0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文旨在通过实例掌握解深度学习模型训练中常用的对应过拟合方法——Dropout丢弃法。
我在前篇博客中介绍了L2范数正则化方法(基于PyTorch实战权重衰减——L2范数正则化方法(附代码)),这两种方法都是对应过拟合的常用方法,而且在本文中会对比这两种方法,因此建议两个方法一起学习。
在CSDN上有很多介绍Dropout方法的文章,但此类文章都没有基于整个深度学习模型对Dropout方法进行应用,仅简单介绍Dropout层的作用,也是基于此原因创作本文。
在本文最后,我也会谈谈自己对这个方法的一些理解。
1. Dropout方法原理
Dropout方法是一种用于训练深度学习网络的方法,在2012年被Hinton等人提出。
这哥们从谷歌离职后开始谈论AI的风险

这个方法在深度学习网络训练时,随机将深度学习网络中某个单元(神经元)丢弃,即将其输出置0,下图左边是全连接深度学习网络,右边是训练时采用Dropout方法的深度学习网络。
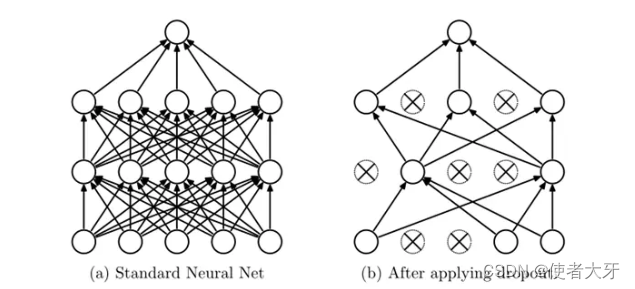
具体来说,某个单元被丢弃的概率为超参数 p p p, p p p服从伯努利分布,该单元的输出有 1 − p 1-p 1−p的概率还会除以 1 − p 1-p 1−p进行扩大,即为下式:
h n e w = ξ 1 − p h o l d h_{new} = \frac{\xi}{1-p}h_{old} hnew=1−pξhold
ξ \xi ξ有 p p p的概率为0, 1 − p 1-p 1−p的概率为1。 h n e w h_{new} hnew为该单元在Dropout后的新输出, h o l d h_{old} hold为该单元原来的输出:
h o l d = σ ( Σ x ⋅ w + b ) h_{old} = \sigma(\Sigma x·w+b) hold=σ(Σx⋅w+b)
σ \sigma σ为激活函数。
2. 基于PyTorch实现Dropout
在PyTorch中使用nn.Dropout(p)实现Dropout,其中p即为上面的被丢弃的超参数概率 p p p。
nn.Dropout(p)的本质作用是把tensor中的元素随机置0(丢弃),只要把它加在某一层后面,就可以把该层的输出进行Dropout。
但是需要注意:nn.Dropout(p)不能放在最后输出层后面!!
道理很简单,输出层的数据是要学习训练数据的,如果再随机置0反而会使loss变大。
例如下面这个模型:
class Linear(torch.nn.Module):
def __init__(self, p):
super().__init__()
self.layers = torch.nn.Sequential(
torch.nn.Linear(in_features=1, out_features=3),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=a),
torch.nn.Linear(in_features=3,out_features=5),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=b),
torch.nn.Linear(in_features=5, out_features=10),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=c),
torch.nn.Linear(in_features=10,out_features=5),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=d),
torch.nn.Linear(in_features=5, out_features=1),
torch.nn.ReLU()
)
这里不仅可以控制某一层输出是否采用Dropout,而且每层的Dropout概率也可以设定为不同值。
这里不禁吐槽下有文章说明nn.Dropout()具备两个用法,用法一:防止过拟合,用法二:将tensor元素随机置0——正是“用法二”的功能决定了“用法一”的效果!
在此,再次强调Dropout仅能用于训练深度学习网络,在测试输出时需要取消Dropout,即 p = 0 p=0 p=0。在实际编码时需要注意!
