继续上一篇的内容:
上一篇的最后我们讲到了web根目录,知道了在一个网页中资源都是存放在web根目录下的,我们上一篇用http的时候直接给了响应正文一个硬链接,实际上这种做法是不规范的:

下面我们重新设计一下正文部分:
首先我们写一个读取文件的函数,未来正文的资源我们会放在文件中,所以直接在文件读数据就好了。
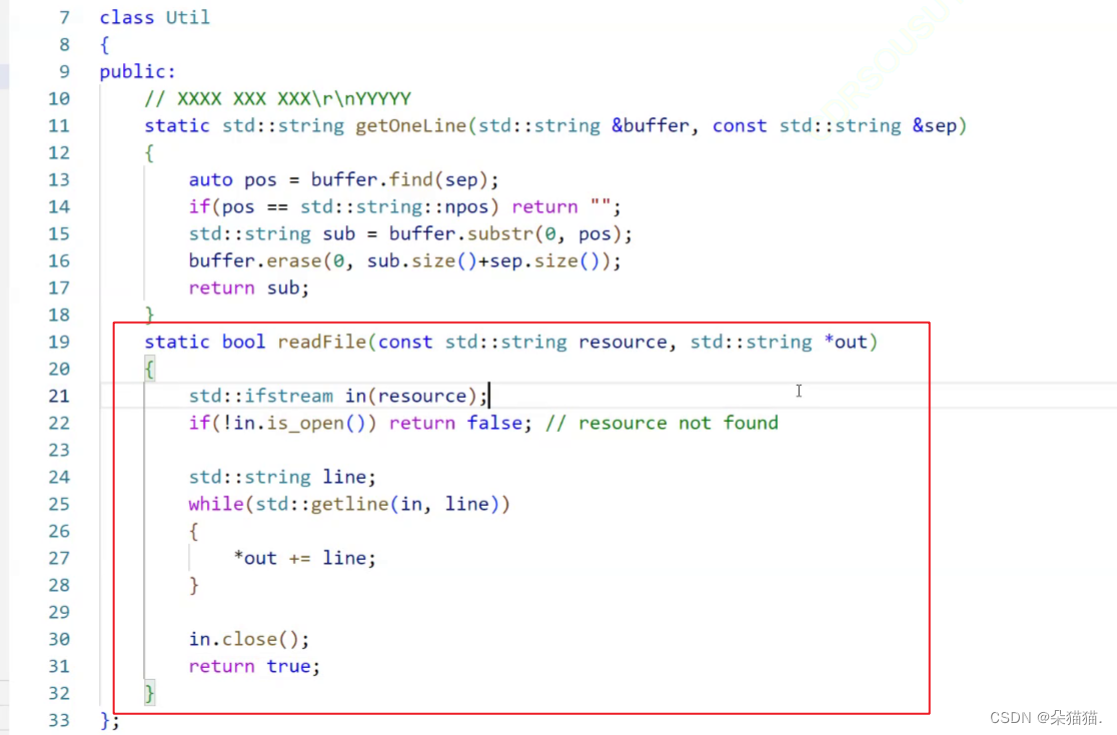
我们的第一个参数是读取的文件路径,第二个参数是输出型参数,未来将读出来的数据会放在out中,这里读取的时候用任意读取方式即可,然后我们判断是否打开文件成功,如果成功则将每一行数据从文件读取到一个新的string对象中,然后让out加等读取到的数据即可,在返回前将文件关闭。
因为我们在某个路径读取数据的时候有可能因为用户输入错误的路径而读取失败,这个时候我们就应该返回404,而404也是存在于根目录下的所以我们创建一个404文件:
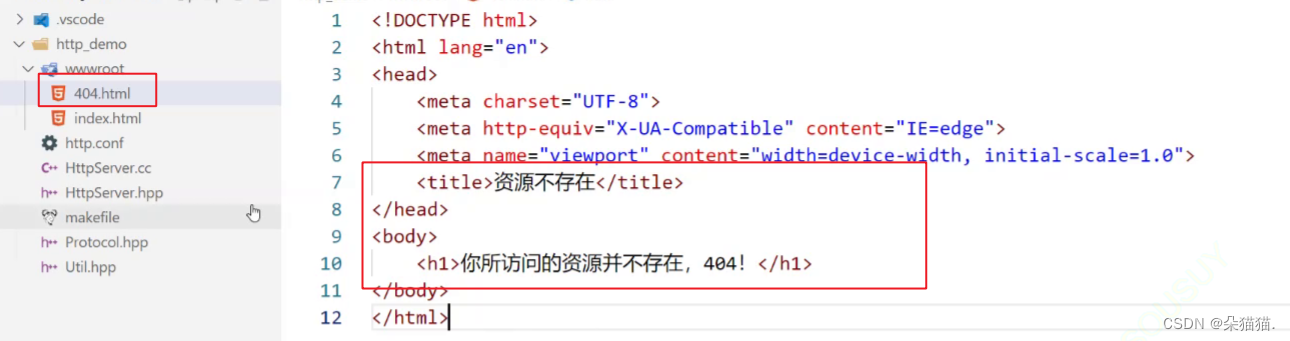
然后我们定义一个string对象来保存这个路径:

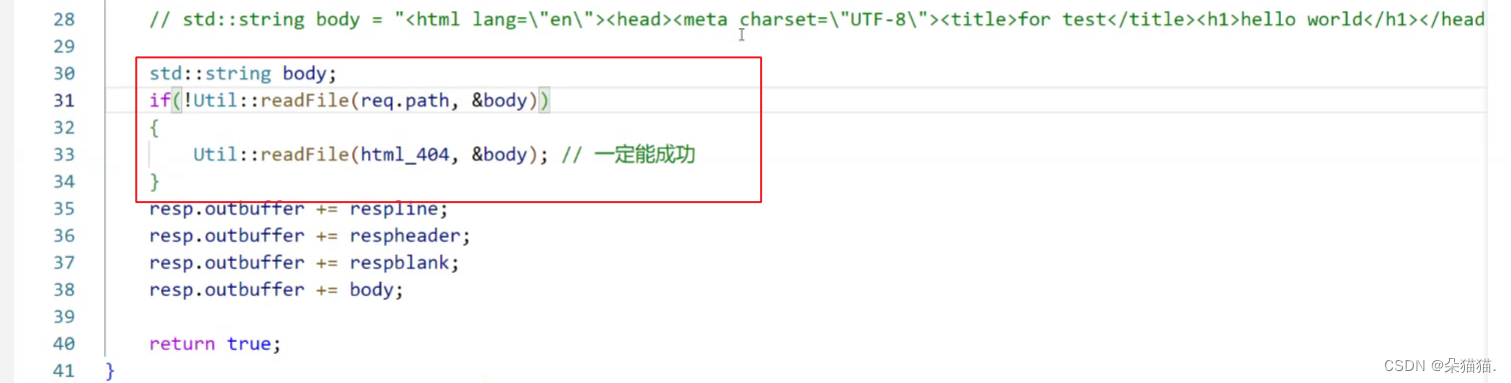 然后我们就将正文部分修改过来了,我们在readFile中读取数据实际上还是有问题的,这个问题我们后面再说。
然后我们就将正文部分修改过来了,我们在readFile中读取数据实际上还是有问题的,这个问题我们后面再说。
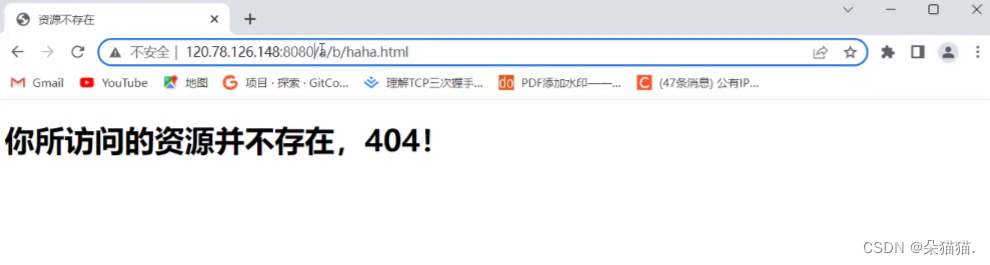
运行起来后,当我们以不存在的路径访问服务器时,就会给我们显示资源不存在:
 当然我们也可以让网页多一个跳转的按钮,首先在web根目录再创建一个文件夹,然后创建两个html文件,分为a网页和b网页:
当然我们也可以让网页多一个跳转的按钮,首先在web根目录再创建一个文件夹,然后创建两个html文件,分为a网页和b网页:

然后我们在网站首页加入跳转按钮:
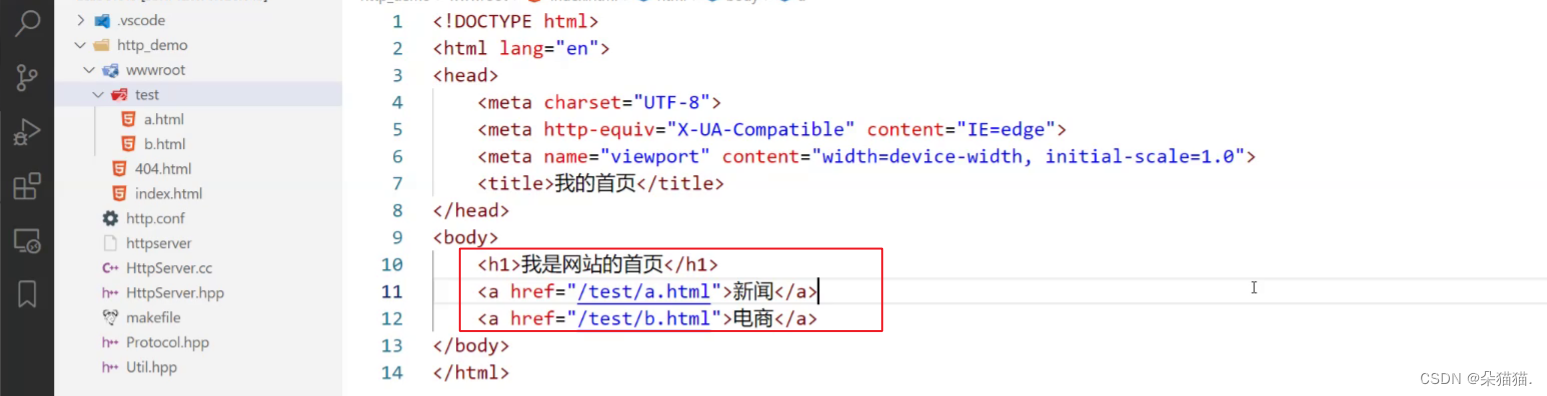
下面我们运行起来看看:
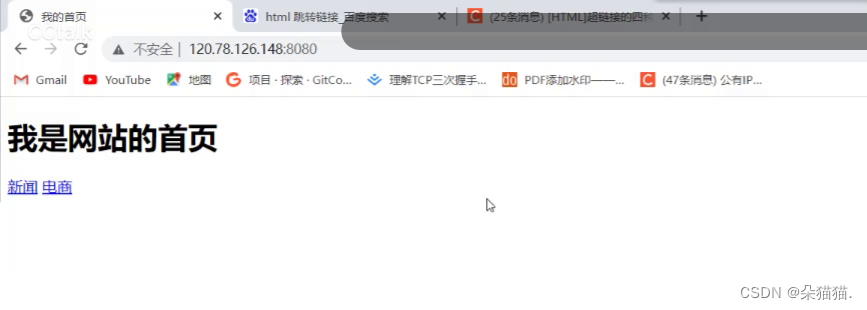
可以看到是没问题的,我们点击就会跳到新闻的资源所在路径或者电商的资源所在路径。
当然也可以在a网页中加入返回按钮:
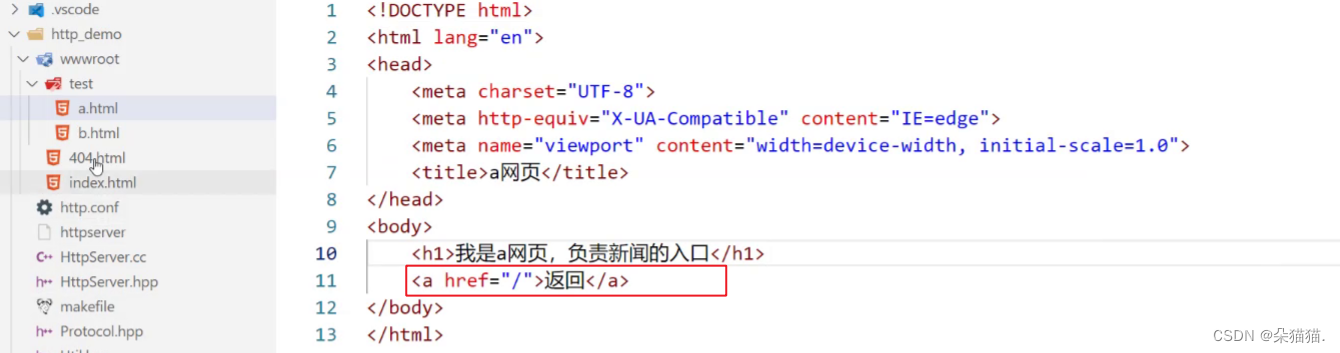
这些都是前端的知识我们就不操作了, 我们继续讲解后端的知识:
之前在响应行中我们为了演示填了一个确定的content-type对照表中的值,而实际上网页中不仅有html资源,还有像jpg照片类格式的,所以我们需要写一个函数,当我们资源是什么类型的时候,我们的函数自动返回content-type对照表中的值要完成这个工作首先需要截取资源类型的后缀。
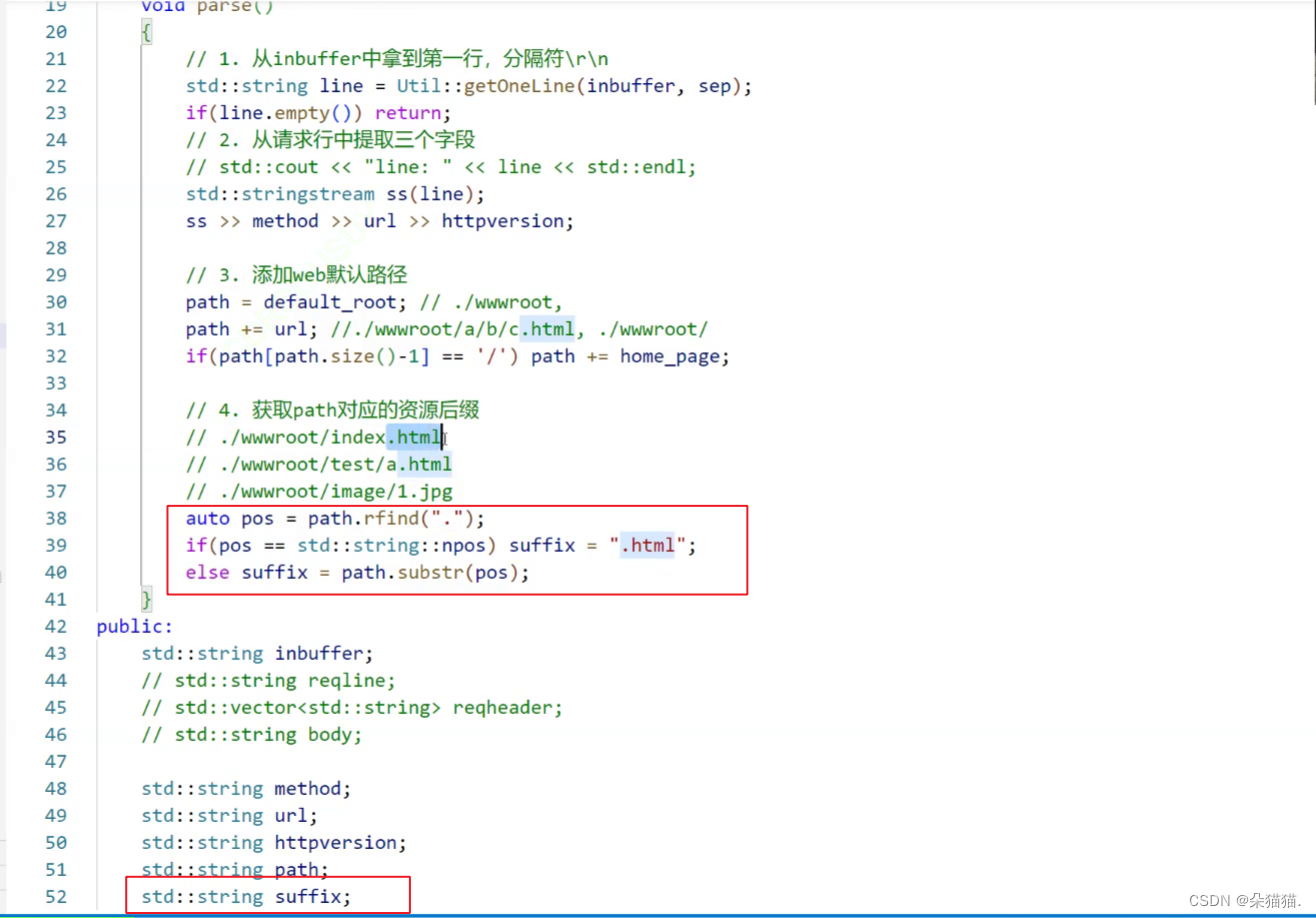
首先创建一个string类来保存路径中资源的类型后缀,然后我们只需要从后往前找到路径中的.符号,然后就可以通过substr直接截取了。如果没有找到.符号,我们就给一个默认的html后缀到时候去content-type对照即可。
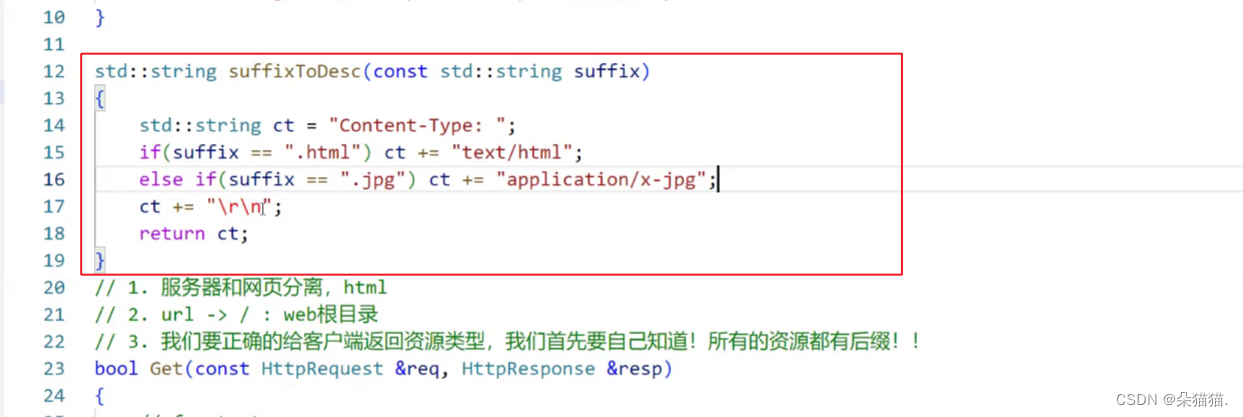
