导语:ClickHouse是一个开源的高性能列式数据库管理系统,OLAP场景设计。列式存储、向量化执行引擎、数据压缩、丰富的函数支持、索引以及预计算能力,是ClickHouse作为高性能大数据实时分析引擎的基石。而在半结构化数据处理领域,ClickHouse显得力不从心。腾讯云数据仓库另辟蹊径融合Schema-less数据库灵活性能力,使得大数据实时分析系统兼具高性能与灵活性。
作者:腾讯云大数据专家工程师 彭健
背景:大数据分析与半结构化数据
半结构化数据指的是介于结构化数据(如关系数据库中的表格数据)和非结构化数据(如文本、图像、音频等)之间的数据类型。常见的半结构化数据包括 JSON、XML、YAML 等。在大数据领域,半结构化数据扮演着越来越重要的角色。其重要性不言而喻。
-
数据来源广泛:互联网、物联网、社交媒体、移动应用、APM等领域都是半结构化数据的重要来源;
-
数据价值潜力巨大:半结构化数据通常包含了大量有价值的信息,通过对这些数据进行分析和挖掘,可以为企业提供关键的洞察和预测。
-
应用场景广泛:半结构化数据具有良好的灵活性,可以很好地表示层次结构和复杂数据关系,便于数据的交换与共享,使得半结构化数据适合处理具有多样化和不规则数据结构的业务场景。
随着数据量的激增,半结构化数据在企业数据分析中的地位将越来越重要。因此,大数据分析系统需要不断优化和发展,以更好地应对半结构化数据处理的挑战。
随着大数据技术的发展,Schema-less数据库被广泛应用在半结构化数据的存储与分析场景。Schema-less数据库无需预定义数据结构,允许数据结构运行时动态扩展,这种特性较好地适应半结构化数据的多样性与潜在可变性。
现有Schema-less数据库具备处理半结构化数据所需的灵活性、扩展性、以及针对性的存储优惠能力,但是缺乏优秀的数据分析能力。在大数据OLAP场景,具备强大分析能力的Schema-less数据库更是凤毛麟角。
ClickHouse 作为大数据实时交互式分析系统,其强大的性能优势,颇受欢迎。如果让ClickHouse也具备Schema-less能力,大数据实时分析能力将如虎添翼!
ClickHouse 现有处理半结构化数据方案
社区ClickHouse在22.3版本以前,处理半结构化数据(以JSON为例)的核心方案为JSON数据存储为STRING类型,通过工具函数来获取JSON字段信息,辅助查询分析。
-
优势:利用现有ClickHouse的能力,实现简单。
-
缺点:所有字段混合存储,查询分析效率低下。
