三、确保所有的客户端请求都得到了妥善处理
如何在pod启动的时候,确保所有的连接都被妥善处理了
1、在pod启动时避免客户端连接断开
当个pod启动的时候,他以服务端点的方式提供给所有的服务,这些服务的标签选择器和pod的标签匹配。pod需要发送信号给kubernetes通知他自己已经准备好了。pod在准备好后,它才能变成一个服务端点,否则无法接受任何客户端的链接请求。
如果在pod spec种没有指定就绪探针,那么pod总是被认为准备好了的。当第一个kube-proxy在他的节点上面更新了iptables规则之后,并且第一个客户端pod开始连接服务的时候,这个默认被认为 准备好了的pod几乎会立即开始接受请求。如果应用这时候还没准备好接受连接,那么客户端会收到“连接被拒绝”一类的 错误信息。
你需要做的就是当且仅当信息准备好处理进来的请求的时候,才去让就绪探针返回成功。实践第一步就是添加一个指向应用根URL的HTTP GET请求的就绪探针。
2、在pod关闭时变客户端连接断开
当pod被删除,pod的容器被终止的时候,pod的容器如何在收到SIGTERM信号的时候干净的关闭。确保所有客户端请求多被妥善处理了?
了解pod删除时发生的一连串事件
1)当api服务器接收到删除pod的请求之后,他首先修改了etcd中的状态并且把删除事件通知给观察者。其中的两个观察者就是kubelet和端点控制器(Endpoint Controller)。
当kubelet接收到pod应用被终止通知的时候,他执行停止前钩子,发送SIGTERM信号,等待一段时间,然后在容器没有自我终止时强制杀死容器。
如果应用理解停止接受客户端的请求以作为对SIGTERM信号的响应,那么任何尝试连接到应用的请求都会收到Connection Refused的错误。从pod被删除到发生这个请求的时间相对来说特别短。因为这是api服务器和kubelet之间的直接通信。
2)在pod被从iptables规则中移除之前,当端点控制器接收到pod要被删除的通知时,他从所有的pod所在的服务中移除了这个pod的服务端点。他通过向api服务器发送REST请求来修改Endpoit API对象。然后api服务器会通知所有的客户端关注这个Endpoint对象。其中一些观察者都是运行在工作节点上的kube-proxy服务。每个kube-proxy服务都会在自己的节点上更新iptables规则,以阻止新的连接被转发到这些处于停止状态的pod上。
上面的两串时间是并行发生的, 最有可能的是,关闭pod中应用进程所消耗的时间比完成iptables规则更新所需要的时间稍微短一点,导致iptables规则更新的那一串事件相对比较长。因为这些事件必须先到达Endpoint控制器,然后Endpoint控制器向api服务器发送新的请求,然后api服务器必须控制kube-proxy,最后kube-proxy在修改iptables规则。存在一个很大的可能性是SIGTERM信号会在iptables规则更新到所有节点之前发送出去。
最终结果是,在发送终止信号给pod之后,pod仍然可以接收客户端请求。如果应用理解关闭服务端套接字,停止接收请求的话,这会导致客户端收到“连接被拒绝”一类的错误
解决问题
给pod添加一个就绪探针来解决问题。假如所需要做的事情就是在pod接收到SIGTERM信号的时候就绪探针开始失败,这会导致pod从服务的端点中被移除。但这个移除动作只会在就绪探针持续失败一段时间后才会发生(可以在就绪探针的spec中配置),并且这个移除动作还需要先到达kube-proxy然后iptables规则才会移除这个pod。
你可以做的唯一合理的事情就是等待足够长的时间让所有kube-proxy可以完成他们的工作,那么多长时间才是足够的呢?大部分场景下,几秒钟应该就足够了,但是无法保证每次都是足够的。当api服务器或者端点控制器过载的时候,通知到达kube-proxy的时间会更长。无法完美的解决这个问题,了解这点很重要,但是及时增加5秒或者10秒延迟也会极大提升用户体验。可以用长一点的延迟时间,但是也别太长,因为这会导致容器无法正常关闭,而且会导致pod被删除很长一段时间后还显示在列表里面,这个会给删除pod的用户带来困扰。
小结:
妥善关闭一个应用包括如下步骤:
- 等待几秒钟,然后停止接收新连接
- 关闭所有没有请求过来的长连接
- 等待所有的请求都完成
- 然后完全关闭应用
四、让应用在kubernetes中方便运行和管理
1、构建可管理的容器镜像
把应用打包进镜像的时候,可以包括应用的二进制文件和他的依赖库,或者可以将一个完整的操作系统和应用打包在一起。镜像里面的操作系统中每个文件都需要吗?并不是,大多数文件都不会用到而且仅仅会让你镜像变得比需要的大。当pod第一次被调度到节点的时候,需要等很长时间。最小化构建镜像的话非常难以调试。当你需要运行一些工具,例如ping、dig、curl或者容器中其他类似的命令的时候,会意识到让容器至少包含这些工具的最小集合有多重要。
镜像中包含那些工具,不包含那些工具,一切取决于自己的需要。
2、合理的给镜像打标签,正确的使用ImagePullPolicypod
manifest中最好不要用latest,否则无法回退到指定的版本。
必须使用能够指明具体版本的标签,如果你使用的是可更改的标签,那么需要在pod spec中奖imagepullpolicy设置为always。但是如果你在生产环境中使用这种方式,需要注意他的附加说明。如果镜像的拉取策略设置为always的话,容器运行是在遇到新的pod需要部署的时候都会联系镜像注册中心。这会拖慢pod的启动速度,因为节点需要去检查镜像是否已经被修改。更糟糕的是,镜像注册中心无法连接到的时候,这个策略会导致新的pod无法启动。
3、使用多维度而不是但维度的标签
标签可以包含如下内容:
- 资源所属应用(或微服务)的名称
- 应用层级(前端、后端等等)
- 运行环境(开发、测试、预发、生产,等等)
- 版本号
- 发布类型
- 发布类型(稳定版本、金丝雀、蓝绿开发中的绿色或者蓝色等等)
- 租户(如果你在每个租户中运行不同的pod而不是使用命名空间)
- 分片(带分片的系统)
标签管理可以让你以组而不是隔离的方式来管理资源,从而很容易了解资源的归属
4、通过注解描述每个资源
可以使用注解来给你的资源添加额外信息。资源至少应该包括一个描述资源的注解和一个描述资源负责人的注解。
在微服务框架中,pod应该包含一个注解来描述该pod依赖的其他服务的名称。这样就很容易展现pod之间的依赖关系了。其他的注解可以包括构建和版本信息,以及其他工具或者图形界面会使用到的元信息(图标名称等)
5、给进程终止提供更多的信息
为了让诊断更容易,在pod状态中显示容器终止原因,可以让容器中的进程向容器的系统中指定文件写入一个终止消息。这个文件内容会在容器终止后被kubelet读取,然后显示在kubectl describe pod中。这个进程需要写入终止消息的文件默认路径是/dev/termination-log。这个路径也可以在pod spec中容器定义的部分设置terminationMessagePath字段来自定义。
