首先得知道
Proxy
Proxy API对应的Proxy对象是ES6就已引入的一个原生对象,用于定义基本操作的自定义行为(如属性查找、赋值、枚举、函数调用等)。 从字面意思来理解,Proxy对象是目标对象的一个代理器,任何对目标对象的操作(实例化,添加/删除/修改属性等等),都必须通过该代理器。因此我们可以把来自外界的所有操作进行拦截和过滤或者修改等操作。 基于Proxy的这些特性,常用于:
- 创建一个可“响应式”的对象,例如Vue3.0中的reactive方法。
- 创建可隔离的JavaScript“沙箱”。
Proxy的基本语法如下代码所示:
const p = new Proxy(target, handler)
中,target参数表示要使用Proxy包装的目标对象(可以是任何类型的对象,包括原生数组,函数,甚至另一个代理),handler参数表示以函数作为属性的对象,各属性中的函数分别定义了在执行各种操作时代理p的行为。常见使用方法如下代码所示:
let foo = {
a: 1,
b: 2
}
let handler = {
get:(obj,key)=>{
console.log('get')
return key in obj ? obj[key] : undefined
}
}
let p = new Proxy(foo,handler)
console.log(p.a) // 打印1
上面代码中p就是foo的代理对象,对p对象的相关操作都会同步到foo对象上,同时Proxy也提供了另一种生成代理对象的方法Proxy.revocable(),如下代码所示:
const {
proxy,revoke } = Proxy.revocable(target, handler)
该方法的返回值是一个对象,其结构为: {“proxy”: proxy, “revoke”: revoke},其中:proxy表示新生成的代理对象本身,和用一般方式new Proxy(target, handler)创建的代理对象没什么不同,只是它可以被撤销掉,revoke表示撤销方法,调用的时候不需要加任何参数,就可以撤销掉和它一起生成的那个代理对象,如下代码所示:
let foo = {
a: 1,
b: 2
}
let handler = {
get:(obj,key)=>{
console.log('get')
return key in obj ? obj[key] : undefined
}
}
let {
proxy,revoke } = Proxy.revocable(foo,handler)
console.log(proxy.a) // 打印1
revoke()
console.log(proxy.a) // 报错信息:Uncaught TypeError: Cannot perform 'get' on a proxy that has been revoked
需要注意的是,一旦某个代理对象被撤销,它将变得几乎完全不可调用,在它身上执行任何的可代理操作都会抛出TypeError异常。 在上面代码中,我们只使用了get操作的handler,即当尝试获取对象的某个属性时会进入这个方法,除此之外Proxy共有接近14个handler也可以称作为钩子,它们分别是:
handler.getPrototypeOf():
在读取代理对象的原型时触发该操作,比如在执行 Object.getPrototypeOf(proxy) 时。
handler.setPrototypeOf():
在设置代理对象的原型时触发该操作,比如在执行 Object.setPrototypeOf(proxy, null) 时。
handler.isExtensible():
在判断一个代理对象是否是可扩展时触发该操作,比如在执行 Object.isExtensible(proxy) 时。
handler.preventExtensions():
在让一个代理对象不可扩展时触发该操作,比如在执行 Object.preventExtensions(proxy) 时。
handler.getOwnPropertyDescriptor():
在获取代理对象某个属性的属性描述时触发该操作,比如在执行 Object.getOwnPropertyDescriptor(proxy, "foo") 时。
handler.defineProperty():
在定义代理对象某个属性时的属性描述时触发该操作,比如在执行 Object.defineProperty(proxy, "foo", {
}) 时。
handler.has():
在判断代理对象是否拥有某个属性时触发该操作,比如在执行 "foo" in proxy 时。
handler.get():
在读取代理对象的某个属性时触发该操作,比如在执行 proxy.foo 时。
handler.set():
在给代理对象的某个属性赋值时触发该操作,比如在执行 proxy.foo = 1 时。
handler.deleteProperty():
在删除代理对象的某个属性时触发该操作,即使用 delete 运算符,比如在执行 delete proxy.foo 时。
handler.ownKeys():
当执行Object.getOwnPropertyNames(proxy) 和Object.getOwnPropertySymbols(proxy)时触发。
handler.apply():
当代理对象是一个function函数时,调用apply()方法时触发,比如proxy.apply()。
handler.construct():
当代理对象是一个function函数时,通过new关键字实例化时触发,比如new proxy()。
结合这些handler,我们可以实现一些针对对象的限制操作,例如: 禁止删除和修改对象的某个属性,如下代码所示:
let foo = {
a:1,
b:2
}
let handler = {
set:(obj,key,value,receiver)=>{
console.log('set')
if (key == 'a') throw new Error('can not change property:'+key)
obj[key] = value
return true
},
deleteProperty:(obj,key)=>{
console.log('delete')
if (key == 'a') throw new Error('can not delete property:'+key)
delete obj[key]
return true
}
}
let p = new Proxy(foo,handler)
// 尝试修改属性a
p.a = 3 // 报错信息:Uncaught Error
// 尝试删除属性a
delete p.a // 报错信息:Uncaught Error
上面代码中,set方法多了一个receiver参数,这个参数通常是Proxy本身即p,场景是当有一段代码执行obj.name=“jen”,obj不是一个proxy,且自身不含name属性,但是它的原型链上有一个proxy,那么,那个proxy的handler里的set方法会被调用,而此时obj会作为receiver这个参数传进来。 对属性的修改进行校验,如下代码所示:
let foo = {
a:1,
b:2
}
let handler = {
set:(obj,key,value)=>{
console.log('set')
if (typeof(value) !== 'number') throw new Error('can not change property:'+key)
obj[key] = value
return true
}
}
let p = new Proxy(foo,handler)
p.a = 'hello' // 报错信息:Uncaught Error
Proxy也能监听到数组变化,如下代码所示:
let arr = [1]
let handler = {
set:(obj,key,value)=>{
console.log('set') // 打印set
return Reflect.set(obj, key, value);
}
}
let p = new Proxy(arr,handler)
p.push(2) // 改变数组
Reflect.set()用于修改数组的值,返回布尔类型,这也可以兼容修改数组原型上的方法对应场景,相当于obj[key] = value。
Reflect
Symbol
Map和Set
diff算法
在vue update过程中在遍历子代vnode的过程中,会用不同的patch方法来patch新老vnode,如果找到对应的 newVnode 和 oldVnode,就可以复用利用里面的真实dom节点。避免了重复创建元素带来的性能开销。毕竟浏览器创造真实的dom,操纵真实的dom,性能代价是昂贵的。
patchChildren
从上文中我们得知了存在children的vnode类型,那么存在children就需要patch每一个
children vnode依次向下遍历。那么就需要一个patchChildren方法,依次patch子类vnode。
vue3.0中 在patchChildren方法中有这么一段源码
if (patchFlag > 0) {
if (patchFlag & PatchFlags.KEYED_FRAGMENT) {
/* 对于存在key的情况用于diff算法 */
patchKeyedChildren(
c1 as VNode[],
c2 as VNodeArrayChildren,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
return
} else if (patchFlag & PatchFlags.UNKEYED_FRAGMENT) {
/* 对于不存在key的情况,直接patch */
patchUnkeyedChildren(
c1 as VNode[],
c2 as VNodeArrayChildren,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
return
}
}
patchChildren根据是否存在key进行真正的diff或者直接patch。
既然diff算法存在patchChildren方法中,而patchChildren方法用在Fragment类型和element类型的vnode中,这样也就解释了diff算法的作用域是什么。
diff算法具体做了什么(重点)?
在正式讲diff算法之前,在patchChildren的过程中,存在 patchKeyedChildren
patchUnkeyedChildren
patchKeyedChildren 是正式的开启diff的流程,那么patchUnkeyedChildren的作用是什么呢? 我们来看看针对没有key的情况patchUnkeyedChildren会做什么。
c1 = c1 || EMPTY_ARR
c2 = c2 || EMPTY_ARR
const oldLength = c1.length
const newLength = c2.length
const commonLength = Math.min(oldLength, newLength)
let i
for (i = 0; i < commonLength; i++) {
/* 依次遍历新老vnode进行patch */
const nextChild = (c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i]))
patch(
c1[i],
nextChild,
container,
null,
parentComponent,
parentSuspense,
isSVG,
optimized
)
}
if (oldLength > newLength) {
/* 老vnode 数量大于新的vnode,删除多余的节点 */
unmountChildren(c1, parentComponent, parentSuspense, true, commonLength)
} else {
/* /* 老vnode 数量小于于新的vnode,创造新的即诶安 */
mountChildren(
c2,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized,
commonLength
)
}
我们可以得到结论,对于不存在key情况
① 比较新老children的length获取最小值 然后对于公共部分,进行从新patch工作。
② 如果老节点数量大于新的节点数量 ,移除多出来的节点。
③ 如果新的节点数量大于老节点的数量,从新 mountChildren新增的节点。
那么对于存在key情况呢? 会用到diff算法 , diff算法做了什么呢?
patchKeyedChildren方法究竟做了什么?