有了后缀查对照表就非常简单了,我们这里就只举html和jpg的例子,一定要记得在最后\r\n。
然后我们的响应报头还应该有用户要访问资源的大小,求大小就非常简单了,我们已经在指定路径中读取到正文了,直接用body.size()就是资源的大小了,如果程序运行起来发生奔溃,我们就让body.size()+1试一下,因为string类中会自带\0的存在。讲到这里我们的Http协议格式的内容就全部搞定了,我们只需要记住请求分为四部分:请求行,请求报头,空行,请求正文,正文是可以没有的,请求行包含http访问方法,url,以及http版本,注意每一部分后面都必须以\r\n结尾,请求报文可以有很多,就像我们上面列举的资源大小,资源类型等。响应与请求同理。
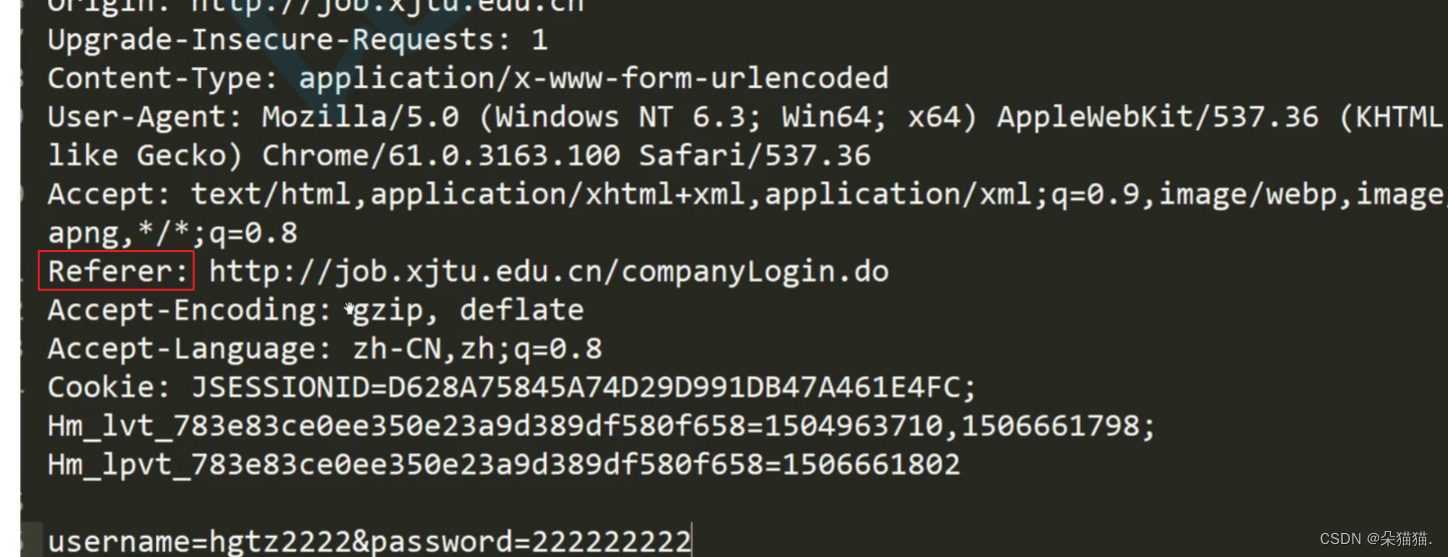
上图中referer代表我们所在的网页是从哪个网页跳转过来的,cookie很重要我们后面详细解释。
http请求方法中的get方法和post方法
想要知道get和post方法的区别,我们就得先知道表单:
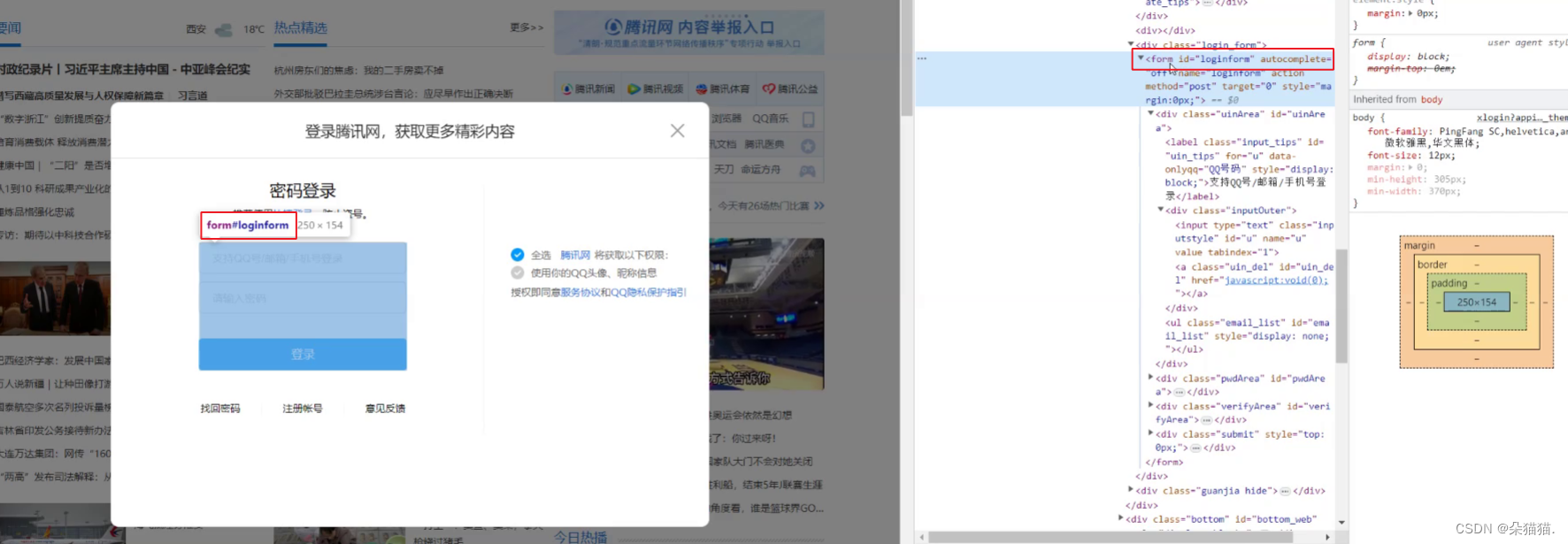
比如我们平常使用的密码登录,这就是一个大的form表单,而我们输入密码和账号进行数据提交的时候,本质前端要通过form表单提交的,浏览器会自动将form表单中的内容转换成GET/POST方法请求。下面我们自己添加一张表单:
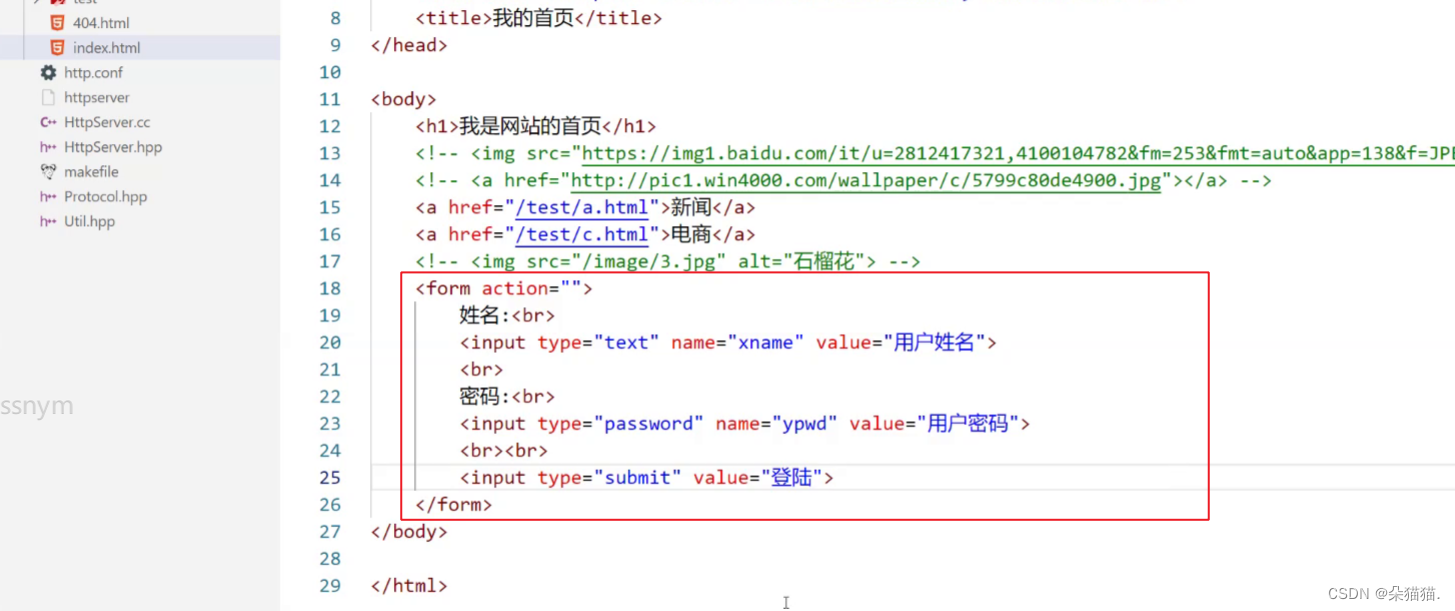
