文章目录
读写分离
为什么要读写分离?
降低数据库服务器的压力
如何实现读写分离?
- 一个主库多个从库
- 配置主库复制数据到从库
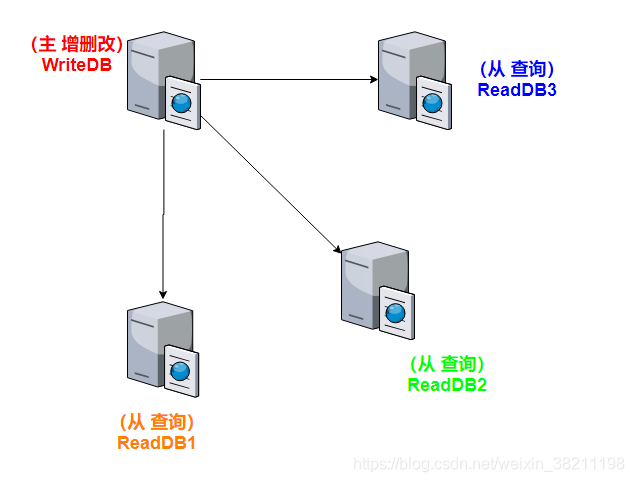
为什么一个主库多个从库?
一般查询多于增删改,这就是我们常说的二八原则,20%操作是增删改,80%操作是查询
是否有缺点?
有延迟
如何解决延迟问题?
比较及时性的数据还是通过主库查询
具体如何实现?
通过发布服务器,主库发布,而从库订阅,从而实现主从库
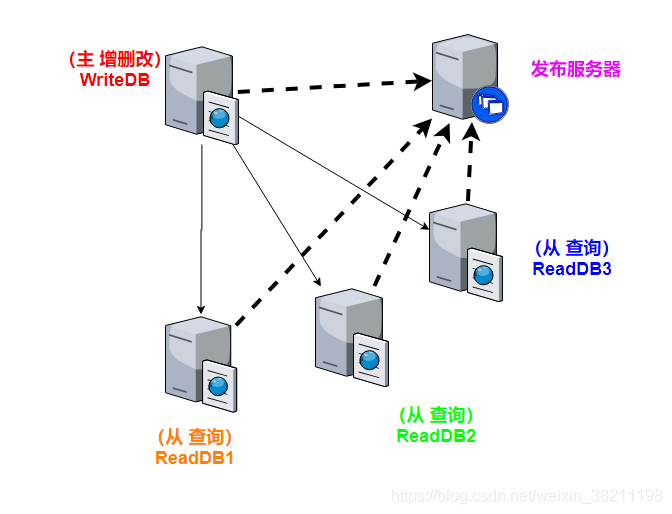
实现
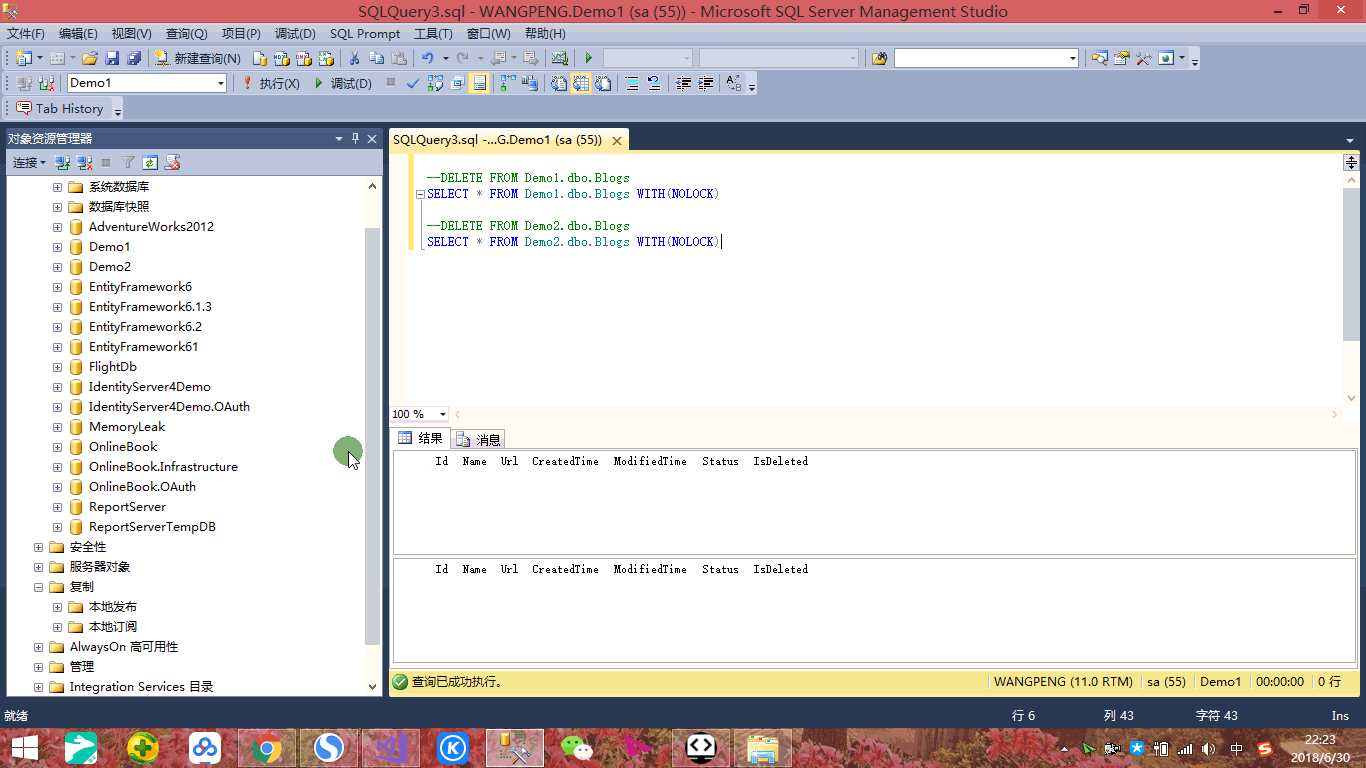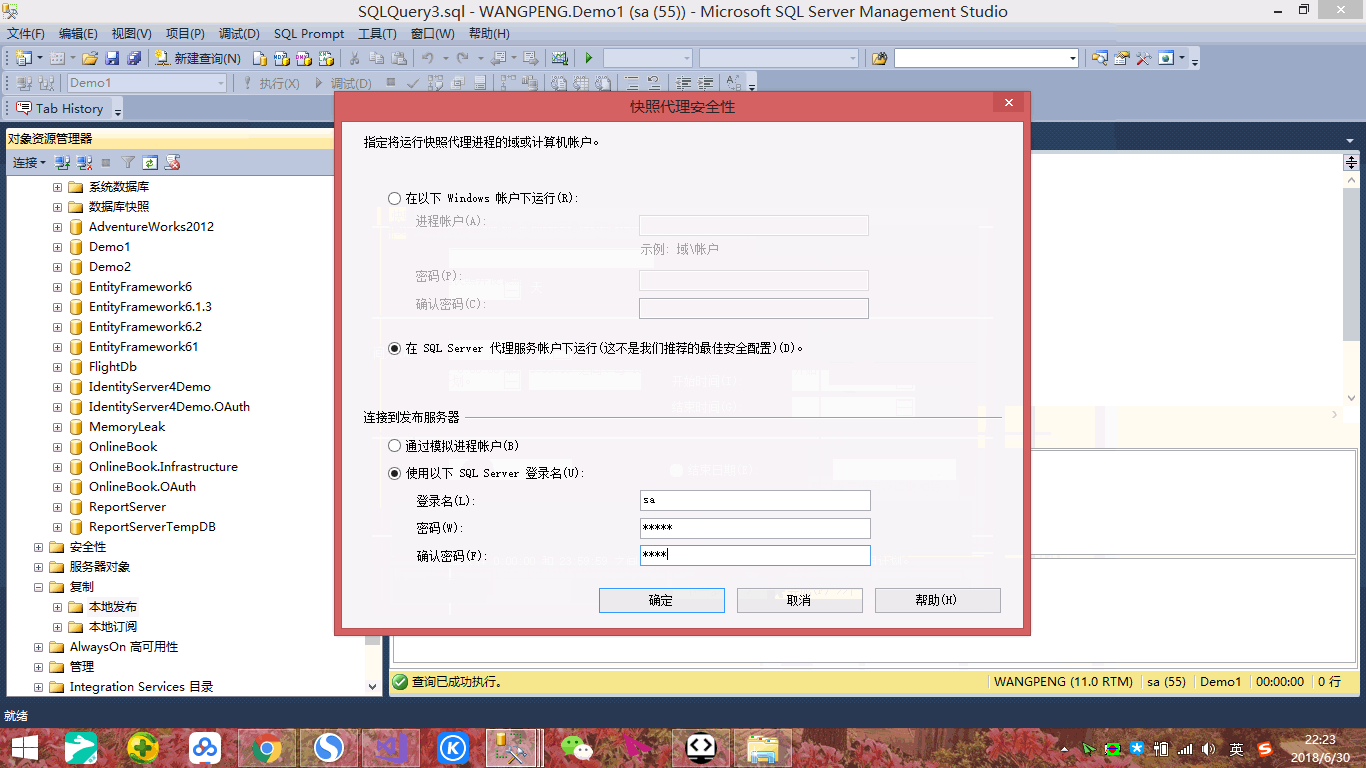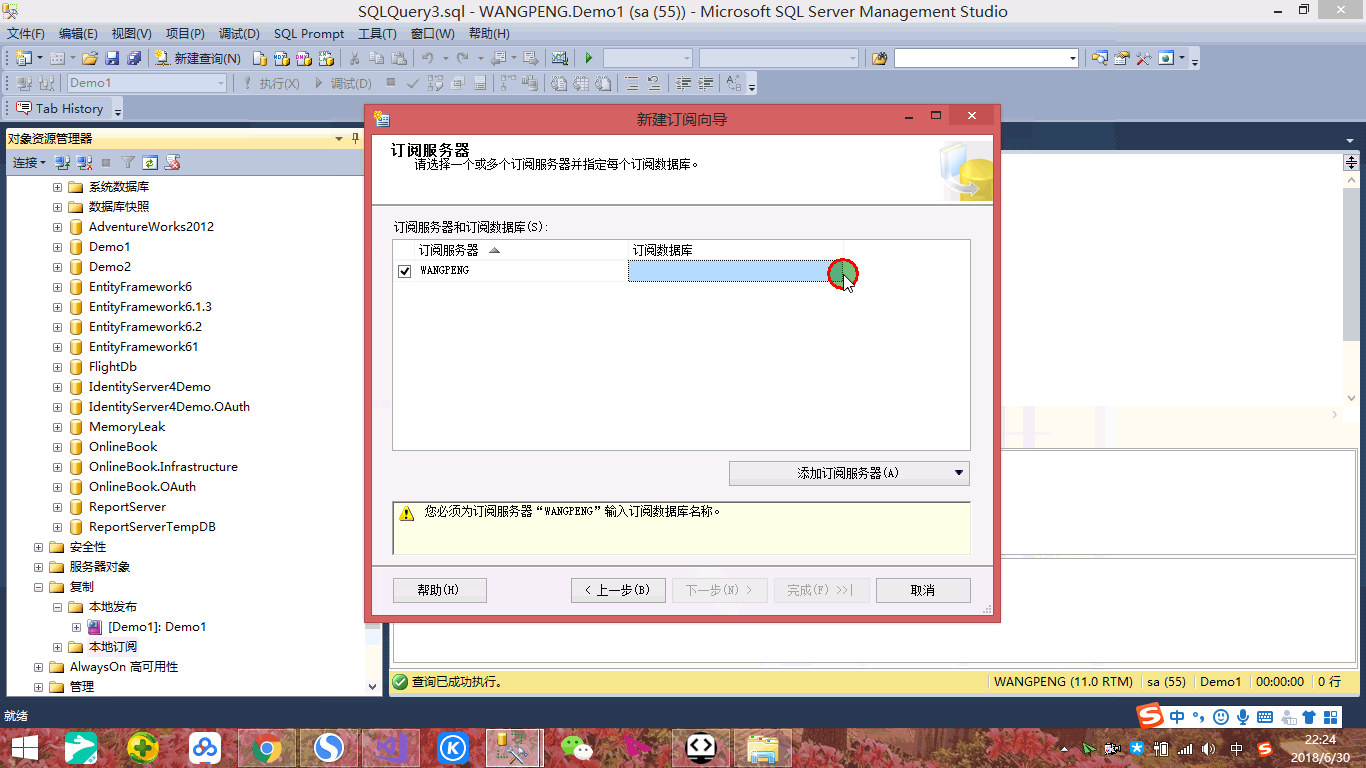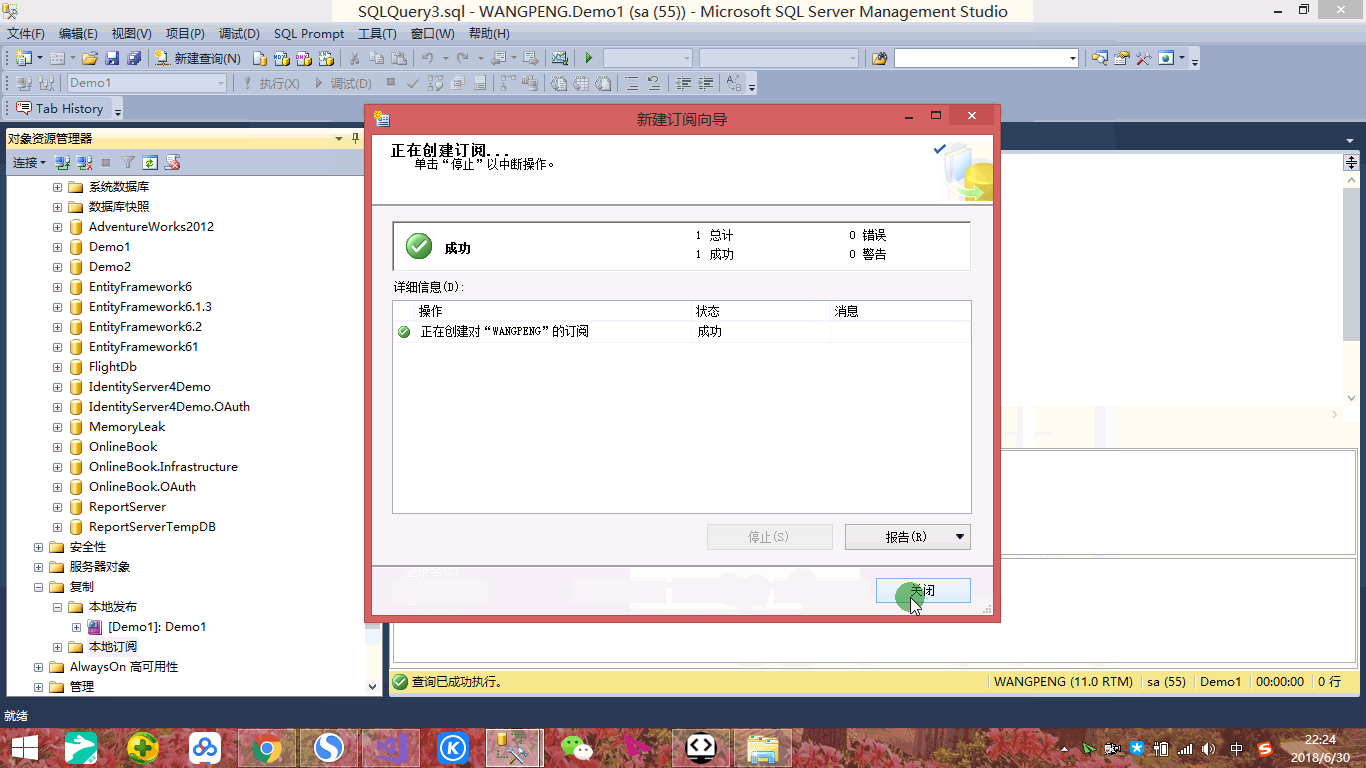
我们创建了两个Demo数据库,如下:

我们将Demo1作为主数据库,Demo2作为从数据库,接下来用一张动态图演示创建复制发布-订阅(每隔10秒发布一次)。
我们给出Demo1上下文,Demo2和其一样,按照正常做法接下来我们应该在.NET Core Web应用程序中注入Demo1和Demo2上下文,如下:
public class Demo1DbContext : DbContext
{
public Demo1DbContext(DbContextOptions<Demo1DbContext> options) :base(options)
{
}
public DbSet<Blog> Blogs {
get; set; }
