
“2011年, A16Z 创始合伙人 Marc Andreesse 提出'Software is eating the world',在我们步入 AI新时代的节点,或许我们可以说, AI is eating the world。”
在火山引擎和锦秋基金联合主办的「2023 AI逐梦者计划」活动中,锦秋基金执行董事臧天宇表示。
在AI发展的历史长河中,深度学习的出现推动了AI第一波大规模应用,AI四小龙的出现,人脸识别的应用落地,吸引了众多人的目光,但行业巨变并未如期而至,AI技术商业落地的表现不尽如人意,拿着锤子找钉子成为AI创业公司普遍面临的难题,行业开始进入冷静期。
随着ChatGPT为代表的AIGC的流行,大模型逐渐走向成熟,其所表现的推理、理解、创造力已经具备了成为人类助手的潜力,而随着数据的不断积累,其所形成的飞轮效应,将使基座模型走向通用AGI,同时基于大模型的应用将变得越来越智能,未来你的工作日程安排、一日三餐、财务税务申报、小孩教育或许都可以由人工智能帮你自动规划。
不过在锦秋基金看来,技术从来不是只可远观的黑科技和“酷炫”的代名词,只有真实解决行业需求和痛点的先进技术,才能真正为行业和社会创造价值。
实际上,锦秋基金的创始团队早在2019年就开始了在AI领域的系统布局,在长坡厚雪的AI赛道上滚起了雪球。
围绕AI相关垂直行业的应用机会,此前团队曾参与投资了零犀科技,基于AI和BPO的结合,零犀科技帮助企业解决营销获客效率的问题。此后沿着AI+垂直行业的脉络,投资团队在AI+工业、AI+农业、AI+生物制药等领域都做了布局。
通过对不同细分行业的梳理,我们敏锐地发现,在不同的行业环节,存在着人力资源瓶颈,而利用行业过去沉淀的有效数据,AI技术可以大幅提高行业生产效率。

随着对细分行业研究的深入,锦秋基金按图索骥,系统地绘制了AI+不同行业的产业版图,而随着版图的不断完善,我们也从中捕捉到了更多藏在冰山之下的机会。
在人口老龄化的背景下,劳动力短缺将不可避免,我们预测,在AI与自动驾驶、智能机器人相结合的领域,未来将有万亿级的市场成长空间,因此锦秋基金深入工业物流、自动驾驶等场景,投资了许多高成长公司。
当迈入大模型时代,锦秋基金又看好哪些方向呢?臧天宇介绍称,锦秋基金目前主要看好以多模态大模型作为认知和决策引擎,集成一系列外围模型、工具和数据,构建AI原生或AI赋能型应用的投资机会,以及大语言模型和机器人相结合的领域。
AI 1.0时代和AI 2.0时代有哪些不同?哪些因素推动了AI技术地发展?大模型时代将孕育哪些新的机会?适合AI创业者的机会有哪些?在《投资视角看大模型及其应用趋势》的演讲中,锦秋基金执行董事臧天宇分享了他对行业的看法和观点。
以下为演讲内容,有删减:
AI范式迁移:从量变到质变
锦秋基金一直以来关注AI领域相关的应用机会,在过去5、6年时间里,我们观察到一些 AI 核心要素逐渐由量变到质变,主要有三方面因素催生了这波大模型热潮。
首先是应用研究和人才的积累。过去10年AI领域的论文数量稳步增加,与此同时,相关专利数量则是呈指数型增长。学界跟业界更紧密的互动推动学术成果完成了产业化或者工程化的转化,AI研究的专利转化数量在过去五年提升了30倍,在此过程中培养了大量的专业人才,这是非常重要的积累过程。
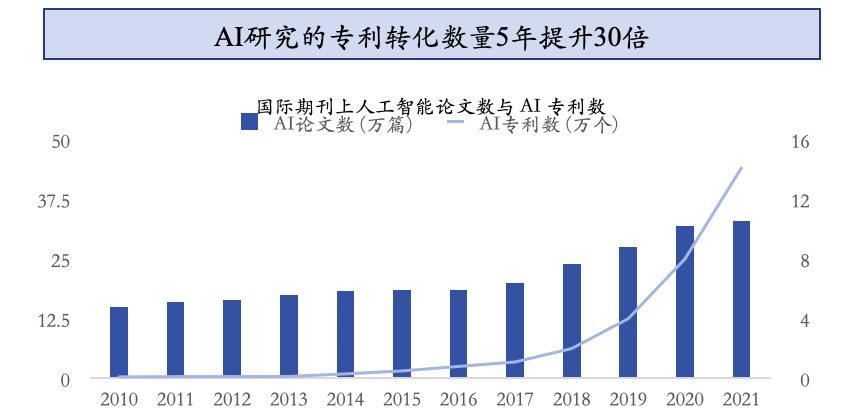
