本文为转载,原博客地址:https://blog.csdn.net/justpsss/article/details/77170004#
FCN
论文《Fully Convolutional Networks for Semantic Segmentation》
这篇论文作为用CNN来做语义分割的开山之作,意义还是非常之大的,目前其他的语义分割模型基本上都是在FCN的基础上做的一些改进。
语义分割指的是对图片上的每一个像素所属的类别进行分类,可以应用在图像识别、分割、检测等领域,目前来看最好的应用场景是在自动驾驶上,用于识别道路、行人、车辆等等。
全卷积
FCN(Fully Convolutional Networks)全卷积,意思就是该网络中没有全链接层,全部用卷积层来代替了 ,全卷积化也是其他领域深度模型的一个趋势,除了分类网络最后必须保留一个全链接层用于分类外,其他领域都有去掉全链接层的趋势,如检测领域的R-FCN等。
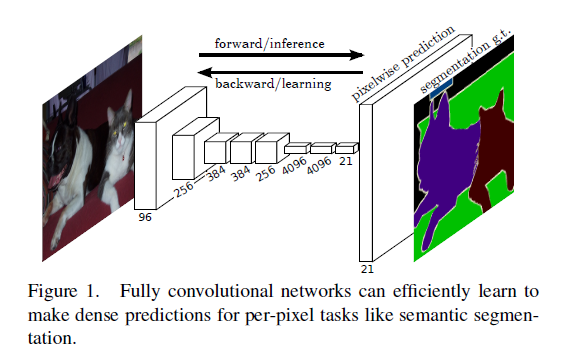
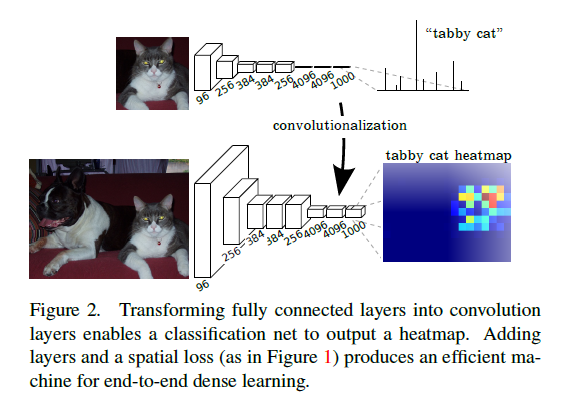
从Figure 2中,我们可以看到,上面是一个CNN的分类网络,最后三个全链接层做推断,最后产生一个1000类的分类概率,其中cat的概率最高,因此识别出图片中是猫;下面是FCN的分割网络,区别就在于把上面的CNN最后三个全链接层改成了卷积层,最后经过若干个上采样层,将特征图扩大到跟原图同样大小的若干张概率图,每张概率图表示这个像素属于该类别的概率值,也就是上图的heatmap。
FCN中上采样使用的方法是逆卷积。
逆卷积
所谓的逆卷积(deconvolution)实际上是一个转置卷积的操作,因此在一些深度框架中都把逆卷积定义为convolution transpose,具体的操作很多大佬在博客,知乎,github上都有介绍了,这里贴一下Matconvnet-manual文档中的介绍,纪念一下我用过这个框架(破涕为笑;

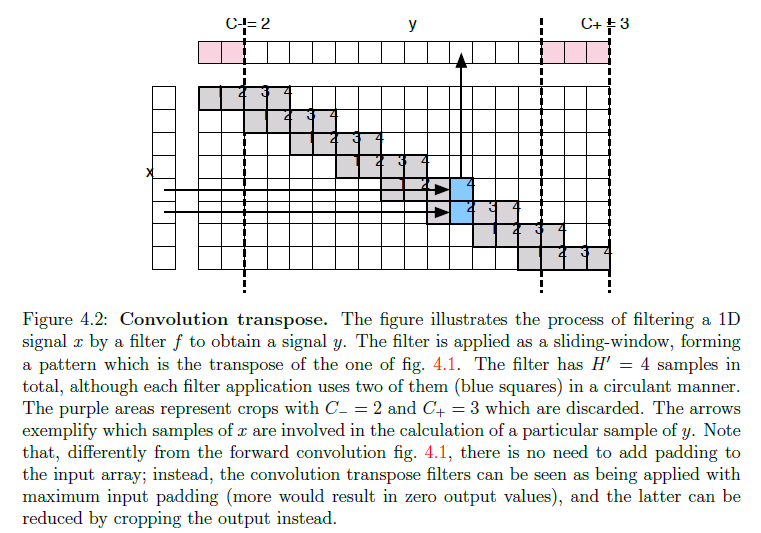