首先类型为text表示账号,类型为password表示密码,类型为submit表示提交,value代表预设内容,预设内容如下图:

预设内容就是输入框的提示字体,而我们form action后面是提交后要跳转的资源路径,然后method后面就是我们的http请求方法:
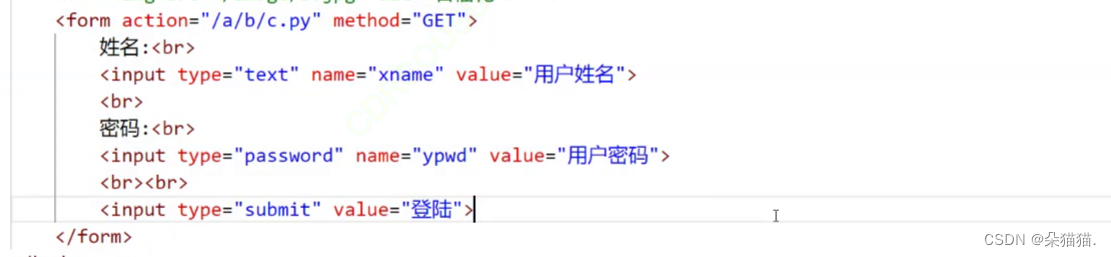
我们先以get演示,路径随便填一个没有的,到时候会跳404:
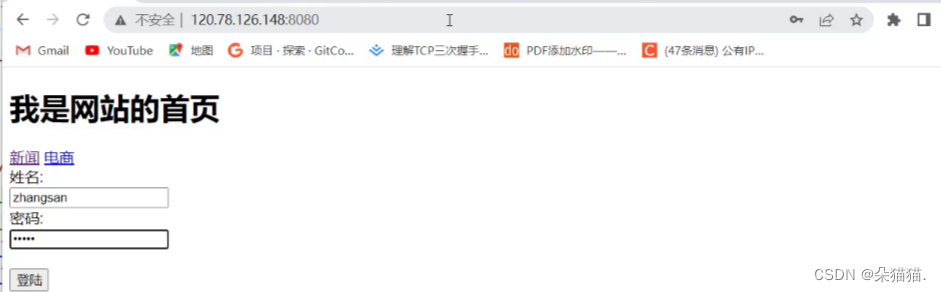
上图是登录之前的网址栏
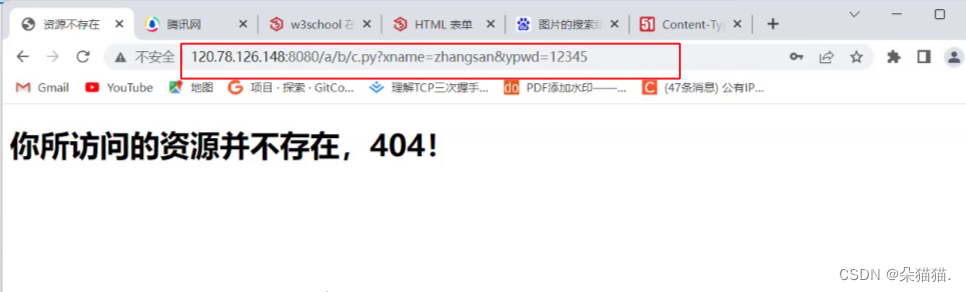
上图是点提交后的,我们可以看到get方法在我们提交的时候会直接将用户名和密码放到表单提交信息的后面,这也就意味着如果一个登录器用get方法的话那么密码会直接被外人看到,这就会很尴尬。
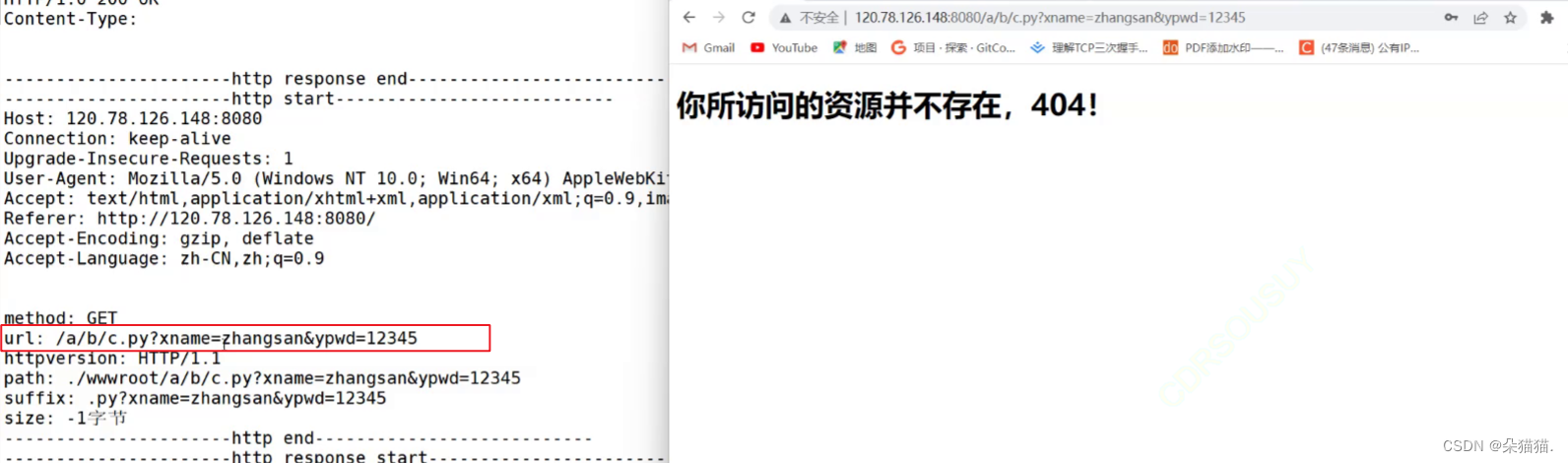
当然我们的服务器是肯定会收到用户提交的密码和账号的,下面我们试试post方法:
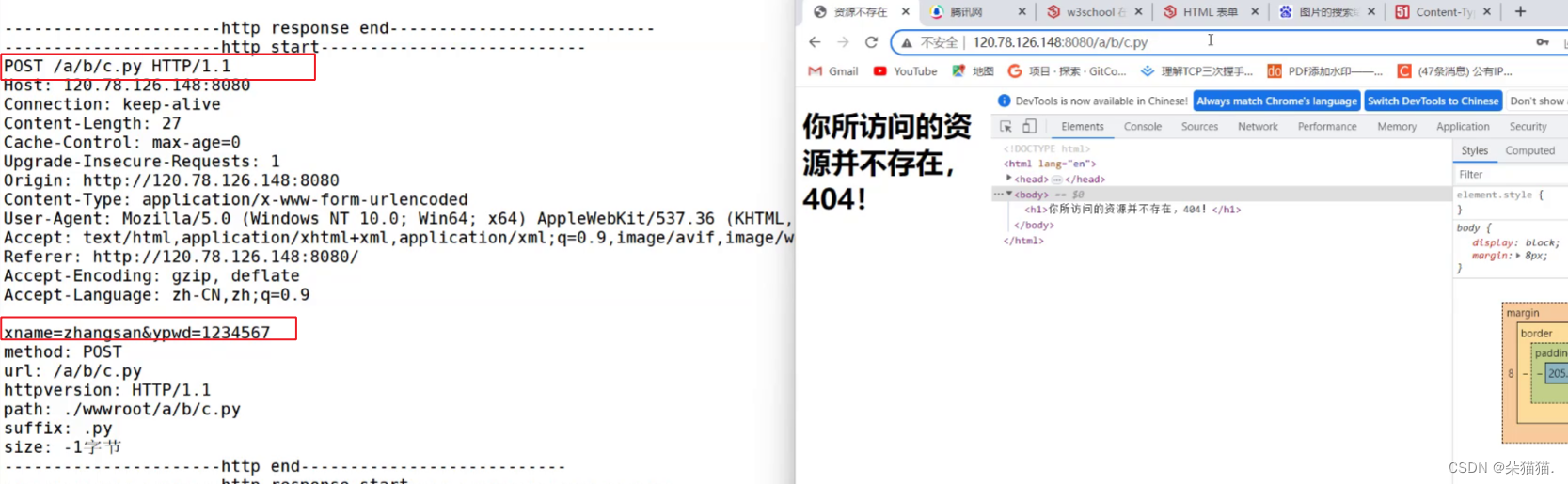
可以看到post方法只会在网址信息后面加上form表单提交的路径,不会带账户名和密码,但是对于服务器来讲还是会收到浏览器提交的用户名和密码的。
总结:GET方法通过url传递参数,而POST提交参数则通过http请求的正文提交参数。
POST方法通过正文提交参数,所以一般用户看不到,私密性更好,而私密性不等于安全性,实际上POST和GET的安全性是一样的。
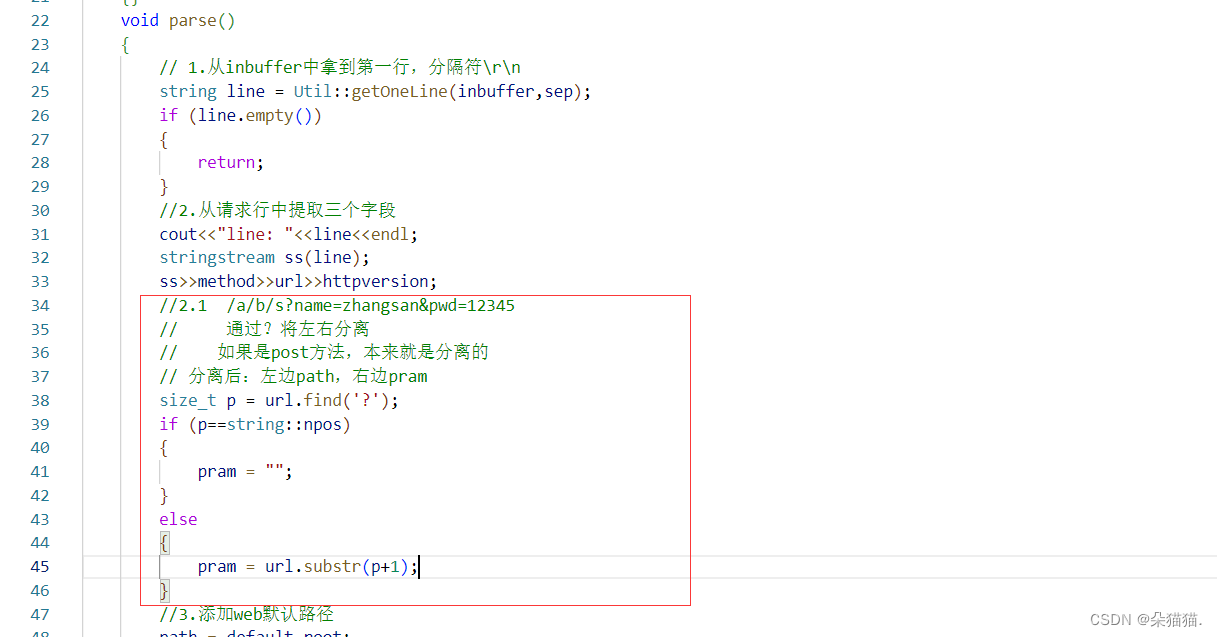
