WWW 概述
前面学院君已经陆续介绍了几个日常常见的应用层协议,今天开始进入应用层协议的重头戏,也是我们日常 Web 开发天天所要打交道的 HTTP 协议,不过在讲 HTTP 协议之前,我们先要介绍它的来龙去脉,这就需要从 WWW 聊起。
WWW 是将互联网中的信息以超文本(HyperText,所谓超文本指的是带有链接到其它资源链接的文本,在 HTML 中对应 a 标签)形式展现的系统,它的英文全名叫 World Wide Web,中文译作万维网,也可简称 Web,PHP 就是一门 Web 开发语言,甚至可以说是 Web 开发语言中的王者,它的全名就是 PHP: Hypertext Preprocessor(超文本处理语言),一路伴随着互联网的兴起而发展壮大。
可以显示 Web 信息的客户端软件叫做 Web 浏览器,比如 IE、Firefox、Chrome、Opera 以及 Safari 等,与之相对的,提供 Web 信息供客户端显示的一端称之为服务端软件,通常也就是我们编写的 Web 应用,比如通过 Laravel 等框架开发的、部署到服务端的项目。客户端与服务器共同构成了 Web 的基本组件。
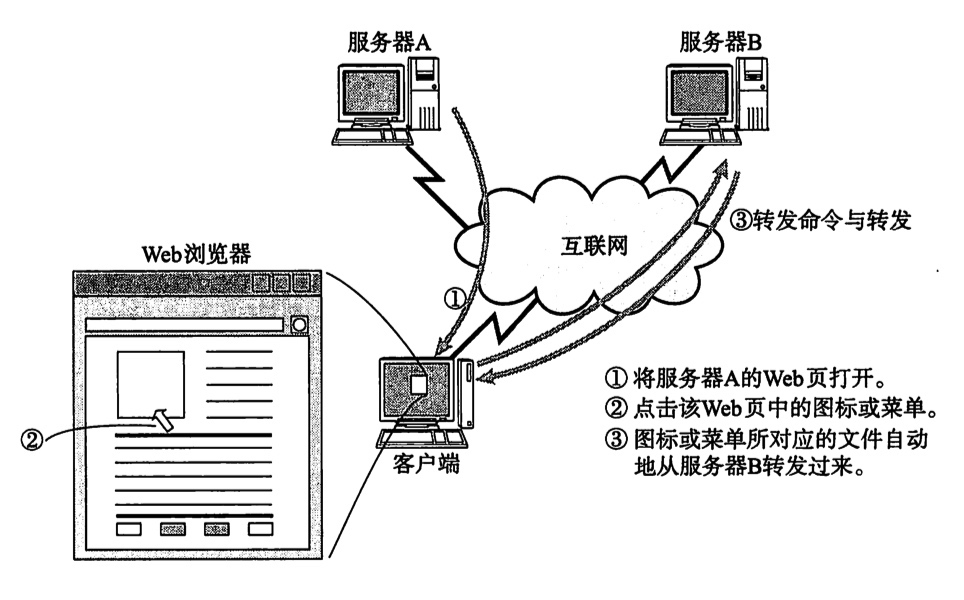
客户端浏览器向 Web 服务器发起 HTTP 请求,并将返回结果显示在浏览器上。日常我们在浏览器中访问网页背后的基本流程如下图所示:
互联网起源与发展
1989 年 3 月,互联网还属于少数人,在这一互联网的黎明期,CERN(欧洲核子研究组织)的蒂姆·伯纳斯-李博士提出了一种能让远隔两地的研究者们共享知识的设想。
最初设想的基本理念是借助多文档之间相互关联形成的超文本连成可相互参阅的 WWW,并且提出了 3 项 WWW 构建技术:
- Web 页面的文本标记语言 HTML(HyperText Markup Language,超文本标记语言);