我们先来看看一些声明的变量。
/* c1 老的vnode c2 新的vnode */
let i = 0 /* 记录索引 */
const l2 = c2.length /* 新vnode的数量 */
let e1 = c1.length - 1 /* 老vnode 最后一个节点的索引 */
let e2 = l2 - 1 /* 新节点最后一个节点的索引 */
①第一步从头开始向尾寻找
(a b) c
(a b) d e
/* 从头对比找到有相同的节点 patch ,发现不同,立即跳出*/
while (i <= e1 && i <= e2) {
const n1 = c1[i]
const n2 = (c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i]))
/* 判断key ,type是否相等 */
if (isSameVNodeType(n1, n2)) {
patch(
n1,
n2,
container,
parentAnchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
} else {
break
}
i++
}
第一步的事情就是从头开始寻找相同的vnode,然后进行patch,如果发现不是相同的节点,那么立即跳出循环。
具体流程如图所示
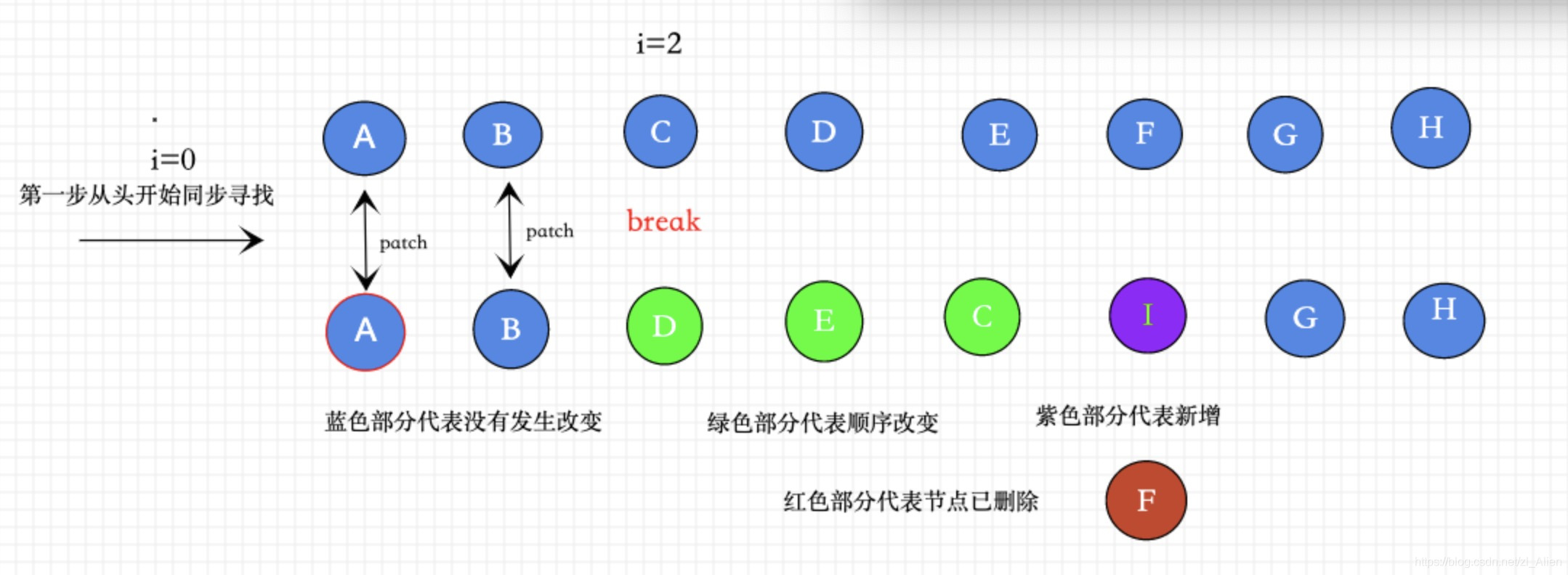
isSameVNodeType
export function isSameVNodeType(n1: VNode, n2: VNode): boolean {
return n1.type === n2.type && n1.key === n2.key
}
②第二步从尾开始同前diff
a (b c)
d e (b c)
/* 如果第一步没有patch完,立即,从后往前开始patch ,如果发现不同立即跳出循环 */
while (i <= e1 && i <= e2) {
const n1 = c1[e1]
const n2 = (c2[e2] = optimized
? cloneIfMounted(c2[e2] as VNode)
: normalizeVNode(c2[e2]))
if (isSameVNodeType(n1, n2)) {
patch(
n1,
n2,
container,
parentAnchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
} else {
break
}
e1--
e2--
}
经历第一步操作之后,如果发现没有patch完,那么立即进行第二部,从尾部开始遍历依次向前diff。
如果发现不是相同的节点,那么立即跳出循环。
具体流程如图所示

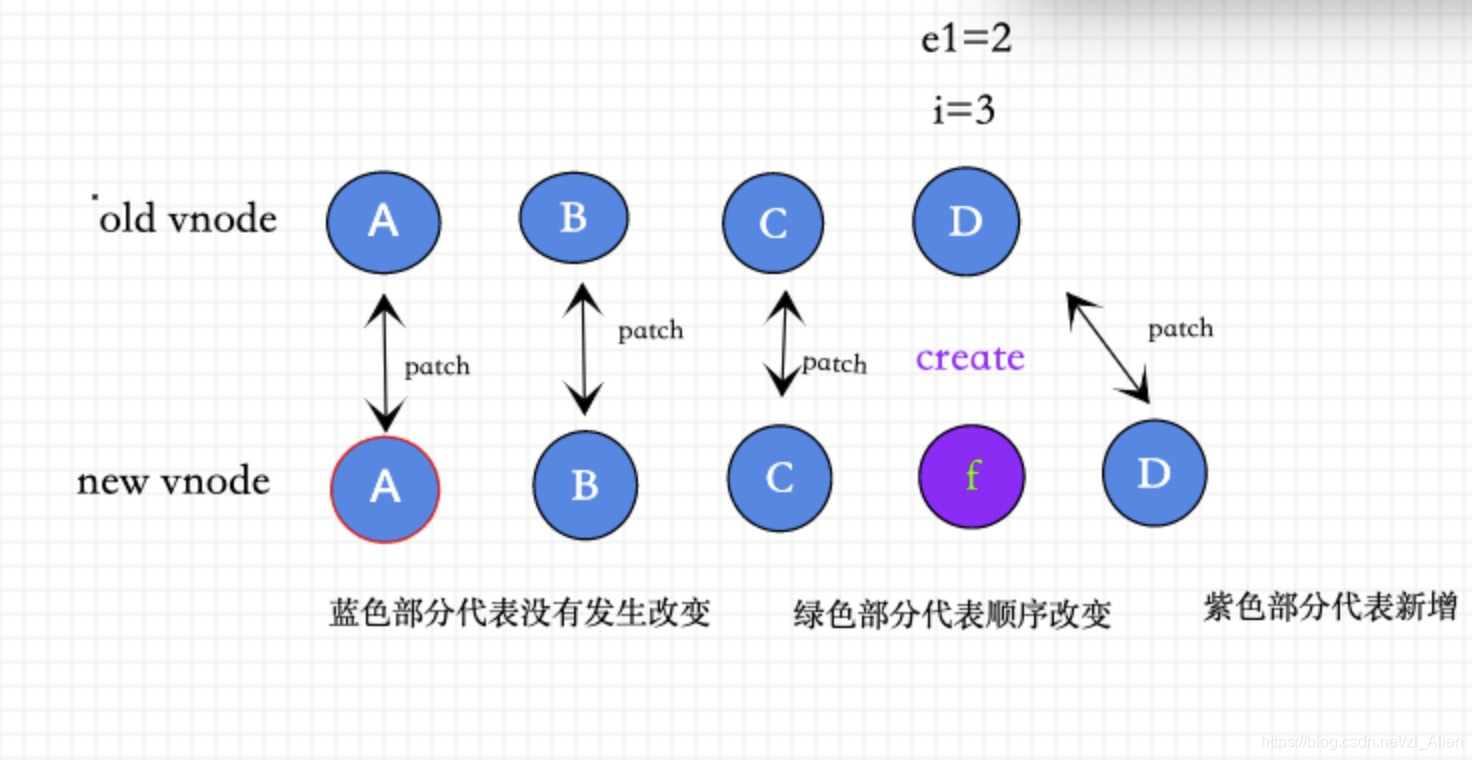
③④主要针对新增和删除元素的情况,前提是元素没有发生移动, 如果有元素发生移动就要走⑤逻辑。
③ 如果老节点是否全部patch,新节点没有被patch完,创建新的vnode
(a b)
(a b) c
i = 2, e1 = 1, e2 = 2
(a b)
c (a b)
i = 0, e1 = -1, e2 = 0
/* 如果新的节点大于老的节点数 ,对于剩下的节点全部以新的vnode处理( 这种情况说明已经patch完相同的vnode ) */
if (i > e1) {
if (i <= e2) {
const nextPos = e2 + 1
const anchor = nextPos < l2 ? (c2[nextPos] as VNode).el : parentAnchor
while (i <= e2) {
patch( /* 创建新的节点*/
null,
(c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i])),
container,
anchor,
parentComponent,
parentSuspense,
isSVG
)
i++
}
}
}
i > e1
如果新的节点大于老的节点数 ,对于剩下的节点全部以新的vnode处理( 这种情况说明已经patch完相同的vnode ),也就是要全部create新的vnode.