了解了get和post提交方法,我们其实可以发现之前从请求行中提取三个字段的方法不全面的,因为如果是get方法那么url后面会自动加上提交信息,提交信息以?为分割,所以我们可以将?右边的数据提取出来,这部分的数据代表用户提交的账号和密码:
HTTP的状态码:

在http状态码中,我们重点讲解一下3开头的重定向状态码。这里有一个常见的误区,很多人都以为当访问网页显示404的时候是服务器的问题,实际上这是客户端的问题,当客户没有正确访问资源的路径或者服务器中根本没有这个资源的时候,就会报404错误,因为客户访问服务器本来就不存在的资源,所以4开头的错误码才是客户端错误状态码。
重定向分为永久重定向和临时重定向,比如一个网站以前这个服务器只能容纳100万人,但是随着人数的增多服务器不够用了,这个时候公司新增加一个容纳1亿人的服务器,这个新服务器的ip和端口号与之前那个不一样,为了挽回之前那100万客户,所以将以前的服务器进行重定向,只要访问以前的服务器就可以选择跳转到新服务器,这就是永久重定向。
临时重定向类似于我们的开屏广告,实际上就是开屏前5秒的时间跳到广告商的服务器。
临时重定向很好演示,只需要在响应报头添加location:跳转的网址
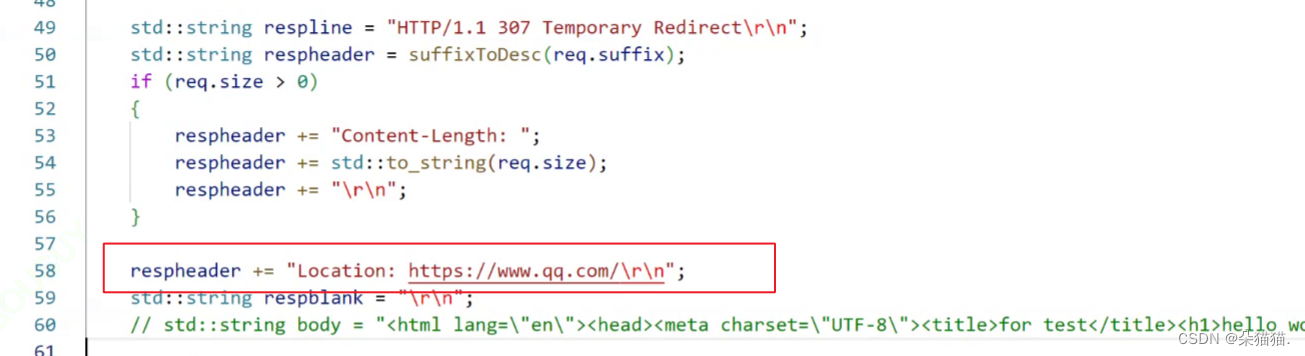
有兴趣的可以试试。
HTTP常见的报头
长链接
