我目前主要的学习资源是 Scrapy 官方文档 以及 百度,个人比较喜欢去官网,虽然全英文,学习起来比起看别人的中文博客要慢很多,但是毕竟官网上给出的解决方案都是保持更新的,现在的很多博客都是一两年前的文章,随着版本跟新很多方案可能不再适用,所以我一边学习,一边更新博客,尽量语言简洁,不扯duzi,但又尽量 step by step,提高内容的实用性。
为了使用 Scrapy 框架开发,同时尽量减少学习阻碍,下面给出一份大致的 Scrapy 框架流程。
首先,查看 Spyder 上已经创建好的项目的结构。
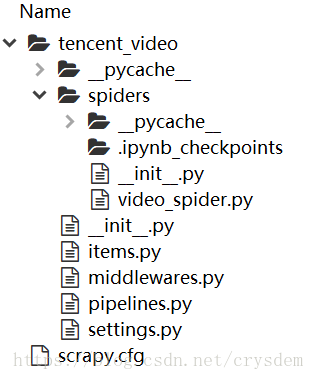
经常编辑的文件就是其中的:
- scrapy.cfg
- items.py
- piplines.py
- settings.py
- video_spider.py # 这是你用模板创建出来的爬虫文件
Scrapy 大致流程是:
- items.py 想要爬取的页面中的内容,比如对于腾讯视频,我想要爬取网页上列出的电视剧的名字和豆瓣评分
- video_spider.py 爬虫本体,执行爬取过程,在哪个网页上爬取什么内容,返回到哪里,都要自己编写
- piplines.py 处理返回结果,爬虫爬完后返回的结果如果想用 txt、excel、mysql 等格式存储,就在这里写
以上就是 Scrapy 框架的一个最简单版本的理解,其中的主要环节就是爬虫本体,它封装好了诸如 urllib 等依赖库,无需关心细节。使用 Scrapy 的感觉就像是一说到吃饭只要能够想到要用筷子(或者刀叉或者手等)把面前的米饭(面包、面条等)送进嘴里咀嚼后吞下去一样,问题就能够解决。而筷子(工具)从哪来、怎么做、好不好用等等细节无需关心,只要能够想到最外层(框架)的思路,问题就能够解决。这也就是框架的强大之处。
- 找到要爬取的内容
首先,去腾讯视频网站上查看网页结构,具体的方法非常简单,就是打开百度,搜素腾讯视频,进入官网,鼠标移动到电视剧上然后在显示出的小面板上点击全部电视剧即可。可能是因为网页进行了改版,现在想要查看所有的电视剧列表不太方便了,入口如下,在左边蓝色箭头位置。

点击最受好评后可以看到这样的页面。
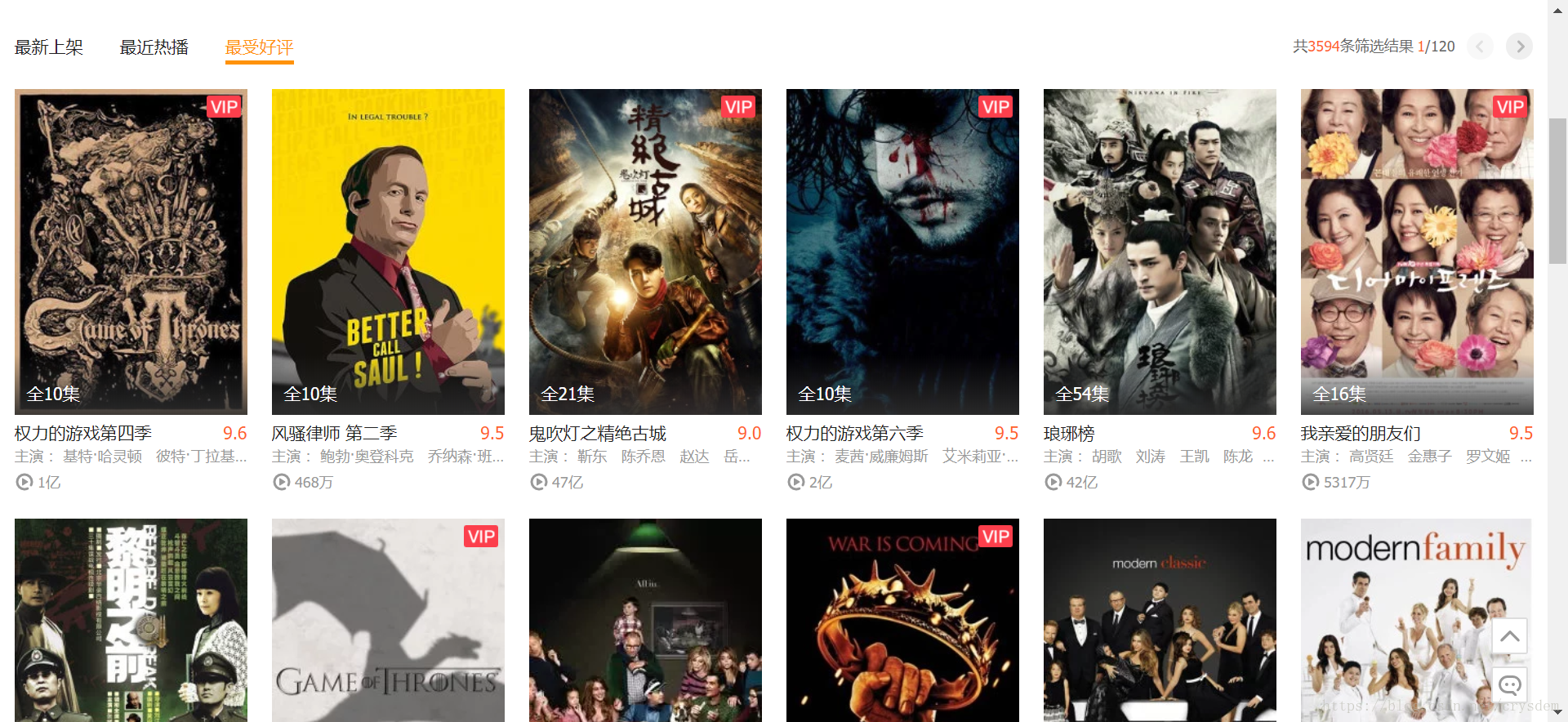
这样的页面结构比较清晰,每一页包含30个电视剧,每一个电视剧包含名称,豆瓣分数,主演,图片等等内容,而且可以想象,页面背后的源码应该也是比较规整的,不同的电视剧之间的源码结构应该都一样,注意这里我已经得到了第一个关键数据,就是这个页面的 url,https://v.qq.com/x/list/tv?offset=0&sort=16。使用右键查看源码,可以看到 html 源码非常多而且看起来比较杂乱,不过没关系, ctrl + F 搜索“权力的游戏第四季”,可以发现匹配的地方只有三处:

其中前两个字符串都是在标签内部作为属性值,之所以是中文属性值,可能是考虑到了 SEO,也就是搜索引擎优化。比如在百度上直接搜索“权力的游戏第四季”,腾讯视频是排在第一位的。
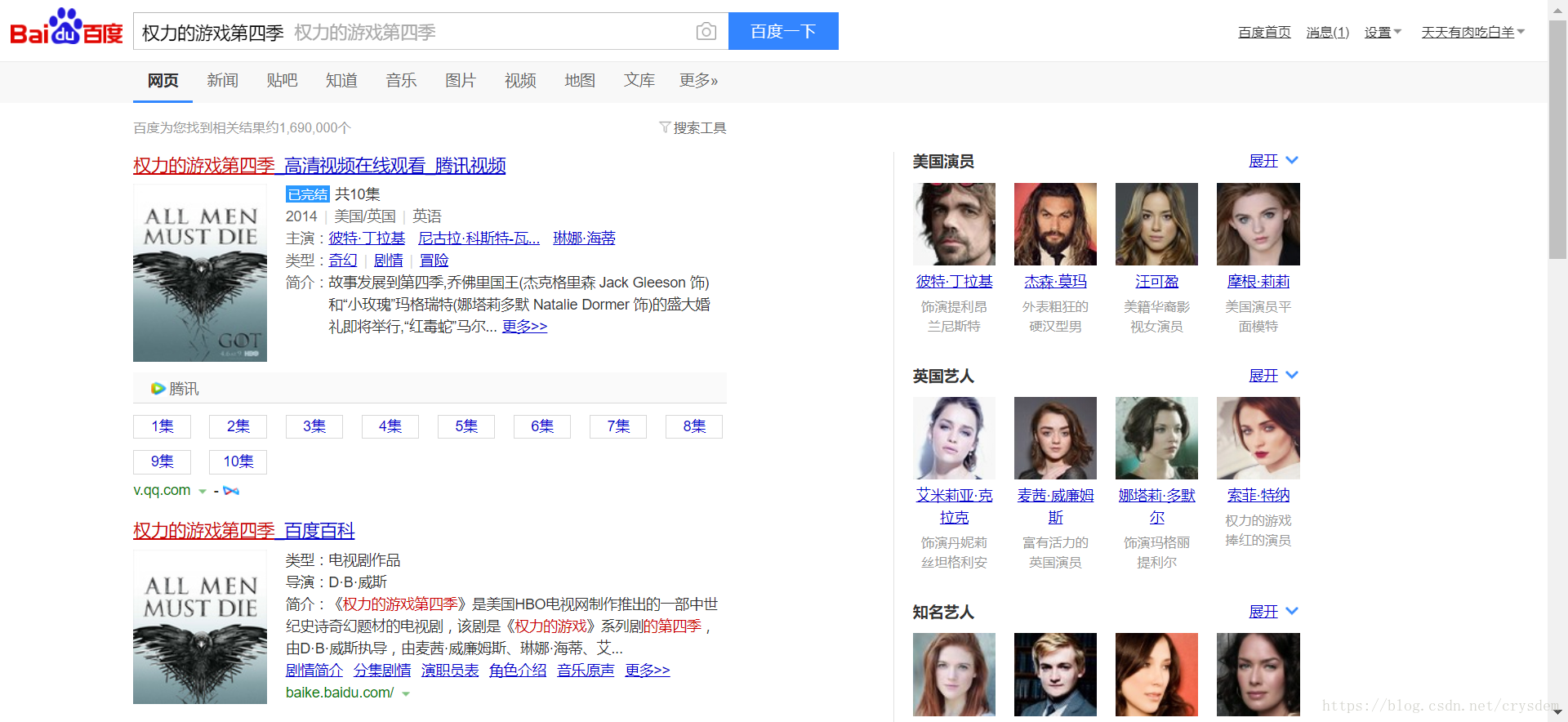
好了,直接看第三个字符串的位置,为了方便查看源码,我把关键部分打印在下面,同时对齐了下格式:
- <div class="figure_title_score">
- <strong class="figure_title">
- <a href="https://v.qq.com/x/cover/6rk0jemko5uecjh.html" target="_blank" title="权力的游戏第四季" _stat2="videos:title">权力的游戏第四季</a>
- </strong>
- <div class="figure_score">
- <em class="score_l">9</em>
- <em class="score_s">.6</em>
- </div>
- </div>
- <div class="figure_title_score">