ps:论文中逆卷积核的初始化方法使用的是双线性插值。
Skip net
跳跃融合是为了获得更加精细的分割结果,我们先看下图:
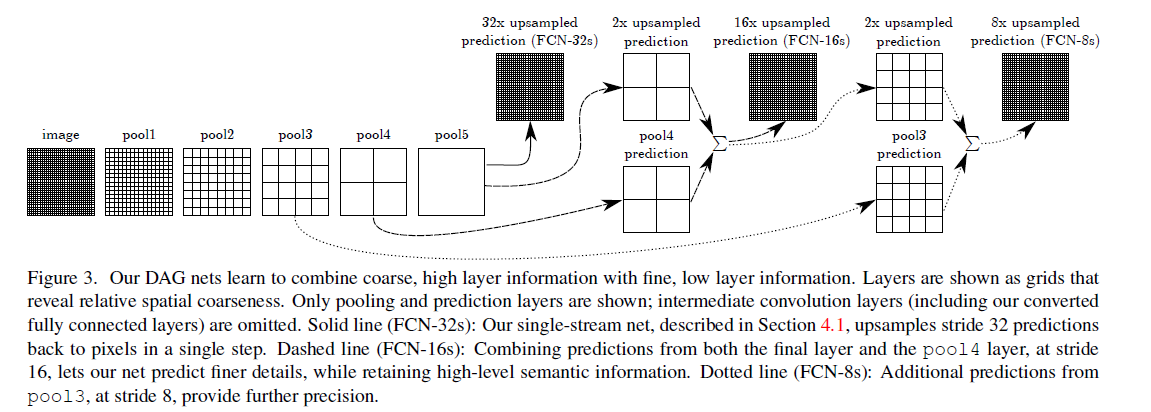
这里用的是VGG为例,pool1到pool5是五个最大池化层,因此图中的pool5层的大小是原图image的1/32(1/251/25),最粗糙的做法就是直接把pool5层进行步长为32的上采样(逆卷积),一步得到跟原图一样大小的概率图(fcn-32s)。但是这样做会丢失掉很多浅层的特征,尤其是浅层特征往往包含跟多的位置信息,所以我们需要把浅层的特征加上来,作者这里做法很简单,就是直接“加”上来,求和操作,也就完成了跳跃融合。也就是先将pool5层进行步长为2的上采样,然后加上pool4层的特征(这里pool4层后面跟了一个改变维度的卷积层,卷积核初始化为0),之后再进行一次步长为16的上采样得到原图大小的概率图即可(fcn-16s)。另外fcn-8s也是同样的做法,至于后面为什么没有fcn-4s、fcn-2s,我认为是因为太浅层的特征实际上不具有泛化性,加上了也没什么用,反而会使效果变差,所以作者也没继续下去了。
FCN分割的结果是比较粗糙的,后面有改进的结构在FCN的结果上再进行精细分割,如加上CRF(条件随机场)等等,另外为了使深层的特征图尺度不至于太小,FCN在原图上加了100个像素的pad,这非常的不优雅啊!后面的结构有提出一个孔算法来改进这个问题,以后写另一个分割模型deeplab的时候再详细说。
FCN基本介绍的差不多了,下面介绍一个在医学图像分割领域很出名的一个全卷积网络——U-Net。
U-Net
论文《U-Net: Convolutional Networks for Biomedical Image Segmentation》
官网:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
有了上面FCN的基础,我们先直接贴U-Net的网络结构:
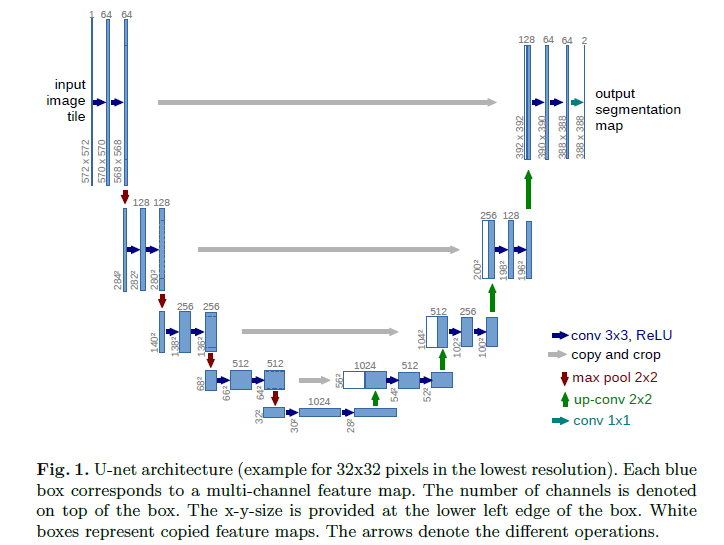
整个网络结构看起来像一个”u”型,因此叫做U-Net。整个网络的思路跟FCN是差不多的,一个区别是它没有用VGG等CNN模型作为预训练模型,因为u-net做的是医学图像的二值分割,没必要用ImageNet的预训练模型,而且u-net这个结构我们是可以根据自己的数据集自由加深网络结构的,比如在处理具有更大的感受野的目标的时候;另一个区别是u-net在进行浅层特征融合的时候,采用的是叠加的做法,而不是FCN中的求和操作,也就是上图中的白色模块,是直接从左边的蓝色模块叠加过来的(如果是在Caffe中实现的,u-net是Concat层,而fcn是Eltwise层)。
另外,u-net中有一个坑,那就是所有的卷积过程都是没有加pad的,这样就会导致每做一次卷积,特征的长宽就会减少两个像素,最后网络的输出和输入大小不一样。比如上图中,输入的图片大小是572x572,输出的概率图大小是388x388。
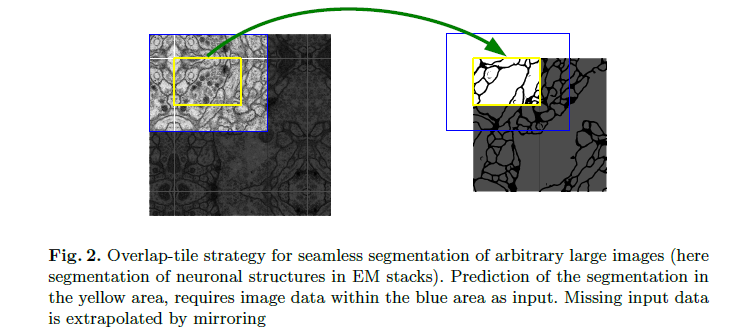
作者这么做的原因是为了数据增强,毕竟作者只用了30张原图做训练集。论文中介绍了一个叫overlap-tile的数据增强的方法,就是上图这个,左图中间的白色框区域是原始图片,旁边的一圈是加了镜像的,然后取左图中蓝色框中区域作为一张训练图,它对应的label就是黄色框的区域,是不是特别绕?如果想详细了解的话,还是去看看官方给的代码吧。虽然官方代码中只给了一个测试网络的demo代码,但是可以推出作者做这个overlap-tile的步骤的(实际上是我给作者发邮件想要数据增强的代码和训练网络的solver文件,作者没吊我(破涕为笑;所以不得不自己去啃demo代码)。
另外论文中提到了加权loss函数,也就是有一个weight map,然而我在作者官网给的prototxt文件中没有发现使用加权loss函数的迹象,不知道有没有研究比较深的大佬给我解个惑,感激不尽!
ps:U-Net在GAN网络中貌似也有比较广泛的应用,以后慢慢了解吧。