进程(process)和线程(thread)各种开发语言中常见的概念,对于代码的并发执行,提升代码效率和缩短运行时间至关重要。
进程是操作系统分配资源的最小单元, 线程是操作系统调度的最小单元。
一个应用程序至少包括1个进程,而1个进程包括1个或多个线程,线程的尺度更小。每个进程在执行过程中拥有独立的内存单元,而一个线程的多个线程在执行过程中共享内存。
一、多进程
要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识。
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
import os
print('Process (%s) start...' % os.getpid())
# Only works on Unix/Linux/Mac:
pid = os.fork()
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))
运行结果如下:
Process (876) start...
I (876) just created a child process (877).
I am child process (877) and my parent is 876.
由于Windows没有fork调用,上面的代码在Windows上无法运行。
有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
multiprocessing
Python中的多进程是通过multiprocessing包来实现的,和多线程的threading.Thread差不多,它可以利用multiprocessing.Process对象来创建一个进程对象。
标准库模块multiprocessing中提供了一个类对象Process,用于表示进程。
# coding: utf-8
import multiprocessing
from multiprocessing import Process, current_process
import time
def do_sth(arg1, arg2):
print('子进程启动(%d--%s)' % (current_process().pid, current_process().name))
print('arg1 = %d, arg2 = %d' % (arg1, arg2))
print('子进程结束(%d--%s)' % (current_process().pid, current_process().name))
if __name__ == '__main__':
print('父进程启动(%d--%s)' % (current_process().pid, current_process().name))
process = Process(target=do_sth, args=(5, 8)) # 根据类对象Process来创建进程
process.start()
process.join()# join等process子线程结束,主线程打印并且结束
print('父进程结束(%d--%s)' % (current_process().pid, current_process().name))
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
python多进程 也可以通过继承Process类来实现。
from multiprocessing import Process, current_process
import time
class MyProcess(Process):
def __init__(self, name, args):
super(MyProcess,self).__init__()
self.args = args
def run(self):
print('子进程启动(%d--%s)' % (current_process().pid, current_process().name))
print('arg1 = %d, arg2 = %d' % self.args)
print('子进程结束(%d--%s)' % (current_process().pid, current_process().name))
if __name__ == '__main__':
print('父进程启动(%d--%s)' % (current_process().pid, current_process().name))
mp = MyProcess(name='myprocess', args=(5, 8))
mp.start()
time.sleep(2)
print('父进程结束(%d--%s)' % (current_process().pid, current_process().name))
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool
import time, random
def do_sth(i):
print('子进程%d启动' % i)
start = time.time()
time.sleep(random.random() * 10)
end = time.time()
print('子进程%d结束,耗时%.2f秒' % (i, end - start))
if __name__ == '__main__':
print('父进程启动...')
pp = Pool(3) # 进程池最大的数量是3
for i in range(1, 11):
pp.apply_async(do_sth, args=(i,))
pp.close()
# 父进程将被阻塞,等子进程全部执行完成之后,父进程再继续执行
pp.join()
print('父进程结束')
代码解读:
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
二、多线程
threading
# coding: utf-8
import time, threading
from threading import current_thread, Thread
print('自动创建并启动了父(主)线程:%s' % threading.current_thread().getName())
# 自动创建并启动了父(主)线程:MainThread
#time.sleep(20)
print('父线程%s启动' % current_thread().getName())
def do_sth(arg1, arg2):
print('子线程%s启动' % current_thread().getName())
time.sleep(20)
print('arg1 = %d, arg2 = %d' % (arg1, arg2))
print('子线程%s结束' % current_thread().getName())
# process = Thread(target=do_sth, args=(5, 8), name='mythread')
process = Thread(target=do_sth, args=(5, 8))
process.start()
time.sleep(25)
print('父线程%s结束' % current_thread().getName())
自定义线程
继承threading.Thread来自定义线程类,其本质是重构Thread类中的run方法
# coding: utf-8
from threading import Thread, current_thread
import time
print('父线程%s启动' % current_thread().getName())
class MyThread(Thread):
def __init__(self, name, args):
super(MyThread, self).__init__(name=name)
self.args = args
def run(self):
print('子线程%s启动' % current_thread().getName())
time.sleep(20)
print('arg1 = %d, arg2 = %d' % self.args)
print('子线程%s结束' % current_thread().getName())
mt = MyThread(name='mythread', args=(5, 8))
mt.start()
time.sleep(25)
print('父线程%s线程' % current_thread().getName())
threadpool