- 作为文档传输协议的 HTTP(HyperText Transfer Protocol,超文本传输协议);
- 指定文档所在位置的 URL(Uniform Resource Locator,统一资源定位符)。
WWW 这一名称是 Web 浏览器当年用来浏览超文本的客户端应用程序时的名称,现在则用来表示这一系列的集合。
1990 年 11 月,CERN 成功研发了世界上第一台 Web 服务器和 Web 浏览器。
1990 年,大家针对 HTML 1.0 草案进行了讨论,因 HTML 1.0 中存在多处模糊不清的部分,草案被直接废弃。
1993 年 1 月,现在浏览器的祖先 NCSA(National Center for Supercomputer Applications,美国国家超级计算机应用中心)研发的 Mosaic 问世。它以内联形式显示 HTML 的图像,在图像方面出色的表现让它在世界范围内迅速流行开来。
同年秋天,Mosaic 的 Windows 版本和 Macintosh 版面世,使用 CGI 技术的 NCSA Web 服务器、NCSA HTTPd 1.0 也差不多是在这个时期出现的。
1994 年 12 月,网景通信公司发布了 Netscape Navigator 1.0,1995 年微软公司发布 Internet Explorer(IE) 1.0 和 2.0。
紧随其后的是现在已经成为 Web 服务器标准之一的 Apache,当时它以 Apache 2.0 的姿态出现在世人眼前。而 HTML 也发布了 2.0 版本。那一年,Web 技术的发展突飞猛进。
时光流转,从 1995 年左右起,微软与网景公司之间爆发的浏览器大战愈演愈烈,在这场浏览器供应商之间的竞争中,他们不仅对当时发展中的各种 Web 标准化视而不见,而且各自对 HTML 及 JavaScript 进行了扩展,导致在写前端页面之前,必须考虑兼容它们两家公司的浏览器,时至今日,这个问题依然令前端工程师头疼不已。