下面。而且通过搜索其他电视剧名称,发现他们的结构确实都是和上面一样的。现在,我把自己想象成电脑,用程序的思路,去精确匹配到这两个值。
- 首先,我要寻找一个 class 属性为 figure_title_score 的 div 标签,但是找到第一个匹配的标签后我不会善罢甘休,继续寻找匹配的标签直到我遍历完整个 html 文件,结束后,我得到了 30 个结构相同的 div 标签
- 第一个 div 标签内,我要寻找 strong 标签,遍历整个标签,我只发现了一个匹配的 strong 标签
- 在这个 strong 标签内,我要寻找 a 标签,我只找到一个,标签内容是“权力的游戏第四季”
- 退出 strong 标签,找到与之同级的 div 标签,只有一个
- 进入这个 div 标签,寻找 class 属性为 score_l 的 em 标签,只有一个,内容是 9,然后寻找 class 属性为 score_s 的 em 标签,只有一个,内容是 .6
- 第一个标签搜索完毕,进入下一个 div 标签
- 重复。。。
好了,网页源码分析到这里可以告一段落,因为我只想要这一个页面的信息,其他页面不用再分析。
到这里,爬虫的主体思路已经有了,爬虫的设计文档可以说也已经写出来了,现在是实现文档。
- 制造爬虫
根据 Scrapy 框架的思路,首先我要在 items.py 中写入我想要爬取的内容,在这里其实就是电视剧标题和豆瓣分数,给他们分别取个易读的名字,不妨称为 video_name 和 douban_score。源码如下:
- # -*- coding: utf-8 -*-
- # Define here the models for your scraped items
- #
- # See documentation in:
- # https://doc.scrapy.org/en/latest/topics/items.html
- import scrapy
- class TencentVideoItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- video_name = scrapy.Field()
- douban_score = scrapy.Field()
- # pass
然后,进入 video_spider.py 中,编写我的爬虫。这个文件是通过 scrapy genspider video_spider v.qq.com 命令自动创建的。里面的代码可以说是模板,只需要修改关键部分即可,有点像是做填空,或者像是填表格。
- # -*- coding: utf-8 -*-
- import scrapy
- from tencent_video.items import TencentVideoItem # 导入 items.py 中的 TencentVideoItem
- '''''
- 爬取腾讯视频网站上的最受好评的电视剧,
- 网址:http://v.qq.com/x/list/tv?offset=0&sort=16,
- 爬取的内容包括电视剧名字, 豆瓣评分
- '''
- class VideoSpiderSpider(scrapy.Spider):
- name = 'video_spider'
- allowed_domains = ['v.qq.com'] # 爬虫只能在这个域内爬行
- start_urls = ['http://v.qq.com/x/list/tv?offset=0&sort=16'] # 目前只爬行一页
- # 解析爬取的 html 内容
- def parse(self, response):
- subselect = response.xpath('//div[@class="figure_title_score"]') # 嵌套匹配
- items = []
- for sub in subselect:
- item = TencentVideoItem() # 结构化 item
