对 date 这一列进行格式转换
df['date'] = df.apply({
'date': lambda x: pd.to_datetime(x, format='%Y%m%d')})
# 获取到 月 和 天
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
# 删除 date 列
df = df.drop(columns='date')
# 简单分组
# 分组后的数据想要查看,必须循环打印
group = df.groupby('type')
for i in group:
print(i)
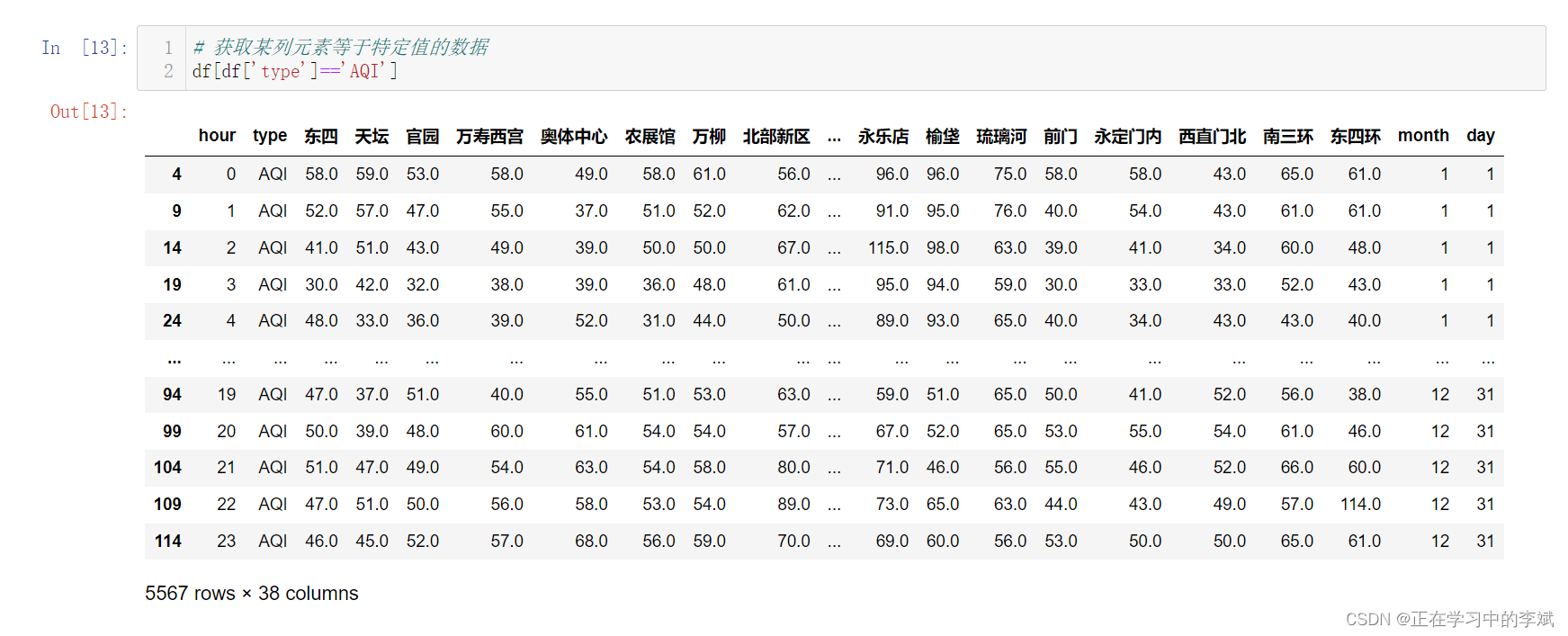
# 获取某列元素等于特定值的数据
df[df['type']=='AQI']
# 多重分组
# 分组后的数据想要查看,必须循环打印
group = df.groupby(['type', 'month'])
for i in group:
print(i)