其次,硬件算力的变化。GPU单卡算力在过去十年里翻了250倍,这带来了训练、推理效率极大的提升和成本的进一步下降。
最后,基于Transformer解码器架构的大型预训练模型,在过去三年时间里,逐渐成为业界共同的探索方向。一方面,整个训练任务能够更好地做并行化;另一方面,基于自监督学习,数据可以被更好地规模化利用,使得硬件提升的潜力能够更多地释放。
以上这些要素的共同作用,推动了这一波大模型热潮的发生,而大语言模型的发展,带来了AI开发或AI应用范式的大迁移。
我们姑且把大模型之前AI发展阶段称之为AI 1.0。在过去AI 1.0阶段进行开发时,当你明确一个应用方向和目标,你可能要选择一个或者多个合适的模型架构,在特定的基于标注的训练数据集上,去搭建一套数据清洗、模型训练、模型部署再到运维等一整套相对复杂的工作流,这些工作可能是由内部的团队来做,也可能是找一些第三方集成商来完成,例如国内的商汤、海外的C3.AI。
但带来的问题是,你需要在单一的应用场景中投入数百甚至上千万的前置成本,同时可能也要投入数十人的算法和工程团队,去维护一整套的模型架构、体系,而且在不同应用之间是不可迁移的,你需要反复地去造轮子。依据商汤科技在招股书披露的数据,其一年要开发近万个AI模型来满足不同下游客户的需求。
而到了大模型驱动的 AI 2.0时代,因为有了通用基座模型,具备通过zero-shot prompting(零样本提示)或few-shot prompting(少量样本提示),去实现模型能力在不同下游任务上的迁移,可横跨多模态,具备很好的性能。
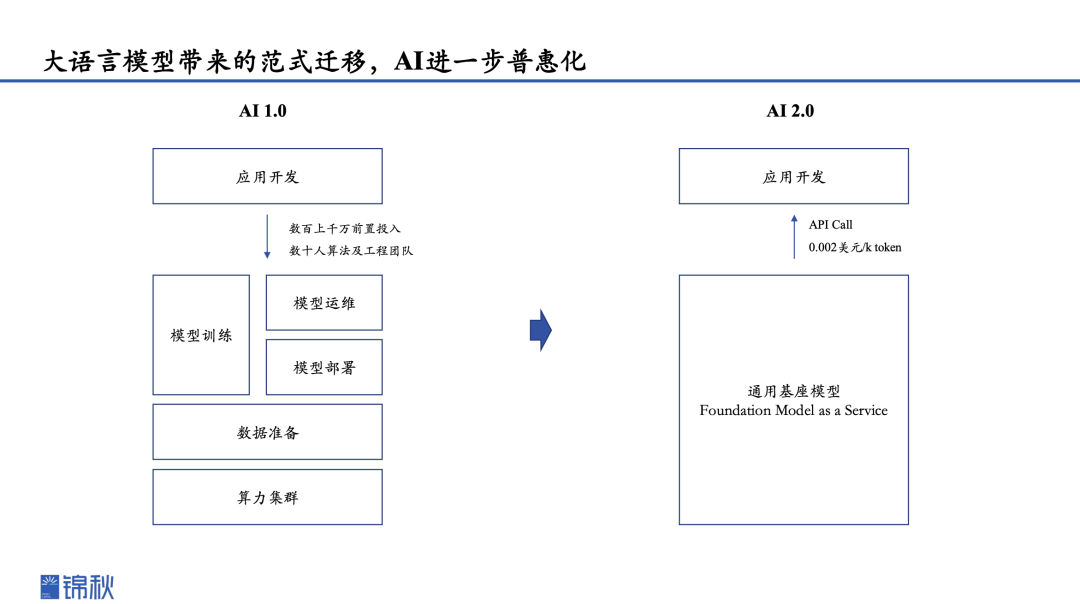
当以通用基座模型作为基础服务,在此基础上去开发应用,成本和开发难度都会降低。以OpenAI 的 GPT 3.5的 API 调用成本作为参考,低至每千个token 0.002美元。这时我们要开发一个AI应用,就不需要前置投入一大笔钱,而是变为Pay as You Go的方式。
这与软件领域类似,从本地化部署on-premise的模式逐渐迁移到SaaS。软件领域的迁移大概是从2010年开始,极大的推动了软件的普及和渗透。2011年A16Z的创始合伙人Marc Andreesse 提出“software is eating the world”,到现在这个时间点,随着AI 应用成本进一步下降以及AI进一步普惠化,我们可以说,AI is eating the world,下一个 AI 时代已经到来。
当然上面只是一个抽象的概念模型,在实际应用开发中,我们可能还需要调用多个模型,不止是通用基座模型,可能还要连接小模型或是向量数据库,实际的最后一公里成本还没有那么低,但相较于原有的开发模式,肯定是极大地节约了开发成本。
大模型时代的新机遇
对于那些通用基座模型,即具备大参数量,权重中存储了海量的常识,且有比较强的复杂推理能力的模型,锦秋基金的观点是,它肯定是少数人的游戏,主要有三方面原因。
首先,它需要非常大的前置投入。比如2.5万-3万张A100的卡,同时搭建数据管线也需要很高的成本。这种前期投入,会随着下游应用调用量的增加逐渐摊薄,所以对于头部企业来说,它会有比较明显的规模优势。
其次,来自于用户反馈的数据飞轮。无论是基于用户反馈的强化学习过程,还是指令微调的过程,这些来自于用户使用后的真实反馈,能够促进模型在应用上的性能迭代。