- item['video_name'] = sub.xpath('./strong/a/text()').extract()[0] # 返回的是 list 所以 [0] 表示获取列表中的第一个元素,也就是字符串
- item['douban_score'] = sub.xpath('./div/em[@class="score_l"]/text()').extract()[0] + \
- sub.xpath('./div/em[@class="score_s"]/text()').extract()[0]
- items.append(item) # 存入 list
- return items
数据已经有了,为了初步验证程序没有什么语法错误等,可以使用 scrapy shell 命令进行初步的测试,在 prompt 中输入:
- scrapy shell "http://v.qq.com/x/list/tv?offset=0&sort=16"
- &sort=16
打印结果如下:
- >scrapy shell "http://v.qq.com/x/list/tv?offset=0&sort=16"
- 2018-04-28 21:14:07 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: tencent_video)
- 2018-04-28 21:14:07 [scrapy.utils.log] INFO: Versions: lxml 4.1.0.0, libxml2 2.9.4, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 17.5.0, Python 3.6.3 |Anaconda custom (64-bit)| (default, Oct 15 2017, 03:27:45) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 17.2.0 (OpenSSL 1.0.2o 27 Mar 2018), cryptography 2.0.3, Platform Windows-10-10.0.15063-SP0
- 2018-04-28 21:14:07 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tencent_video', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'tencent_video.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tencent_video.spiders']}
- 2018-04-28 21:14:07 [scrapy.middleware] INFO: Enabled extensions:
- ['scrapy.extensions.corestats.CoreStats',
- 'scrapy.extensions.telnet.TelnetConsole']
- 2018-04-28 21:14:07 [scrapy.middleware] INFO: Enabled downloader middlewares:
- ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
- 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
- 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
- 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
- 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
- 'scrapy.downloadermiddlewares.retry.RetryMiddleware',
- 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
- 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
- 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
- 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
- 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
- 'scrapy.downloadermiddlewares.stats.DownloaderStats']
- 2018-04-28 21:14:07 [scrapy.middleware] INFO: Enabled spider middlewares:
- ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
- 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
- 'scrapy.spidermiddlewares.referer.RefererMiddleware',
- 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
- 'scrapy.spidermiddlewares.depth.DepthMiddleware']
- 2018-04-28 21:14:07 [scrapy.middleware] INFO: Enabled item pipelines:
- []
- 2018-04-28 21:14:07 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
- 2018-04-28 21:14:07 [scrapy.core.engine] INFO: Spider opened
- 2018-04-28 21:14:07 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://v.qq.com/robots.txt> (referer: None)
- 2018-04-28 21:14:08 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://v.qq.com/x/list/tv?offset=0&sort=16> (referer: None)
- 2018-04-28 21:14:09 [traitlets] DEBUG: Using default logger
- 2018-04-28 21:14:09 [traitlets] DEBUG: Using default logger
- [s] Available Scrapy objects:
- [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
- [s] crawler <scrapy.crawler.Crawler object at 0x00000157C6E7BB70>
- [s] item {}
- [s] request <GET http://v.qq.com/x/list/tv?offset=0&sort=16>
- [s] response <200 http://v.qq.com/x/list/tv?offset=0&sort=16> # 这里说明 http 请求成功
- [s] settings <scrapy.settings.Settings object at 0x00000157C97C8C18>
- [s] spider <VideoSpiderSpider 'video_spider' at 0x157c9a55b70>
- [s] Useful shortcuts:
