语法分析——自上而下分析
语法分析是编译过程的核心部分,它的任务是在词法分析识别出单词符号串的基础上,分析并判定程序的语法结构是否符合语法规则。
语法分析器在编译程序中的地位
按照语法分析树的建立方法,我们可以粗略地把语法分析办法分成两类,一类是自上而下分析法,一类是自下而上分析法。
自上而下分析的主旨是,对任何输入串,试图用一切可能的办法,从文法的开始符号(根节点)出发,根据文法自上而下地为输入
串建立一棵语法树,或者说为输入串寻找一个最左推导。这种分析过程本质上是一种试探过程,是反复使用不同产生式谋求匹配
输入串的过程。
例:假定有文法(1)S—>xAy (2)A—>**|* 以及输入串x*y(记为α)。
为了自上而下构造α的语法树,我们首先按文法的开始符号产生一个根结S,并让指示器ip指向输入串的第一个符号x,然后用S的
规则将这棵树发展为:
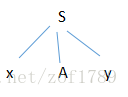
我们希望用S的子结从左至右地匹配整个输入串α。首先,此树的最左子结是以终结符x为标志的子结,它和输入串的第一个符号
相匹配。于是应将ip调整为指向下一个输入符号*,并让第二个子结A去进行匹配。非终结符A有两个候选,我们试着用它的第一
个候选式去匹配输入串,则语法树发展为下图:
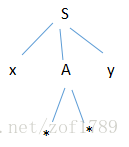
A的左子结和ip所指的符号*相符,但是A的第二个子结和y不符,故的第一个候选并不适用,应看A的第二个候选。用A的第二个
候选去匹配输入串,则语法树发展为下图:
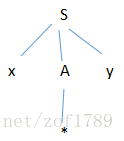
A只有一个子结*而且它和ip所指的符号串相一致,于是A完成匹配任务。S的第三个子结y与y相匹配,则y完成匹配任务。至此,
完成了α构造语法树的任务,证明了α是一个句子。
实现这种自上而下的带回溯试探法的一个简单的途径是让每个非终结符对应一个递归子程序。每个这种子程序可作为一个布尔过
程。一旦发现他的某个候选与输入串相匹配,就用这个候选去扩展语法树,并返回“真”值;否则,保持原来的语法树和ip值不
变,并返回“假”值。
自上而下分析法存在的问题:
P=>+Pα 当试图用P去匹配输入串时,在没有识别任何输入符号的情况下,又得重新要求P去进行新的匹配,这样一来,使推
导无限循环下去。
2.回溯的不确定性,要求我们将已经完成工作推倒从来
匹配不成功,需要回溯。需要把已经做过的一大堆工作(各种表格工作、语义分析等)推倒重来,既费时又费力.
3.虚假匹配的问题
例如上述的例子,考虑输入串x**y。若对A首先使用第二个候选式,A将成功地把它的唯一的子结*匹配于输入串的第二个符号,
但是S的第三个子结y与第三个输入符号*不匹配。因而导致了无法识别输入串x**y是个句子,然而,若A首先使用它的第一个候选
**,则整个输入串即可获得成功分析。这意味着,A首先使用第二个候选所得的成功匹配是虚假的。由于这种现象的产生,我们
需要更复杂的回溯技术。一般来说,消除虚假匹配是很困难的,但若从最长的候选开始匹配,虚假匹配的现象就会减少。
4.不能准确地确定输入串中出错的位置
当最终报告分析不成功时,难于知道输入串中出错的确切位置
5.效率低
由于带回溯,实际上才用了一种穷尽一切可能的试探法,因此,效率很低,代价极高。该方法只有理论意义,在实践上价值不大
4.3 LL(1) 分析法
引例:
设有产生式
P→Pα|β (1)
其中β不以P开头,α不为ε。那么,我们可以把P的规则改为如下的非直接左递归形式:
P→βP’
P’→αP’|ε (2)(1)式和(2)式是等价的
对于(1)式:
P=>Pα=>Pαα=>…=>Pαα…α=>βαα…α
对于(2)式:
P=>βP’=>βαP’=>βααP’=>…=>βαα…αP’=> βαα…α
例:设有文法
E → E + T | TT → T * F | F