# coding: utf-8
from threadpool import ThreadPool, makeRequests
import time, random
print('父线程启动')
args_list = []
for i in range(1, 11):
args_list.append(i)
def do_sth(i):
print('子线程%d启动' % i)
start = time.time()
time.sleep(random.random() * 10)
end = time.time()
print('子线程%d结束,耗时%.2f秒' % (i, end - start))
tp = ThreadPool(3)
requests = makeRequests(do_sth, args_list)
for req in requests:
tp.putRequest(req)
tp.wait()
print('父线程结束')
semaphore信号量

semaphore是一个内置的计数器。
每当调用acquire()时,内置计数器-1
每当调用release()时,内置计数器+1
计数器不能小于0,当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
import time
import threading
s1=threading.Semaphore(5)# 添加一个计数器
def foo():
s1.acquire() #计数器获得锁
time.sleep(2) #程序休眠2秒
print("ok",time.ctime())
s1.release() #计数器释放锁
for i in range(20):
t1=threading.Thread(target=foo,args=()) #创建线程
t1.start() #启动线程
# ----------使用with语句对代码进行简写-------------
from threading import Thread, Semaphore
import time, random
sem = Semaphore(3) # 最多同时3个线程可以执行,来限制一个时间点内的线程数量
class MyThread(Thread):
def run(self):
# sem.acquire()
with sem:
print('%s获得资源' % self.name)
time.sleep(random.random() * 10)
# sem.release()
for i in range(10):
MyThread().start()
三、全局解释锁 GIL
在进行GIL讲解之前,我们可以先介绍一下并行和并发的区别:
- 并行:多个CPU同时执行多个任务,就好像有两个程序,这两个程序是真的在两个不同的CPU内同时被执行
- 并发:CPU交替处理多个任务,还是有两个程序,但是只有一个CPU,会交替处理这两个程序,而不是同时执行,只不过因为CPU执行的速度过快,而会使得人们感到是在“同时”执行,执行的先后取决于各个程序对于时间片资源的争夺。
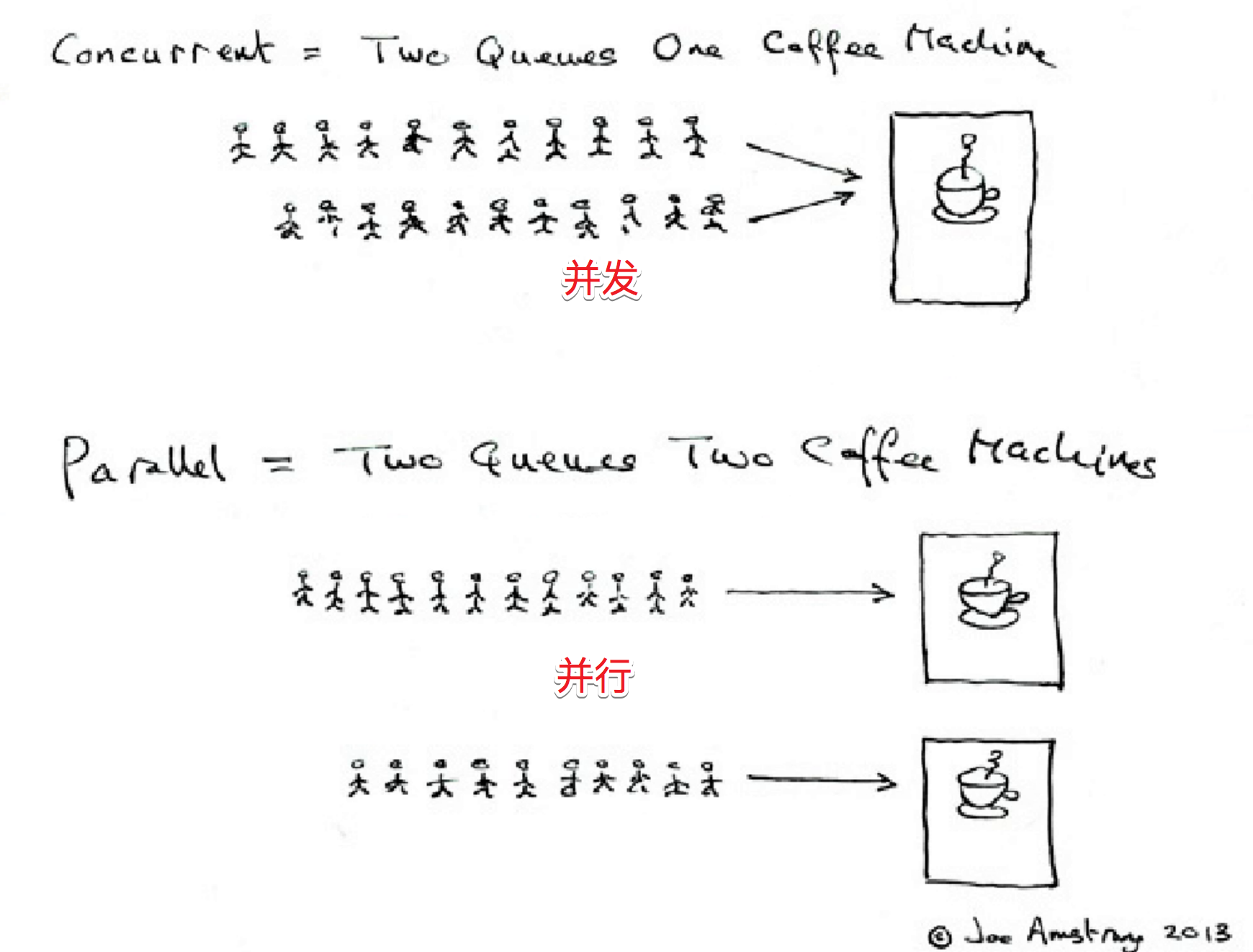
并行和并发同属于多任务,目的是要提高CPU的使用效率。
这里需要注意的是,一个CPU永远不可能实现并行,即一个CPU不能同时运行多个程序,但是可以在随机分配的时间片内交替执行(并发),就好像一个人不能同时看两本书,但是却能够先看第一本书半分钟,再看第二本书半分钟,这样来回切换。
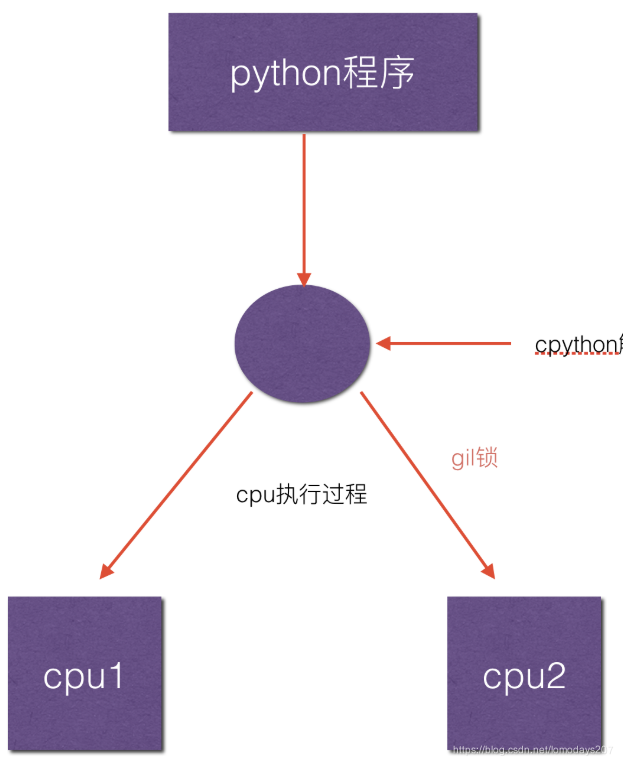
什么是GIL?
即全局解释器所(global interpreter lock),每个线程在执行时候都需要先获取GIL,保证同一时刻只有一个线程可以执行代码,即同一时刻只有一个线程使用CPU,也就是说多线程并不是真正意义上的同时执行。

