目录
openGauss介绍
openGauss介绍
本人有幸被CSDN、InfoQ邀请参加2023年“可信数据库发展大会”。本年度的分享聚焦“自主、创新、引领”,7月4号是主会场分享。本次大会由中国通信研究院牵头、中国通信标准化协会、大数据技术标准推进委员会、InfoQ极传媒牵头,清华大学、华为、阿里云、腾旭云、浪潮等等国内顶尖学术研究院、企业共同参与分享的顶级学术盛宴。参与了大会也深切的感受到了国内顶级学府、研究院对于理论基础研究的深度和广度,以及国内顶级企业应用研究的成果,总之受益匪浅。
下面是李国良教授关于数据库与大模型的分享,因为涉及到AIGC所以我当时就截图了,希望可以分享给更多的同学,大家一起知识共享。也感受一下国内顶级院校的独到知识熏陶。
清华大学计算机科学与技术系教授。主要研究方向为数据库,群体计算,数据挖掘、分析与检索。在数据库、数据挖掘、信息检索领域顶级会议和期刊上发表论文50余篇。获得了IEEE TCDE Early Career Award(IEEE 数据工程领域杰出新人奖)。

数据库与大模型
openGauss介绍
openGauss是一个开源关系型数据库管理系统,随Mulan PSL v2一起发布。内核基于华为多年数据库领域经验打造,持续提供针对企业级场景的有竞争力的特性。下面是openGauss的官网。
openGauss,主打就是一个高性能、高可用、高安全、高智能,比我们平时说的软件的三高还多一个,最最主要的我觉得还是自主研发。教授也提到,Gauss已经获得海外很多企业的关注和使用。