2000 年前后,这场浏览器战争随着网景公司的衰落而告一段落,随后 Mozilla 基金会发布了 Firefox 浏览器,IE 也不断迭代。
随后,Chrome、Opera、Safari 等浏览器也相继问世并纷纷抢占市场份额。目前,由 Google 公司发布的 Chrome 浏览器是市场份额最大的浏览器供应商。
与之相对的,在服务端领域也出现了大量的 Web 服务器,比如适用于 Java 的 Tomcat 和 Jetty,适用于 Windows 系统的 IIS,以及轻量级、支持高并发的 Nginx 和 Lighttpd,目前代表高性能、高并发支持的 Nginx 是比较主流的 Web 服务器。
同时,与 Web 相关的编程语言和技术也在不断蓬勃发展,并且在 2010 年后,智能手机的快速发展使得人们逐渐从传统的 PC 互联网转移到移动互联网上来。
后面将花几个篇幅详细介绍围绕 HTTP 协议相关的技术和术语,包括 WWW 的其它两个要素:URI 和 HTML。
Web 客户端与服务器
Web 互联网基于 HTTP 协议传输数据,构成 Web 的基本组件包括客户端和服务端,提供给客户端展示的内容存放在 Web 服务器中,由于 Web 服务器基于 HTTP 协议进行通信,所以也被称作 HTTP 服务器,常见的 Web 服务器有 Apache、Nginx、IIS 等。
客户端向 Web 服务器发送 HTTP 请求,服务器收到请求后会在响应中返回存放在服务器上的资源。日常最常见的客户端就是浏览器,比如 IE、Chrome、Firefox、Safari 等,随着移动互联网的兴起,客户端不仅限于浏览器,App 也是客户端,其实 PC 上的应用软件如果会发起 HTTP 请求,则也算作客户端。
Web 资源与 URI