四、进程通信方式
python提供了多种进程通信的方式,主要有队列Queue、Pipe、共享内存、Manager模块等
Queue用于多个进程间实现通信,Pipe是两个进程的通信
共享内存

from multiprocessing import Process, Value, Array
import ctypes
"""
共享数字、数组 进程之间的通信
"""
def do_sth(num, arr):
num.value = 1.8
for i in range(len(arr)):
arr[i] = -arr[i]
if __name__ == "__main__":
# num = Value('d', 2.3) 创建一个进程间共享的数字类型,默认值为2.3,d的类型为双精度小数
num = Value(ctypes.c_double, 2.3)
arr = Array('i', range(1, 5)) #创建一个进程间共享的数组类型,初始值为range[1, 5],i是指整型
# arr = Array(ctypes.c_int, range(1, 5))
p = Process(target=do_sth, args=(num, arr,))
p.start()
p.join() # 阻塞主线程
print(num.value)
print(arr[:])
#------------------------------------------------
import multiprocessing
def square_list(mylist, result, square_sum):
"""
function to square a given list
"""
# append squares of mylist to result array
for idx, num in enumerate(mylist):
result[idx] = num * num
# square_sum value
square_sum.value = sum(result)
# print result Array
print("Result(in process p1): {}".format(result[:]))
# print square_sum Value
print("Sum of squares(in process p1): {}".format(square_sum.value))
if __name__ == "__main__":
# input list
mylist = [1,2,3,4]
# creating Array of int data type with space for 4 integers
result = multiprocessing.Array('i', 4)
# creating Value of int data type
square_sum = multiprocessing.Value('i')
# creating new process
p1 = multiprocessing.Process(target=square_list, args=(mylist, result, square_sum))
# starting process
p1.start()
# wait until process is finished
p1.join()
# print result array
print("Result(in main program): {}".format(result[:]))
# print square_sum Value
print("Sum of squares(in main program): {}".format(square_sum.value))

