代码用的是b导的
整个训练流程也是根据b导的视频来的
源码地址:https://github.com/bubbliiiing/unet-pytorch
博客地址:https://blog.csdn.net/weixin_44791964/article/details/108866828
# 一、准备数据集
1、使用labelme软件标注数据,得到json文件
注意:图片格式为.jpg,位深为24位,否则无法标注。
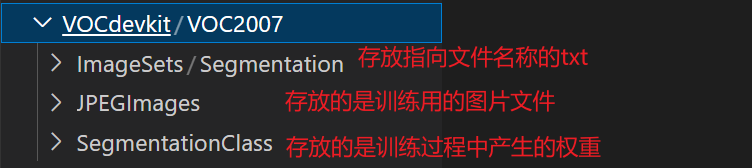
2.数据集的格式
SegmentationClass里的存放的是JPEGImages里的图片标注过后的png图片
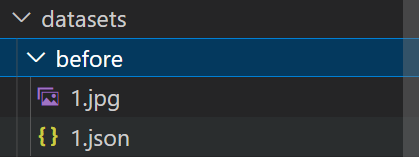
3.制作自己的数据集
把原始图像放在datasets>before里
before里含有jpg的原始图片和json的标注文件
使用labelme生成json的标注文件
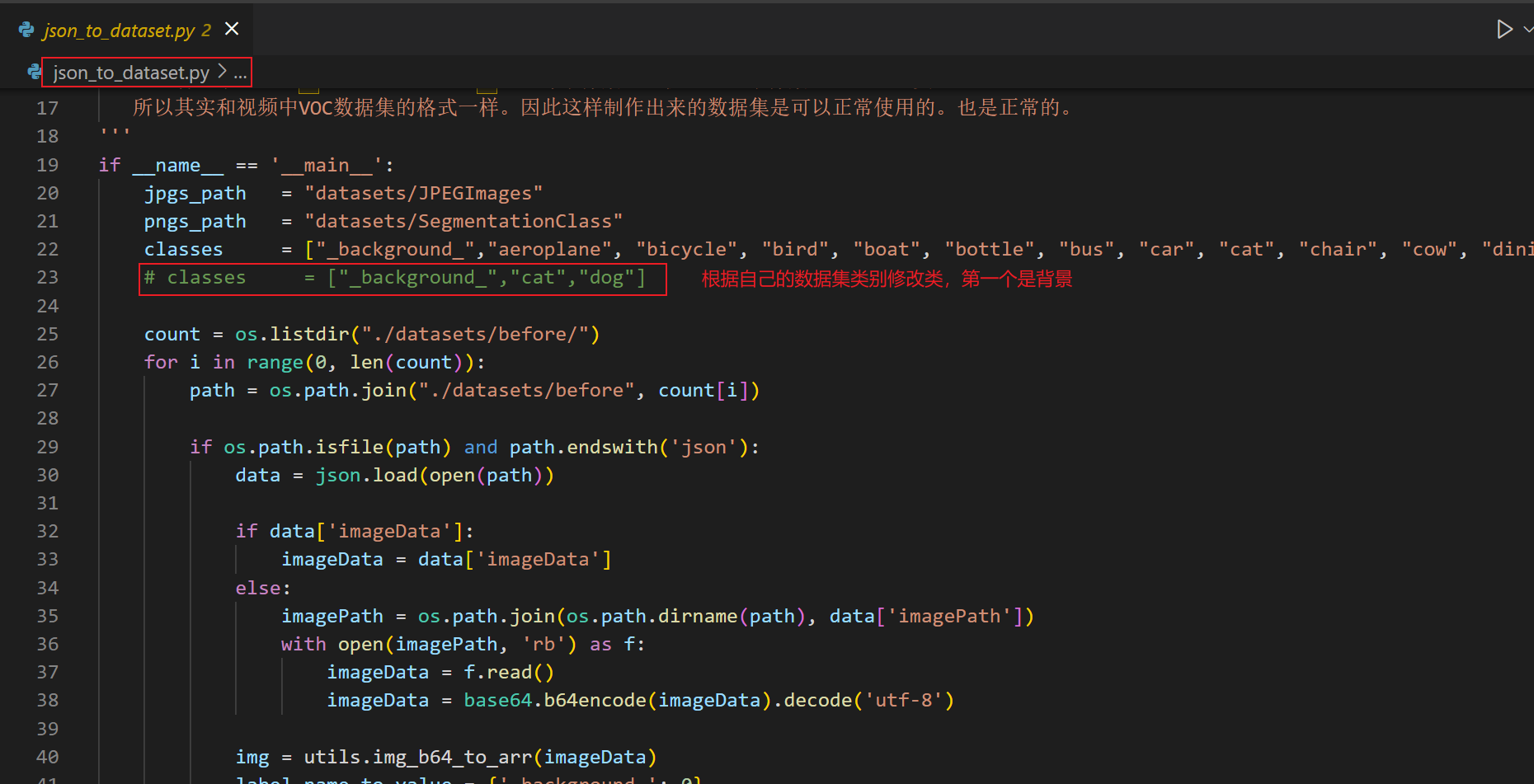
4.运行json_to_dataset.py
完成图片的标注后,可以运行根目录下的json_to_dataset.py文件,将数据转化为固定的格式。
运行前需要修改类
json_to_dataset.py运行完成后saved 1.jpg and 1.png 分别存放在JPEGImages和SegmentationClass