大模型与数据库
教授带来的大模型与数据的分享涵盖一下四个方面,PPT里都有描述我就不做文字翻译了,大家可以清晰的看到。

大模型为数据库带来的机遇
LLM(大模型)为数据库带来的机遇有五点:索引推荐、物化视图推荐、智能负载管理、参数调优、基数优化。







大模型解决数据库问题的挑战




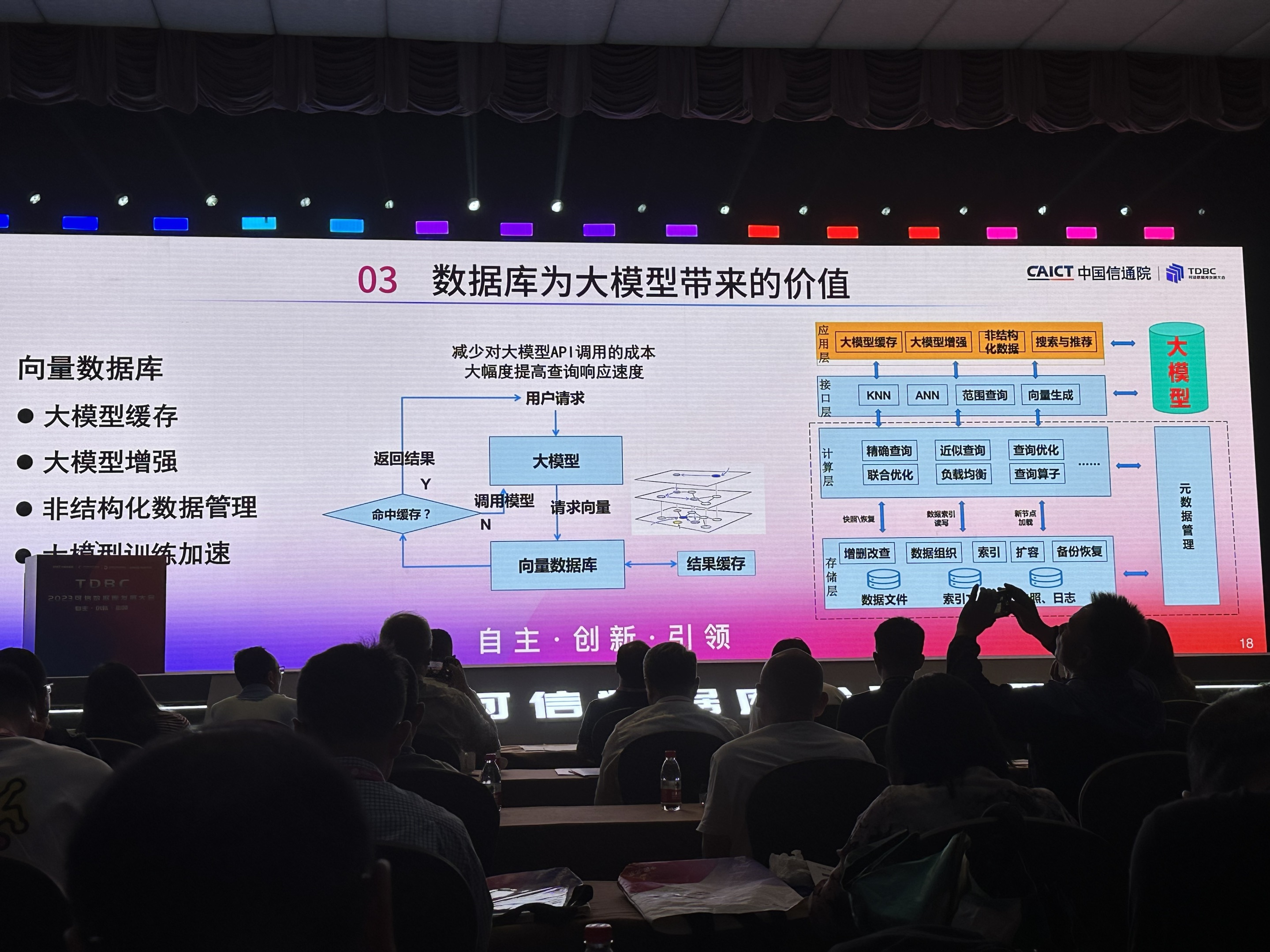
数据库为大模型带来的价值

大模型+大模型的发展趋势

趋势产品:Chat2DB
Chat2DB/README_CN.md at main · chat2db/Chat2DB · GitHub
简介
Chat2DB 是一款有开源免费的多数据库客户端工具,支持windows、mac本地安装,也支持服务器端部署,web网页访问。和传统的数据库客户端软件Navicat、DBeaver 相比Chat2DB集成了AIGC的能力,能够将自然语言转换为SQL,也可以将SQL转换为自然语言,可以给出研发人员SQL的优化建议,极大的提升人员的效率,是AI时代数据库研发人员的利器,未来即使不懂SQL的运营业务也可以使用快速查询业务数据、生成报表能力。
特性
- AI智能助手,支持自然语言转SQL、SQL转自然语言、SQL优化建议
- SQL查询、AI查询和数据报表完美集成的一体化解决方案设计与实现
- 支持团队协作,研发无需知道线上数据库密码,解决企业数据库账号安全问题
- 强大的数据管理能力,支持数据表、视图、存储过程、函数、触发器、索引、序列、用户、角色、授权等管理
- 强大的扩展能力,目前已经支持MySQL、PostgreSQL、Oracle、SQLServer、ClickHouse、OceanBase、H2、SQLite等等,未来会支持更多的数据库
- 前端使用 Electron 开发,提供 Windows、Mac、Linux 客户端、网页版本一体化的解决方案
- 支持环境隔离、线上、日常数据权限分离
生产应用:基于AI+数据驱动的慢查询索引推荐
前段时间美团也发表一篇文章,描述的是基于AI做的DB索引推荐,但是不是给予GPT是基于自己的算法所做的,思路也是比较好的,并且效果也挺好,在代价方法推荐索引的基础上,AI模型有额外12.16%的推荐索引被用户所采纳 。并且做了相关测试:这些额外补充的索引对于查询的改善情况如上图所示:上半部分展示了优化的查询执行次数,下半部分展示了查询在使用推荐的索引之后的执行时间以及减少的执行时间,这些索引总计约优化了52亿次的查询执行,减少了4632小时的执行时间。下面是文章地址,我这里就简单提一下关注的同学可以通过文章末尾的参考资料详细阅读原理。
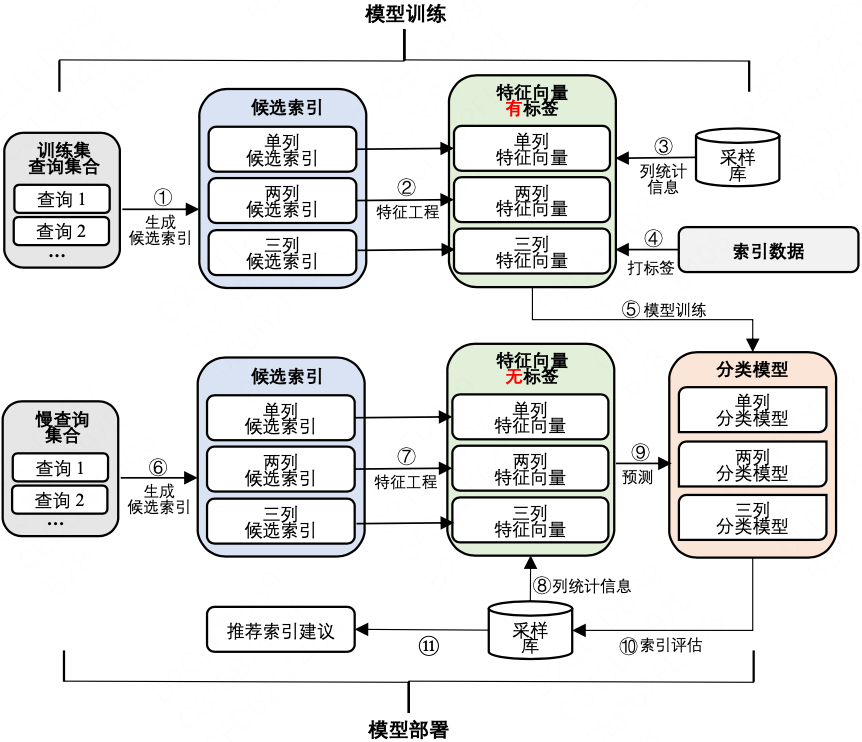
基于AI+数据驱动的索引推荐的整体架构如下图所示,主要分为两个部分:模型训练和模型部署。
模型训练
- 慢查询和被验证有效的推荐索引作为训练数据。我们生成每条查询的单列、两列和三列候选索引。
- 通过特征工程来为每个候选索引构建特征向量,使用索引数据来为特征向量打标签。
- 单列、两列和三列特征向量将分别用于训练单列、两列和三列索引推荐模型。
模型部署
- 针对需要推荐索引的慢查询,同样生成候选索引并构建特征向量。
- 我们使用分类模型来预测特征向量的标签,即预测出候选索引中的有效索引。
- 我们在采样库上创建模型预测出的有效索引,并通过实际执行查询来观察建立索引前后查询性能是否得到改善。只有当查询性能真正得到改善时,我们才会将索引推荐给用户。
参考资料: