一、groupby函数
首先先来看网上最经典的解释
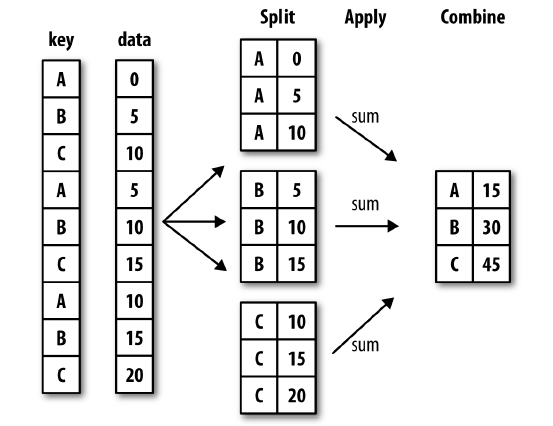
即对不同列进行再分类,标准是先拆分再组合(如果有操作,比如sum则可以进行操作);就是我们读取文件一般有很多列,如果我们按列进行分类,那么就先把列一样的挑出来。
1、分组原理
核心:
(1)不论分组健是数组、列表、字典、series、函数,只要与其待分组变量得轴长度一致,都可以传入groupby进行分组。
(2)默认axis=0,按行分组;可指定axis=1,按列分组。
对数据进行分组操作得过程可以概括为:split-apply-combine三步:
(1)按照键值(key)或者分组变量将数据分组;
(2)对于每组应用我们的函数,这一步非常灵活,可以是python自带得函数,也可以是我们自己编写得函数。
(3)将函数计算后得结果聚合。
举例说明:
import pandas as pd
import numpy as np
df = pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df 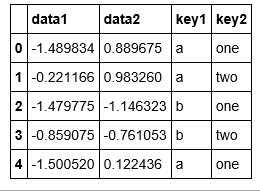
(1) 我们将key1当作我们得分组键值,对data1进行分组,再求每组得均值:
grouped = df['data1'].groupby(df['key1'])语法很简单,但是这里需要注意的是grouped的数据类型,它不是一个数据框,而是一个GroupBy对象。
grouped ![]()
实际上,在这一步,我们并没有进行任何计算,仅仅是用key1分组并创建了一个GroupBy对象,我们后面函数的任何操作都是基于这个对象的。
求均值:
grouped.mean() 
(2)刚刚我们只是用key1进行了分组,我们也可以使用两个分组变量,并且通过unstack方法进行结果重塑:
means = df['data1'].groupby([df['key1'],df['key2']]).mean()
means 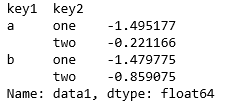
means = df.groupby([df['key1'],df['key2']]).mean()
means 
(3)以上我们的分组变量都是df内部的series,实际上只要和key1等长的数组就可以:
states = np.array(['Ohio','California','California','Ohio','Ohio'])
years = np.array([2005,2005,2006,2005,2006])
df['data1'].groupby([states,years]).mean() 
2、对分组进行迭代
(1) GroupBy对象支持迭代操作,会产生一个由分组变量名和数据块组成的二元元组:
for name,group in df.groupby(df['key1']):
print(name)![]()
print(group)
(2) 如果分组变量有两个:
for (k1,k2),group in df.groupby([df['key1'],df['key2']]):
print(k1,k2)
print(group) 
(3) 我们可以将上面的结果转化为list或者dict,来看看结果是什么样的:
list(df.groupby(['key1','key2'])) 
看不太清楚,我们来看这个列表的第一个元素:
list(df.groupby(['key1','key2']))[0]
同样,我们也可以将结果转化为dict(字典):
dict(list(df.groupby(['key1','key2']))) 
dict(list(df.groupby(['key1','key2'])))[('a','one')] 
以上都是基于行进行分组的,因为默认情况下groupby是在axis=0方向进行分组,我们可以指定axis=1方向(列方向)进行分组。
注意:
#下面两段语句功能一样
df.groupby('key1')['data1']
df.data1.groupby(df.key1)
(4) 通过函数进行分组
对于一些复杂的需求,我们可以直接对groupby函数传递函数名来进行分组,如果我们想按行分组,分组的key是每个人名的字母长度,来实验以下:
df = pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)},index=['joe','steve','wes','jim','travis'])
df 
l = [len(x) for x in df.index]
df.groupby(l).mean()
二、agg函数
聚合函数,对分组后数据进行聚合,默认情况对分组后其他列进行聚合。
import pandas as pd
df = pd.DataFrame({'Country':['China','China', 'India', 'India', 'America', 'Japan', 'China', 'India'],
'Income':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000],
'Age':[5000, 4321, 1234, 4010, 250, 250, 4500, 4321]})

df_agg = df.groupby('Country').agg(['min', 'mean', 'max'])
print(df_agg)
对分组后的部分列进行聚合,某些情况下,只需要对部分数据进行不同的聚合操作,可以通过字典来构建
num_agg={'Age':['min','mean','max']}
print(df.groupby('Country').agg(num_agg))
num_agg={'Age':['min','mean','max']}
print(df.groupby('Country').agg(num_agg))