# 获取同时满足多个列条件的数据
df[(df['type']=='AQI') & (df['month']==1)]
二、聚合
所谓聚合就是在对数据进行合理分组后,再根据需要对数据进行的一列操作,比如求和、转换等。聚合函数通常是数据处理的最终目的,数据分组很多情况下也是为更好聚合来服务的。
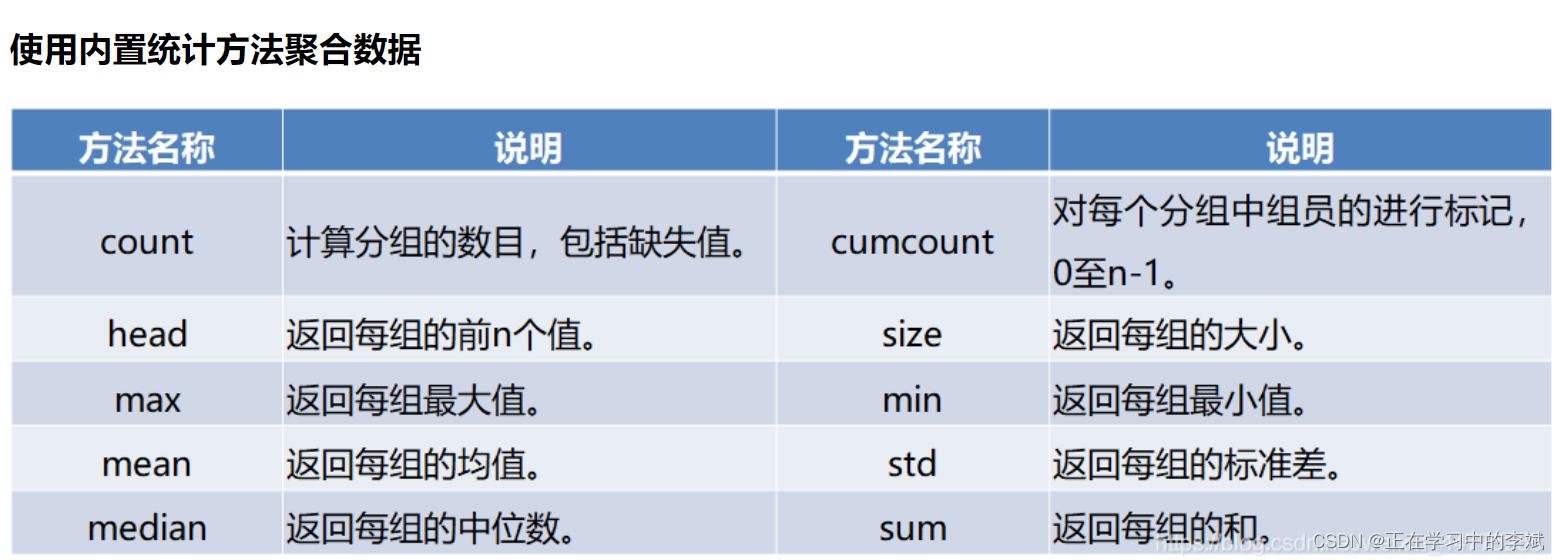
1. 使用内置函数聚合
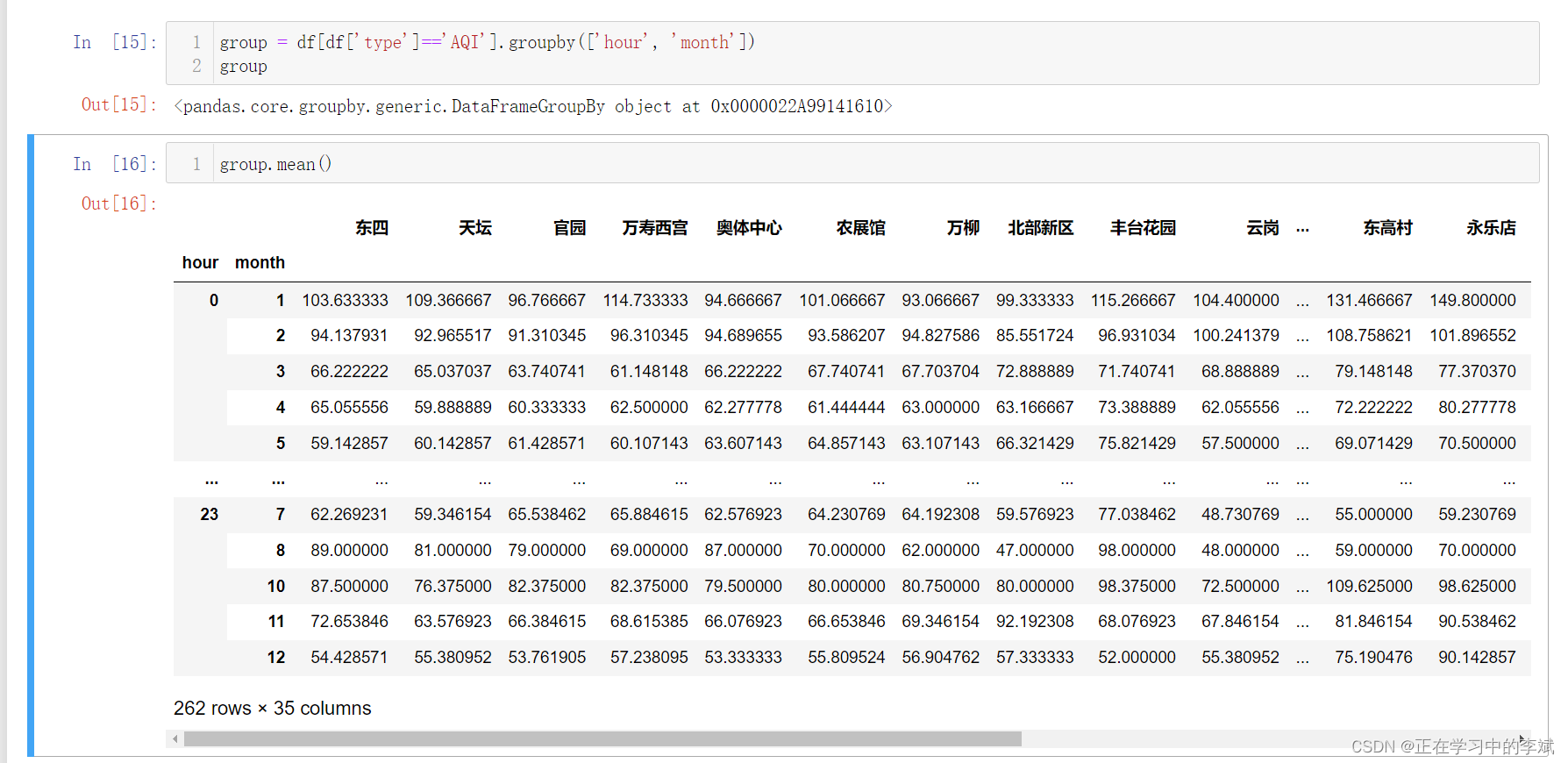
# 对type列所有值等于AQI的数据进,行多重分组
group = df[df['type']=='AQI'].groupby(['hour', 'month'])
# 使用内置的方法,进行求平均值聚合,得到每个月每小事的平均值
group.mean()
2. 利用agg进行简单的聚合
# 对所有列数据应用相同函数的两个函数
group.agg([np.mean, np.std])