Web 服务器是 Web 资源的宿主,Web 资源是 Web 内容的源头。最简单的 Web 资源就是存放在 Web 服务器文件系统中的静态文件,比如图片、纯文本、HTML文件、CSS文件、JavaScript文件、音视频文件等。早期的互联网提供的就是静态资源,所以 HTTP 协议很多设计都是围绕静态资源的。
但随着互联网的发展,所提供的服务也越来越丰富,静态资源已经满足不了用户的多样化需求了,需要根据用户需求动态生成相应资源,比如博客文章、电商网站中的商品、社交网站上的讯息、搜索引擎结果页等,这往往要借助 CGI 程序来实现。CGI(Common Gateway Interface,通用网关接口)是指 Web 服务器在接收到客户端发送过来的请求后转发给后端程序的一种机制。在 CGI 的作用下,程序会对请求内容做出相应的动作,比如创建 HTML 等动态内容。实际上,PHP Web 应用工作原理正是如此,由 Nginx 判断请求 URI 是否以 .php 后缀结尾,如果是的话则认为是动态请求,然后将请求转发给后端 PHP-FPM 进行处理。
Web 服务器会为每种要通过 HTTP 传输的资源对象都打上了 MIME 类型的数据格式标签。MIME(Multipurpose Internet Mail Extension,多用途互联网邮件扩展)我们在电子邮件协议中已经介绍过,最初是为了解决电子邮件系统间内容传输的格式问题,HTTP 也采纳了它用来标记多媒体内容。
当 Web 浏览器从服务器取回一个对象时,会去查看相关的 MIME 类型,看看它能否处理,大多数浏览器都可以处理数百种常见的对象类型:
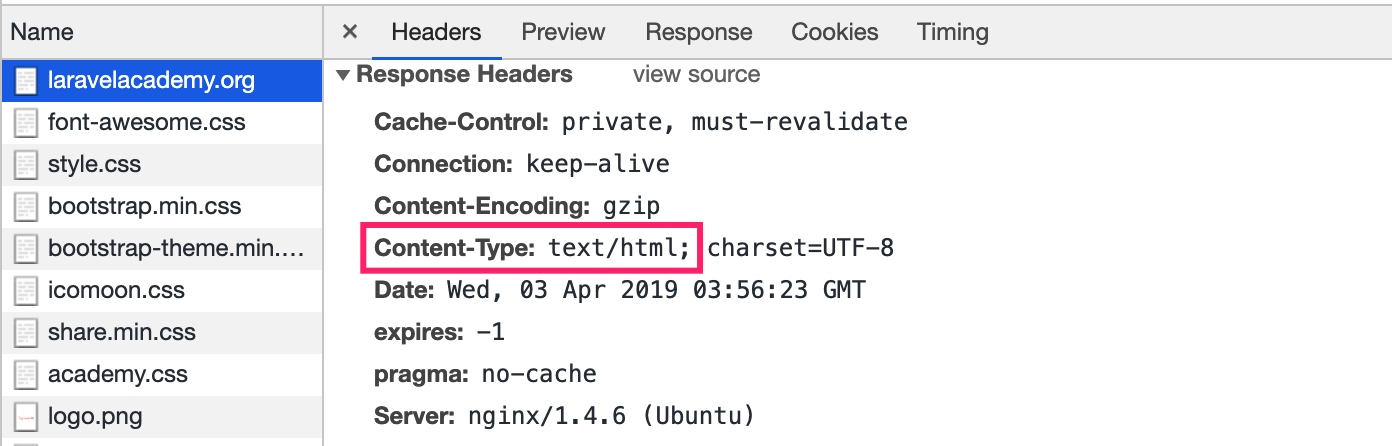
返回对象的 MIME 类型位于响应头的 Content-Type 字段中。
