“ 上一篇图文我们简要的看了DragGAN的官方源码,效果还可以,但是只能编辑StyleGAN生成的图片,没办编辑自定义的图片,当然如果需要编辑自己的图片,就需要将图片投影(或反转)到styleGAN预训练生成器的领域中。”
01
—
什么是图像反转(inversion)
反转是指将一个图像映射到生成模型的潜空间中,然后通过调整潜空间向量来修改图像的外观。反转过程旨在通过反向计算生成模型中的潜空间向量,将现实图像转换为生成模型可识别和编辑的形式。在图像编辑的上下文中,反转常用于在潜空间中进行编辑操作,然后将编辑后的潜空间向量转换为修改后的图像。通过这种方式,可以实现对图像的各种编辑操作,例如改变姿势、修改外貌特征或添加不同的风格。通过反转和编辑潜空间,可以实现对图像的高级编辑,同时保持图像的真实性和准确性。
最近,出现了一系列利用预训练的StyleGAN的生成能力的高级面部编辑技术。为了成功地编辑一张图片,首先必须将该图片投影(或反转)到预训练生成器的领域中。然而,事实证明,StyleGAN的潜空间引入了一种固有的失真和可编辑性之间的权衡,也就是在保持原始外观和真实改变一些属性之间的权衡。从实际角度来看,这意味着对于位于生成器领域之外的面部,应用保持身份特征的面部潜空间编辑仍然具有挑战性。
02
—
PTI
为了解决这个问题,有人提出了关键调整用于基于潜空间编辑真实图像的方法(Pivotal Tuning for Latent-based Editing of Real Images)。它是一种技术,通过微调生成模型的潜空间,使得可以对真实图像进行编辑。在这种方法中,首先需要将真实图像进行反转,将其映射到生成模型的潜空间。然后,通过调整潜空间向量,可以对图像进行各种编辑操作,例如改变外貌特征、调整姿势或添加不同的风格。关键调整的目标是在编辑图像时保持其身份特征的准确性和一致性。通过这种方式,可以在真实图像上应用基于潜空间的语义编辑技术,实现高级的图像修改。
PTI原始论文,2106.05744.pdf (arxiv.org),研究目标,对于真实图片的高清编辑,论点:对于一个编辑任务,对于真实图片的映射到隐层空间后已经out of domain,导致生成的图片会有伪影,因提出了训练生成器,扩大生成器的输入domain,使得编辑后的采样点也在生成器的输入域范围内。所以,本文在训练的时候是pivotal tuning,轻微调整生成器,使得那些从真实图片映射至隐空间可能out of domain的点也能生成和输入一样的图像。这样既能保持编辑能力又能保持重构能力。