社区ClickHouse在22.3版本以后,引入了OBJECT数据类型,支持动态子列能力。引擎针对每个写入的 JSON 对象值进行动态的类型推导,JSON属性会表示为OBJECT(JSON)列的动态子列。动态子列的支持,大幅提高了非结构化数据的分析效率和扩展性支持。
-
优势:相比早期版本,在数据建模与写入灵活性方面有了质的提升。
-
缺点:该方案在数据存储与分析的系统层面仍然没有统一结构化与半结构化数据,由此带来的问题为:
1)JSON数据的属性被存储为OBJECT(JSON)类型动态子列,由于子列与普通列的区别,导致用户无法基于动态子列二级索引、创建物化视图、PROJECTION、以及对列的增删改等核心功能。
2)由于动态子列的存在,构建分布式查询计划复杂,性能低下;
由于这些限制,客户很难使用ClickHouse处理半结构化数据。ClickHouse在处理结构化数据方面有强大的性能优势,而Schema-less 在处理半结构化数据方面具备无与伦比的灵活性与扩展性,让ClickHouse具有Schema-less能力,可大幅提升ClickHouse实时处理/分析大规模半结构化数据的能力,这将使ClickHouse在大数据实时分析领域更有竞争力。
腾讯云数据仓库ClickHouse处理半结构化数据的创新方案
腾讯云数据仓库ClickHouse实现实时分析半结构化数据方案,在系统设计时遵循了易用性、高性能、灵活性、以及可扩展原则,主要包含以下内容:
-
兼容客户端协议,降低客户集群迁移成本;
-
内核层面支持Schema-less能力,使得大数据分析兼具高性能与灵活性;
-
集群内广播元数据信息,提升系统水平扩展能力;
如果新引入协议,将加大客户业务迁移成本,限制了云数据仓库ClickHouse的应用场景。在方案设计之初,就明确降低客户业务迁移成本,做到无缝升级。
在内核层面支持Schema-less能力。简而言之,业务在写入数据前无需指定表的结构,专注业务逻辑。内核在收到写入数据后,动态增加列。后台任务根据查询分析情况,动态折叠或展开半结构化数据的嵌套结构,以实现存储效率与查询性能之间的平衡。
云数据仓库ClickHouse是采用去中心化架构设计,计算节点之间无共享数据,集群内也无管理节点。在支持Schema-less能力后,节点之间需要保持一致的表元数据信息。否则,会因为数据写入不均衡问题,导致某些动态列在其他节点上未出现,进一步引发分布式查询失败。为了保持架构上的简洁,云数据仓库ClickHouse采用GOSSIP协议实现节点之间元数据信息广播。
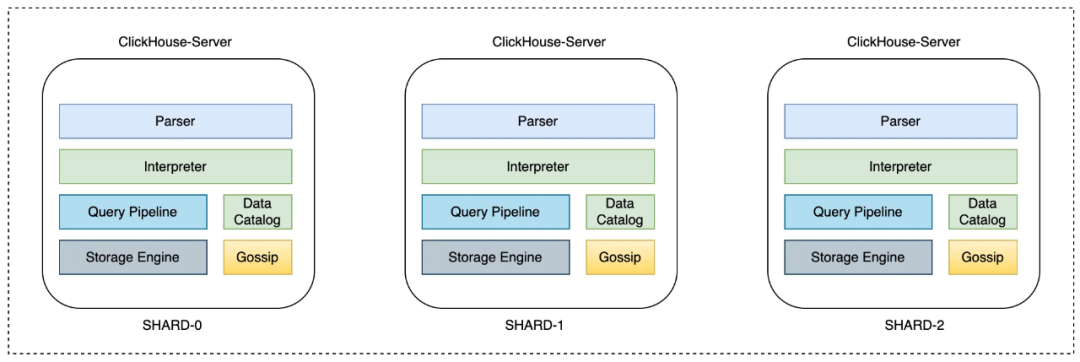
ClickHouse在代码框架上足够灵活与扩展性,能过在较少的代码侵入的情况下,实现上述功能。