为了让客户端可以指定想要访问的资源,我们需要为 Web 服务器资源设置统一资源标识符(Uniform Resource Identifier,URI),URI 就像互联网上的邮件地址一样,可以在世界范围内唯一标识并定位某个资源。比如下面这个 Laravel 学院上的图片资源的 URI:
https://static.laravelacademy.org/wp-statics/images/carousel/LaravelAcademy.jpg
给定了 URI,HTTP 就可以解析出对象。URI 通常有两种形式,URL 和 URN。
URL 是 Uniform Resource Location 的缩写,意为统一资源定位符,是 URI 最常见的形式,它描述了特定服务器上某资源的特定位置,可以明确说明如何从一个精确、固定的位置获取资源。
URL 大都遵循以下标准:
- URL 的第一部分称为方案(scheme),说明了访问资源所使用的协议类型,通常是
http://或https://; - 第二部分给出了服务器的域名/IP地址和端口号(不指定默认为80),比如
static.laravelacademy.org; - 其余部分指定的是 URI 的路径信息,比如
/wp-statics/images/carousel/LaravelAcademy.jpg。
一般情况下,在 Web 领域,URI 和 URL 几乎等价。
URN 是统一资源名称的缩写,目前尚在实验阶段,没有大范围使用,平时很少看到。
HTTP 事务
我们参考数据库中的概念,将一个完整的 HTTP 请求与处理过程称之为 HTTP 事务。一个 HTTP 事务由一条请求命令(从客户端发往服务器)和一个响应结果(从服务器发往客户端)组成,这种通信是通过名为 HTTP 报文的格式化数据块进行的:
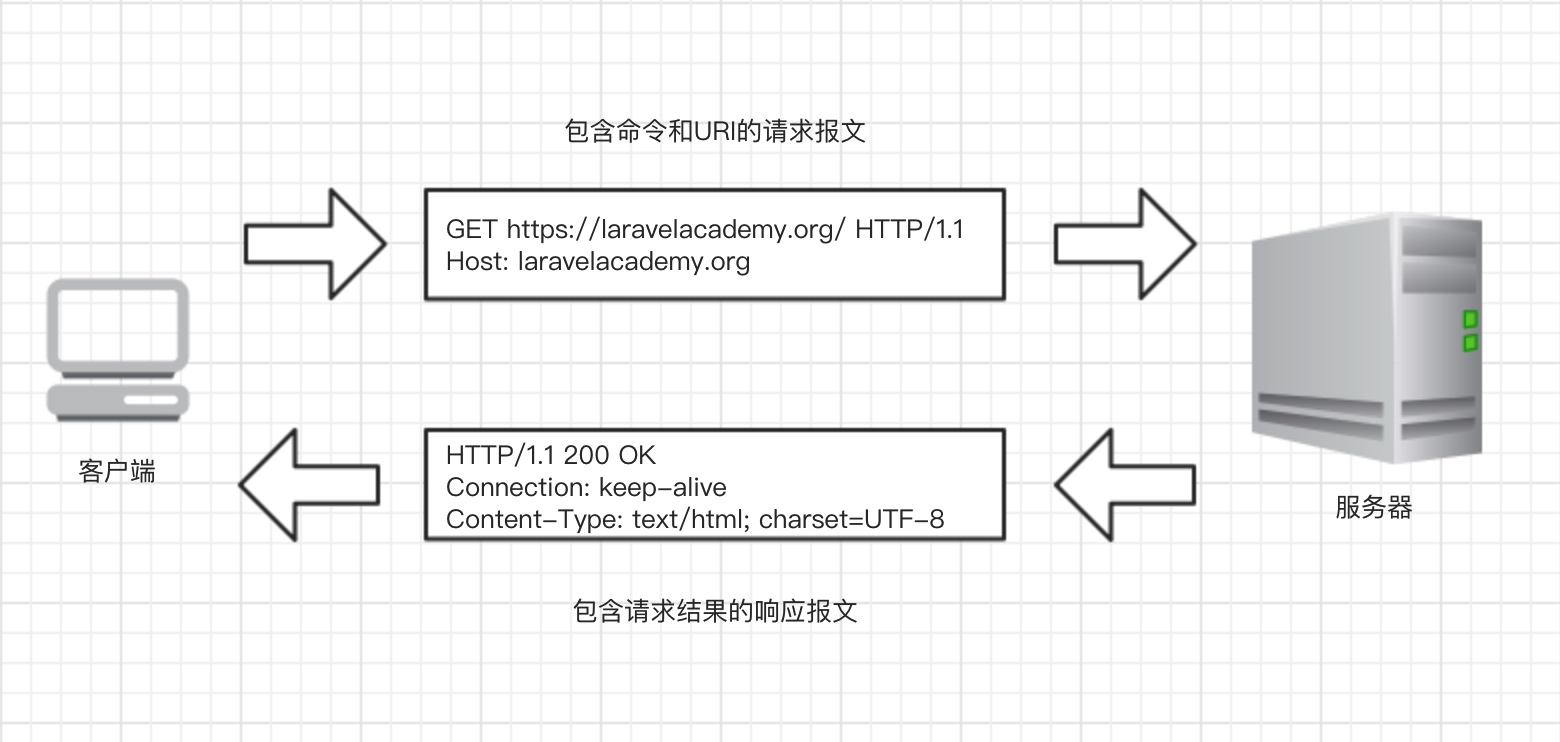