}
public class Demo2DbContext : DbContext
{
public Demo2DbContext(DbContextOptions<Demo2DbContext> options) :base(options)
{
}
public DbSet<Blog> Blogs {
get; set; }
}
services.AddDbContext<Demo1DbContext>(options =>
{
options.UseSqlServer("data source=WANGPENG;User Id=sa;Pwd=sa123;initial catalog=Demo1;integrated security=True;");
}).AddDbContext<Demo2DbContext>(options =>
{
options.UseSqlServer("data source=WANGPENG;User Id=sa;Pwd=sa123;initial catalog=Demo2;integrated security=True;");
});
然后我们创建Demo控制器,通过Demo1上下文添加数据,Demo2上下文读取数据,如下:
[Route("[controller]")]
public class DemoController : Controller
{
private readonly Demo1DbContext _demo1DbContext;
private readonly Demo2DbContext _demo2DbContext;
public DemoController(Demo1DbContext demo1DbContext, Demo2DbContext demo2DbContext)
{
_demo1DbContext = demo1DbContext;
_demo2DbContext = demo2DbContext;
}
[HttpGet("index")]
public IActionResult Index()
{
var blogs = _demo2DbContext.Blogs.ToList();
return View(blogs);
}
[HttpGet("create")]
public IActionResult CreateDemo1Blog()
{
var blog = new Blog()
{
IsDeleted = false,
CreatedTime = DateTime.Now,
ModifiedTime = DateTime.Now,
Name = "demoBlog1",
Url = "http://www.cnblogs.com/createmyslef"
};
_demo1DbContext.Blogs.Add(blog);
_demo1DbContext.SaveChanges();
return RedirectToAction(nameof(Index));
}
}
razor页面
@{
ViewData["Title"] = "Index";
}
@model IEnumerable<EFCore.Blog>
<div class="panel panel-primary">
<div class="panel-heading panel-head">博客列表</div>
<div class="panel-body">
<table class="table" style="margin: 4px">