我们之前演示的网页大家可以看到实际上网页中有多种元素构成,比如文字,图片,音频等,这这些资源实际上都在web根目录下有着自己的路径,当我们进入首页的时候不仅会访问首页,还会访问首页中出现的图片的路径或者音频的路径或者视频的路径等等,也就是说我们一个被网页可能会有很多次客户端请求发送给服务器,而我们都知道现在的浏览器都是高并发多线程的,所以才能在一个页面一次显示那么多的信息,既然要多次发送请求链接,那么必然会导致效率降低,我们在学tcp服务器的时候也知道每次客户端与服务端建立链接的时候需要三次握手的过程,那么如何降低消耗的效率呢?建立好一条链接,获取一大份资源的时候通过同一条资源完成,这就是长链接。比如我们之前一个网页有图片和视频,没有长链接就需要多次发起http请求图片和视频经过不同的链接才能刷新出来,而有了长链接可以使图片和视频通过同一条链接获取资源。
注意:要支持长链接必须客户端和服务器都支持。
Cookie(会话保持)
什么是Cookie呢,首先我们举一个例子:当我们登录qq或者微信时,只需要登录一次只要不是特殊情况下次登录都不需要输入密码和账号,直接就可以登录,这就是会话保持,下面我们看看现象:
如上图,我们发现第一次登录视频网站的时候首页加载很慢,但是登陆一次后下一次就直接可以显示了,这是因为浏览器帮我们缓存了数据,密码和账号也是同理,浏览器帮我们记录了登录信息,当我们下一次进入app时浏览器会帮我们直接登录。注意:http协议是无状态的,这个协议本身是不会帮我们记录数据的,因为用户查看新的网页是常规操作,如果发生页面跳转那么新的页面也就无法识别是哪一个用户了,为了让用户一经登录就可以在整个网站按照自己的身份随意访问,所以才有了会话保持的存在。
cookie分为内存级和文件级,如果是内存级当我们杀掉某个APP的进程,那么重新进入该APP就会让我们重新登录,而如果是文件级即使我们关机也依旧会自动登录。