HTTP 支持不同的请求命令,这些命令被称为 HTTP 方法。每条 HTTP 请求都包含一个方法,这个方法会告诉服务器要执行的动作,下面是最常见的五个 HTTP 请求方法:

每条 HTTP 响应报文返回时都会携带一个状态码,状态码由三个数字组成,告知客户端请求是否成功,或者是否需要采取其它行动:

伴随每个数字状态码,HTTP 还会发送一条解释性的「原因短句」文本,例如:
200 OK
HTTP 报文
书接上文,HTTP 报文是由一行一行的简单纯文本字符串组成,从 Web 客户端发往务器的 HTTP 报文称为请求报文,相对的,从服务器发往客户端的报文称为响应报文:
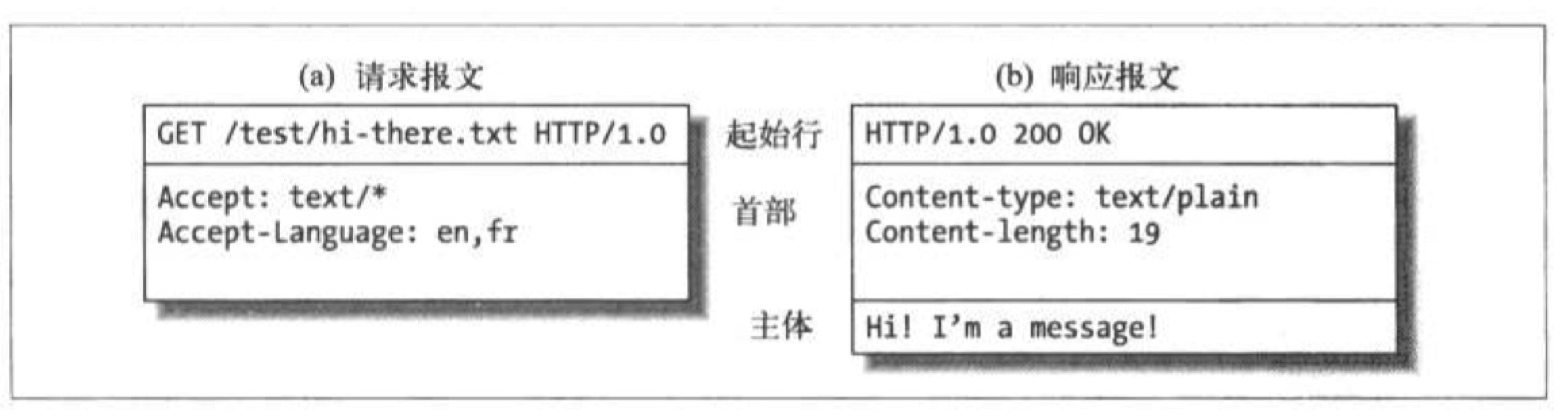
请求报文和响应报文的格式类似,都由三部分组成:
- 起始行:报文的第一行就是起始行,在请求报文中用来说明要做什么,在响应报文中说明出现了什么情况。
- 首部字段:起始行后面有零个或多个首部字段,每个首部字段包含一个名字和对应的值,为了便于解析,两者之间用冒号分隔,在请求报文中我们将其称作请求头,在响应报文中我们将其称作响应头。
- 主体:报文主体和首部字段之间通过一个空行分隔,请求主体中包含了要发送给 Web 服务器的数据(一般 POST 请求都会包含请求主体,GET 请求参数都在 URL 里面,请求主体一般为空),响应主体中包含了服务器返回给客户端的数据,一般是 HTML 文档或者 JSON 格式数据。
下面我们以 Laravel 学院首页为例来看一个简单的报文实例:
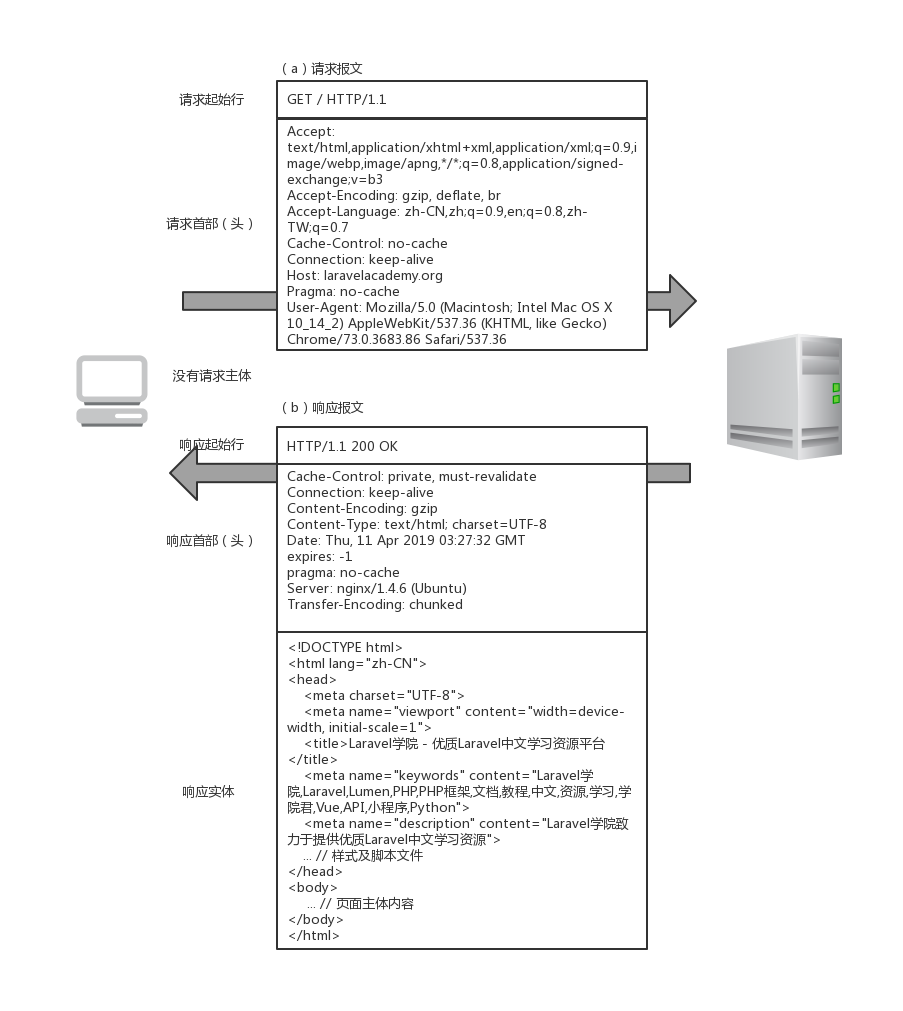
关于起始行和首部字段的含义和使用,后面我们会详细展开,这里只需要有一个大体的认识即可。
HTTP 连接的建立
HTTP 基于 TCP 协议进行可靠的数据传输:
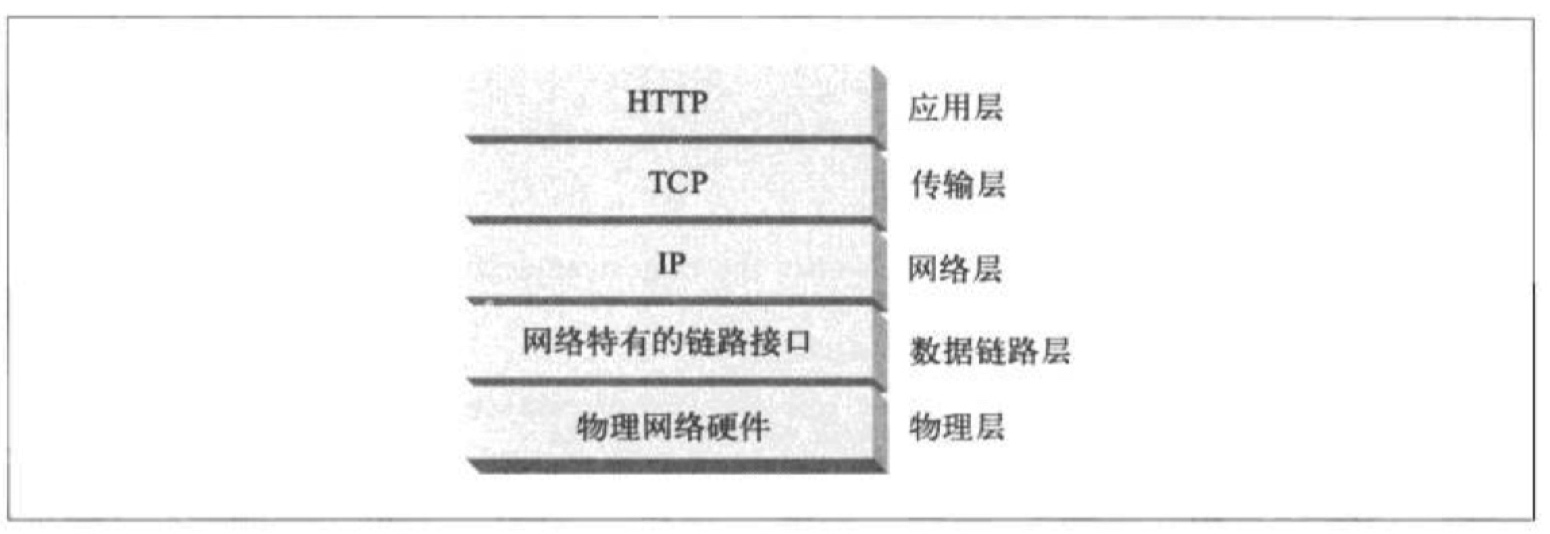