内核支持Schema-less功能
降低业务迁移成本,是方案设计过程中一个重要的考量因素。ClickHouse提供了丰富的客户端接口,方便业务以不同的方式与系统交互。这些客户端已广泛应用在业务系统中。
以原生协议(Native Protocol)为例, 数据写入过程需要客户端与服务端握手,从服务端获取表结构信息,包括字段名称与类型。客户端根据上述信息,序列化输入数据以及表结构信息,并发送至服务端。服务端收到请求后,依次解析出数据,并构建和执行Query Pipeline。
为了兼容现有协议,不修改协议规范,也不增加新的数据类型。而是沿用现有协议与字段,对云数据仓库ClickHouse的Schema-less而言,沿用现有OBJECT或者String类型,沿用现有客户端协议。具体而言:
-
在数据写入流程中,支持Schema-less的表引擎将发送一个“匿名”字段,该字段为OBJECT或者String类型;
-
客户端以JSON格式数据写入,以一个OBJECT或者String类型字段存储,并发送到服务端;
服务端未发布新的数据类型,现有业务代码可以无缝升级。
对于支持Schema-less的表引擎而言,服务端收到客户端写入数据后,会被解析为TUPLE类型的数据。将TUPLE类型数据展开,并包装为ClickHouse内部通用的BlockHouse数据结构。构建数据写入的Query Pipeline,并执行。具体过程:
-
解析客户端发送的数据;
-
扩展数据写入的Pipeline, 在写入数据前检查是否存在类型冲突;
-
将JSON数据按其内部字段独立成列,并持久化在次盘上;
-
数据落盘后,在PART提交过程中更新动态列;
-
向客户端返回必要数据;
数据流动示意图,如下所示,其中CheckDynamicColumnsTransform将检查是否存在字段类型冲突问题。
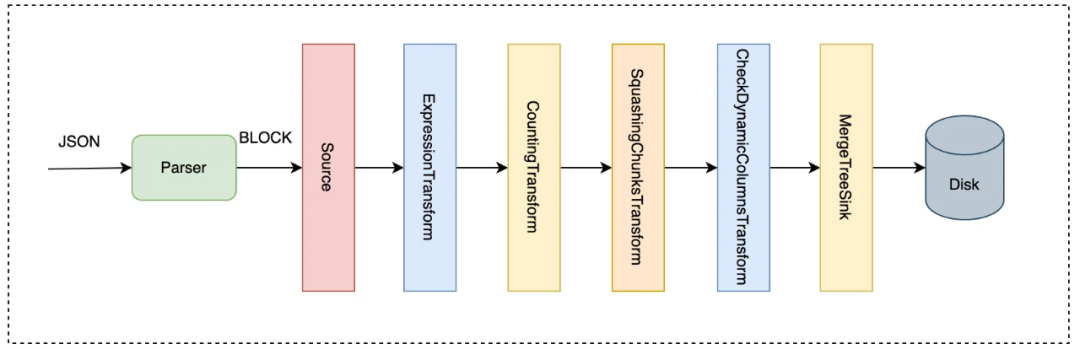
由于存储层已经将JSON内部字段按列存储了,查询引擎层需要做一些适配工作。这些适配工作包括:
-
支持通过ALTER TABLE ADD/MODIFY/DROP COLUMN ... 修改JSON内部字段;
-
支持基于JSON内部字段构建物化视图,以及PROJECTION 从而加速查询;
-
支持针对半结构化数据的特有查询方式,比如在SELECT 子句中通过通配符查询JSON内部嵌套结构。
集群内广播元数据信息
云数据仓库ClickHouse采用无中心架构设计,集群无统一的管理节点。对于支持Schema-less功能后,节点之间需要广播动态列信息,并使集群范围内节点的动态列信息保持最终一致性。否则,就会出现分布式查询执行失败问题。