具体逻辑如图所示
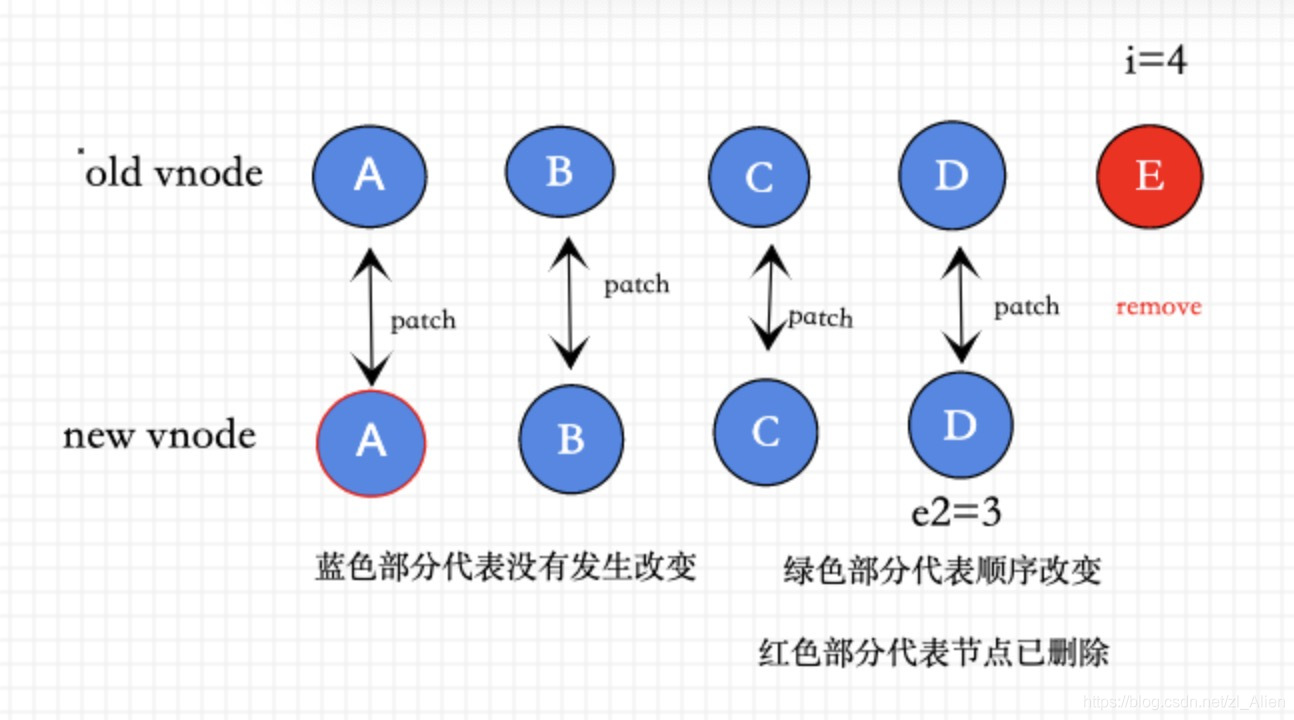
④ 如果新节点全部被patch,老节点有剩余,那么卸载所有老节点
i > e2
(a b) c
(a b)
i = 2, e1 = 2, e2 = 1
a (b c)
(b c)
i = 0, e1 = 0, e2 = -1
else if (i > e2) {
while (i <= e1) {
unmount(c1[i], parentComponent, parentSuspense, true)
i++
}
}
对于老的节点大于新的节点的情况 ,对于超出的节点全部卸载 ( 这种情况说明已经patch完相同的vnode )
具体逻辑如图所示
⑤ 不确定的元素 ( 这种情况说明没有patch完相同的vnode ),我们可以接着①②的逻辑继续往下看
diff核心
在①②情况下没有遍历完的节点如下图所示。

剩下的节点。
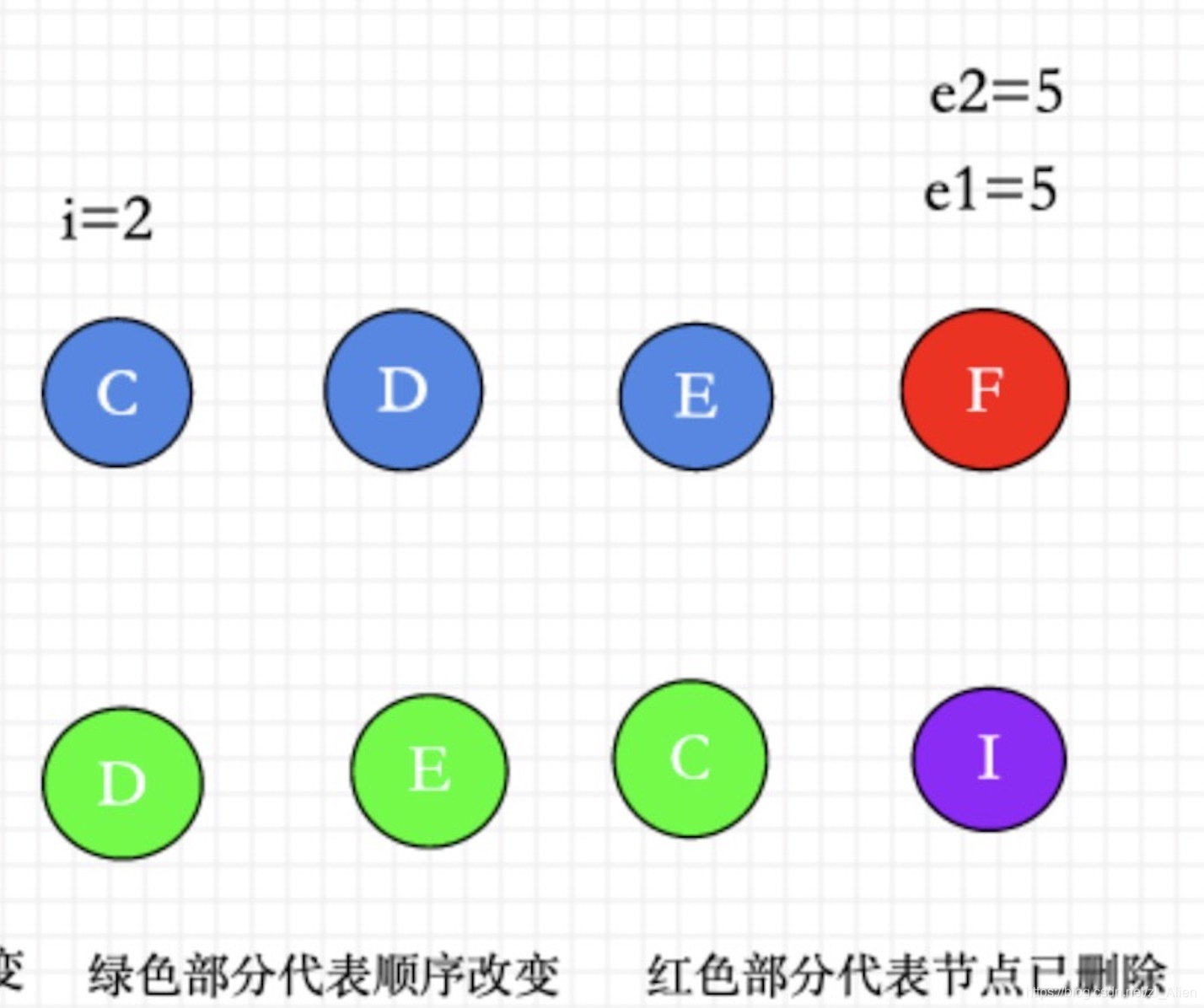
const s1 = i //第一步遍历到的index
const s2 = i
const keyToNewIndexMap: Map<string | number, number> = new Map()
/* 把没有比较过的新的vnode节点,通过map保存 */
for (i = s2; i <= e2; i++) {
if (nextChild.key != null) {
keyToNewIndexMap.set(nextChild.key, i)
}
}
let j
let patched = 0
const toBePatched = e2 - s2 + 1 /* 没有经过 path 新的节点的数量 */
let moved = false /* 证明是否 */
let maxNewIndexSoFar = 0
const newIndexToOldIndexMap = new Array(toBePatched)
for (i = 0; i < toBePatched; i++) newIndexToOldIndexMap[i] = 0
/* 建立一个数组,每个子元素都是0 [ 0, 0, 0, 0, 0, 0, ] */
遍历所有新节点把索引和对应的key,存入map keyToNewIndexMap中
keyToNewIndexMap 存放 key -> index 的map
D : 2
E : 3
C : 4
I : 5
接下来声明一个新的指针 j,记录剩下新的节点的索引。
patched ,记录在第⑤步patched新节点过的数量
toBePatched 记录⑤步之前,没有经过patched 新的节点的数量。
moved代表是否发生过移动,咱们的demo是已经发生过移动的。
newIndexToOldIndexMap 用来存放新节点索引和老节点索引的数组。
newIndexToOldIndexMap 数组的index是新vnode的索引 , value是老vnode的索引。
接下来
for (i = s1; i <= e1; i++) {
/* 开始遍历老节点 */
const prevChild = c1[i]
if (patched >= toBePatched) {
/* 已经patch数量大于等于, */
/* ① 如果 toBePatched新的节点数量为0 ,那么统一卸载老的节点 */
unmount(prevChild, parentComponent, parentSuspense, true)
continue
}
let newIndex
/* ② 如果,老节点的key存在 ,通过key找到对应的index */
if (prevChild.key != null) {
newIndex = keyToNewIndexMap.get(prevChild.key)
} else {
/* ③ 如果,老节点的key不存在 */
for (j = s2; j <= e2; j++) {
/* 遍历剩下的所有新节点 */
if (
newIndexToOldIndexMap[j - s2] === 0 && /* newIndexToOldIndexMap[j - s2] === 0 新节点没有被patch */
isSameVNodeType(prevChild, c2[j] as VNode)
) {
/* 如果找到与当前老节点对应的新节点那么 ,将新节点的索引,赋值给newIndex */
newIndex = j
break
}
}
}
if (newIndex === undefined) {
/* ①没有找到与老节点对应的新节点,删除当前节点,卸载所有的节点 */
unmount(prevChild, parentComponent, parentSuspense, true)
} else {
/* ②把老节点的索引,记录在存放新节点的数组中, */
newIndexToOldIndexMap[newIndex - s2] = i + 1
if (newIndex >= maxNewIndexSoFar) {
maxNewIndexSoFar = newIndex
} else {
/* 证明有节点已经移动了 */
moved = true
}
/* 找到新的节点进行patch节点 */
patch(
prevChild,
c2[newIndex] as VNode,
container,
null,
parentComponent,
parentSuspense,
isSVG,
optimized
)
patched++
}
}
这段代码算是diff算法的核心。
第一步: 通过老节点的key找到对应新节点的index:开始遍历老的节点,判断有没有key, 如果存在key通过新节点的keyToNewIndexMap找到与新节点index,如果不存在key那么会遍历剩下来的新节点试图找到对应index。
第二步:如果存在index证明有对应的老节点,那么直接复用老节点进行patch,没有找到与老节点对应的新节点,删除当前老节点。
第三步:newIndexToOldIndexMap找到对应新老节点关系。
到这里,我们patch了一遍,把所有的老vnode都patch了一遍。
如图所示
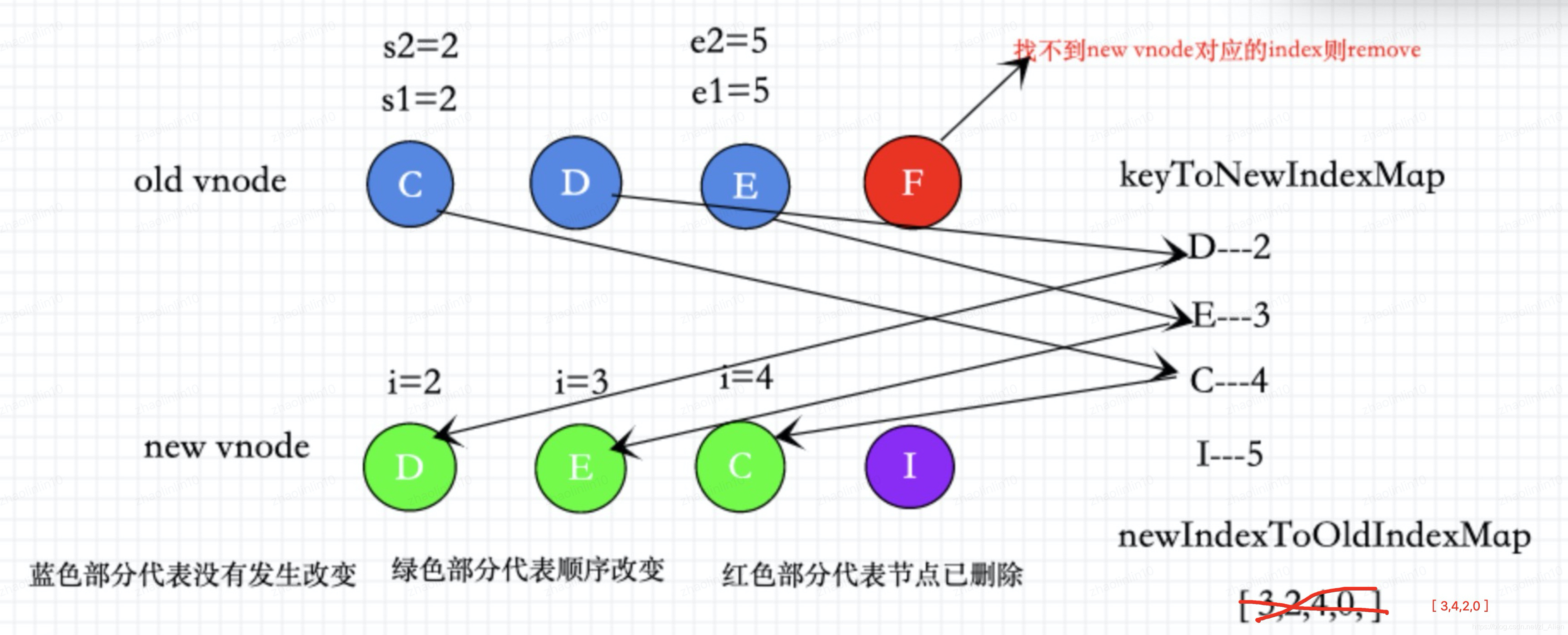
但是接下来的问题。
1 虽然已经patch过所有的老节点。可以对于已经发生移动的节点,要怎么真正移动dom元素。
2 对于新增的节点,(图中节点I)并没有处理,应该怎么处理。
/*移动老节点创建新节点*/
/* 根据最长稳定序列移动相对应的节点 */
const increasingNewIndexSequence = moved
? getSequence(newIndexToOldIndexMap)
: EMPTY_ARR
j = increasingNewIndexSequence.length - 1
for (i = toBePatched - 1; i >= 0; i--) {
const nextIndex = s2 + i
const nextChild = c2[nextIndex] as VNode
const anchor =
nextIndex + 1 < l2 ? (c2[nextIndex + 1] as VNode).el : parentAnchor
if (newIndexToOldIndexMap[i] === 0) {
/* 没有老的节点与新的节点对应,则创建一个新的vnode */
patch(
null,
nextChild,
container,
anchor,
parentComponent,
parentSuspense,
isSVG
)
} else if (moved) {