最后,大模型的下游,一方面是面向开发者,另一方面它又面向C端用户,能够在开发者和用户间形成双边网络。更多的开发者开发了更丰富的应用和插件,能够吸引更多用户,而由此带来的收入机会又会吸引更多的应用开发者,这样的双边网络会促进头部基座模型形成领先生态。
预计未来通用基座模型只会有3到5家主导性的模型供应商。目前来看,业界领先的基座模型有OpenAI 的GPT3.5、GPT4,谷歌的PaLM 2和ANTHROP/C 的Claude。
未来的行业格局可能会比较像云计算,3家头部厂商,各家的模型可能会略有差异化的能力侧重或价值主张,有的更强调语言类任务,有的更强调多模态。
同时我们认为,未来还会存在一个活跃的开源生态,例如围绕Meta开源的LLaMA已经诞生了一系列的羊驼家族模型。那些对数据隐私和安全性要求较高,或对模型某一类性能有比较极致要求,同时没有特别复杂的推理需求的垂直场景,可以在finetune开源模型的基础上去做应用开发。

锦秋基金执行董事臧天宇
对于锦秋基金来说,目前我们看好以多模态大模型作为认知和决策引擎,集成多种外围模型、工具、数据库,去构建AI原生或者AI赋能已有场景的应用。
从投资的角度来说,大模型孕育了哪些新的机会呢?我们对此做了梳理。
不考虑最底层的算力提供商,大模型的生态大概可以分为四层。
最下层是 foundation model ops 层,包含针对模型的训练、推理、部署优化以及一些数据工具。这一层的挑战在于价值可能受到更底层芯片厂和云厂商的挤压,如果未来底层更多是异构或多云的生态,那么会更有机会。
在此基础之上是模型层。这其中就包括通用基座模型,这是链条中价值最集中的一环,但从创业的角度来看,可能机会并不多。同时还存在一些基于开源体系的垂直模型,它最终是面向某个特定行业或者场景的应用,我们会更多结合具体行业应用做进一步考察。
在这两层之上是开发者工具。通过集成一些中小模型、向量数据库,去解决应用中诸如胡说八道或者长短期记忆等方面的问题,在此过程中,他肯定需要有一些开发者工具,去帮助顶层的应用开发者更好地完成应用的搭建。由于它受益于生态整体的发展,在中短期有比较高的确定性,但也要关注长期天花板问题。
最上层为应用层。这一层我们认为长期会诞生最多有价值的公司。从我们的观察看,目前市面上的应用主要集中在三个方向。

围绕大模型的投资机会版图
第一类是基于大模型比较强的开放域生成能力,解决创意启发、创意产生环节的问题。
第二类是利用大模型很强的消化吸收和索引知识的能力,可以在学习专业知识的基础上去做推理问答,能够在一些知识密集型的行业,例如法律、医疗、教育,去满足研究和咨询等场景的需求。
第三类是利用大模型本身较强的推理能力,以及代码生成和使用工具的能力,去再造自己的业务流。无论是营销端的业务流、还是企业内部管理的业务流,去解决端到端的效率问题。
这是我们目前关注到的,无论是AI native,还是基于AI去做嵌入和赋能的比较主流的创业方向。无论选择哪个方向,在做AI应用中有一个比较关键的点,就是如何面向数据闭环去做用户体验设计。在我们利用AI赋能前,首先需要对业务目标有清晰的定义,再面向这个目标进行优化,同时你要把定义清晰的这些指标通过用户体验设计的方式,落到你的产品中,才能形成正向的数据飞轮。
除了以上这些,锦秋还关注相对偏早期、偏长期的机会,即大模型和机器人的结合方向,如何让机器人和自动驾驶实现更高的智能。