未来解决这个问题,通过在集群内部采用GOSSIP协议来广播信息。采用该协议的主要原因包括:
-
可扩展性:云数据仓库ClickHouse是去中心架构,很容易扩展大规模集群,而GOSSIP协议具有良好的扩展性,满足弹性集群弹性伸缩需求;
-
容错:集群中任意节点失败,不影响GOSSIP算法正确运行,不影响云数据仓库ClickHouse集群可用性;
-
最终一致性:在去中心化架构下算法收敛快,能过实现信息指数级传播,使得元数据不一致时间短;
-
健壮性:GOSSIP协议是去中心化的协议,任意计算接单失败,不影响其他节点信息同步;
具体而言,对于支持Schema-less的表引擎,每次动态列更新后,其对应的版本信息将递增。动态列信息将会通过GOSSIP协议广播至集群其他节点。每个节点保持了一个后台任务,周期性执行消息广播动作。
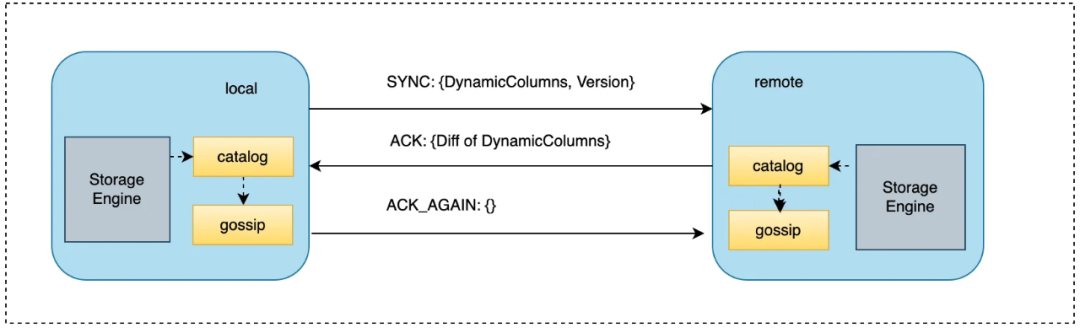
将集群节点分为2类:保持连通的节点集合与未保持连通的节点集合。后台周期性任务,每次分别在上述2个集合中各选择一个节点,完成一次消息广播(本地节点记为local, 随机选取的节点记为remote):
-
local 节点向remote节点发送SYNC类型信息:包含动态列信息以及版本;
-
remote节点收到消息后,与本地动态列比较,如必要则更新其动态列信息,向local节点返回ACK类型信息。且该类型信息中包含了增量差异信息;
-
local节点收到remote节点发送的ACK类型信息后,如必要则更新本地动态列信息,并向remote节点返回ACK_AGAIN类型消息。
数据写入,或者ALTER命令触发表的SCHEMA信息发送变更,将同步更新对应的Version。GOSSIP模块后台任务会周期性将本地数据与随机节点进行交换信息,如必要则更新。
在实际业务中,动态列信息并不是频繁变动。通常在新业务接入时,有较高频率变动,随后趋于稳定状态。
应用举例
半结构化数据写入支持Schema-less的ClickHouse集群时,只需要简单步骤:
-
创建表时需要设置参数以标识该表支持Schema-less功能,该参数为enable_dynamic_columns=1;
-
创建表时只需要指定分区键,主键以及排序键引用的字段名称以及类型;
举例说明,创建表:
CREATE TABLE r
(
`@timestamp` DateTime,
`clientip` IPv4
)
ENGINE = MergeTree
PARTITION BY toDate(`@timestamp`)