HTTP 协议是一个应用层协议,它无需关心操作网络通信的具体细节,而是把联网的细节都交给了底层的 TCP/IP 协议。在 HTTP 客户端向服务器发送报文之前,需要通过网络层的 IP 地址和传输层的端口号建立起一条 TCP/IP 连接。IP 地址和端口号可以从请求 URL 中获取,IP 地址通过 DNS 查询域名获取,端口号不写的话默认是 80:
具体连接建立步骤如下:
- 浏览器从 URL 中解析出服务器的域名;
- 浏览器将服务器的域名替换为服务器的 IP 地址(通过 DNS 获取);
- 浏览器将端口号从 URL 中解析出来(默认是 80);
- 浏览器建立一条与 Web 服务器的 TCP 连接;
- 浏览器向服务器发送一条 HTTP 请求报文;
- 服务器收到浏览器请求后进行处理并回送一条 HTTP 响应报文;
- 浏览器收到响应后将其显示出来。
HTTP 协议版本变迁
1)HTTP/0.9
HTTP 于 1990 年问世,那时的 HTTP 并没有作为正式的标准被建立,这个版本的 HTTP 其实含有 HTTP 1.0 之前版本的意思,所以被称为 HTTP/0.9。
2)HTTP/1.0
HTTP 正式作为标准被公布是在 1996 年 5 月,版本被正式命名为 HTTP/1.0,并记载于 RFC 1945。
3)HTTP/1.1
1997 年 1 月份公布的 HTTP/1.1 是目前主流的 HTTP 协议版本,当初的标准是 RFC 2068,之后发布的修订版 RFC 2616 就是当前的最新版本。
HTTP/1.0 每次请求都会建立连接,返回响应后断开连接,而 HTTP/1.1 可以在一条连接上处理多个请求,从而提升了性能。
4)HTTP-NG(又名 HTTP/2.0)
重点关注的是 HTTP 性能的大幅优化,以及更加强大的服务逻辑远程执行框架。后面我们在聊 HTTP/2.0 的时候会详细介绍。