首先,该方向具备很高的技术价值。一方面,探索从LLM到AGI过程中可能有一个比较重要的路线,就是具身智能(指能理解、推理、并与物理世界互动的智能系统),目前大模型只是从静态的文本和视觉图像中去学习,未来可能要从与环境的交互中去学习,这需要大模型和机器人的结合。
另一方面,对机器人行业来说,能够让其从目前的自主型机器人发展到真正的智能机器人。现在的自主型机器人在任务中能做一些简单的自适应,但它是基于对已有环境清晰的建模和特定任务明确的示教,未来机器人能够完成在更开放环境的探索或者多任务的迁移学习。
其次,从商业价值角度来看,无论是清洁工、卡车司机、建筑工人、产线工人,其所做的工作有一部分是可以通过现有技术解决,但仍存在很多问题,是需要花很多成本才能在某个环境下落地,如果未来能够用更智能化的机器人去解决,将会是万亿美金级的市场。在这个方向上谷歌已经做了比较多探索,基于PaLM模型做了非常多大模型和机器人结合的研究。
当然这其中也存在很多挑战,比如大模型如何进行压缩并部署到端侧,或者可能是云-端多模型协同的一个架构;其次,过程中需要大量的多模态预训练数据,且需要不同模态间对齐,怎么规模化地去获取这样的数据,可能数据合成会是一个重要的方向;最后,这些场景是和物理世界相连接的,这其中如何保证模型的安全性,如何做质量控制,都是非常值得思考的问题。

大模型热潮爆发前后,国内外涌现了很多基于大模型领域的创业公司,我们也对海外大模型方向的创业公司进行了梳理。
截止到2023年4月,海外的创业公司最集中的类别主要在创意辅助类的应用,比如文本生成、文生图、文生视频等方向。
第二大类是面向个人的生产力工具,利用大模型去完成个人工作流的重构。
第三大类是基础设施,相对更偏向工具链层,即如何利用好的工具链体系,在大模型的基础上去搭建应用。无论是像LangChain这样的开发框架,还是Pinecone这样的向量数据库,以及其他一些数据工具,都有不错的热度。
此外面向2B场景,能帮助企业实现内外部工作流重构。比如Chatbot跟企业的客服、销售、营销以及企业搜索等场景的结合,或者一些垂直行业的生产力工具,例如从对话到销售线索的分析、医疗记录和处方的转写、人身伤害赔付的文书准备等等。
锦秋基金在AI领域深耕多年,对AI整个商业周期的发展有切身感知。
从2012年开始,以深度学习驱动的AI 1.0萌芽,推动了CV领域的高速发展,人们对AI能力及其通用性的预期经历过一轮高峰,但事实却并没有达到大多数人的预期,最终落地的最高价值场景是在字节和Meta的信息流推荐业务中。其次,在人脸识别落地于安防场景的过程中,AI四小龙也捕获到了一定的价值和行业机会。
随着第一轮泡沫逐渐破灭,大家意识到AI的落地无法摆脱垂直领域经过标注的高质量数据集,且很难在不同任务、场景间迁移,AI开始向与垂直行业深度结合且以数据为中心的范式发展,由此带来了AI+工业、AI+农业、AI+医疗等领域的兴起,自动驾驶也向着不同的垂直场景去落地,AI 1.0重新进入了爬升期。
站在今天这个时间点,两条主线交汇。一方面,AI 1.0经历了泡沫后的复苏,和行业的结合更加紧密,逐渐进入到了商业化“摘果实”阶段;另一方面,以大模型驱动的 AI 2.0 又刚刚过了萌芽期,为行业带来了新变量。
⭐️如果你是AI领域创业者,欢迎投递BP至 [email protected]
锦秋基金愿与你共赴AI新纪元!
——END——