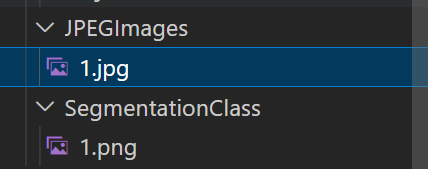

最后,可以把在dataset里生成后的JPEGImags和SegmentationClass文件复制到VOCdevkit里的JPEGImags和SegmentationClass文件。
5.训练集和验证集划分
运行voc_annotion.py文件后生成train.txt文件和val.txt文件
二、训练
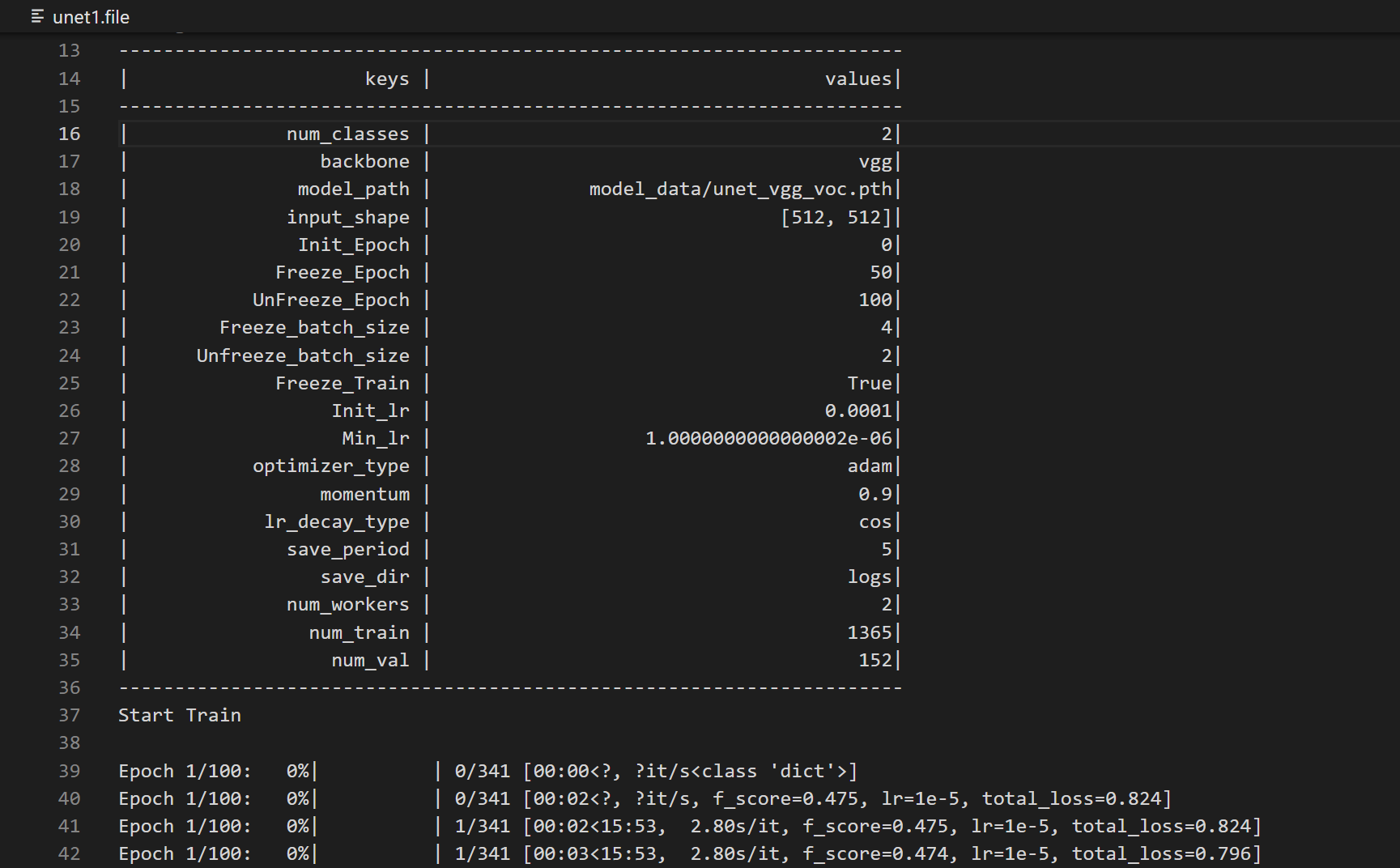
1train.py文件中参数设置
Cuda 是否使用cuda,没有gpu可以设置为False
num_classes 数目为分类个数+1,这里的1是background
model_path 预训练权重
VOCdevkit_path=‘VOCdevkit’ 数据集路径
2.训练自己的数据集
python train.py
训练后保存的文件在根目录的logs文件夹下
3.利用训练好的模型进行预测
unet.py文件中
修改model_path和num_classes
model_path指向logs文件夹下的权值文件
num_classes为类别个数+1
运行predict.py文件,预测图片
需要输入你要预测的图片的路径
4.Miou评价指标计算
修改model_path和num_classes
model_path指向logs文件夹下的权值文件
num_classes为类别个数+1
修改name_classes
运行get_miou.py