<tr>
<th>
@Html.DisplayNameFor(model => model.Id)
</th>
<th>
@Html.DisplayNameFor(model => model.Name)
</th>
<th>
@Html.DisplayNameFor(model => model.Url)
</th>
</tr>
@if (Model != null)
{
@foreach (var item in Model)
{
<tr>
<td>
@Html.DisplayFor(modelItem => item.Id)
</td>
<td>
@Html.DisplayFor(modelItem => item.Name)
</td>
<td>
@Html.DisplayFor(modelItem => item.Url)
</td>
</tr>
}
}
</table>
</div>
</div>
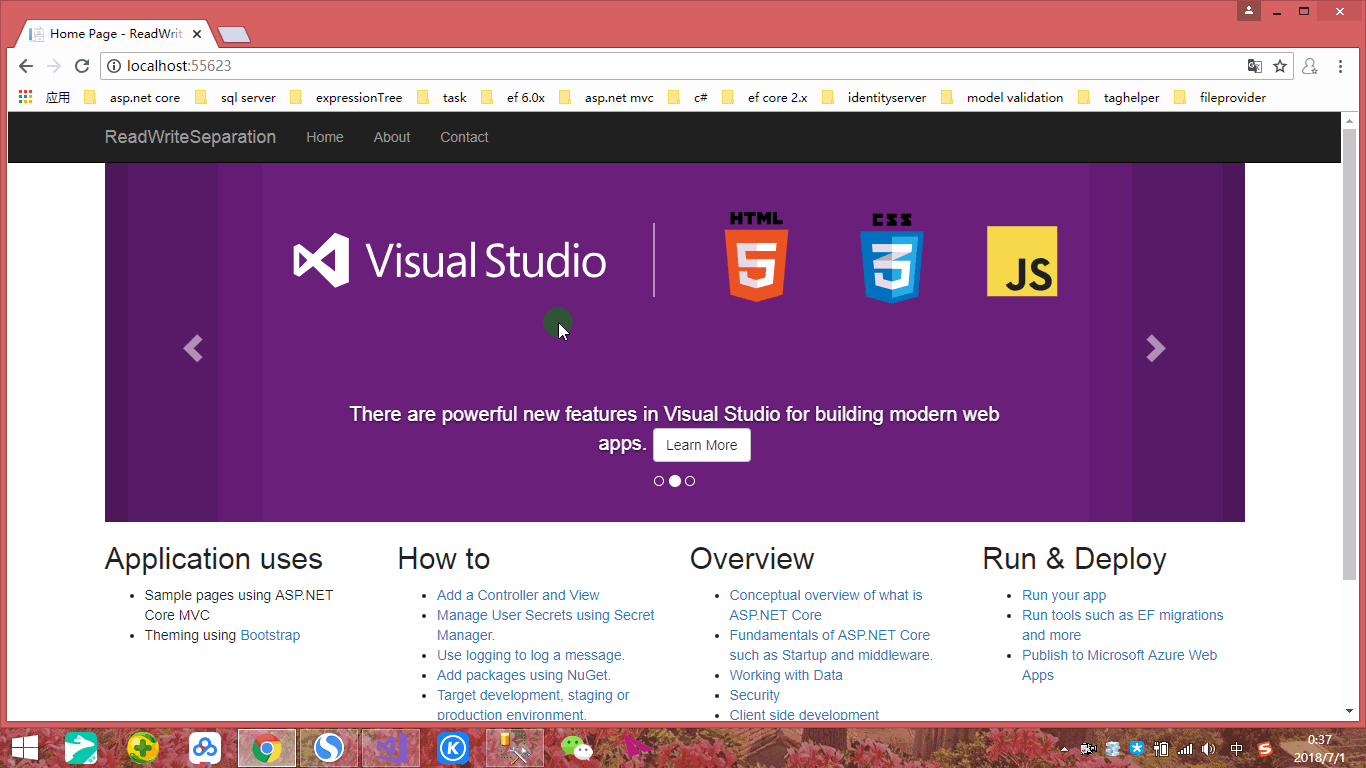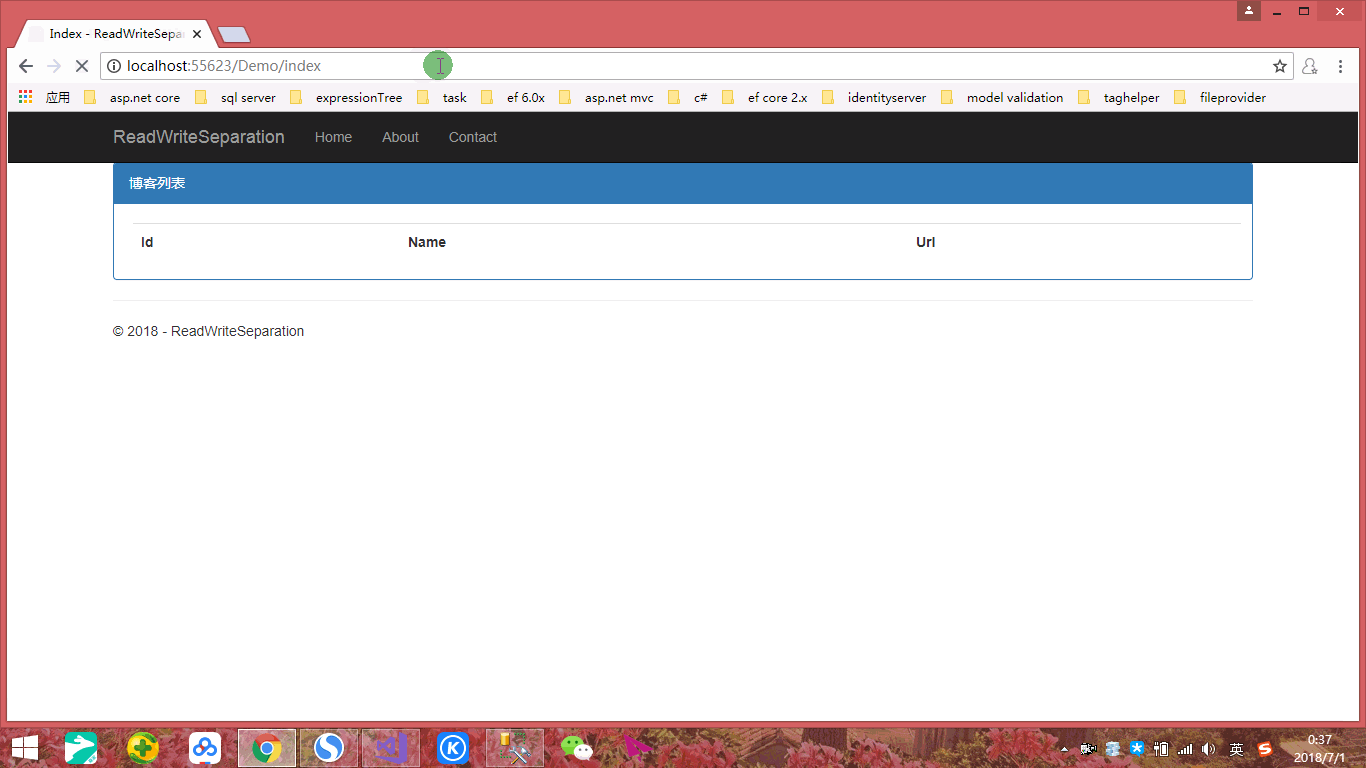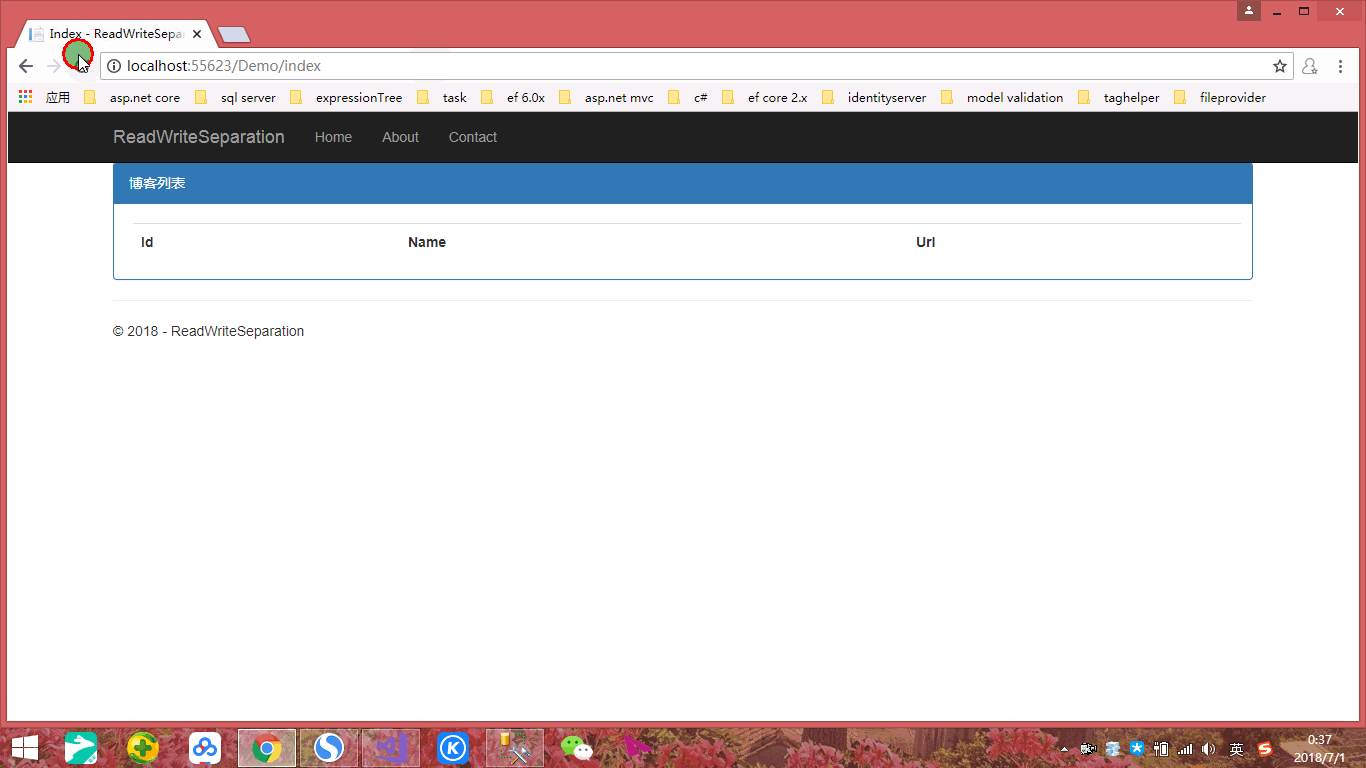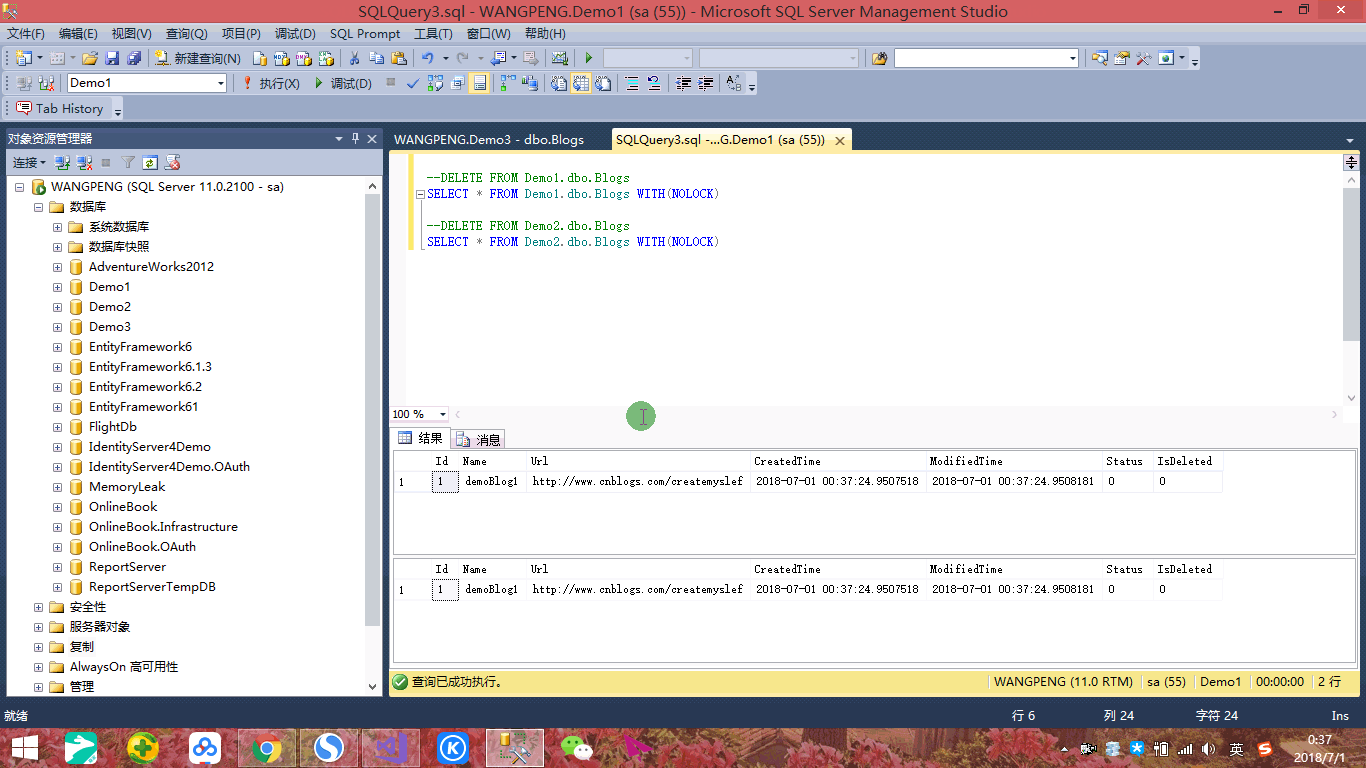
我们看到通过Demo1上下文添加数据后重定向到Demo2上下文查询到的列表页面,到了10秒自动同步到Demo2数据库,通过刷新可以看到数据显示。虽然结果如我们所期望,但是实现的路径却令我们不是那么如意,因为所用实体都是一样的,只是说所连接数据库不一样而已,但是我们需要创建两个不同的上下文实例,很显然这不是最佳实践方式,那么我们如何做才是最佳实践方式呢?接下来我们再来创建一个Demo3数据库,表结构和Demo1、Demo2一致,如下:
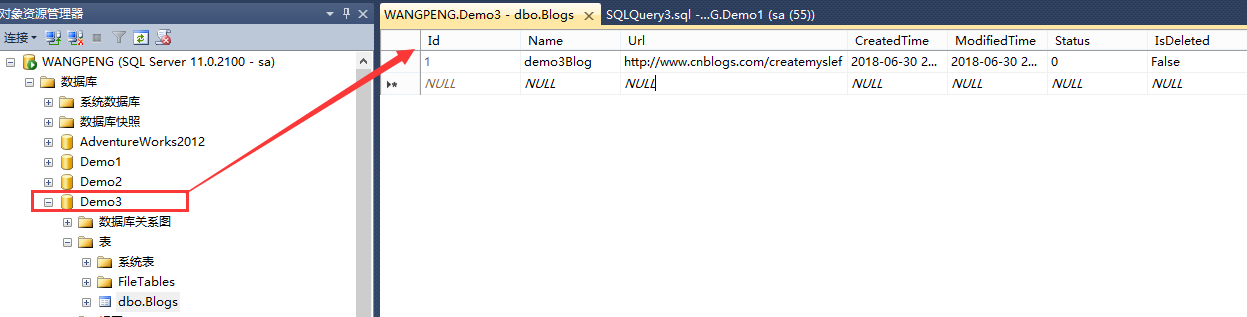
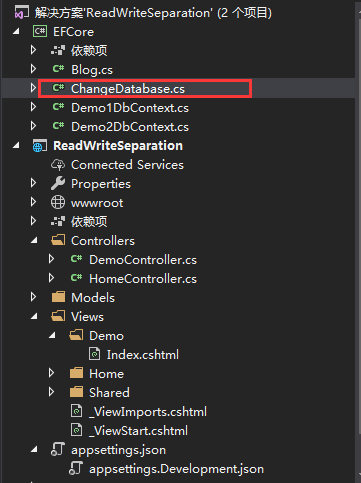
接下来我们在.NET Core Web应用程序Demo1、Demo2上下文所在的类库中创建如下扩展方法(方便有同行需要学习,给出Demo项目基本结构)。
public static class ChangeDatabase
{
public static void ChangeToDemo3Db(this DbContext context)
{
context.Database.GetDbConnection().ConnectionString = "data source=WANGPENG;User Id=sa;Pwd=sa123;initial catalog=Demo3;integrated security=True;";
}
}
我们暂且不去看为何这样设置,我们只是添加上下文扩展方法,更改连接为Demo3的数据库,然后接下来我们获取博客列表时,调用上述扩展方法,请问:是否可以获取到Demo3的数据或者说是否会抛出异常呢?我们依然通过动态图来进行演示,如下:
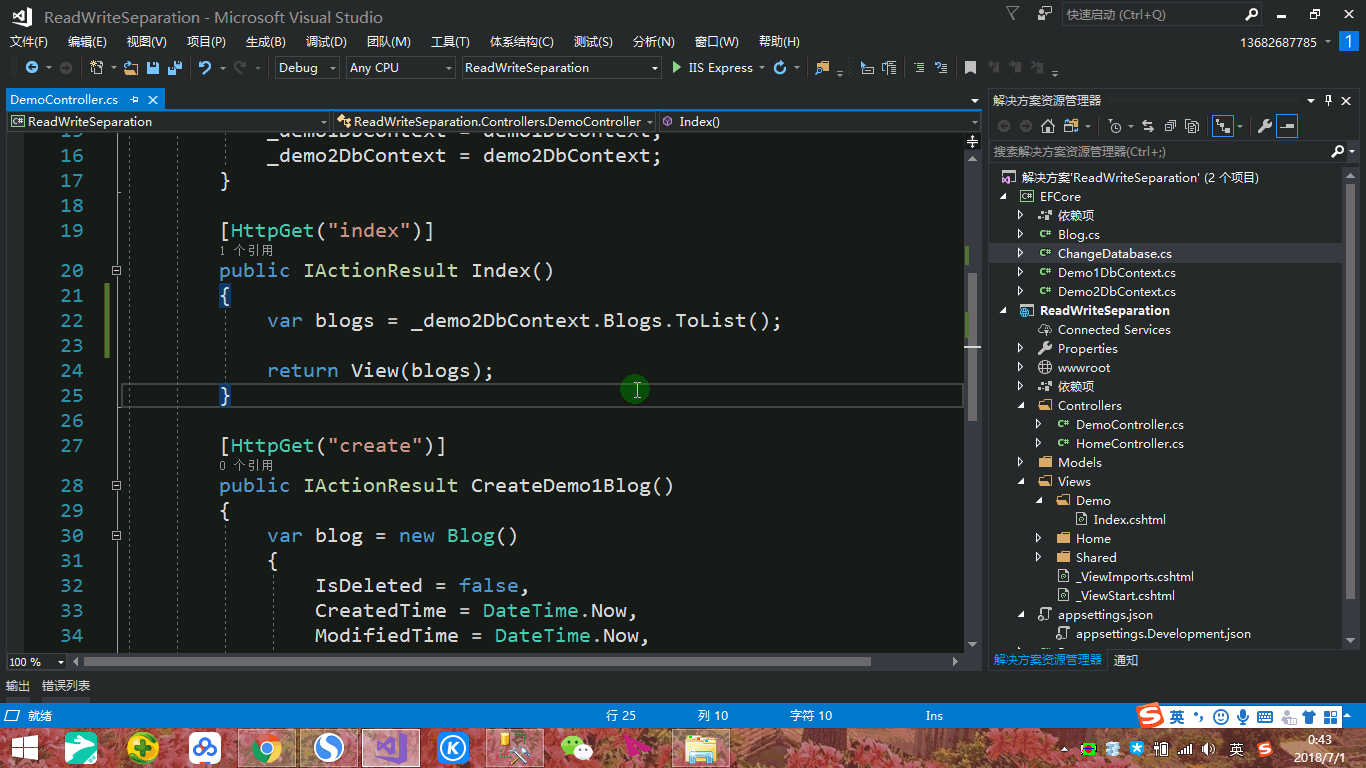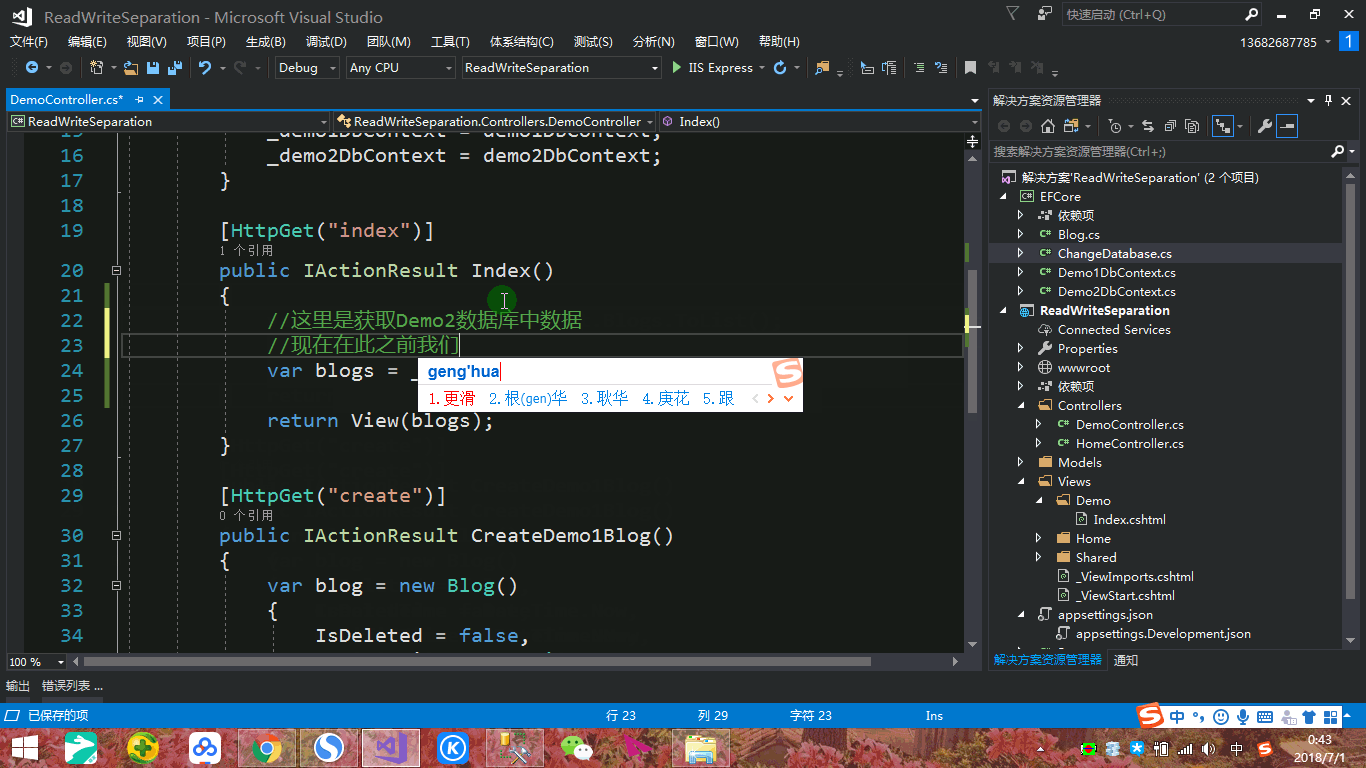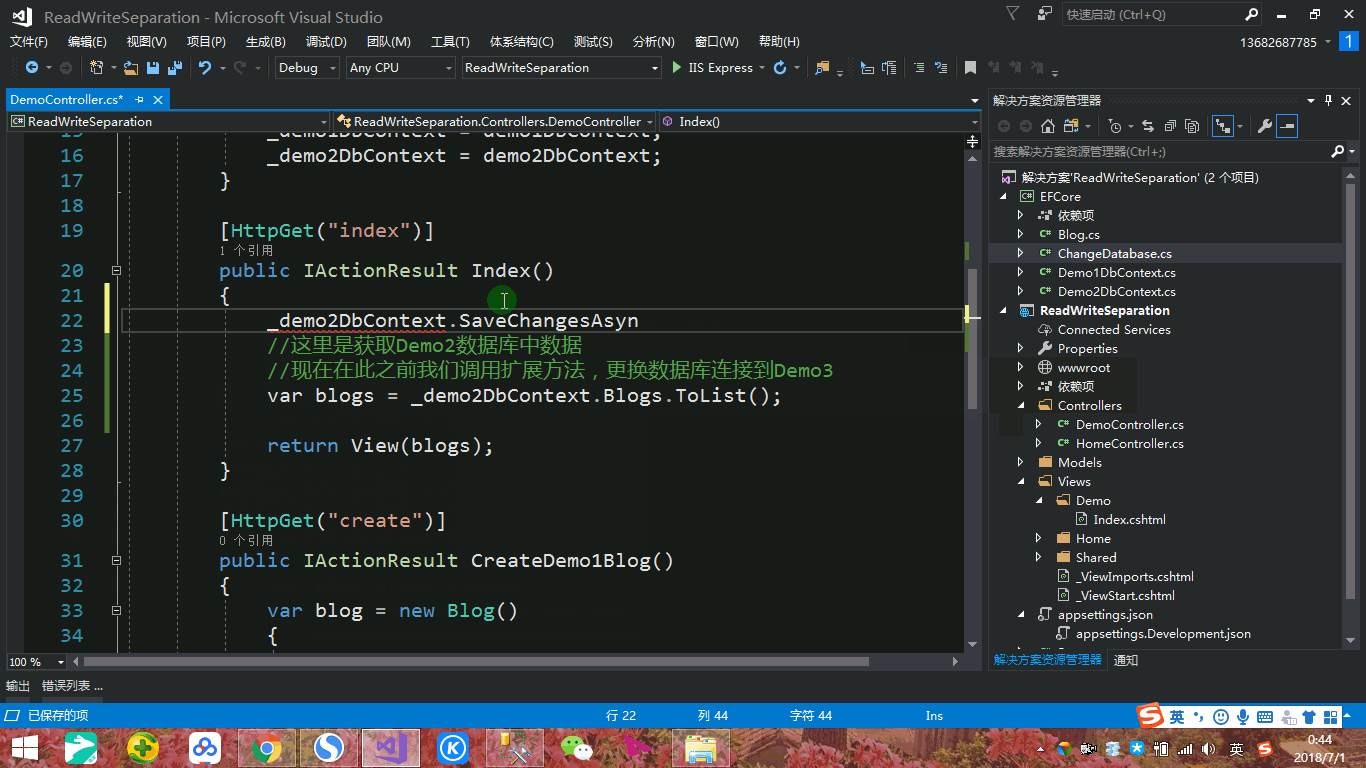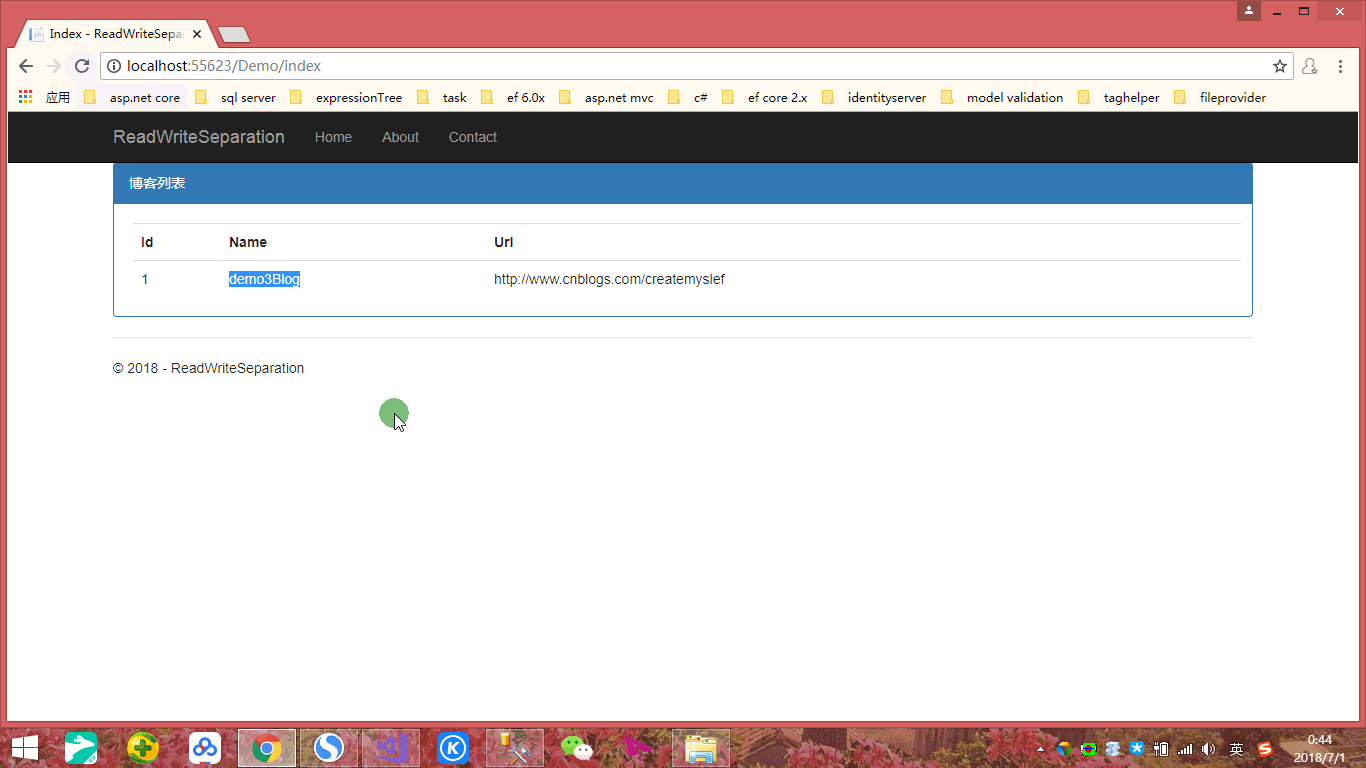