注意:如果容器没有像任何文件写入消息,可以将terminationMessagePolicy字段的只设置为FallbackToLogsOnError。在这种请下,容器的最后几行日志会被当做终止消息(仅当容器没有成功终止的情况下)
6、处理应用日志
应用将日志写到标准输出中断,而非文件中,可以容易通过kubectl log命令来查看应用日志。
提示:如果一个容器崩溃了,然后使用一个新的容器替代它,你就会看到新的容器的日志。如果希望看到之前容器的日志,那么使用kubectl logs命令的时候,加上选项--provious
如果应用把日志写到文件而不是标准输出终端,那么可以使用另外一种方法来查看日志:
$kubectl exec <pod> cat <logfile>
这个命令会在容器内部执行cat命令,把日志流返回给kubectl ,然后kubectl 将他们显示在你的终端。
将日志或者其他文件复制到容器或者从容器复制出来
将文件传送到本地机器:
$kubectl cp foo-pod:/var/log/foo.log foo.log
将文件从你的本地机器复制到pod中,可以指定pod的名字作为第二个参数:
$kubectl cp localfile foo-pod:/etc/remotefile
使用集中式日志记录
kubectl本身不提供任何集中式日志记录,必须通过其他组件来支持所有容器日志的集中式存储和分析,这些组件通常在集群中以普通的pod方式运行。
部署集中式日志记录方案很简单,需要做的就是部署几个YAML/JSON的manifest文件,这样就可以了。
在google的kubernetes引擎上,这个更加简单,在设置集群的时候选中“Enable Strackdriver Logging”选项即可。
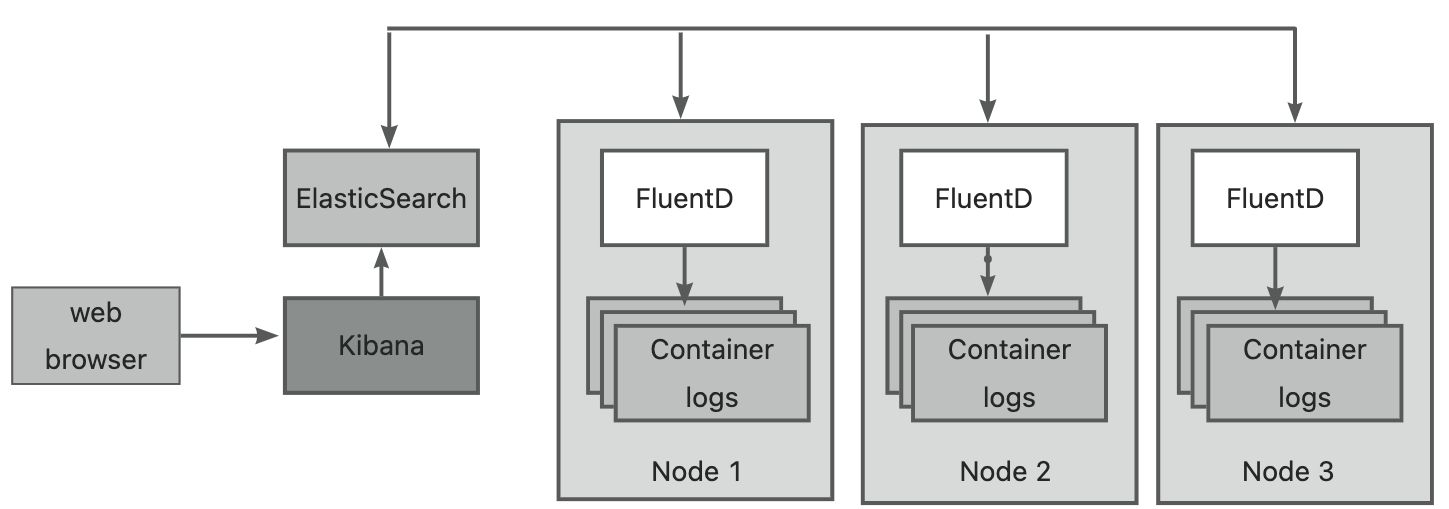
或许你已经听说过由ElasticSearch 、Logstash和Kibanna组成的ELK栈,一个稍微更改的变种的EFK栈,其中Logstash倍FluentD替换了。
当使用EFK作为集中式日志记录的时候,每个kubernetes集群节点都会运行一个FluentD的代理(通过使用DaemonSet作为pod来部署),这个代理负责从容器搜集日志,给日志打上和pod相关的信息,然后把他们发送给ElasticSearch,然后由ElasticSearch来永久的存储他们。ElasticSearch在集群中也是作为pod部署的。这些日志可以通过kubana在web浏览器中查看和分析,kubana是一个可视化ElasticSearch数据的工具,他经常也是作为pod来运行的,并且通过以服务暴露出来。EFK的三个组件如下图所示:
处理多行日志输入
FluentD代理将日志文件的每一行当做一个条目存储在ElasticSearch数据存储中,当日志输出跨多行的时候,如java 的异常堆栈,就会以不同条目存储在集中式的日志记录系统中。
为了解决这个问题,可以让应用日志输出JSON格式的内容而不是纯文本。这样的话,一个多行的日志输出就可以作为一个条目进行存储了。也可以在kibana中以一个条目的方式显示出来,但是这种做法会让kubectl log命令查看日志变得不太人性化了。
解决方式是输出到标准输出终端的日志仍然是用户刻度的日志,但是写入日志文件供FluentD处理的日志是JSON格式。这就要求在节点级别合理的配置FluentD代理或者给每个pod增加一个轻量级的日志记录容器。