if (j < 0 || i !== increasingNewIndexSequence[j]) {
/*如果没有在长*/
/* 需要移动的vnode */
move(nextChild, container, anchor, MoveType.REORDER)
} else {
j--
}
⑥最长稳定序列
首选通过getSequence得到一个最长稳定序列,对于index === 0 的情况也就是新增节点(图中I) 需要从新mount一个新的vnode,然后对于发生移动的节点进行统一的移动操作
什么叫做最长稳定序列?
对于以下的原始序列
0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15
最长递增子序列为
0, 2, 6, 9, 11, 15.
为什么要得到最长稳定序列?
因为我们需要一个序列作为基础的参照序列,其他未在稳定序列的节点,进行移动。
总结
经过上述我们大致知道了diff算法的流程
- 从头对比找到有相同的节点 patch ,发现不同,立即跳出。
- 如果第一步没有patch完,立即,从后往前开始patch ,如果发现不同立即跳出循环。
- 如果新的节点大于老的节点数 ,对于剩下的节点全部以新的vnode处理( 这种情况说明已经patch完相同的vnode )。
- 对于老的节点大于新的节点的情况 , 对于超出的节点全部卸载 ( 这种情况说明已经patch完相同的vnode )。
- 不确定的元素( 这种情况说明没有patch完相同的vnode ) 与 3 ,4对立关系。
1 把没有比较过的新的vnode节点,通过map保存
记录已经patch的新节点的数量 patched
没有经过 path 新的节点的数量 toBePatched
建立一个数组newIndexToOldIndexMap,每个子元素都是[ 0, 0, 0, 0, 0, 0, ] 里面的数字记录老节点的索引 ,数组索引就是新节点的索引
开始遍历老节点
① 如果 toBePatched新的节点数量为0 ,那么统一卸载老的节点
② 如果,老节点的key存在 ,通过key找到对应的index
③ 如果,老节点的key不存在
1 遍历剩下的所有新节点
2 如果找到与当前老节点对应的新节点那么 ,将新节点的索引,赋值给newIndex
④ 没有找到与老节点对应的新节点,卸载当前老节点。
⑤ 如果找到与老节点对应的新节点,把老节点的索引,记录在存放新节点的数组中,
1 如果节点发生移动 记录已经移动了
2 patch新老节点 找到新的节点进行patch节点
遍历结束
如果发生移动
① 根据 newIndexToOldIndexMap 新老节点索引列表找到最长稳定序列
② 对于 newIndexToOldIndexMap -item =0 证明不存在老节点 ,从新形成新的vnode
③ 对于发生移动的节点进行移动处理。
composition-api
Composition API简介:一组基于函数的附加API,能够灵活地组成组件逻辑,Composition API希望将通过当前组件属性、可用的机制公开为JavaScript函数来解决这个问题。Vue核心团队将组件Composition API描述为“一套附加的、基于函数的api,允许灵活地组合组件逻辑”。使用Composition API编写的代码更易读,并且场景不复杂,这使得阅读和学习变得更容易
Options API
在vue2中,我们会在一个vue文件中定义methods,computed,watch,data中等等属性和方法,共同处理页面逻辑,我们称这种方式为Options API

优缺点
- 一个功能往往需要在不同的vue配置项中定义属性和方法,比较分散,项目小还好,清晰明了,但是项目大了后,一个methods中可能包含很多个方法,你往往分不清哪个方法对应着哪个功能
- 条例清晰,相同的放在相同的地方;但随着组件功能的增大,关联性会大大降低,组件的阅读和理解难度会增加;
Composition-API
为了解决在vue2中出现的问题,在vue3 Composition API 中,我们的代码是根据逻辑功能来组织的,一个功能所定义的所有api会放在一起(更加的高内聚,低耦合这样做,即使项目很大,功能很多,我们都能快速的定位到这个功能所用到的所有API

Composition-API将每个功能模块所定义的所有的API都放在一个模块,这就解决了Vue2中因为模块分散而造成的问题
- Composition API 是根据逻辑相关性组织代码的,提高可读性和可维护性
- 基于函数组合的 API 更好的重用逻辑代码(在vue2 Options API中通过Mixins重用逻辑代码,容易发生命名冲突且关系不清)
API介绍
Setup函数
使用setup 函数时,它将接受两个参数:props,context
props:父组件传递给子组件的数据,context: 包含三个属性attrs, slots, emit
(1)attrs:所有的非prop的attribute;
(2)slots:父组件传递过来的插槽
(3)emit:当我们组件内部需要发出事件时会用到emit
props: {
message: {
type: String,
required: true
default:'长夜将至'
}
},
setup(props,context) {
// Attribute (非响应式对象)
console.log(context.attrs)
// 插槽 (非响应式对象)
console.log(context.slots)
// 触发事件 (方法)
console.log(context.emit)
//因为setup函数中是没有this这个东西的, 然而当我们需要拿到父组件所传递过来的数据时, setup函数的第一个参数props便起作用了
console.log(this)// undefined
console.log(props.message);//长夜将至
return {
} // 我们可以通过setup的返回值来替代data选项(但是当setup和data选项同时存在时,使用的是setup中的数据),并且这里返回的任何内容都可以用于组件的其余部分
},
- setup函数是处于 生命周期函数 beforeCreate 和 Created 两个钩子函数之前的函数
- 执行 setup 时,组件实例尚未被创建(在 setup() 内部,this 不会是该活跃实例的引用,即不指向vue实例,Vue为了避免我们错误的使用,直接将 setup函数中的this修改成了 undefined)
ref
ref 用于为数据添加响应式状态。由于reactive只能传入对象类型的参数,而对于基本数据类型要添加响应式状态就只能用ref了,同样返回一个具有响应式状态的副本。
<template>
<h1>{
{
newObj}}</h1>
<button @click="change">点击按钮</button>
</template>
<script>
import {
ref} from 'vue';
export default {
name:'App',
setup(){
let obj = {
name : 'alice', age : 12};
let newObj= ref(obj.name);
function change(){
newObj.value = 'Tom';
console.log(obj,newObj)
}
return {
newObj,change}
}
}
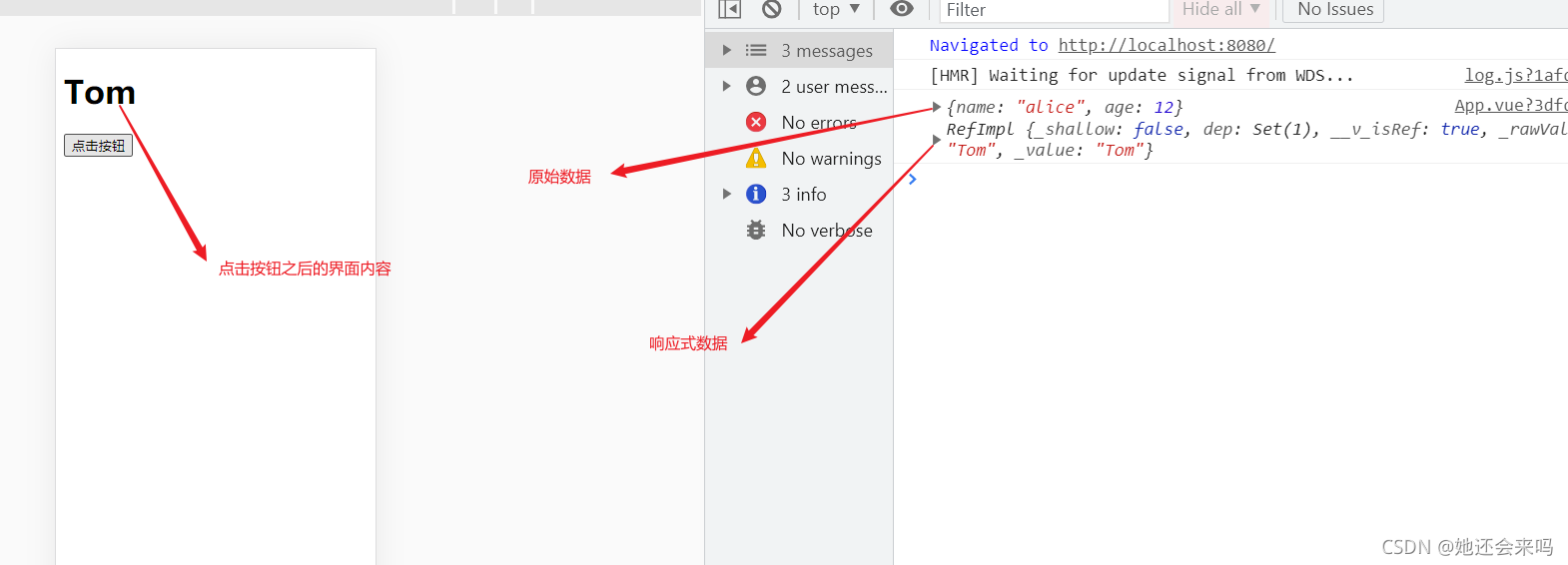
- ref函数只能监听简单类型的变化,不能监听复杂类型的变化,比如对象和数组
- ref的本质是拷贝,与原始数据没有引用关系。
- ref修改响应式数据不会影响原始数据,界面会更新
toRef
toRef 用于为源响应式对象上的属性新建一个ref,从而保持对其源对象属性的响应式连接
