行人重识别Reid(一):Person_reID_baseline_pytorch
文章目录
前言
最近项目上有人员轨迹识别的需求,传统使用手机基站定位法数据获取难度大,后来确定还是用图像识别的方法来做,据了解可以借助REID技术来实现。
一、reid 定义
1、什么是reid
简单理解就是,我们需要根据某行人A的图像,在图像候选集中找到该行人A的其他图像。reid 技术在实际场景中有着很重要的作用。
使用 reid 技术,我们便可以在一个监控系统中,构建行人的运动轨迹,并应用到各种下游任务。比如在小区监控系统中,我们在某个时刻锁定犯人A,根据 reid 技术,我们就可以在整个监控系统的中,自动的找出犯人A在整个小区监控中出现的图片,并确定他的运动轨迹,最终辅助警察抓捕。再比如在智慧商业场景中,我们可以根据 reid 技术描绘出每个消费者的商场运动轨迹和区域驻留时间,从而优化客流、辅助商品推荐等。。
reid 算法可以分解为以下3步:
- 特征提取:给定一个查询图片(query image)和大量的数据库图片(gallery
images),提取出它们的语义特征。在这个特征空间,同一个人的图片距离尽可能小,不同人图片距离尽可能大。目前主流的 reid算法使用深度卷机神经网络(CNN,如 ResNet50)提取特征。 - 距离计算:得到查询特征(query feature)和数据库特征(gallery
features)后,计算查询图片和数据库图片的距离。通常使用欧式(euclidean)、余弦(cosine)距离等。 - 排序返回:得到距离后,我们可以使用排序算法对样本进行排序,通过卡距离阈值或者K近邻的方法,返回最终样本。一般使用快速排序算法,其复杂度是
O(NlogN),N 为数据库图片数量。
2、reid_baseline
reid_baseline(Person_reID_baseline_pytorch):reid_baseline 是一个基于pytorch实现的,小巧、友好并且强大的 reid baseline。它的性能媲美当前最好的公开方法(强大),支持fp16精度用2GB显存进行训练(小巧),并且提供了一个8分钟快速教程入门reid(新手友好)。该 baseline 由 Zhezhong Zheng 博士于2017年发布,至今 github star 数量已经超过 2k。
二、准备工作
1、环境
依赖pytorch环境,之前已配置好,在这复用即可,配置方法参考文章:图像识别(二):anaconda 配置pytorch环境,运行yolov5
2、code
项目地址:https://github.com/layumi/Person_reID_baseline_pytorch
3、数据
下载地址Market-1501
数据集简介:
Market-1501数据集在清华大学校园中采集,夏天拍摄,在2015年构建并公开。它包括由6个摄像头(其中5个高清摄像头和1个低清摄像头)拍摄的1501个行人的32217张图片。图片分辨率统一为128X64。每个行人至少由2个摄像头捕获到,并且在一个摄像头中可能具有多张图像。
训练集bounding_box_train有751人,包含12,936张图像,平均每个人有17.2张训练数据;