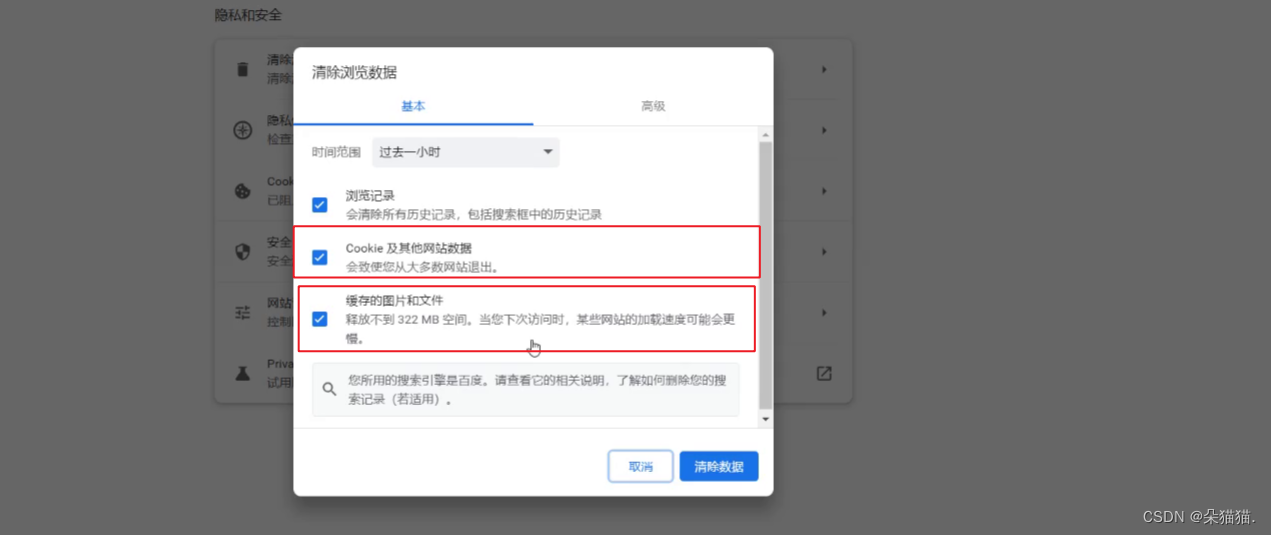
如果我们就想重新登录的话,那么找到cookie直接删除某个网站或者APP的登录信息,如下图:

下面有一个问题:
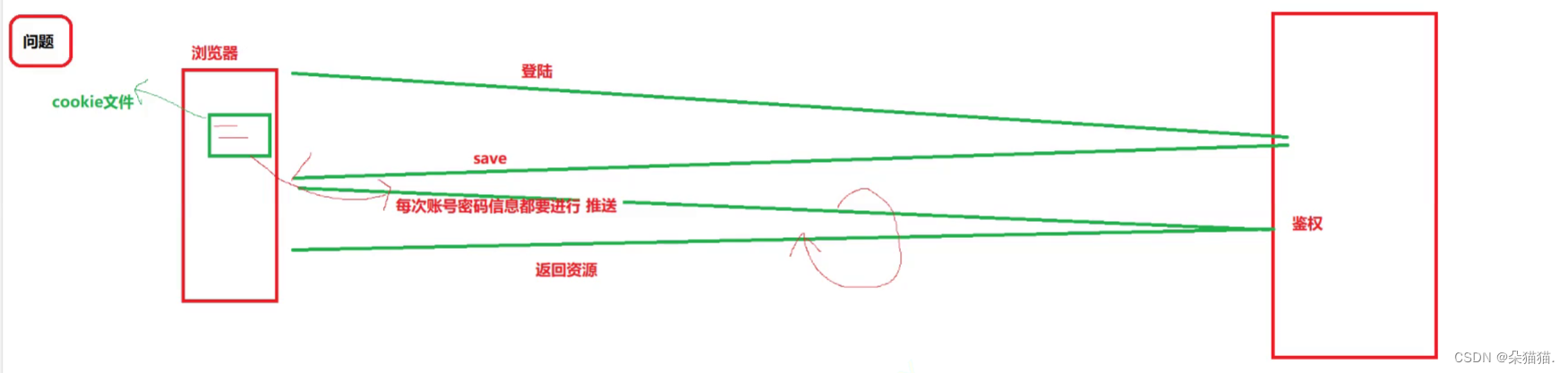
我们的浏览器会保存登录信息,保存后每次登录网站http发起请求服务器会查看浏览器为我们填的账号和密码对不对,如果对才会让我们登录,但是如果有一天我们访问不良网站中了病毒,如下图:
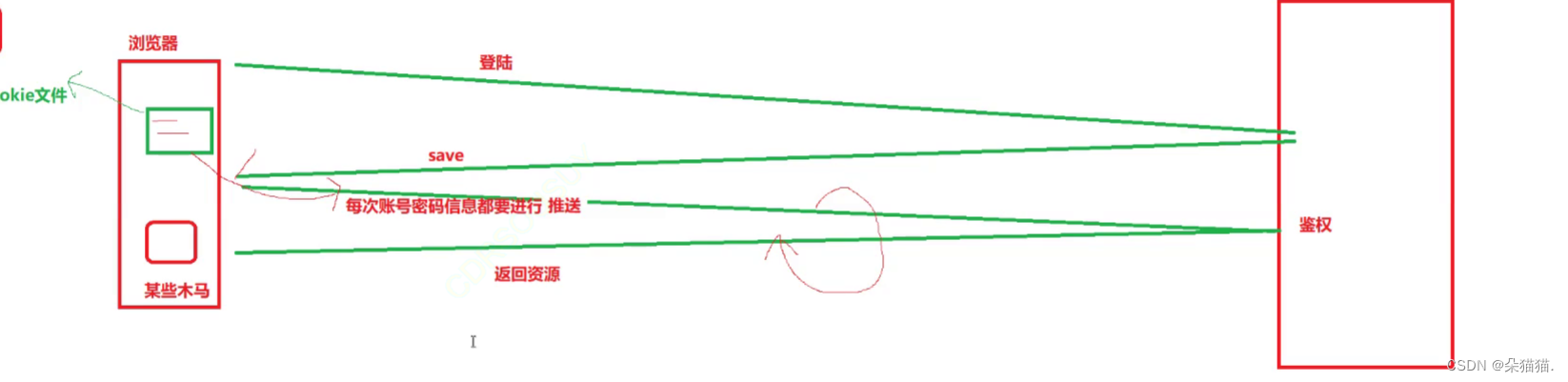
一旦中了木马病毒,黑客就可以通过木马截取我们浏览器对服务器发送的请求,比如这个时候浏览器拿着我们的登录信息向服务器发起登录请求,然后被黑客劫持,这样黑客就得到了我们的密码,然后黑客就通过我们的账号和密码请求服务器,然后登录我们的账号,那么如何解决这样的问题呢? 我们发现,对于密码这种私密信息,保存在客户端是不安全的,因为我们做不到不让用户访问非法网站或者钓鱼网站从而防止信息被泄漏,所以好的办法是将用户的信息保存在服务器端。如下图:
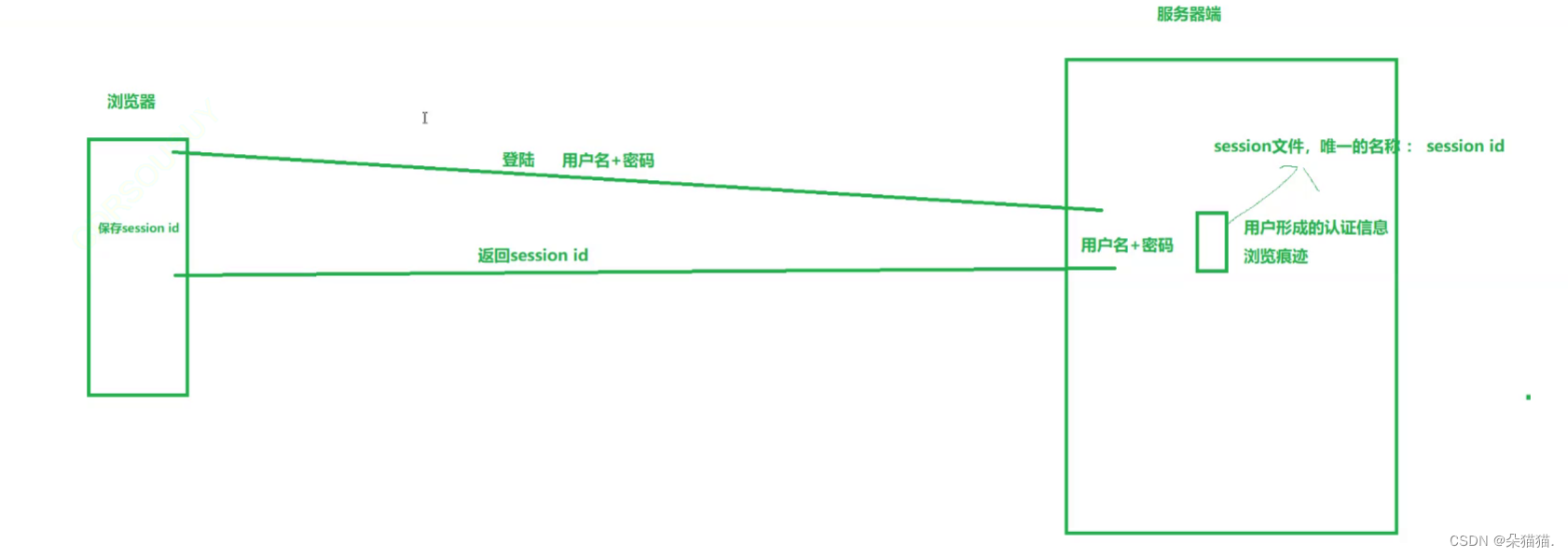
当我们第一次用浏览器登录,然后浏览器向服务器发起请求,服务器端发现这是第一次登录的用户,会直接创建一个session文件,由于用户很多所以每个session文件都必须有唯一的session id,然后服务器会给浏览器发送session id的响应,浏览器收到session