一直以来我们认为利用 context.Database.GetDbConnection() 方法可以回到ADO.NET进行查询,但是我们通过实际证明,我们可以设置其他数据库连接从而达到读写分离最佳实践方式,免去再实例化一个上下文。所以对于上述我们配置的Demo1和Demo2上下文,我们大可只需要Demo1上下文即主数据库,对于从数据库进行查询,我们只需在Demo1上下文的基础上更该连接字符串即可,如下:
public static class ChangeDatabase
{
public static void ChangeToDemo2Db(this DbContext context)
{
context.Database.GetDbConnection().ConnectionString = "data source=WANGPENG;User Id=sa;Pwd=sa123;initial catalog=Demo2;integrated security=True;";
}
}
[HttpGet("index")]
public IActionResult Index()
{
_demo1DbContext.ChangeToDemo2Db();
var blogs = _demo1DbContext.Blogs.ToList();
return View(blogs);
}
接下来问题来了,那么为何更改Demo1上下文连接字符串就能转移到其他数据库查询呢?就是为了解决读写分离免去实例化上下文即Demo2的情况,但是内部是如何实现的呢?因为EF Core内部添加了方法实现IRelationalConnection接口,使得我们可以在已存在的上下文实例上重新设置连接字符串即更换数据库,但是其前提是必须保证当前上下文连接已关闭,也就是说比如我们在同一个事务中利用当前上下文进行更改操作,然后更改连接字符串进行更改操作,最后提交事务,因为在此事务内,当前上下文连接还未关闭,所以再更改连接字符串后进行数据库更改操作,将必定会抛出异常。