测试集bounding_box_test有750人,包含19,732张图像,平均每个人有26.3张测试数据;
查询集query有3368张查询图像。
该数据集提供的固定数量的训练集和测试集均可以在single-shot或multi-shot测试设置下使用。
参考文章行人重识别Market1501数据集介绍
三、训练
1、生成训练数据
MARK数据集下载解压后,文件分布如下:
准备训练数据需要通过prepare.py,将第五行的地址改为自己本地的地址
然后运行prepare.py文件,会生成一个pytorch文件夹
进入pytorch文件夹,文件分布如下:
现在我们已经成功准备好了图像来做后面的训练了。
2、开始训练
我们可以输入如下命令开始训练:
python train.py --gpu_ids 0 --name ft_ResNet50 --train_all --batchsize 32 --data_dir your_data_path
修改后
python train.py --gpu_ids 0 --name ft_ResNet50 --train_all --batchsize 32 --data_dir ./Market/pytorch/
默认训练60代,可修改train.py文件中默认参数
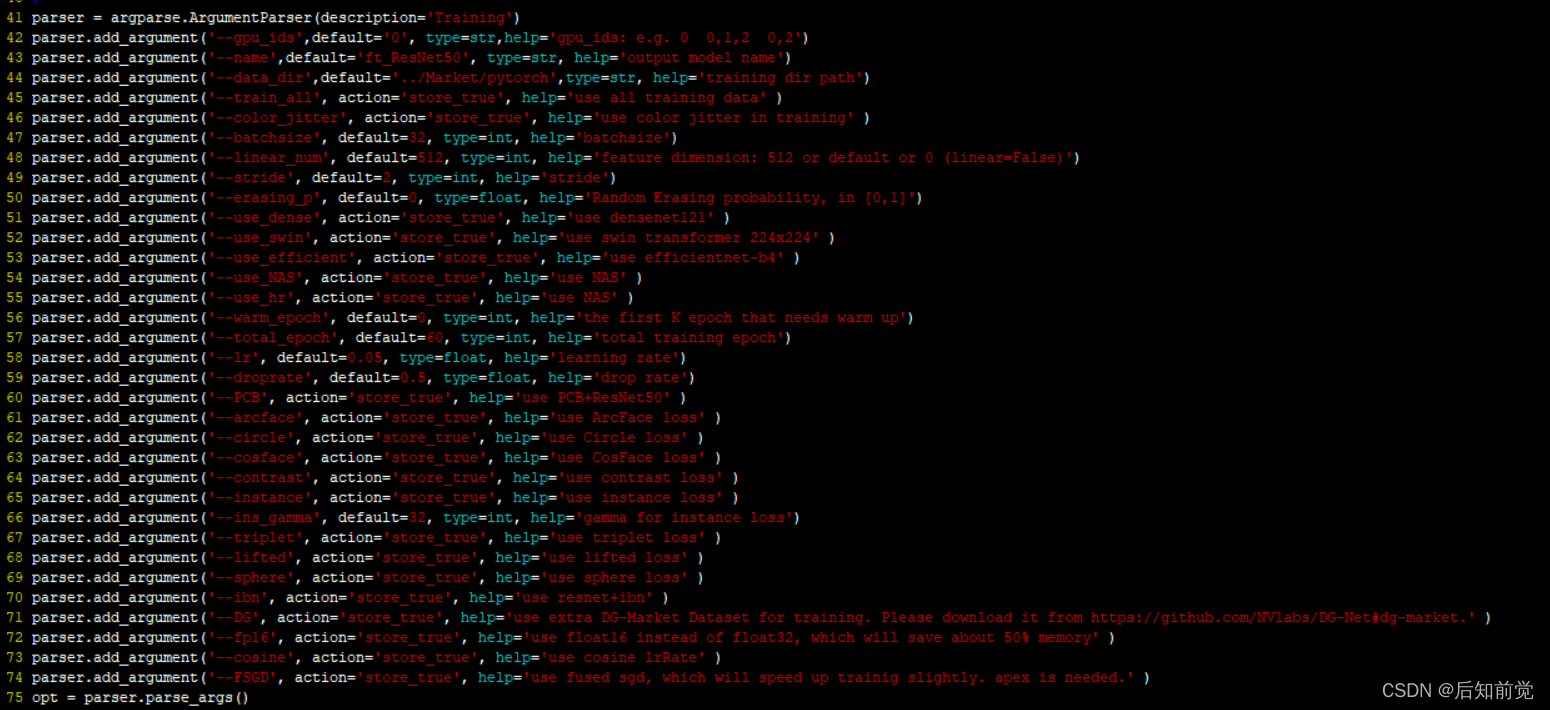
四、测试
1、特征提取
这一部分, 我们载入我们刚刚训练的模型 来抽取每张图片的视觉特征
python test.py --gpu_ids 0 --name ft_ResNet50 --test_dir your_data_path --batchsize 32 --which_epoch 59
修改后
python test.py --gpu_ids 0 --name ft_ResNet50 --test_dir ./Market/pytorch/ --batchsize 32 --which_epoch 59
–gpu_ids which gpu to run.
–name the dir name of the trained model.
–batchsize batch size.
–which_epoch select the i-th model.
–data_dir the path of the testing data.
2、评测
现在我们有了每张图片的特征。 我们需要做的事情只有用特征去匹配图像。
python evaluate_gpu.py
mAP:0.7

五、简单的可视化
可视化结果,
python demo.py --query_index 600

–query_index which query you want to test. You may select a number in the range of 0 ~ 3367.
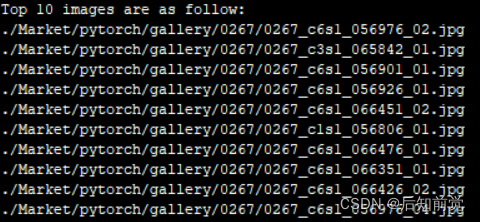
上图显示最相似的10张图片,可应用的场景很多。在实际人员轨迹应用中,可通过输出的摄像头编号,以及拍摄时间描述目标人员的行为轨迹。
六、总结
按照教程体验了一下reid_baseline,这个步骤比较简单,特记录一下,正在学习其他reid,希望后续能有所突破。