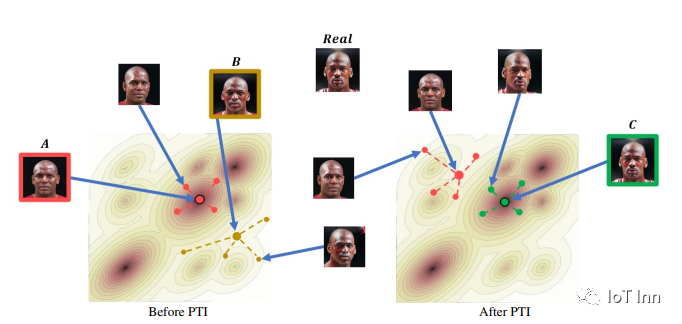
训练分两大步,首先是GANinversion,将真实图片映射到wp,然后以这个wp点去训练生成器来产生希望的图片,由于wp与真实图片的位置足够近,使得只需增强一些外形参数而不影响其他StyleGAN结构即可完成重构。(intuition的感觉就是先通过原始的GANinversion生成一张相似的脸,再通过finetun把这个相似的脸训练成和真实图片一样的脸)
03
—
PTI代码训练
在论文中作者给出了代码仓库的地址:danielroich/PTI: Official Implementation for "Pivotal Tuning for Latent-based editing of Real Images" (ACM TOG 2022) https://arxiv.org/abs/2106.05744 (github.com)
首先我们将代码clone下来,然后anaconda配置好环境,如果各位已经根据我上一篇图文跑通了GragGAN,用这个环境即可,实际上都是styleGAN的开发环境。如果各位在配置环境的时候出现了如下错误

大概率是cudatoolkit的版本不对,本人之前的版本是11.4,一直没跑通,后来换了很多版本,发现只有11.1可以用,那么pytorch的版本只能配合cu111的。
然后我们需要配置好config文件下的paths_config各个路径,包括原始图片的路径,已经对齐图片的路径。
接下来需要进行如下操作:
1、将需要编辑的图片放到配置的文件夹内,运行utils下的align_data.py,将图片处理成需要的格式和大小,处理后的图片会生成到你配置的路径下。
2、运行scripts下的run_pti.py,这个过程会生成对应的权重文件到scripts下的checkpoints文件夹下以及embedding权重文件到embeddings文件夹下。
import os
from configs import paths_config
import pickle