Manager共享模块
与共享内存相比,Manager模块更加灵活,可以支持多种对象类型。
from multiprocessing import Process, Manager
def f(d,l):
d[1] = 18
d['2'] = 56
l.reverse()
if __name__ == '__main__':
manager = Manager()
d = manager.dict()
l = manager.list(range(5))
p = Process(target=f,args=(d,l))
p.start()
p.join()
print(d)
print(l)
# --------------------------------------------------------
# 共享字符串
from multiprocessing import Process, Manager
from ctypes import c_char_p
def greet(shareStr):
shareStr.value = shareStr.value + ", World!"
if __name__ == '__main__':
manager = Manager()
shareStr = manager.Value(c_char_p, "Hello") # 字符串共享
process = Process(target=greet, args=(shareStr,))
process.start()
process.join()
print(shareStr.value)
-------------------------------------------------
import multiprocessing
def print_records(records):
"""
function to print record(tuples) in records(list)
"""
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
"""
function to add a new record to records(list)
"""
records.append(record)
print("New record added!\n")
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
# creating a list in server process memory
records = manager.list([('Sam', 10), ('Adam', 9), ('Kevin',9)])
# new record to be inserted in records
new_record = ('Jeff', 8)
# creating new processes
p1 = multiprocessing.Process(target=insert_record, args=(new_record, records))
p2 = multiprocessing.Process(target=print_records, args=(records,))
# running process p1 to insert new record
p1.start()
p1.join()
# running process p2 to print records
p2.start()
p2.join()
New record added!
Name: Sam
Score: 10
Name: Adam
Score: 9
Name: Kevin
Score: 9
Name: Jeff
Score: 8

共享队列 Queue
import multiprocessing
def square_list(mylist, q):
"""
function to square a given list
"""
# append squares of mylist to queue
for num in mylist:
print("put num %s to list" %num)
q.put(num * num) #插入数据到队列
def print_queue(q):
"""
function to print queue elements
"""
print("Queue elements:")
while not q.empty():
print(q.get())
print("Queue is now empty!")
if __name__ == "__main__":
# input list
mylist = [1, 2, 3, 4]
# creating multiprocessing Queue
q = multiprocessing.Queue()
# creating new processes
p1 = multiprocessing.Process(target=square_list, args=(mylist, q))
p2 = multiprocessing.Process(target=print_queue, args=(q,))
# running process p1 to square list
p1.start()
p1.join()
# running process p2 to get queue elements
p2.start()
p2.join()
Given below is a simple diagram depicting the operations on queue:

Pipe通信机制
- Pipe常用于两个进程,两个进程分别位于管道的两端
- Pipe方法返回(conn1,conn2)代表一个管道的两个端,Pipe方法有duplex参数,默认为True,即全双工模式,若为FALSE,conn1只负责接收信息,conn2负责发送
- send和recv方法分别为发送和接收信息
import multiprocessing
def sender(conn, msgs):
"""
function to send messages to other end of pipe
"""
for msg in msgs:
conn.send(msg)
print("Sent the message: {}".format(msg))
conn.close()
def receiver(conn):
"""
function to print the messages received from other end of pipe
"""
while 1:
msg = conn.recv()
if msg == "END":
break
print("Received the message: {}".format(msg))
if __name__ == "__main__":
# messages to be sent
msgs = ["hello", "hey", "hru?", "END"]
# creating a pipe 返回一个元组,分别代表管道的两端
parent_conn, child_conn = multiprocessing.Pipe()
# creating new processes
p1 = multiprocessing.Process(target=sender, args=(parent_conn, msgs))
p2 = multiprocessing.Process(target=receiver, args=(child_conn,))
# running processes
p1.start()
p2.start()
# wait until processes finish
p1.join()
p2.join()

参考文档
https://www.cnblogs.com/luyuze95/p/11289143.html
https://www.geeksforgeeks.org/multithreading-python-set-1/