id会保存也就是我们之前说的cookie,当这个用户下一次登录的时候http发起请求并且将上次保存的session id发送给服务器,服务器只需要看浏览器发来的session id所对应的文件是否存在,只要存在就会让用户处于登录状态。
我们可以发现,当用户信息保存在服务器端时,尽管客户端发起的请求被劫持,黑客也只能得到session id,是无法得到用户的密码和账号的,虽然还是可以通过session i登录我们的账号,但是比起密码泄露已经很不错了,如何要解决登录账号的问题还需要配合其他的策略,比如我们的账号突然显示ip地区发生变化,让我们确认是否是本人,如果不是就会帮我们冻结账号。
下面我们演示一下如何写入cookie信息:

我们只需要在响应报头添加set cookie字样并且后面跟上session id,下面我们运行起来去浏览器看看:
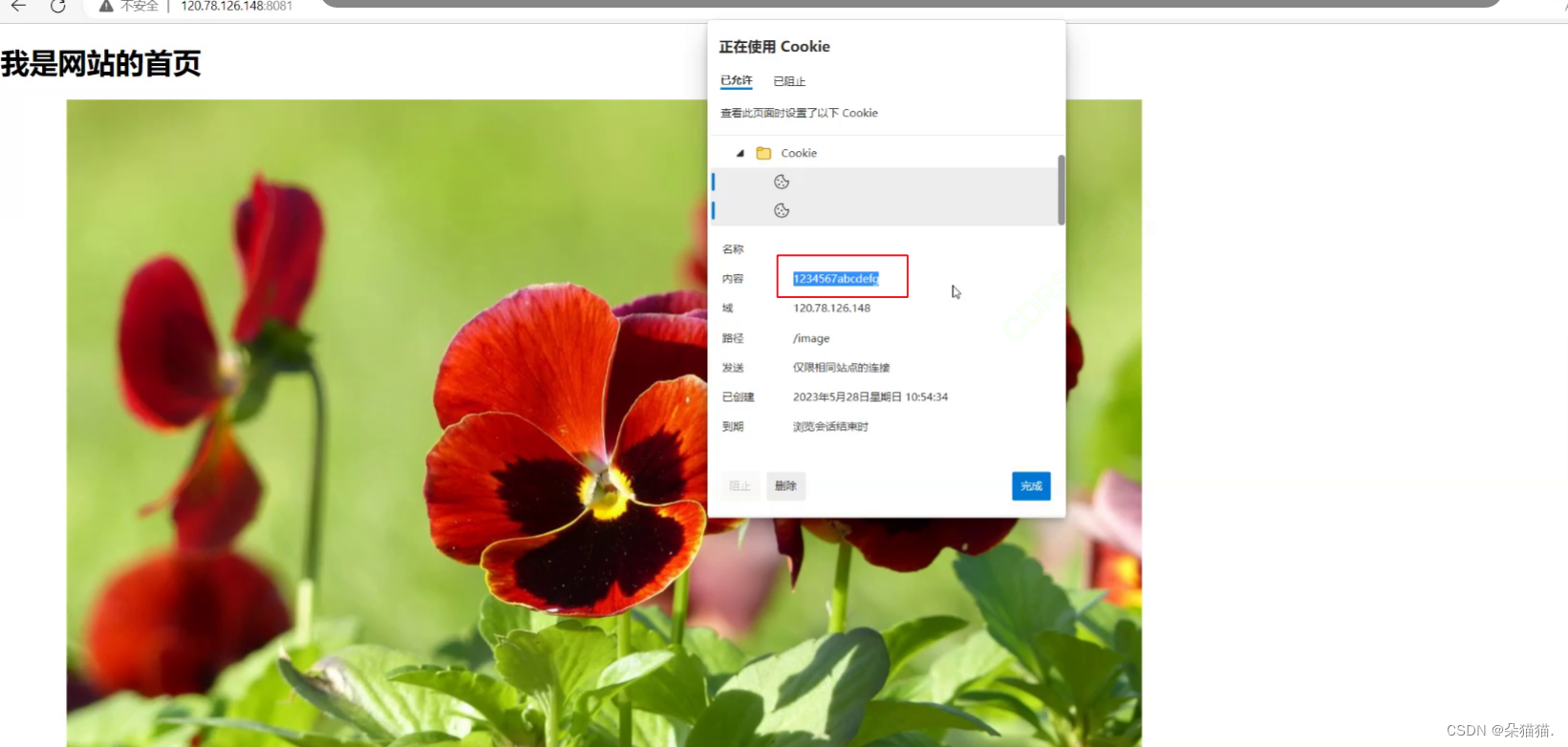
可以看到我们的浏览器中已经有我们随便设置的session id的内容了,下面再看看服务器是否收到:
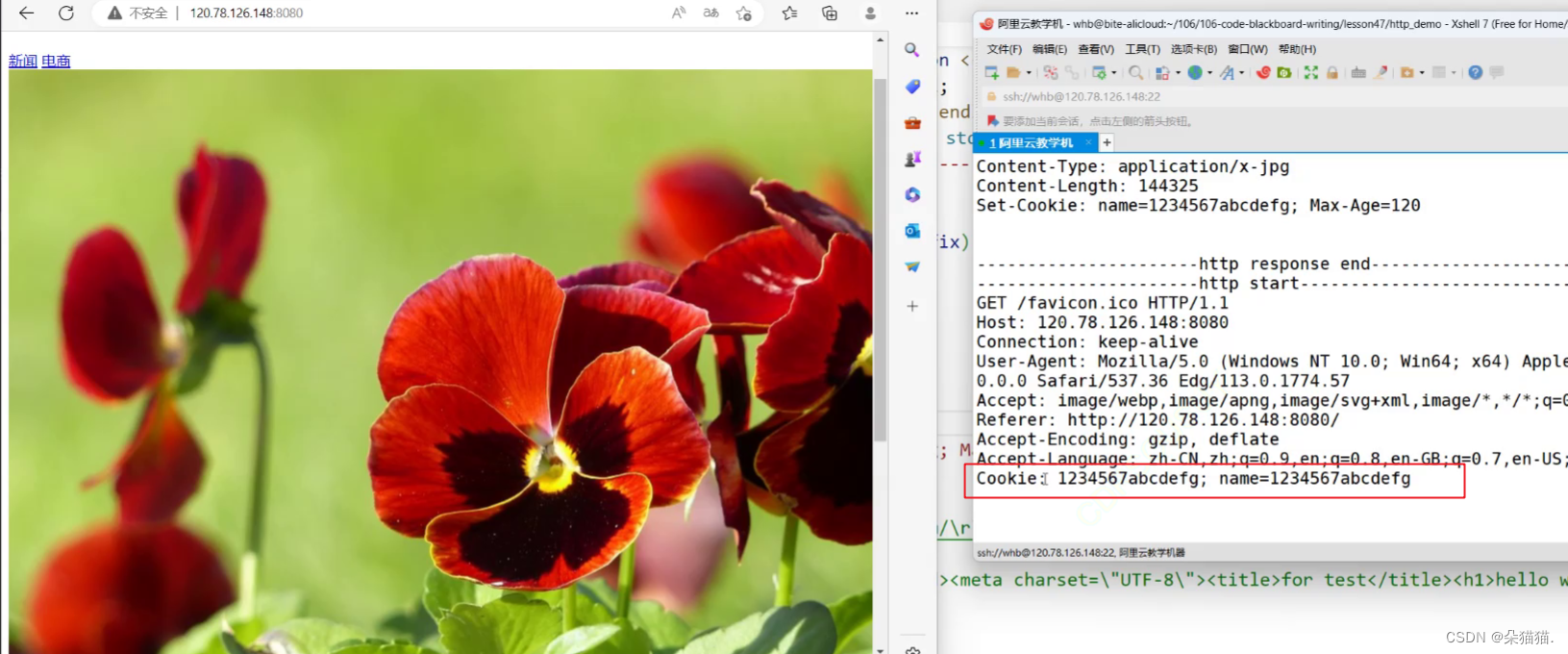 我们发现每次的http请求都会自动携带曾经设置的所有cookie,帮服务器进行鉴权行为。
我们发现每次的http请求都会自动携带曾经设置的所有cookie,帮服务器进行鉴权行为。
在http中我们可以看到还是有没解决的安全问题,在下一篇文章我们讲解的https协议中,会详细的介绍https是如何解决http遗留的问题的。
总结
http协议内容都是按照文本的方式明文传输的。