3. 验证Dropout方法的实例说明
这里采用与上篇介绍L2范数法文章(基于PyTorch实战权重衰减——L2范数正则化方法(附代码))一样的实例说明。
-
输入训练数据为x_train = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],输出训练数据为y_train = [0.52, 8.54, 6.94, 20.76, 32.17, 30.65, 40.46, 80.12, 75.12, 98.83]。这个数据集是由 y = x 2 y = x^2 y=x2函数增加一个噪声数据生成得出,可以理解为 y = x 2 y = x^2 y=x2为该实例的真实解析解(真实规律)。
-
网络模型:使用
torch.nn.Sequential()构建6层全连接层网络,每层神经元个数为:
InputLayer = 1,HiddenLayer1 = 3,HiddenLayer2 = 5,HiddenLayer3 = 10,HiddenLayer4 = 5,OutputLayer = 1。丢弃层设置在HiddenLayer2和HiddenLayer3后,p = 0.4 。 -
损失函数:MSE均方差损失函数。
-
训练参数:优化函数选用
torch.optim.Adam(),学习速率lr=0.005,训练次数epoch=3000。
4. 模型预测输出结果
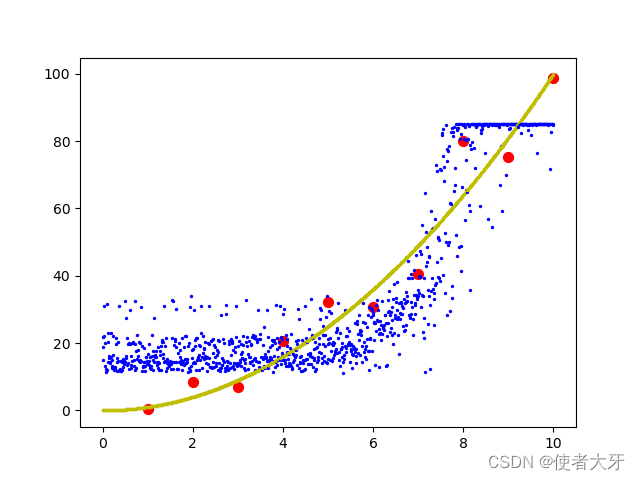
其中横坐标为输入 x x x,纵坐标为输出 y y y,红点为训练数据;黄色线为解析解,即 y = x 2 y=x^2 y=x2;蓝色线为训练后的模型在 x = [ 0 , 10 ] x=[0, 10] x=[0,10]上的预测结果。
可见,使用Dropout后,其输出结果呈现明显的离散性。
损失值loss随迭代次数epoch变化如下图:
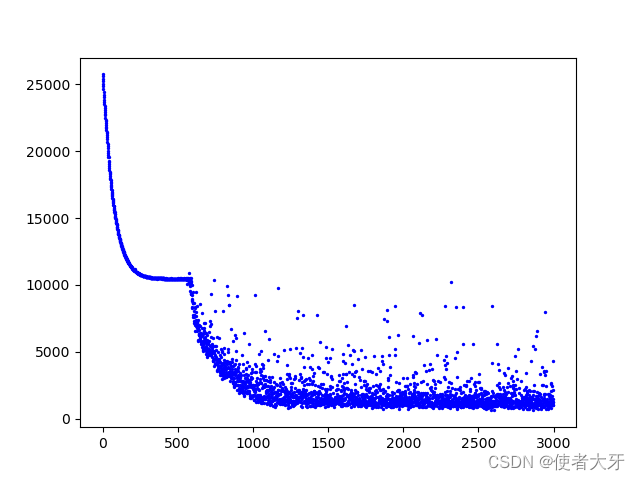
其中横坐标为迭代次数epoch,纵坐标为损失值loss。可见,loss也是离散的。
无论是预测输出的离散还是loss的离散,这两者应该都是由随机丢弃Dropout导致的。
5. 谈谈我的理解
在写完本篇博客和前一篇介绍L2范数法博客后,不禁有一个灵魂拷问:
为什么L2范数法和Dropout法可以用作正则化?
我的理解是这两种方法都是能通过人为施加外部干涉来提高深度学习模型的鲁棒性,L2范数法是通过增加权重的L2范数“惩罚项”来削弱神经元之间的联系;而Dropout方法更加“极端”,直接抛弃一部分神经元。模型在此干扰下进行学习,能够提高其输出稳定性,进而抑制过拟合。
但是单从本文的Dropout方法输出来看,其结果还是离散的比较严重的,这个结果可能是由于超参数没调好导致。读者可以咨询尝试在不同层设置不同的Dropout概率来获得更好的结果。
6. 源码
import torch
import matplotlib.pyplot as plt
torch.manual_seed(4) #3
x_train = torch.tensor([1,2,3,4,5,6,7,8,9,10],dtype=torch.float32).unsqueeze(-1)
y_train = torch.tensor([0.52,8.54,6.94,20.76,32.17,30.65,40.46,80.12,75.12,98.83],dtype=torch.float32).unsqueeze(-1)
plt.scatter(x_train.detach().numpy(),y_train.detach().numpy(),marker='o',s=50,c='r')
class Linear(torch.nn.Module):
def __init__(self, p):
super().__init__()
self.p = p
self.layers = torch.nn.Sequential(
torch.nn.Linear(in_features=1, out_features=3),
torch.nn.Sigmoid(),
# torch.nn.Dropout(p=self.p),
torch.nn.Linear(in_features=3,out_features=5),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=self.p),
torch.nn.Linear(in_features=5, out_features=10),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=self.p),
torch.nn.Linear(in_features=10,out_features=5),
torch.nn.Sigmoid(),
# torch.nn.Dropout(p=self.p),
torch.nn.Linear(in_features=5, out_features=1),
torch.nn.ReLU(),
)
def forward(self,x):
return self.layers(x)
linear = Linear(p=0.4)
opt = torch.optim.Adam(linear.parameters(),lr= 0.005)
loss = torch.nn.MSELoss()
for epoch in range(3000):
l = 0
for iter in range(10):
opt.zero_grad()
output = linear(x_train[iter])
loss_dropout = loss(output, y_train[iter])
loss_dropout.backward()
l = loss_dropout.detach() + l
opt.step()
print(epoch,'loss=%s'%(l))
# plt.scatter(epoch,l,s=2,c='b')
#
# plt.show()
if __name__ == '__main__':
predict_loss = 0
linear.p = 0 #只有在训练时才会使用dropout!!!!
zeros = 0
for i in range(1000):
x = torch.tensor([i/100], dtype=torch.float32)
y_predict = linear(x)
plt.scatter(x.detach().numpy(),y_predict.detach().numpy(),s=2,c='b')
plt.scatter(i/100,i*i/10000,s=2,c='y')
predict_loss = (i*i/10000 - y_predict)**2/(y_predict)**2 + predict_loss #计算神经元网络模型输出对解析解的loss
if y_predict == 0:
zeros += 1
print(zeros)
# print(linear.state_dict())
plt.show()
# print(linear.state_dict())
print(predict_loss)
本文的主要参考文献:
[1]Aston Zhang, Mu Li. Dive into deep learning.北京:人民邮电出版社.2021-8