读写分离与cqrs的区别
网上也没有特别准确的理解,按我目前的理解为:读写分离的主从同步依靠数据库的定时同步,有延迟。而CQRS则是事件驱动,通过监听变化,实时性较高,配合队列等也可以实现异步达到最终一致性
动静分离
什么是动静分离
动静分离是指在web服务器架构中,将静态页面与动态页面或者静态内容接口和动态内容接口分开不同系统访问的架构设计方法,进而提升整个服务访问性能和可维护性。
nginx 的动静分离,指的是由 nginx 将客户端请求进行分类转发,静态资源请求(如html、css、图片等)由静态资源服务器处理,动态资源请求(如 jsp页面、servlet程序等)由 tomcat 服务器处理,tomcat 本身是用来处理动态资源的,同时 tomcat 也能处理静态资源,但是 tomcat 本身处理静态资源的效率并不高,而且还会带来额外的资源开销。利用 nginx 实现动静分离的架构,能够让 tomcat 专注于处理动态资源,静态资源统一由静态资源服务器处理,从而提升整个服务系统的性能 。
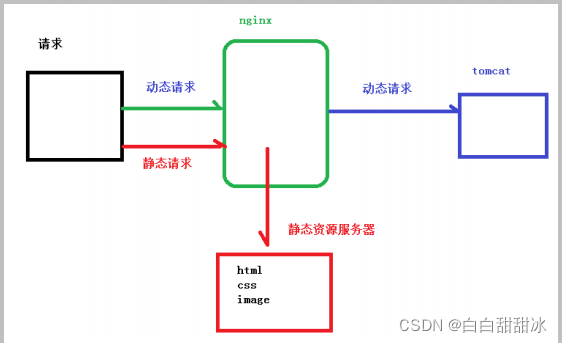
使用nginx实现动静分离
案例:
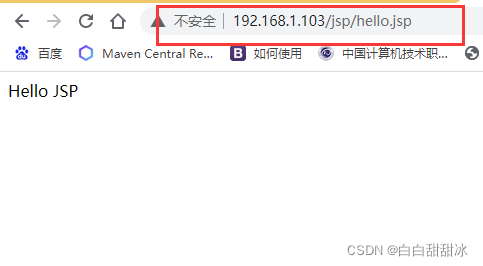
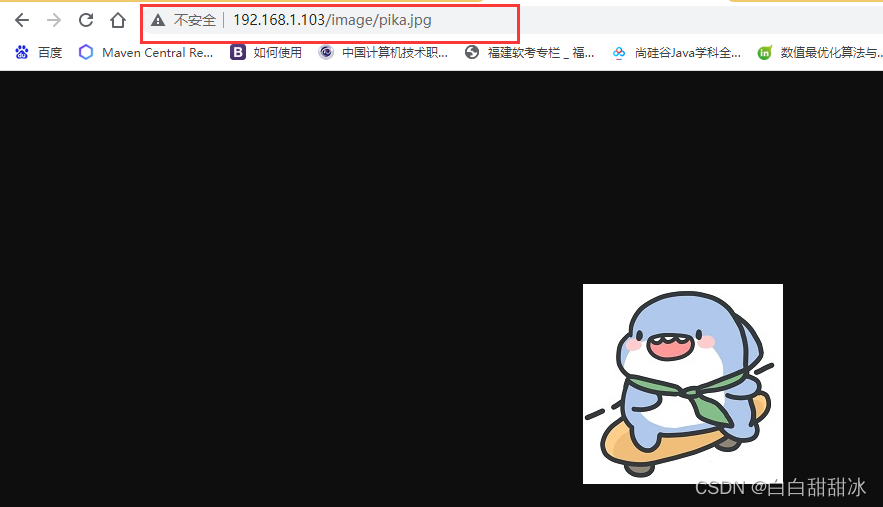
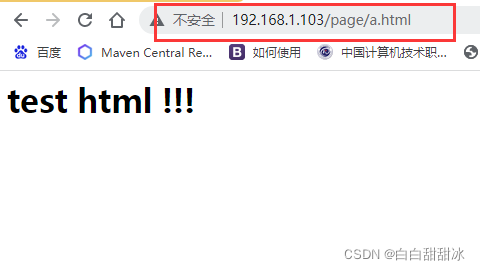