# 传入字典格式的数据
# 对不同列数据应用不同函数
group.agg({
'东四': [np.mean, np.std], '天坛': [np.min, np.max]})
三、transform函数
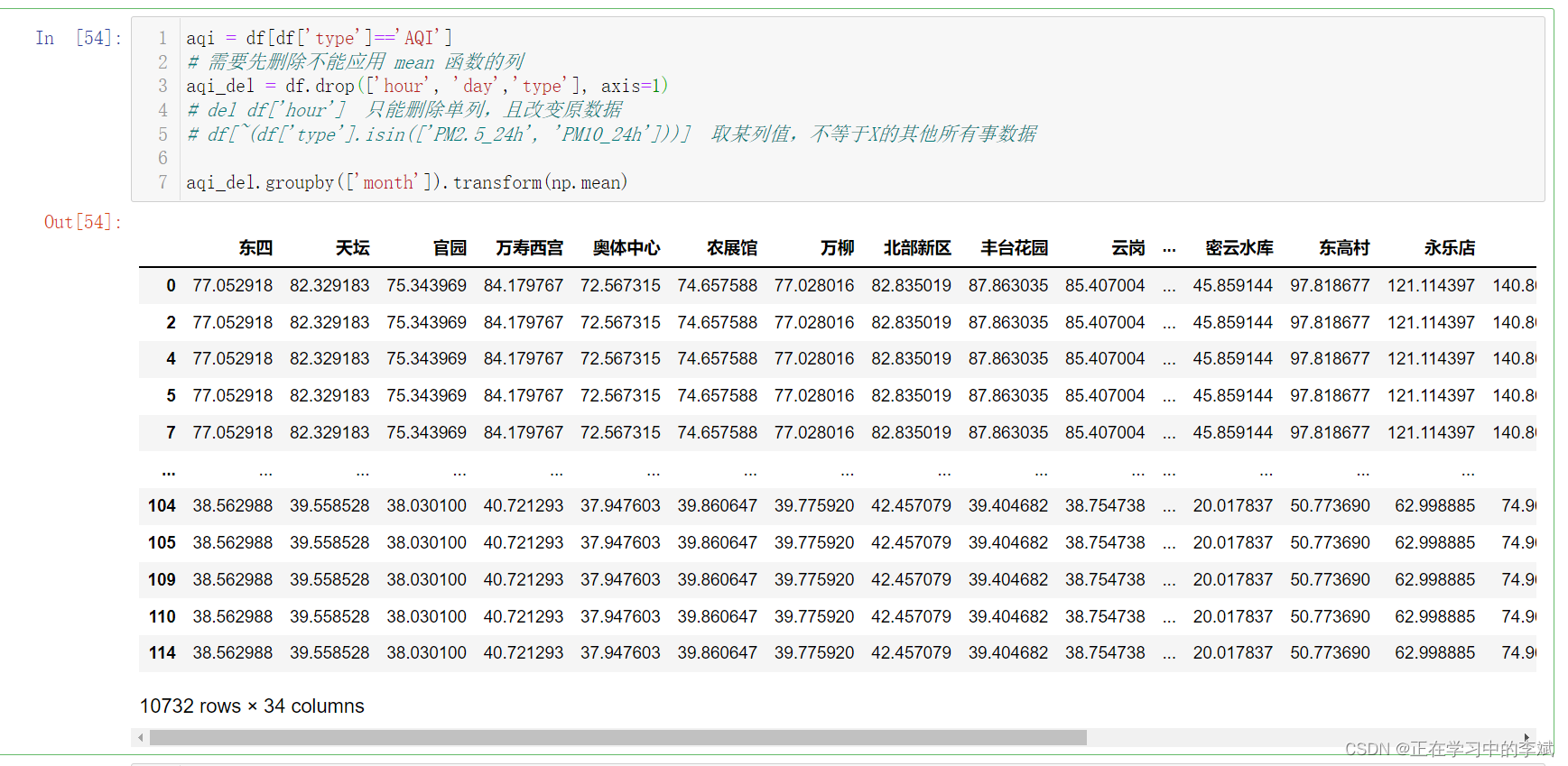
使用transform函数对groupby对象进行变换,transform的计算结果和原始数据的形状保持一致。
使用内置聚合函数或者agg会改变数据的形状,请对比上图中数据的行和列数。但是使用 transform 将不会改变数据的形状,相当于用算出来的值,替换原数据中的每一个值。
import pandas as pd
import glob
import numpy as np
files = glob.glob('../../data/03表格数据处理Pandas/C3.7 数据的分组与聚合/*')
df = pd.concat([pd.read_csv(f) for f in files])
df = df.dropna(axis='columns', how='all').dropna(axis='index', how='any')
df['date'] = df.apply({
'date': lambda x: pd.to_datetime(x, format='%Y%m%d')})
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df = df.drop(columns='date')
aqi = df[df['type']=='AQI']
# 改变数据形状
aqi.groupby(['month']).agg(np.mean)
# 不改变数据形状 应用内置函数
aqi.groupby(['month']).transform(np.mean)
# 不改变数据形状 应用匿名函数
aqi.groupby(['hour', 'month']).transform(lambda x: x - x.mean())
扫描二维码关注公众号,回复:
16021373 查看本文章