<template>
<h1>{
{
newObj}}</h1>
<button @click="change">点击按钮</button>
</template>
<script>
import {
toRef} from 'vue';
export default {
name:'App',
setup(){
let obj = {
name : 'alice', age : 12};
let newObj= toRef(obj, 'name');
function change(){
newObj.value = 'Tom';
console.log(obj,newObj)
}
return {
newObj,change}
}
}
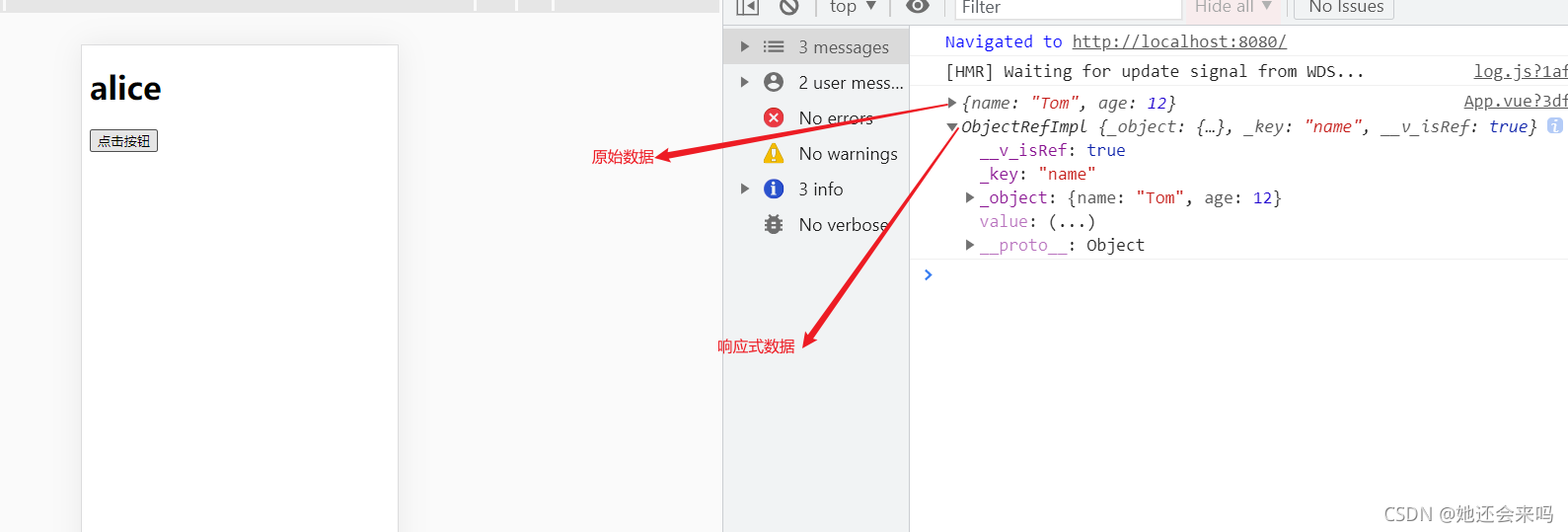
- 获取数据值的时候需要加.value
- toRef后的ref数据不是原始数据的拷贝,而是引用,改变结果数据的值也会同时改变原始数据
- toRef接收两个参数,第一个参数是哪个对象,第二个参数是对象的哪个属性
- toRef一次仅能设置一个数据
toRefs
有的时候,我们希望将对象的多个属性都变成响应式数据,并且要求响应式数据和原始数据关联,并且更新响应式数据的时候不更新界面,就可以使用toRefs,用于批量设置多个数据为响应式数据。
<template>
<h1>{
{
newObj}}</h1>
<button @click="change">点击按钮</button>
</template>
<script>
import {
toRefs} from 'vue';
export default {
name:'App',
setup(){
let obj = {
name : 'alice', age : 12};
let newObj= toRefs(obj);
function change(){
newObj.name.value = 'Tom';
newObj.age.value = 18;
console.log(obj,newObj)
}
return {
newObj,change}
}
}
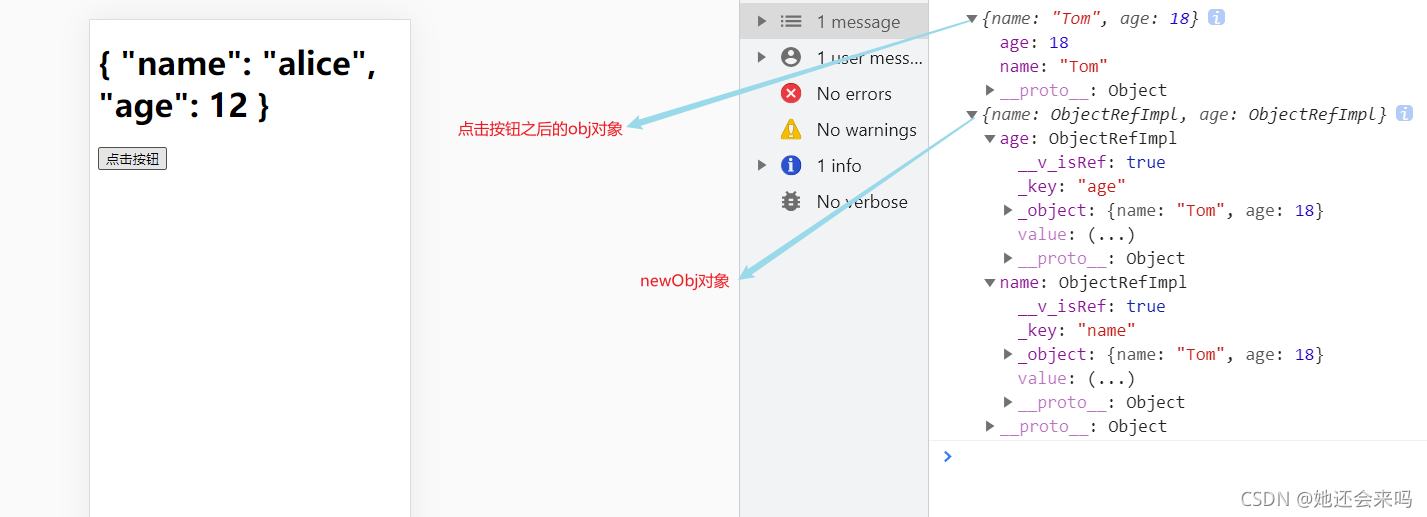
从上图可以明显看出,点击按钮之后,原始数据和响应式数据更新,但界面不发生变化,
- toRefs接收一个对象作为参数,它会遍历对象身上的所有属性,然后挨个调用toRef执行
- 获取数据值的时候需要加.value
- toRefs后的ref数据不是原始数据的拷贝,而是引用,改变结果数据的值也会同时改变原始数据
带 ref 的响应式变量
setup()内使用响应式数据时,需要通过.value获取,但从 setup() 中返回的对象上的 property 返回并可以在模板中被访问时,它将自动展开为内部值。不需要在模板中追加 .value
<template>
<h1>{
{
count}}</h1>
</template>
<script>
import {
ref } from 'vue' // ref函数使任何变量在任何地方起作用
export default {
setup(){
const count= ref(0)
console.log(count)
console.log(count.value) // 0
return {
count }
}
}
</script>
解析
目录结构
vue3
├── packages # 所有包(此目录只保持一部分包)
│ ├── compiler-core # 编译核心包
│ │ ├── api-extractor.json # 用于合并.d.ts, api-extractor API Extractor是一个TypeScript分析工具
│ │ ├── src # 包主要开发目录
│ │ ├── index.js # 包入口,导出的都是dist目录的文件
│ │ ├── LICENSE # 开源协议文件
│ │ ├── package.json
│ │ ├── README.md # 包描述文件
│ │ └── __tests__ # 包测试文件
├── scripts # 一些工程化的脚本,本文重点
│ ├── bootstrap.js # 用于生成最小化的子包
│ ├── build.js # 用于打包所有packages下的包
│ ├── checkYarn.js # 检查是否是yarn进行安装
│ ├── dev.js # 监听模式开发
│ ├── release.js # 用于发布版本
│ ├── setupJestEnv.ts # 设置Jest的环境
│ ├── utils.js # 公用的函数包
│ └── verifyCommit.js # git提交验证message
├── test-dts # 验证类型声明
│ ├── component.test-d.ts
| ├── .....-d.ts
├── api-extractor.json # 用于合并.d.ts
├── CHANGELOG.md # 版本变更日志
├── jest.config.js # jest测试配置
├── LICENSE
├── package.json
├── README.md
├── rollup.config.js # rollup配置
├── tsconfig.json # ts配置
└── yarn.lock # yarn锁定版本文件
其中,Vue 3和核心源码都在packages里面,并且是基于RollUp构建,其中每个目录代表的含义,如下所示:
├── packages
│ ├── compiler-core // 核心编译器(平台无关)
│ ├── compiler-dom // dom编译器
│ ├── compiler-sfc // vue单文件编译器
│ ├── compiler-ssr // 服务端渲染编译
│ ├── global.d.ts // typescript声明文件
│ ├── reactivity // 响应式模块,可以与任何框架配合使用
│ ├── runtime-core // 运行时核心实例相关代码(平台无关)
│ ├── runtime-dom // 运行时dom 关api,属性,事件处理
│ ├── runtime-test // 运行时测试相关代码
│ ├── server-renderer // 服务端渲染
│ ├── sfc-playground // 单文件组件在线调试器
│ ├── shared // 内部工具库,不对外暴露API
│ ├── size-check // 简单应用,用来测试代码体积
│ ├── template-explorer // 用于调试编译器输出的开发工具
│ └── vue // 面向公众的完整版本, 包含运行时和编译器
│ └── vue-compat //针对vue2的兼容版本
通过上面源码结构,可以看到有下面几个模块比较特别:
- compiler-core
- compiler-dom
- runtime-core
- runtime-dom
可以看到core, dom 分别出现了两次,那么compiler和runtime它们之间又有什么区别呢? - compile:我们可以理解为程序编绎时,是指我们写好的源代码在被编译成为目标文件这段时间,可以通俗的看成是我们写好的源代码在被构建工具转换成为最终可执行的文件这段时间,在这里可以理解为我们将.vue文件编绎成浏览器能识别的.js文件的一些工作。
- runtime:可以理解为程序运行时,即是程序被编译了之后,在浏览器打开程序并运行它直到程序关闭的这段时间的系列处理。
响应式原理
Proxy API
见上
Proxy和响应式对象reactive
在Vue 3中,使用响应式对象方法如下代码所示:
import {
ref,reactive} from 'vue'
...