在Windows浏览器中输入 192.168.1.103/jsp/hello.jsp,跳转到提前准备好的 jsp 页面,这个动态资源请求是有tomcat服务器处理的;输入 192.168.1.103/image/pika.jpg,跳转到提前准备好的图片,这个静态资源请求是由 linux 主机处理的;输入 192.168.1.103/page/a.html,跳转到提前准备好的 html 页面,这个静态资源请求是由 linux 主机处理的。
- (1)准备工作
① 在 linux 根目录下新建 static 目录,并在此目录下分别新建 image 目录和 page 目录,在 image 目录中放入准备好的图片 pika.jpg,在 page 目录中放入准备好的页面 a.html
② 在 tomcat 下的 webapps 目录下 新建 jsp 目录,在 jsp 目录中放入提前准备好的页面 hello.jsp
③ 关闭 linux 系统的防火墙或者开放需要被访问的端口
- (2)具体配置
① 修改 linux 系统中nginx的配置文件 nginx.conf,默认在 /usr/local/nginx/conf 目录下。
将配置文件中server块的内容修改成如下形式:

② 保存修改并启动 nginx ,在Windows浏览器中输入相应请求地址,测试成功的结果如下所示:
<1> 访问 192.168.1.103/jsp/hello.jsp
<2> 访问 192.168.1.103/image/pika.jpg
<3> 访问 192.168.1.103/page/a.html
来源
【EFCore】.NET Core + EFCore 实现数据读写分离
EntityFramework Core进行读写分离最佳实践方式,了解一下(一)?
如何实现动静分离