- [s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
- [s] fetch(req) Fetch a scrapy.Request and update local objects
- [s] shelp() Shell help (print this help)
- [s] view(response) View response in a browser
- >In [1]:
- In [5]: response.xpath('//div[@class="figure_title_score"]/strong/a/text()').extract()
- Out[5]:
- ['权力的游戏第四季',
- '风骚律师 第二季',
- '鬼吹灯之精绝古城',
- '权力的游戏第六季',
- '琅琊榜',
- '我亲爱的朋友们',
- '黎明之前',
- '权力的游戏第三季',
- '摩登家庭第六季',
- '权力的游戏第二季',
- '摩登家庭第五季',
- '摩登家庭第四季',
- '摩登家庭第三季',
- '摩登家庭第二季',
- '小戏骨水浒传',
- '小戏骨红楼梦刘姥姥进大观园',
- '权力的游戏第七季',
- '信号 Signal',
- '权力的游戏第一季',
- '权力的游戏第五季',
- '战长沙',
- '父母爱情',
- '毛骗 第2季',
- '茶馆',
- '情满四合院',
- '一起同过窗',
- '真探第一季',
- '硅谷第二季',
- '风骚律师 第一季',
- '摩登家庭 第7季']
- In [6]:
我这里稍微变了一下 xpath 语句,打印出这一页所有的电视剧名字,注意 xpath().extract() 方法返回结果是一个 list.
这说明程序应该没有问题,接下来保存数据。
- 保存数据
在保存数据前,需要设置 settings.py 指定数据处理者
- # 找到下面一段代码,并取消注释
- # Configure item pipelines
- # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
- ITEM_PIPELINES = {
- 'tencent_video.pipelines.TencentVideoPipeline': 300,
- }
然后编写 piplines.py,这里我用 csv 格式保存数据
- # -*- coding: utf-8 -*-
- # Define your item pipelines here
- #
- # Don't forget to add your pipeline to the ITEM_PIPELINES setting
- # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
- import csv
- class TencentVideoPipeline(object):
- def __init__(self):
- with open("tencent-video.csv", "a", newline='') as csvfile:
- writer = csv.writer(csvfile)
- writer.writerow(["电视剧", "豆瓣评分"])
- def process_item(self, item, spider):
- video_name = item['video_name']
- douban_score = item['douban_score']
- with open("tencent-video.csv", "a", newline='') as csvfile:
- writer = csv.writer(csvfile)
- writer.writerow([video_name, douban_score])
- return item
上面添加了类的解析函数,以便只生成一次表头,process_item 在这里会被循环调用 30 次。