setup(){
const name = ref('test')
const state = reactive({
list: []
})
return {
name,state}
}
...
在Vue 3中,Composition API中会经常使用创建响应式对象的方法ref/reactive,其内部就是利用了Proxy API来实现的,特别是借助handler的set方法,可以实现双向数据绑定相关的逻辑,这对于Vue 2中的Object.defineProperty()是很大的改变,主要提升如下:
- Object.defineProperty()只能单一的监听已有属性的修改或者变化,无法检测到对象属性的新增或删除(Vue
2中是采用$set()方法来解决),而Proxy则可以轻松实现。 - Object.defineProperty()无法监听响应式数据类型是数组的变化(主要是数组长度变化,Vue
2中采用重写数组相关方法并添加钩子来解决),而Proxy则可以轻松实现。
正是由于Proxy的特性,在原本使用Object.defineProperty()需要很复杂的方式才能实现的上面两种能力,在Proxy无需任何配置,利用其原生的特性就可以轻松实现。
ref()方法运行原理
在Vue 3的源码中,所有关于响应式的代码都在vue-next/package/reactivity下面,其中reactivity/src/index.ts里暴露了所有可以使用的方法。我们以常用的ref()方法举例,来看看Vue 3是如何利用Proxy的。 ref()方法的主要逻辑在reactivity/src/ref.ts中,其代码如下:
...
// 入口方法
export function ref(value?: unknown) {
return createRef(value, false)
}
function createRef(rawValue: unknown, shallow: boolean) {
// rawValue表示原始对象,shallow表示是否递归
// 如果本身已经是ref对象,则直接返回
if (isRef(rawValue)) {
return rawValue
}
// 创建一个新的RefImpl对象
return new RefImpl(rawValue, shallow)
}
...
createRef这个方法接收的第二个参数是shallow,表示是否是递归监听响应式,这个和另外一个响应式方法shallowRef()是对应的。在RefImpl构造函数中,有一个value属性,这个属性是由toReactive()方法所返回,toReactive()方法则在reactivity/src/reactive.ts文件中,如下代码所示:
class RefImpl<T> {
...
constructor(value: T, public readonly _shallow: boolean) {
this._rawValue = _shallow ? value : toRaw(value)
// 如果是非递归,调用toReactive
this._value = _shallow ? value : toReactive(value)
}
...
}
在reactive.ts中,则开始真正创建一个响应式对象,如下代码所示:
export function reactive(target: object) {
// 如果是readonly,则直接返回,就不添加响应式了
if (target && (target as Target)[ReactiveFlags.IS_READONLY]) {
return target
}
return createReactiveObject(
target,// 原始对象
false,// 是否readonly
mutableHandlers,// proxy的handler对象baseHandlers
mutableCollectionHandlers,// proxy的handler对象collectionHandlers
reactiveMap// proxy对象映射
)
}
其中,createReactiveObject()方法传递了两种handler,分别是baseHandlers和collectionHandlers,如果target的类型是Map,Set,WeakMap,WeakSet则会使用collectionHandlers,类型是Object,Array则会是baseHandlers,如果是一个基础对象,也不会创建Proxy对象,reactiveMap则存储所有响应式对象的映射关系,用来避免同一个对象的重复创建响应式。我们在来看看createReactiveObject()方法的实现,如下代码所示:
function createReactiveObject(...) {
// 如果target不满足typeof val === 'object',则直接返回target
if (!isObject(target)) {
if (__DEV__) {
console.warn(`value cannot be made reactive: ${
String(target)}`)
}
return target
}
// 如果target已经是proxy对象或者只读,则直接返回
// exception: calling readonly() on a reactive object
if (
target[ReactiveFlags.RAW] &&
!(isReadonly && target[ReactiveFlags.IS_REACTIVE])
) {
return target
}
// 如果target已经被创建过Proxy对象,则直接返回这个对象
const existingProxy = proxyMap.get(target)
if (existingProxy) {
return existingProxy
}
// 只有符合类型的target才能被创建响应式
const targetType = getTargetType(target)
if (targetType === TargetType.INVALID) {
return target
}
// 调用Proxy API创建响应式
const proxy = new Proxy(
target,
targetType === TargetType.COLLECTION ? collectionHandlers : baseHandlers
)
// 标记该对象已经创建过响应式
proxyMap.set(target, proxy)
return proxy
}
可以看到在createReactiveObject()方法中,主要做了以下事情:
- 防止只读和重复创建响应式。
- 根据不同的target类型选择不同的handler。
- 创建Proxy对象。
最终会调用new Proxy来创建响应式对象,我们以baseHandlers为例,看看这个handler是怎么实现的,在reactivity/src/baseHandlers.ts可以看到这部分代码,主要实现了这几个handler,如下代码所示:
const get = /*#__PURE__*/ createGetter()
...
export const mutableHandlers: ProxyHandler<object> = {
get,
set,
deleteProperty,
has,
ownKeys
}
以handler.get为例看看在其内部做了什么操作,当我们尝试读取对象的属性时,便会进入get方法,其核心代码如下所示:
function createGetter(isReadonly = false, shallow = false) {
return function get(target: Target, key: string | symbol, receiver: object) {
if (key === ReactiveFlags.IS_REACTIVE) {
// 如果访问对象的key是__v_isReactive,则直接返回常量
return !isReadonly
} else if (key === ReactiveFlags.IS_READONLY) {
// 如果访问对象的key是__v_isReadonly,则直接返回常量
return isReadonly
} else if (// 如果访问对象的key是__v_raw,或者原始对象只读对象等等直接返回target
key === ReactiveFlags.RAW &&
receiver ===
(isReadonly
? shallow
? shallowReadonlyMap
: readonlyMap
: shallow
? shallowReactiveMap
: reactiveMap
).get(target)
) {
return target
}
// 如果target是数组类型
const targetIsArray = isArray(target)
// 并且访问的key值是数组的原生方法,那么直接返回调用结果
if (!isReadonly && targetIsArray && hasOwn(arrayInstrumentations, key)) {
return Reflect.get(arrayInstrumentations, key, receiver)
}
// 求值
const res = Reflect.get(target, key, receiver)
// 判断访问的key是否是Symbol或者不需要响应式的key例如__proto__,__v_isRef,__isVue
if (isSymbol(key) ? builtInSymbols.has(key) : isNonTrackableKeys(key)) {
return res
}
// 收集响应式,为了后面的effect方法可以检测到
if (!isReadonly) {
track(target, TrackOpTypes.GET, key)
}
// 如果是非递归绑定,直接返回结果
if (shallow) {
return res
}
// 如果结果已经是响应式的,先判断类型,再返回
if (isRef(res)) {
const shouldUnwrap = !targetIsArray || !isIntegerKey(key)
return shouldUnwrap ? res.value : res
}
// 如果当前key的结果也是一个对象,那么就要递归调用reactive方法对改对象再次执行响应式绑定逻辑
if (isObject(res)) {
return isReadonly ? readonly(res) : reactive(res)
}
// 返回结果
return res
}
}