F → (E) | i
消除其产生式的直接左递归解:对于E → E + T | T
(P=E,α=+T,β=T)变成
E→TE’
E’→+TE’|ε
E=>E+T=> E+T+T=> E+T+…+T=>T+T+…+T
E=>TE’=> T+TE’=> T+T+TE’=>T+T+…+TE’=>T+T+…+T
消除直接左递归方法:
设有产生式P→Pα1|Pα2|…|Pαm|β1|β2|…|βn其中每个βi不以P开头,每个αi不为ε
消除P的直接左递归性就是把这些规则改写成:P→β1P’|β2P’|…|βnP’
P’→α1P’| α2P’|…|αmP’| ε
用这个办法,我们容易把见诸于表面的所有直接左递归都消除掉,也就是说,把直接左递归都改成直接右递归。但这并不意味着已经消除整个文法的左递归性。例如文法:
S→Qc|c
Q →Rb|b
R →Sa|a
虽然不具有直接左递归,但SQR都是左递归的,例如有S=>Qc=>Rbc=>Sabc。
消除文法的左递归的步骤:
1)将间接左递归改造为直接左递归
将文法中所有如下形式的产生式:
Pi →Pjγ|β1|β2|…|βn
Pj→δ1|δ2|δ3|…|δk
改写成:
Pi →δ1γ|δ2γ|δ3γ|…|δkγ|β1|β2|…|βn2)消除直接左递归
P→Pα1|Pα2|...|Pαm|β1| β2|...| βn
消除P的左递归
P→ β1P'| β2P'|...| βnP'
P'→ α1 P'| α2 P'|...|αm P'| ε
3)化简改写后的文法,即去除那些从开始符号出发却永远无法到达的非终结符的产生规则。
最终得到无左递归的文法。
消除回溯
欲构造行之有效的自上而下分析器,必须消除回溯。为了消除回溯就必须保证:对文法的任何非终结符,当要它去匹配输入串
时,能够根据它所面临的输入符号准确地指派它的一个候选去执行任务,并且此候选的工作结果应是确信无疑的。即若该候选式
匹配成功,那么该匹配不是虚假匹配。若该候选式无法完成最终的匹配任务,则其他任何候选式肯定也无法完成。
消除回溯的条件
定义FIRST集
令文法G是不含左递归的文法,对G的非终结符的候选α,定义它的开始符号(终结首符)集合: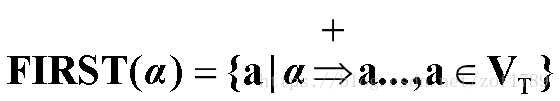
【注】
特别地,如果α=> ε,则ε∈FIRST(α)
如果非终结符A的任意两个候选式αi和αj的开始符号集满足FIRST(αi)∩FIRST(αj)=Φ,则A可以根据所面临的第一个输入符号,准
确地指派一个候选式α去执行任务,α是那个FIRST集含a的候选式,即 a ∈FIRST(α)。
将一个文法改造成任何非终结符的所有候选首符集两两不相交的办法是提取公共左因子。
例如:假设A的产生式为
A→δβ1|δβ2|…|δβn|γ1| γ2|…|γm
其中每个γ不以δ开头
那么把这些产生式改写为:
A→δA’ |γ1| γ2|…|γm
A’→β1|β2|…|βn反复提取左因子(包括对新引进的非终结符,例如A’)就能够把每个非终结符的所有候选首符集变成为两两不相交。我们为此付出
符代价是,大量引进新的非终结符和ε-产生式。
LL(1)分析条件
定义FOLLOW集
对文法G的任何非终结符A,定义它的后继符号集合:
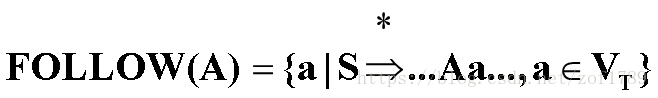
【注】
1)特别地,如果S*=>…A,则#∈FOLLOW(A)
2)FOLLOW(A)集合是所有句型中出现在紧接A之后的终结符号或#所组成的集合
3)当非终结符A面临输入符号a,且a不属于A的任意候选式的FIRST集但A的某个候选式的FIRST集包含ε时,只有当a
∈FOLLOW(A),才可能允许A自动匹配
3.不带回溯的自上而下分析的文法条件(LL(1)文法)
(1)文法不含左递归
(2)对于文法中每一个非终结符A的各个产生式的候选式的FIRST集两两不相交。即,若 A→α1|α2|…|αn 则