import torch
class pt2pkl:
def __init__(self,modelpath):
self.modelpath = modelpath
self.model_id = []
self.image_name = []
file_list = os.listdir(self.modelpath)
for file in file_list:
name, ext = os.path.splitext(file)
if ext == '.pt':
self.model_id.append(name.split('_')[1])
self.image_name.append(name.split('_')[2])
def load_generators(self, model_id, image_name):
with open(paths_config.stylegan2_ada_ffhq, 'rb') as f:
old_G = pickle.load(f)['G_ema'].cuda()
with open(f'{paths_config.checkpoints_dir}/model_{model_id}_{image_name}.pt', 'rb') as f_new:
new_G = torch.load(f_new).cuda()
return old_G, new_G
def export_updated_pickle(self,new_G,model_id,image_name):
print("Exporting large updated pickle based off new generator and ffhq.pkl")
with open(paths_config.stylegan2_ada_ffhq, 'rb') as f:
d = pickle.load(f)
old_G = d['G_ema'].cuda() ## tensor
old_D = d['D'].eval().requires_grad_(False).cpu()
tmp = {}
tmp['G_ema'] = old_G.eval().requires_grad_(False).cpu()# copy.deepcopy(new_G).eval().requires_grad_(False).cpu()
tmp['G'] = new_G.eval().requires_grad_(False).cpu() # copy.deepcopy(new_G).eval().requires_grad_(False).cpu()
tmp['D'] = old_D
tmp['training_set_kwargs'] = None
tmp['augment_pipe'] = None
with open(f'{paths_config.checkpoints_dir}/model_{model_id}_{image_name}.pkl', 'wb') as f:
pickle.dump(tmp, f)
def pt2pkl_impl(self):
for i in range(len(self.image_name)):
use_multi_id_training = False
generator_type = paths_config.multi_id_model_type if use_multi_id_training else self.image_name[i]
old_G, new_G = self.load_generators(self.model_id[i], generator_type)
self.export_updated_pickle(new_G, self.model_id[i],self.image_name[i])
if __name__ == '__main__':
modelpath = './checkpoints'
file_list = os.listdir(modelpath)
for file in file_list:
name, ext = os.path.splitext(file)
print(name,ext)
pt2pkl_demo = pt2pkl(modelpath=modelpath)
pt2pkl_demo.pt2pkl_impl()checkpoints文件会转换成pkl格式。
04
—
GragGAN编辑自定义图片
我们将第三步的生成的checkpoint文件和对应的embeddings文件复制到DragGAN工程中scripts/checkpoints文件夹下。