上面这段代码是Vue 3响应式的核心代码之一,其逻辑相对比较复杂,读者可以根据注释来理解,总结下来,这段代码主要做了以下事情:
- 对于handler.get方法来说,最终都会返回当前对象对应key的结果即obj[key],所以该段代码最终会return结果。
- 对非响应式key,只读key等直接返回对应的结果。
- 对于数组类型的target,key值如果是原型上的方法,例如includes,push,pop等,采用Reflect.get直接返回。
- 在effect添加收集监听track,为响应式监听服务。
- 当当前key对应的结果是一个对象时,为了保证set方法能够触发,需要循环递归的对这个对象进行响应式绑定即递归调用reactive()方法。
handler.get方法主要功能是对结果value的返回,那么我们看看handler.set主要做了什么,其代码如下所示:
function createSetter(shallow = false) {
return function set(
target: object,
key: string | symbol,
value: unknown,// 即将被设置的新值
receiver: object
): boolean {
// 缓存旧值
let oldValue = (target as any)[key]
if (!shallow) {
// 新旧值转换原始对象
value = toRaw(value)
oldValue = toRaw(oldValue)
// 如果旧值已经是一个RefImpl对象且新值不是RefImpl对象
// 例如var v = Vue.reactive({a:1,b:Vue.ref({c:3})})场景的set
if (!isArray(target) && isRef(oldValue) && !isRef(value)) {
oldValue.value = value // 直接将新值赋给旧址的响应式对象里
return true
}
}
// 用来判断是否是新增key还是更新key的值
const hadKey =
isArray(target) && isIntegerKey(key)
? Number(key) < target.length
: hasOwn(target, key)
// 设置set结果,并添加监听effect逻辑
const result = Reflect.set(target, key, value, receiver)
// 判断target没有动过,包括在原型上添加或者删除某些项
if (target === toRaw(receiver)) {
if (!hadKey) {
trigger(target, TriggerOpTypes.ADD, key, value)// 新增key的触发监听
} else if (hasChanged(value, oldValue)) {
trigger(target, TriggerOpTypes.SET, key, value, oldValue)// 更新key的触发监听
}
}
// 返回set结果 true/false
return result
}
}
handler.set方法核心功能是设置key对应的值即obj[key] = value,同时对新旧值进行逻辑判断和处理,最后添加上trigger触发监听track逻辑,便于触发effect。 如果读者感觉上述源码理解比较困难,笔者剔除一些边界和兼容判断,将整个流程进行梳理和简化,可以参考下面这段便于理解的代码:
let foo = {
a:{
c:3,d:{
e:4}},b:2}
const isObject = (val)=>{
return val !== null && typeof val === 'object'
}
const createProxy = (target)=>{
let p = new Proxy(target,{
get:(obj,key)=>{
let res = obj[key] ? obj[key] : undefined
// 添加监听
track(target)
// 判断类型,避免死循环
if (isObject(res)) {
return createProxy(res)// 循环递归调用
} else {
return res
}
},
set: (obj, key, value)=> {
console.log('set')
obj[key] = value;
// 触发监听
trigger(target)
return true
}
})
return p
}
let result = createProxy(foo)
result.a.d.e = 6 // 打印出set
当尝试去修改一个多层嵌套的对象的属性时,会触发该属性的上一级对象的get方法,利用这个就可以对每个层级的对象添加Proxy代理,这样就实现了多层嵌套对象的属性修改问题,在此基础上同时添加track和trigger逻辑,就完成了基本的响应式流程。
虚拟DOM
什么是虚拟DOM
在浏览器中,HTML页面由基本的DOM树来组成的,当其中一部分发生变化时,其实就是对应某个DOM节点发生了变化,当DOM节点发生变化时就会触发对应的重绘或者重排,当过多的重绘和重排在短时间内发生时,就会可能引起页面的卡顿,所以改变DOM是有一些代价的,那么如何优化DOM变化的次数以及在合适的时机改变DOM就是开发者需要注意的事情。
虚拟DOM就是为了解决上述浏览器性能问题而被设计出来的。当一次操作中有10次更新DOM的动作,虚拟DOM不会立即操作DOM,而是和原本的DOM进行对比,将这10次更新的变化部分内容保存到内存中,最终一次性的应用在到DOM树上,再进行后续操作,避免大量无谓的计算量。
虚拟DOM实际上就是采用JavaScript对象来存储DOM节点的信息,将DOM的更新变成对象的修改,并且这些修改计算在内存中发生,当修改完成后,再将JavaScript转换成真实的DOM节点,交给浏览器,从而达到性能的提升。 例如下面一段DOM节点,如下代码所示:
<div id="app">
<p class="text">Hello</p>
</div>
转换成一般的虚拟DOM对象结构,如下代码所示:
{
tag: 'div',
props: {
id: 'app'
},
chidren: [
{
tag: 'p',
props: {
className: 'text'
},
chidren: [
'Hello'
]
}
]
}
上面这段代码就是一个基本的虚拟DOM,但是他并非是Vue中使用的虚拟DOM结构,因为Vue要复杂的多。
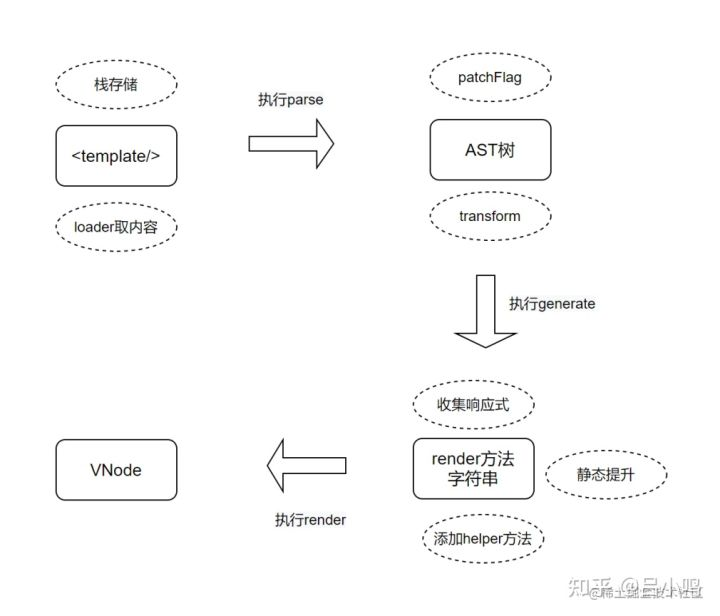
Vue 3虚拟DOM
在Vue中,我们写在<template>标签内的内容都属于DOM节点,这部分内容会被最终转换成Vue中的虚拟DOM对象VNode,其中的步骤比较复杂,主要有以下几个过程:
- 抽取
<template>内容进行compile编译。 - 得到AST语法树,并生成render方法。
- 执行render方法得到VNode对象。
- VNode转换真实DOM并渲染到页面。
完整流程如下图:
我们以一个简单的demo为例子,在Vue 3的源码里去寻找,到底是如何一步一步进行了,demo如下代码所示:
<div id="app">
<div>
{
{
name}}
</div>
<p>123</p>
</div>
Vue.createApp({
data(){
return {
name : 'abc'
}
}
}).mount("#app")
上面代码中,data中定义了一个响应式数据name,并在<template>中使用插值表达式{
{name}}进行使用,还有一个静态节点<p>123</p>。
获取<template>内容
调用createApp()方法,会进入到源码packages/runtime-dom/src/index.ts里面的createApp()方法,如下代码所示:
export const createApp = ((...args) => {
const app = ensureRenderer().createApp(...args)
...
app.mount = (containerOrSelector: Element | ShadowRoot | string): any => {
if (!isFunction(component) && !component.render && !component.template) {
// 将#app绑定的HTML内容赋值给template项上
component.template = container.innerHTML
// 调用mount方法渲染
const proxy = mount(container, false, container instanceof SVGElement)
return proxy
}
...
return app
}) as CreateAppFunction<Element>
对于根组件来说,<template>的内容由挂载的#app元素里面的内容组成,如果项目是采用npm和Vue Cli+Webpack这种前端工程化的方式,那么对于<template>的内容则主要由对应的loader在构建时对文件进行处理来获取,这和在浏览器运行时的处理方式是不一样的。
生成AST语法树
在得到<template>后,就依据内容生成AST语法树。抽象语法树(Abstract Syntax Tree,AST),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现;而类似于if-condition-then这样的条件跳转语句,可以使用带有三个分支的节点来表示。如下代码所示:
while b ≠ 0
if a > b
a := a − b
else
b := b − a
return a
如果将上述代码转换成广泛意义上的语法树,如图所示。
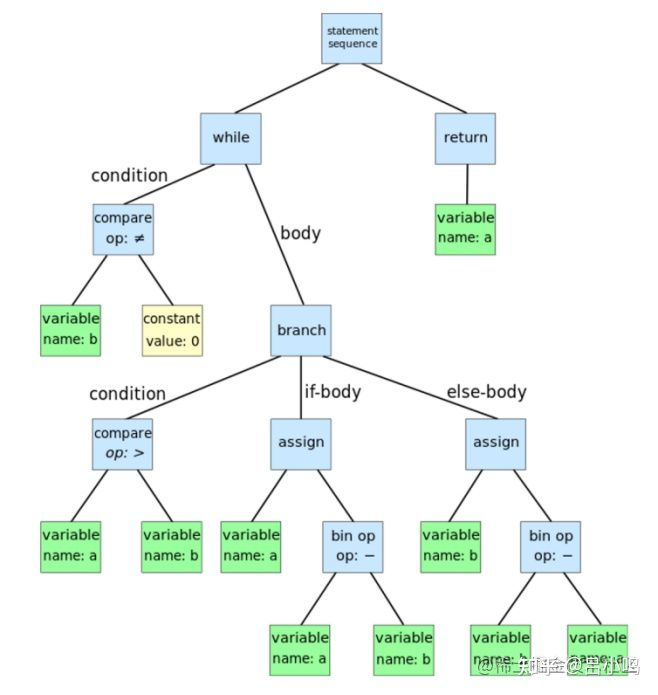
对于<template>的内容,其大部分是由DOM组成,但是也会有if-condition-then这样的条件语句,例如v-if,v-for指令等等,在Vue 3中,这部分逻辑在源码packages\compiler-core\src\compile.ts中baseCompile方法,核心代码如下所示:
export function baseCompile(
template: string | RootNode,
options: CompilerOptions = {
}
): CodegenResult {
...
// 通过template生成ast树结构
const ast = isString(template) ? baseParse(template, options) : template
...
// 转换
transform(
ast,
...