FIRST(αi)∩FIRST(αj)=Φ (i≠j)
(3)对于文法中的每个非终结符A,若它的某个候选首符集包含ε,则FIRST(A)∩FOLLOW(A)=Φ
如果一个文法G满足以上条件,则称该文法G为LL(1)文法(第1个L代表从左到右扫描输入串,第2个L代表最左推导,1表示分
析时每一步只看1个符号)
4.不带回溯的自上而下分析的方法
对于LL(1)文法,假设要用非终结符A进行匹配,面临输入符号为a,A的所有产生式为 A→α1|α2|…|αn(1)若a ∈ FIRST(αi) ,则指派αi去匹配
(2)若a不属于任何一个候选首符集,则:
①若ε属于某个 FIRST(αi)且a∈FOLLOW(A),则让A与ε自动匹配;
②否则,a的出现是一种语法错误
4.4递归下降分析程序构造
当一个文法满足LL(1)条件时,我们就可以构造一个不带回溯的自上而下分析程序,这个分析程序由一组(可能的)递归程序组
成,每个过程对应文法的一个非终结符。这样一个分析程序称为递归下降分析器。
具体做法:对文法的每一个非终结符都编一个分析程序,当根据文法和当时的输入符号预测到要用某个非终结符去匹配输入串
时,就调用该非终结符的分析程序。
4.5预测分析程序
使用高级语言的递归过程描述递归下降分析器,只有当具有实现这种过程的编译系统时才有实际意义。
实现LL(1)分析的另一种有效方式是使用一张分析表和一个栈进行联合控制。我们现在介绍的预测分析程序就是属于这种类型的
LL(1)分析器。
预测分析程序工作过程
在实际语言中,每一种语法成分都有确定的左右界符,为了研究问题方便,统一以‘#’表示 。
预测分析器模型:
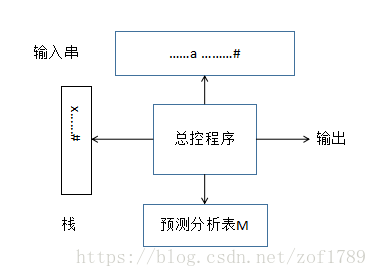
栈STACK用于存放文法的符号。分析开始时,栈底先放一个‘#’,然后,放进文法开始符号。同时,假定输入串之后也总有一
个‘#’,标志输入串结束。执行程序主要实现如下操作:
1.把#和文法起始符号E推进栈,并读入输入串的第一 个符a,重复下述过程直到正常结束或出错.
2.测定栈顶符号X和当前输入符号a,执行如下操作:
(1)若X=a=#,分析成功,停止。E匹配输入串成功.
(2)若X=a≠#,把X推出栈,再读入下一个符号。
(3)若X∈Vn,查分析表M
a) M[X,a]= X→UVW 则将X弹出栈,将UVW压入
注:U在栈顶 (最左推导)
b) M[X, a] = error 转出错处理
c) M[X, a] = X-〉ε ---a为X的后继符号 则将X弹出栈 (不读下一符号)
预测分析表的构造——FIRST(X)
1.若X终结符,则FIRST(X)={X}
2.若X为非终结符,且有X->a …的产生式,则把a加入到FIRST(X)中;
3.若X->Y…是一个产生式,且Y为非终结符,则把FIRST (Y)-ε加入到FIRST(X)中;
若X->Y1Y2Y3….YK,是产生式, Y1Y2Y3….Yi-1是非终结符,而且ε属于 FIRST (Yj)(1<=j<=i-1),则把FIRST (Yj)-ε加入到
FIRST(X)中;如果ε属于所有的FIRST (Yj),则ε加入到FIRST(X)中
预测分析表的构造——FOLLOW(X)
1.对于文法的开始符,置#于FOLLOW(S)中
2.若A->αBβ, 则把FIRST (β)-ε加入到FOLLOW(B)中,
3.若A->αB 是一个产生式,或 A->αBβ是一个产生式,而β-> ε,则把FOLLOW(A)加入到FOLLOW(B)中
4.6错误恢复的方法
跳过输入串中的一些符号,直到遇到同步符号。遇到同步符号时,将符号栈顶的非终结符出栈
将FOLLOW(A)设为同步符号
将FIRST(A)加入到同步符号
如果非终结符产生空串,可以自动匹配,以推迟检测到错误的时间。
如果栈顶是终结符,当出错时,直接将栈顶出栈