“ 从学校毕业好多年了,但是语文科目的看图写话这种作文形式给我的困扰还是历历在目,为了弥补这一遗憾,决定用AI来给我看图写话,哈哈。”
01
—
图像说明
Illustrated Image Captioning(图片说明)是一种人工智能技术,它将图像自动描述为文字,同时为图像添加图像化的补充说明。与基本的图像标注技术相比,Illustrated Image Captioning可以生成更具表现力和详细的图像说明。例如,对于一张照片中的人像,Illustrated Image Captioning 能够生成像“一个年轻女性穿着蓝色的连衣裙,在风中微微地微笑着”的说明。这种技术可以应用于视觉搜索引擎、智能相册和自动翻译等领域,可以帮助计算机更好地理解和语言化图像内容,从而更好地为人类服务。
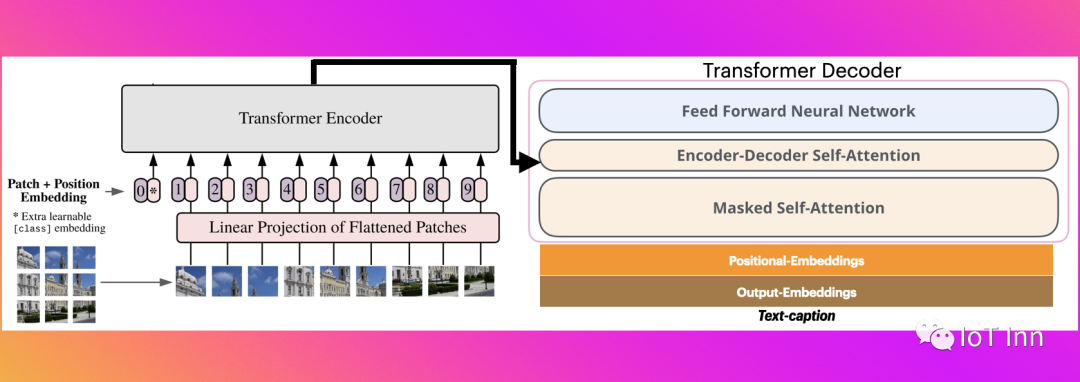
视觉编码器解码器模型可以使用任何预训练的基于Transformer的视觉模型,比如ViT,BEiT,DeiT和Swin作为编码器,以及任何预训练的语言模型,比如RoBERTa,GPT2,BERT和DistilBERT作为解码器,从而初始化一个图像到文本模型。
图像字幕生成是一个例子,其中编码器模型用于对图像进行编码,之后自回归语言模型,即解码器模型生成字幕
02
—
模型构建
主要的思路是借助图片总结模型,生成对模型总结的一句话,然后利用openai对这句话进行扩写
from transformers import VisionEncoderDecoderModel, ViTImageProcessor, AutoTokenizer
import torch
from PIL import Image
import gradio as gr
from revChatGPT.V3 import Chatbot
chatbot = Chatbot(api_key="your api key")
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning",cache_dir="vit-gpt2-image-captioning",resume_download=True)
feature_extractor = ViTImageProcessor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
tokenizer = AutoTokenizer.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
max_length = 100
num_beams = 40
gen_kwargs = {"max_length": max_length, "num_beams": num_beams}
def predict_step(image,style):
i_image = Image.fromarray(image.astype('int8'),'RGB')
pixel_values = feature_extractor(images=i_image, return_tensors="pt").pixel_values
pixel_values = pixel_values.to(device)
output_ids = model.generate(pixel_values, **gen_kwargs)
preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
preds = [pred.strip() for pred in preds]
prompt = "根据这句话写一篇200字的散文,散文是{}的风格:{}".format(style,preds[0])
result = chatbot.ask(prompt)
# result = llm.generate([prompt])
return result
demo = gr.Interface(fn=predict_step,
inputs=[gr.Image(),
gr.Dropdown(
["鲁迅", "徐志摩", "莫言", "老舍"],
label="Style",
info="选择你需要的作文的风格."
)],
outputs=[
# gr.Textbox(label="prediction"),
gr.Textbox(label= "Essay")]
)
demo.launch()如下图是生成的结果,看上去像那么回事了,但是感觉还是有点胡扯,哈哈
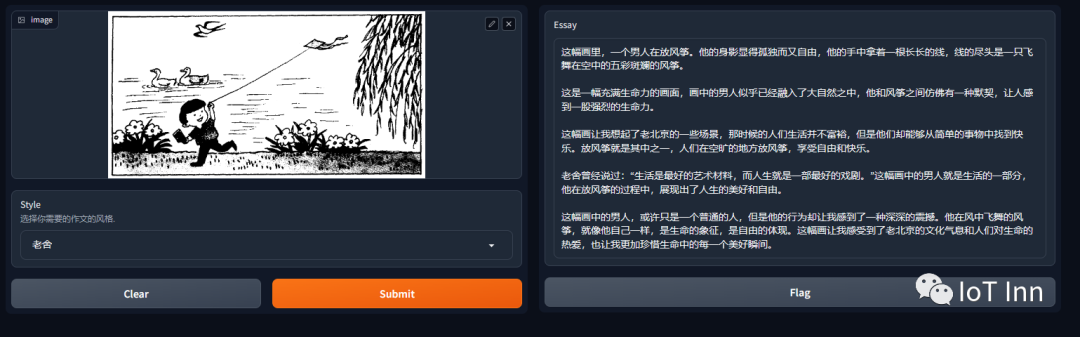
如果你也想用AI看图说话,那就试试吧