然后需要对visualizer_drag_gradio.py文件进行如下修改:
init_pkl = 'stylegan2_model_WRAFMRCPCXUC_AB'修改为你生成的pkl模型名字,注意一定要在名字前加上stylegan2,不然会无法识别
然后修改init_image
w_pivot = torch.load('0.pt',map_location=torch.device('cpu'))
state['renderer'].init_network(
state['generator_params'], # res
valid_checkpoints_dict[state['pretrained_weight']], # pkl
state['params']['seed'], # w0_seed,
# None, # w_load
w_pivot, # w_load
state['params']['latent_space'] == 'w+', # w_plus
'const',
state['params']['trunc_psi'], # trunc_psi,
state['params']['trunc_cutoff'], # trunc_cutoff,
None, # input_transform
state['params']['lr'] # lr,
)接着就是见证奇迹的时刻python visualizer_drag_gradio.py
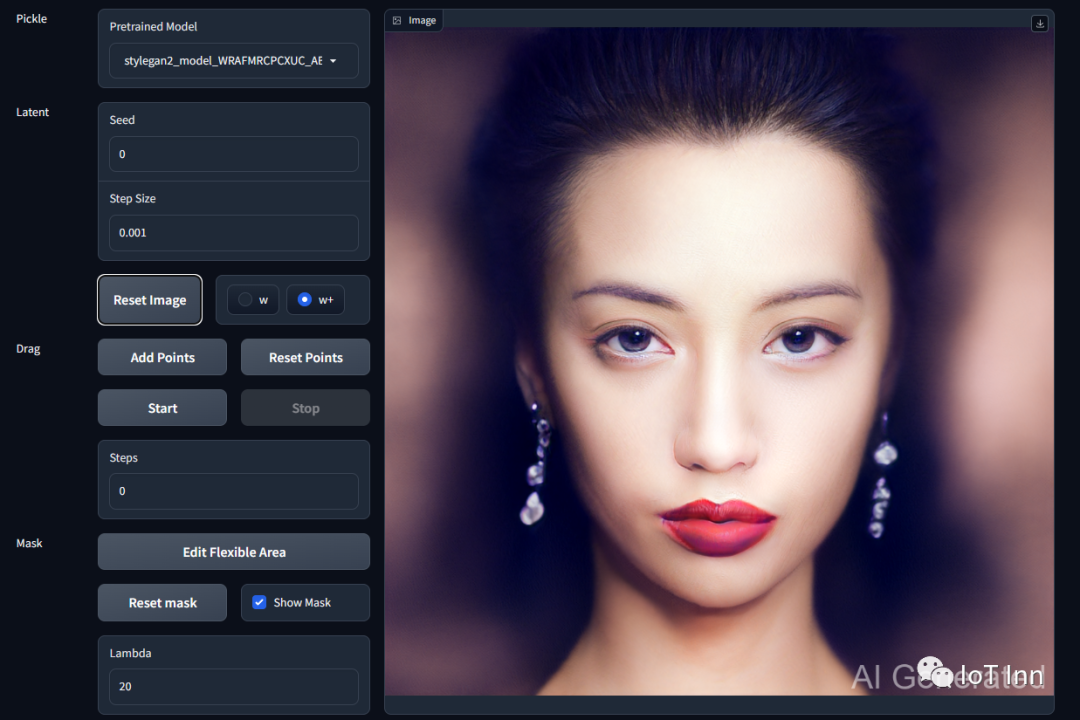
然后我们我们试试编辑他的头发
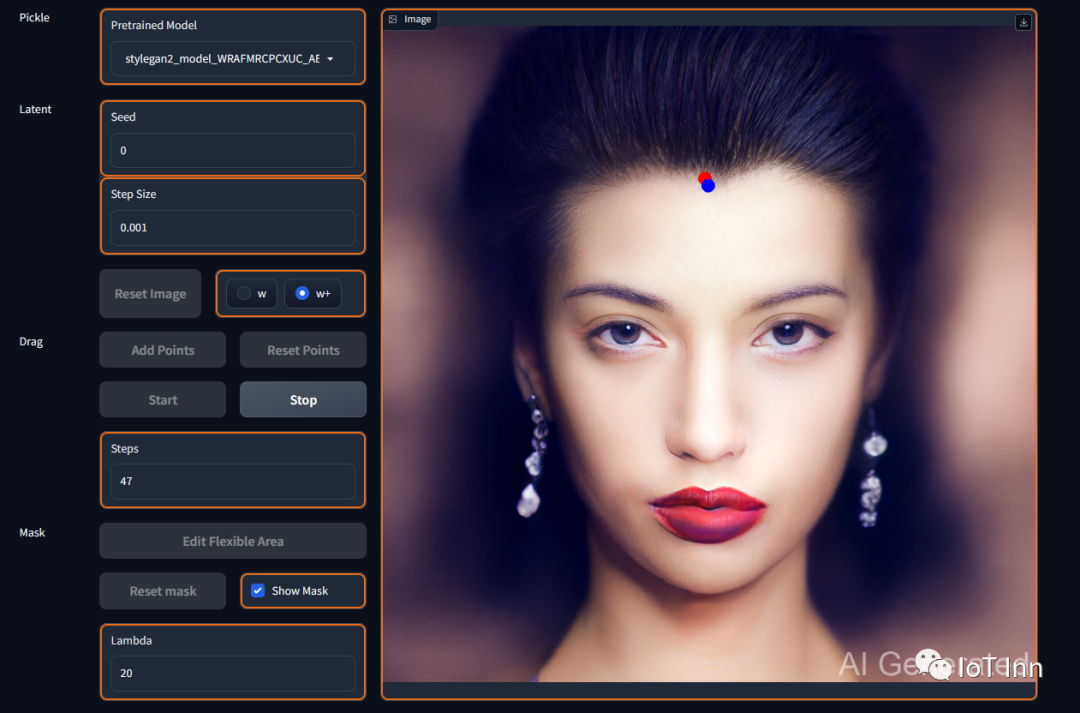
哈哈,一键摆脱脱发困扰。
再试试另外的图像
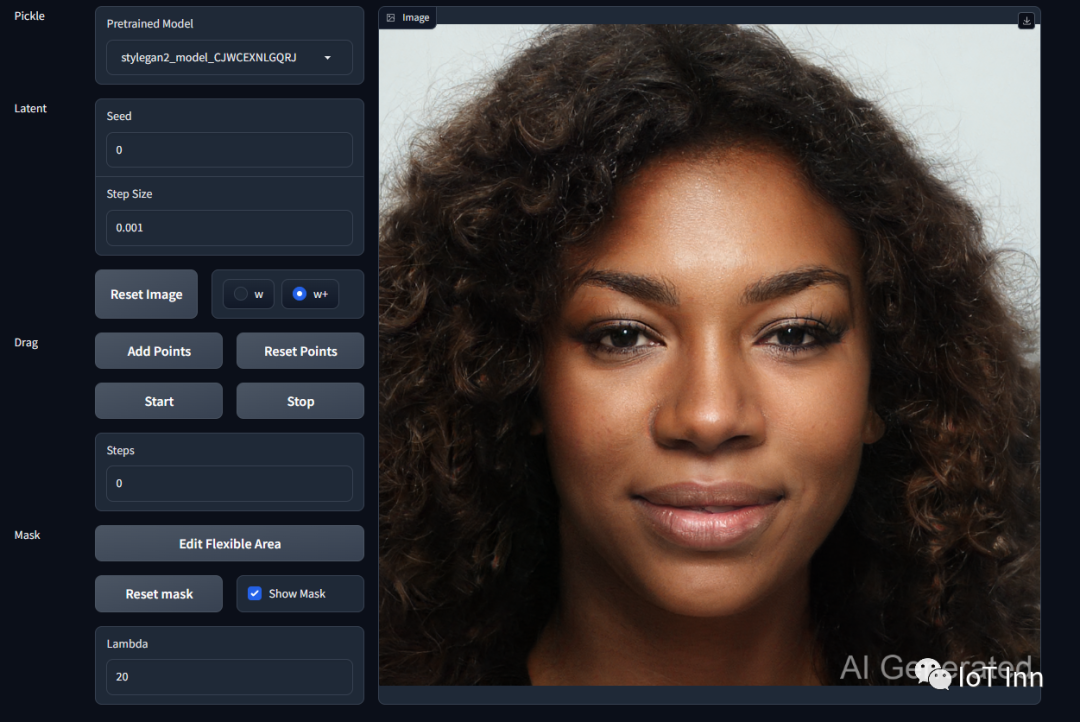
这次让小薇给咱笑一个
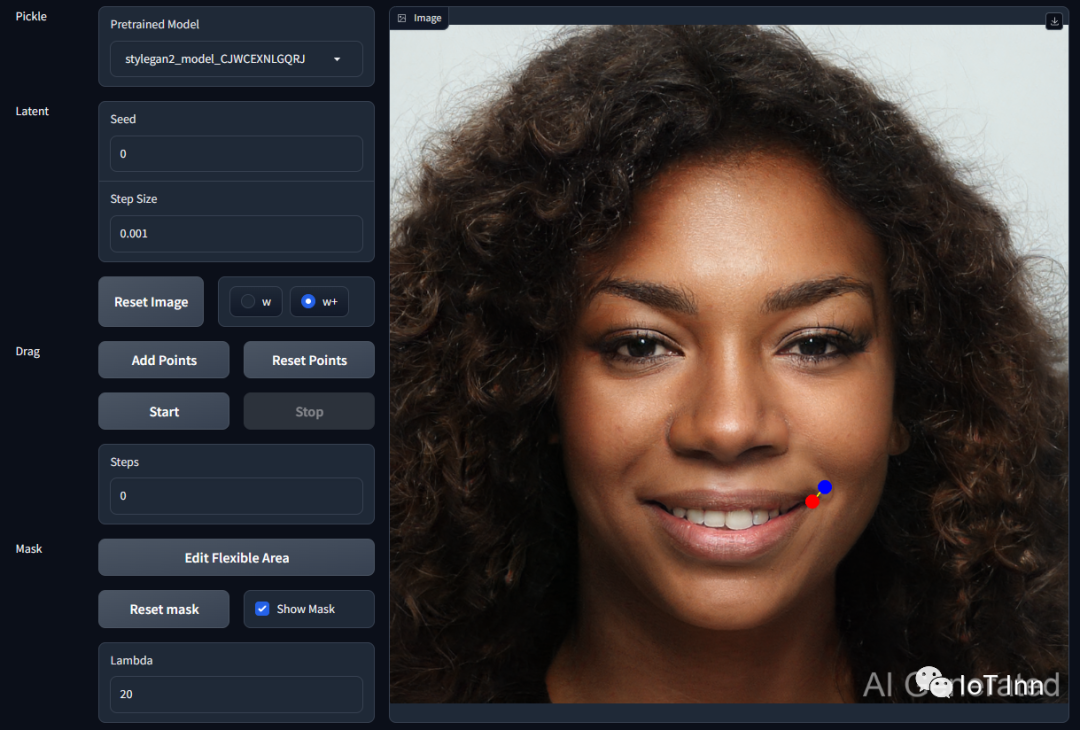
效果还是相当不错的。
到这里基本实现了自定义图像的输入到styleGAN,但是这种方式实在是显得太笨拙了,每一张图像都需要反转一次,费时费力,每一张图像都需要两个不小的模型来支撑,实在是不具备量产的基础。当然硬件富裕的大佬除外。
想尝试的小伙伴点个关注,可以自行尝试下。