)
return generate(
ast,
extend({
}, options, {
prefixIdentifiers
})
)
}
baseCompile方法主要做了以下事情:
- 生成Vue中的AST对象。
- 将AST对象作为参数传入transform函数,进行转换。
- 将转换后的AST对象作为参数传入generate函数,生成render函数。
其中,baseParse方法用来创建AST对象,在Vue 3中,AST对象是一个RootNode类型的树状结构,在源码packages\compiler-core\src\ast.ts中,其结构如下代码所示:
export function createRoot(
children: TemplateChildNode[],
loc = locStub
): RootNode {
return {
type: NodeTypes.ROOT, // 元素类型
children, // 子元素
helpers: [],// 帮助函数
components: [],// 子组件
directives: [], // 指令
hoists: [],// 标识静态节点
imports: [],
cached: 0, // 缓存标志位
temps: 0,
codegenNode: undefined,// 存储生成render函数字符串
loc // 描述元素在AST树的位置信息
}
}
其中,children存储的时后代元素节点的数据,这就构成一个AST树结构,type表示元素的类型NodeType,主要分为HTML普通类型和Vue指令类型等,常见的有以下几种:
ROOT, // 根元素 0
ELEMENT, // 普通元素 1
TEXT, // 文本元素 2
COMMENT, // 注释元素 3
SIMPLE_EXPRESSION, // 表达式 4
INTERPOLATION, // 插值表达式 {
{ }} 5
ATTRIBUTE, // 属性 6
DIRECTIVE, // 指令 7
IF, // if节点 9
JS_CALL_EXPRESSION, // 方法调用 14
...
hoists是一个数组,用来存储一些可以静态提升的元素,在后面的transform会将静态元素和响应式元素分开创建,这也是Vue 3中优化的体现,codegenNode则用来存储最终生成的render方法的字符串,loc表示元素在AST树的位置信息。
在生成AST树时,Vue 3在解析<template>内容时,会用一个栈stack来保存解析到的元素标签。当它遇到开始标签时,会将这个标签推入栈,遇到结束标签时,将刚才的标签弹出栈。它的作用是保存当前已经解析了,但还没解析完的元素标签。这个栈还有另一个作用,在解析到某个字节点时,通过stack[stack.length - 1]可以获取它的父元素。
demo代码中生成的AST语法树如下图所示。

生成render方法字符串
在得到AST对象后,会进入transform方法,在源码packages\compiler-core\src\transform.ts中,其核心代码如下所示:
export function transform(root: RootNode, options: TransformOptions) {
// 数据组装
const context = createTransformContext(root, options)
// 转换代码
traverseNode(root, context)
// 静态提升
if (options.hoistStatic) {
hoistStatic(root, context)
}// 服务端渲染
if (!options.ssr) {
createRootCodegen(root, context)
}
// 透传元信息
root.helpers = [...context.helpers.keys()]
root.components = [...context.components]
root.directives = [...context.directives]
root.imports = context.imports
root.hoists = context.hoists
root.temps = context.temps
root.cached = context.cached
if (__COMPAT__) {
root.filters = [...context.filters!]
}
}
transform方法主要是对AST进行进一步转化,为generate函数生成render方法做准备,主要做了以下事情:
- traverseNode方法将会递归的检查和解析AST元素节点的属性,例如结合helpers方法对@click等事件添加对应的方法和事件回调,对插值表达式、指令、props添加动态绑定等。
- 处理类型逻辑包括静态提升逻辑,将静态节点赋值给hoists,以及根据不同类型的节点打上不同的patchFlag,便于后续diff使用。
- 在AST上绑定并透传一些元数据。
generate方法主要是生成render方法的字符串code,在源码packages\compiler-core\src\codegen.ts中,其核心代码如下所示:
export function generate(
ast: RootNode,
options: CodegenOptions & {
onContextCreated?: (context: CodegenContext) => void
} = {
}
): CodegenResult {
const context = createCodegenContext(ast, options)
if (options.onContextCreated) options.onContextCreated(context)
const {
mode,
push,
prefixIdentifiers,
indent,
deindent,
newline,
scopeId,
ssr
} = context
...
// 缩进处理
indent()
deindent()
// 单独处理component、directive、filters
genAssets()
// 处理NodeTypes里的所有类型
genNode(ast.codegenNode, context)
...
// 返回code字符串
return {
ast,
code: context.code,
preamble: isSetupInlined ? preambleContext.code : ``,
// SourceMapGenerator does have toJSON() method but it's not in the types
map: context.map ? (context.map as any).toJSON() : undefined
}
}
generate方法的核心逻辑在genNode方法中,其逻辑是根据不同的NodeTypes类型构造出不同的render方法字符串,部分类型如下代码所示:
switch (node.type) {
case NodeTypes.ELEMENT:
case NodeTypes.IF:
case NodeTypes.FOR:// for关键字元素节点
genNode(node.codegenNode!, context)
break
case NodeTypes.TEXT:// 文本元素节点
genText(node, context)
break
case NodeTypes.VNODE_CALL:// 核心:VNode混合类型节点(AST语法树节点)
genVNodeCall(node, context)
break
case NodeTypes.COMMENT: // 注释元素节点
genComment(node, context)
break
case NodeTypes.JS_FUNCTION_EXPRESSION:// 方法调用节点
genFunctionExpression(node, context)
break
...
其中:
- 节点类型NodeTypes.VNODE_CALL对应genVNodeCall方法和ast.ts文件里面的createVNodeCall方法对应,后者用来返回VNodeCall,前者生成对应的VNodeCall这部分render方法字符串,是整个render方法字符串的核心。
- 节点类型NodeTypes.FOR对应for关键字元素节点,其内部是递归调用了genNode方法。
- 节点类型NodeTypes.TEXT对应文本元素节点负责静态文本的生成。
- 节点类型NodeTypes.JS_FUNCTION_EXPRESSION对应方法调用节点,负责方法表达式的生成。
终于,经过一系列的加工,最终生成的render方法字符串结果如下所示:
(function anonymous(
) {
const _Vue = Vue
const {
createElementVNode: _createElementVNode } = _Vue
const _hoisted_1 = ["data-a"] // 静态节点
const _hoisted_2 = /*#__PURE__*/_createElementVNode("p", null, "123", -1 /* HOISTED */)// 静态节点
return function render(_ctx, _cache) {
// render方法
with (_ctx) {
const {
toDisplayString: _toDisplayString, createElementVNode: _createElementVNode, Fragment: _Fragment, openBlock: _openBlock, createElementBlock: _createElementBlock } = _Vue // helper方法
return (_openBlock(), _createElementBlock(_Fragment, null, [
_createElementVNode("div", {
"data-a": attr }, _toDisplayString(name), 9 /* TEXT, PROPS */, _hoisted_1),
_hoisted_2
], 64 /* STABLE_FRAGMENT */))
}
}
})
_createElementVNode,_openBlock等等上一步传进来的helper方法。其中<p>123</p>这种属于没有响应式绑定的静态节点,会被单独区分,而对于动态节点会使用createElementVNode方法来创建,最终这两种节点会进入createElementBlock方法进行VNode的创建。
render方法中使用了with关键字,with的作用如下代码所示:
const obj = {
a:1
}
with(obj){
console.log(a) // 打印1
}
在with(_ctx)包裹下,我们在data中定义的响应式变量才能正常使用,例如调用_toDisplayString(name),其中name就是响应式变量。
得到最终VNode对象
最终,这是一段可执行代码,会赋值给组件Component.render方法上,其源码在packages\runtime-core\src\component.ts中,如下所示:
...
Component.render = compile(template, finalCompilerOptions)
...
if (installWithProxy) {
// 绑定代理
installWithProxy(instance)
}
...
compile方法是最初baseCompile方法的入口,在完成赋值后,还需要绑定代理,执行installWithProxy方法,其源码在runtime-core/src/component.ts中,如下所示:
export function registerRuntimeCompiler(_compile: any) {
compile = _compile
installWithProxy = i => {
if (i.render!._rc) {
i.withProxy = new Proxy(i.ctx, RuntimeCompiledPublicInstanceProxyHandlers)
}
}
}
这主要是给render里_ctx的响应式变量添加绑定,当上面render方法里的name被使用时,可以通过代理监听到调用,这样就会进入响应式的监听收集track,当触发trigger监听时,进行diff。
在runtime-core/src/componentRenderUtils.ts源码里的renderComponentRoot方法里会执行render方法得到VNode对象,其核心代码如下所示:
export function renderComponentRoot(){
// 执行render
let result = normalizeVNode(render!.call(
proxyToUse,
proxyToUse!,
renderCache,
props,
setupState,
data,
ctx
))
...
return result
}
demo代码中最终得到的VNode对象如下图所示。

上图就是通过render方法运行后得到的VNode对象,可以看到children和dynamicChildren区分,前者包括了两个子节点分别是<div>和<p>这个和在<template>里面定义的内容是对应的,而后者只存储了动态节点,包括动态props即data-a属性。同时VNode也是树状结构,通过children和dynamicChildren一层一层递进下去。
在通过render方法得到VNode的过程也是对指令,插值表达式,响应式数据,插槽等一系列Vue语法的解析和构造过程,最终生成结构化的VNode对象,可以将整个过程总结成流程图,便于读者理解,如下图所示。
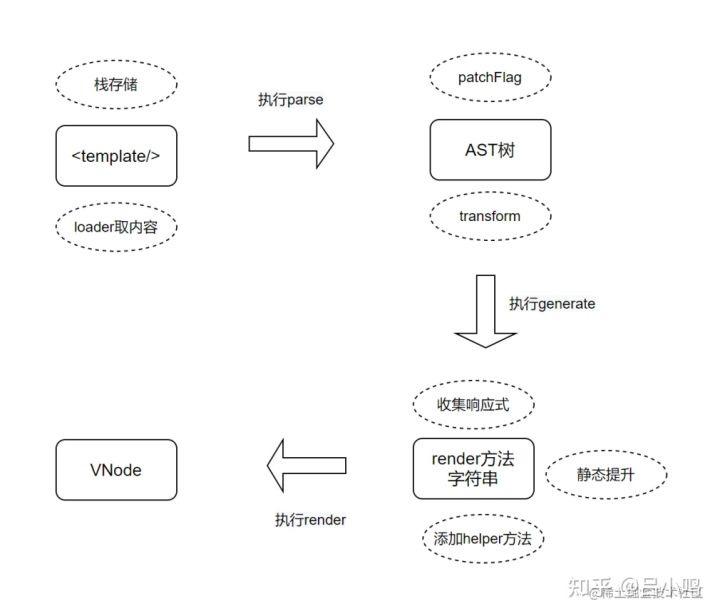
另外一个需要关注的属性是patchFlag这个是后面进行VNode的diff时所用到的标志位,数字64表示稳定不需要改变。最后得到VNode对象后需要转换成真实的DOM节点,这部分逻辑是在虚拟DOM的diff中完成的
来源
Vue3源码解析–目录结构
Vue 3源码解析–响应式原理
Vue3源码解析–虚拟DOM
Vue3 源码解析(一)—— 包管理
vue3.0 diff算法详解(超详细)
Composition-API