ORDER BY clientip
SETTINGS enable_dynamic_columns = 1在创建表时,只需要少量必要的字段定义,同时,指定参数表明该表支持Schema-less功能。需要注意的是,该表引擎除了支持Schema-less功能外,其他行为完全兼容。
数据写入时,需要将半结构化数据以JSON的形式放在已定义字段的后面:
INSERT INTO r SELECT
toDateTime(JSONExtractUInt(json, '@timestamp')) AS timestamp,
toIPv4(JSONExtractString(json, 'clientip')) AS clientip,
json
FROM s3('https://schema-less-testing-1301087413.cos.ap-hongkong.myqcloud.com/documents-01.ndjson.gz', 'JSONAsString')在写入了JSON数据后,该表会动态扩展字段,通过DESC r查看:
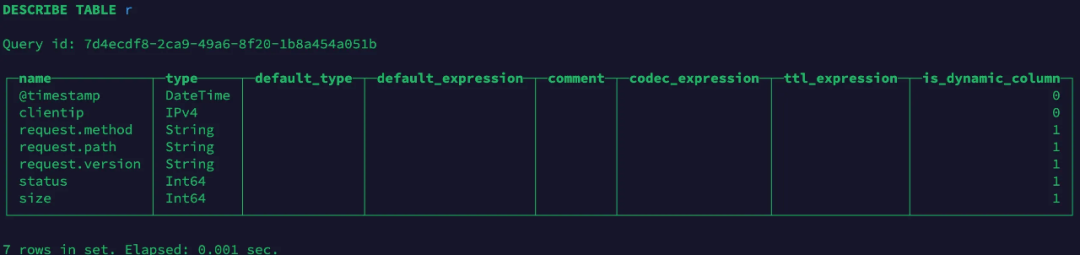
查看数据:
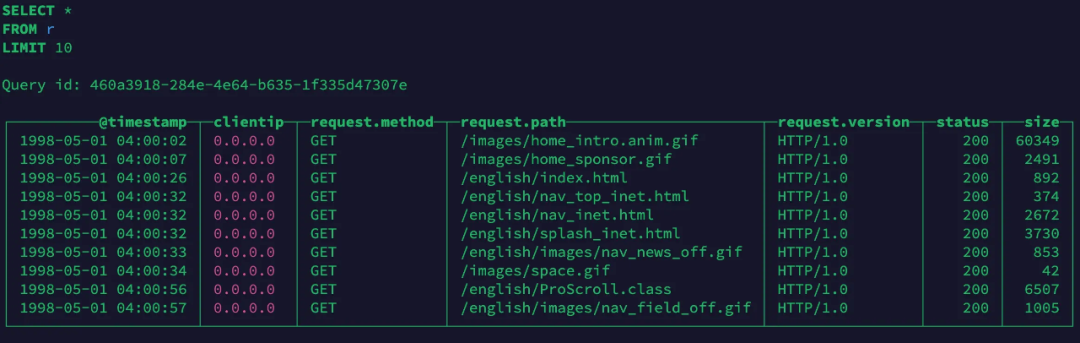
数据写入引擎后,通过通配符查询JSON内部的嵌套结构:
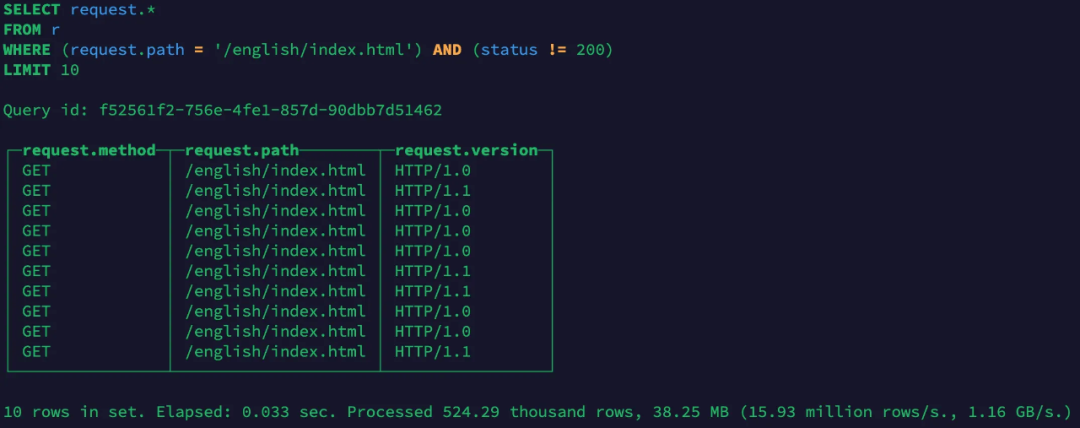
当然,也可以直接使用JSON内部字段各类查询:

对于ClickHouse内部的预计算加速查询机制,也能得到支持:
ALTER TABLE r
ADD PROJECTION p1
(
SELECT
request.path,
count()
GROUP BY request.path
)可以看到,用户可以使用ClickHouse 非常方便的对非结构化数据进行分析和查询。
性能表现
云数据仓库ClickHouse处理半结构化数据拥有良好的性能表现。在客户的生产环节中(其日志分析场景中,总数据规模300TB, 集群规模为50节点,总核数1600)ClickHouse现有方案与云数据仓库ClickHouse性能对比:
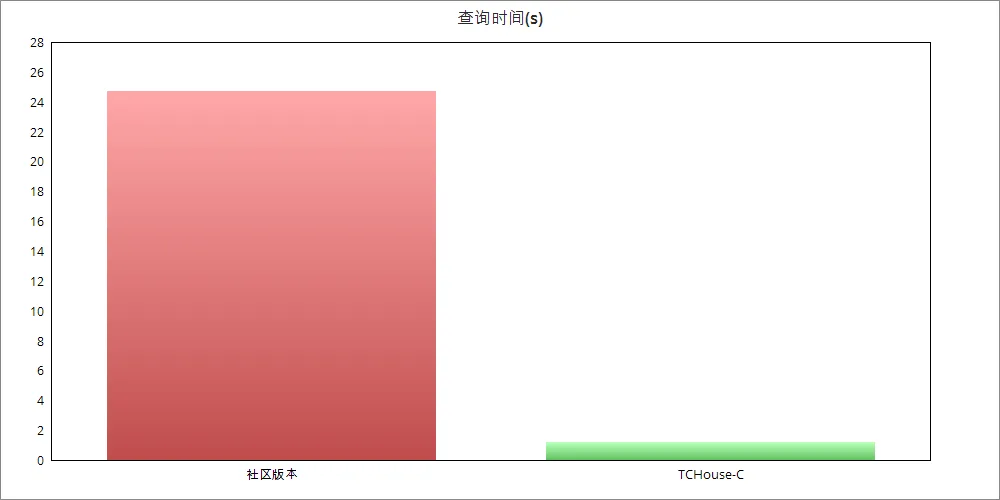
性能提升的的原因:将查询高频字段按普通列存储,充分利用向量化计算的性能优势,并且能够对其进行二级索引、预计算处理,从而提升查询性能。
总结
目前,云数据仓库ClickHouse在日志检索以及APM场景下,对半结构化数据实时分析性能提升20倍。为公有云客户节约了大量硬件成本,做到秒级返回查询结果。