2023年的深度学习入门指南(10) - CUDA编程基础
上一篇我们走马观花地看了下SIMD和GPGPU的编程。不过线条太粗了,在开发大模型时遇到问题了肯定还会晕。
所以我们还是需要深入到CUDA中去探险一下。
获取CUDA设备信息
在使用CUDA设备之前,首先我们得获取是否支持CUDA,有几个设备。这个可以通过cudaGetDeviceCount
int deviceCount;
cudaError_t cudaError;
cudaError = cudaGetDeviceCount(&deviceCount);
if (cudaError == cudaSuccess) {
cout << "There are " << deviceCount << " cuda devices." << endl;
}
获取了支持多少个设备了之后,我们就可以遍历设备去用cudaGetDeviceProperties函数去查看设备信息了。
for (int i = 0; i < deviceCount; i++)
{
cudaError = cudaGetDeviceProperties(&props, i);
if (cudaError == cudaSuccess) {
cout << "Device Name: " << props.name << endl;
cout << "Compute Capability version: " << props.major << "." << props.minor << endl;
}
}
这是我在我的电脑上输出的结果:
There are 1 cuda devices.
Device Name: NVIDIA GeForce RTX 3060
Compute Capability version: 8.6
struct cudaDeviceProp {
char name[256];
cudaUUID_t uuid;
size_t totalGlobalMem;
size_t sharedMemPerBlock;
int regsPerBlock;
int warpSize;
size_t memPitch;
int maxThreadsPerBlock;
int maxThreadsDim[3];
int maxGridSize[3];
int clockRate;
size_t totalConstMem;
int major;
int minor;
size_t textureAlignment;
size_t texturePitchAlignment;
int deviceOverlap;
int multiProcessorCount;
int kernelExecTimeoutEnabled;
int integrated;
int canMapHostMemory;
int computeMode;
int maxTexture1D;
int maxTexture1DMipmap;
int maxTexture1DLinear;
int maxTexture2D[2];
int maxTexture2DMipmap[2];
int maxTexture2DLinear[3];
int maxTexture2DGather[2];
int maxTexture3D[3];
int maxTexture3DAlt[3];
int maxTextureCubemap;
int maxTexture1DLayered[2];
int maxTexture2DLayered[3];
int maxTextureCubemapLayered[2];
int maxSurface1D;
int maxSurface2D[2];
int maxSurface3D[3];
int maxSurface1DLayered[2];
int maxSurface2DLayered[3];
int maxSurfaceCubemap;
int maxSurfaceCubemapLayered[2];
size_t surfaceAlignment;
int concurrentKernels;
int ECCEnabled;
int pciBusID;
int pciDeviceID;
int pciDomainID;
int tccDriver;
int asyncEngineCount;
int unifiedAddressing;
int memoryClockRate;
int memoryBusWidth;
int l2CacheSize;
int persistingL2CacheMaxSize;
int maxThreadsPerMultiProcessor;
int streamPrioritiesSupported;
int globalL1CacheSupported;
int localL1CacheSupported;
size_t sharedMemPerMultiprocessor;
int regsPerMultiprocessor;
int managedMemory;
int isMultiGpuBoard;
int multiGpuBoardGroupID;
int singleToDoublePrecisionPerfRatio;
int pageableMemoryAccess;
int concurrentManagedAccess;
int computePreemptionSupported;
int canUseHostPointerForRegisteredMem;
int cooperativeLaunch;
int cooperativeMultiDeviceLaunch;
int pageableMemoryAccessUsesHostPageTables;
int directManagedMemAccessFromHost;
int accessPolicyMaxWindowSize;
}
我们择其要者介绍几个吧:
- totalGlobalMem是设备上可用的全局内存总量,以字节为单位。
- sharedMemPerBlock是一个线程块可用的最大共享内存量,以字节为单位。
- regsPerBlock是一个线程块可用的最大32位寄存器数量。
- warpSize是线程束的大小,以线程为单位。
- memPitch是涉及通过cudaMallocPitch()分配的内存区域的内存复制函数允许的最大间距,以字节为单位。
- maxThreadsPerBlock是每个块的最大线程数。
- maxThreadsDim[3]包含了一个块的每个维度的最大尺寸。
- maxGridSize[3]包含了一个网格的每个维度的最大尺寸。
- clockRate是时钟频率,以千赫为单位。
- totalConstMem是设备上可用的常量内存总量,以字节为单位。
- major, minor是定义设备计算能力的主要和次要修订号。
- multiProcessorCount是设备上多处理器的数量。
- memoryClockRate是峰值内存时钟频率,以千赫为单位。
- memoryBusWidth是内存总线宽度,以位为单位。
- memoryPoolsSupported 是 1,如果设备支持使用 cudaMallocAsync 和 cudaMemPool 系列 API,否则为 0
- gpuDirectRDMASupported 是 1,如果设备支持 GPUDirect RDMA API,否则为 0
- gpuDirectRDMAFlushWritesOptions 是一个按照 cudaFlushGPUDirectRDMAWritesOptions 枚举解释的位掩码
- gpuDirectRDMAWritesOrdering 参见 cudaGPUDirectRDMAWritesOrdering 枚举的数值
- memoryPoolSupportedHandleTypes 是一个支持与 mempool-based IPC 的句柄类型的位掩码
- deferredMappingCudaArraySupported 是 1,如果设备支持延迟映射 CUDA 数组和 CUDA mipmapped 数组
- ipcEventSupported 是 1,如果设备支持 IPC 事件,否则为 0
- unifiedFunctionPointers 是 1,如果设备支持统一指针,否则为 0
有了更多的信息,我们输出一些看看:
for (int i = 0; i < deviceCount; i++)
{
cudaError = cudaGetDeviceProperties(&props, i);
if (cudaError == cudaSuccess) {
cout << "Device Name: " << props.name << endl;
cout << "Compute Capability version: " << props.major << "." << props.minor << endl;
cout << "设备上可用的全局内存总量:(G字节)" << props.totalGlobalMem / 1024 / 1024 / 1024 << endl;
cout << "时钟频率(以MHz为单位):" << props.clockRate / 1000 << endl;
cout << "设备上多处理器的数量:" << props.multiProcessorCount << endl;
cout << "每个块的最大线程数:" << props.maxThreadsPerBlock <<endl;
cout << "内存总线宽度(位)" << props.memoryBusWidth << endl;
cout << "一个块的每个维度的最大尺寸:" << props.maxThreadsDim[0] << ","<< props.maxThreadsDim[1] << "," << props.maxThreadsDim[2] << endl;
cout << "一个网格的每个维度的最大尺寸:" << props.maxGridSize[0] << "," << props.maxGridSize[1] << "," << props.maxGridSize[2] <<endl;
}
}
在我的3060显卡上运行的结果:
Device Name: NVIDIA GeForce RTX 3060
Compute Capability version: 8.6
设备上可用的全局内存总量:(G字节)11
时钟频率(以MHz为单位):1777
设备上多处理器的数量:28
每个块的最大线程数:1024
内存总线宽度(位)192
一个块的每个维度的最大尺寸:1024,1024,64
一个网格的每个维度的最大尺寸:2147483647,65535,65535
线程块和线程网格
在CUDA中,线程块(block)和线程网格(grid)是两个非常重要的概念,它们用于描述GPU执行并行任务时的线程组织方式。线程块是由若干个线程(thread)组成的,它们可以在同一个GPU多处理器(multiprocessor)上并行执行。线程网格则是由若干个线程块组成的,它们可以在整个GPU设备上并行执行。每个线程块和线程网格都有一个唯一的索引,用于在CUDA C/C++的GPU核函数中对线程进行标识和控制。
在CUDA中,使用dim3结构体来表示线程块和线程网格的维度。例如,dim3(2,2)表示一个2D线程网格,其中有2x2=4个线程块;dim3(2,2,2)表示一个3D线程块,其中有2x2x2=8个线程。在启动GPU核函数时,可以使用<<< >>>的语法来指定线程网格和线程块的大小,例如:
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 2);
myKernel<<<dimGrid, dimBlock>>>(...);
这里使用dimGrid和dimBlock指定了线程网格和线程块的大小,然后调用myKernel函数,并传递必要的参数。在执行GPU核函数时,CUDA会按照指定的线程网格和线程块的大小启动对应的线程,并对它们进行分配和协作,从而完成任务的并行执行。线程块和线程网格的组织方式和大小都可以根据具体的应用场景和硬件环境进行调整和优化,以实现最优的性能和效率。
我们再看下在核函数中如何使用线程网格和线程块。
__global__ void testKernel(int val) {
printf("[%d, %d]:\t\tValue is:%d\n", blockIdx.y * gridDim.x + blockIdx.x,
threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x,
val);
}
上面有几个点我们需要解释一下:
__global__:并不是表明这是一个全局函数,而是表明这是一个GPU核函数。- blockIdx:是一个内置的变量,表示当前线程所在的块(block)的索引。它是一个结构体类型,包含了三个成员变量,分别表示当前块在x、y、z三个维度上的索引值。
- threadIdx:也是一个内置的变量,表示当前线程在所在的块中的索引。它也同样是一个结构体类型,包含了三个成员变量,分别表示当前线程在x、y、z三个维度上的索引值。
- blockDim:同样是一个内置的变量,表示每个块(block)的维度(dimension),包括x、y、z三个维度。
在CUDA中,每个核函数(kernel function)被分配到一个或多个块(block)中执行,每个块包含若干个线程(thread),它们可以在GPU上并行执行。通过访问blockIdx的成员变量,可以确定当前线程所在的块在哪个位置,从而在核函数中进行特定的计算。例如,可以使用blockIdx.x表示当前线程所在的块在x轴上的索引值。在CUDA编程中,通常需要使用blockIdx和threadIdx来确定每个线程在整个GPU并行执行中的唯一标识,以便进行任务的分配和协作。
然后将dimGrid和dimBlock传给testKernel.
// Kernel configuration, where a two-dimensional grid and
// three-dimensional blocks are configured.
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 2);
testKernel << <dimGrid, dimBlock >> > (10);
将下面的文件保存为kernel.cu,然后通过nvcc命令编译,最后运行生成的可执行文件就可以了。
// System includes
#include <stdio.h>
#include <assert.h>
#include <iostream>
// CUDA runtime
#include <cuda_runtime.h>
using namespace std;
__global__ void testKernel(int val) {
printf("[%d, %d]:\t\tValue is:%d\n", blockIdx.y * gridDim.x + blockIdx.x,
threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x,
val);
}
int main(int argc, char** argv) {
int devID;
cudaDeviceProp props;
int deviceCount;
cudaError_t cudaError;
cudaError = cudaGetDeviceCount(&deviceCount);
if (cudaError == cudaSuccess) {
cout << "There are " << deviceCount << " cuda devices." << endl;
}
for (int i = 0; i < deviceCount; i++)
{
cudaError = cudaGetDeviceProperties(&props, i);
if (cudaError == cudaSuccess) {
cout << "Device Name: " << props.name << endl;
cout << "Compute Capability version: " << props.major << "." << props.minor << endl;
cout << "设备上可用的全局内存总量:(G字节)" << props.totalGlobalMem / 1024 / 1024 / 1024 << endl;
cout << "时钟频率(以MHz为单位):" << props.clockRate / 1000 << endl;
cout << "设备上多处理器的数量:" << props.multiProcessorCount << endl;
cout << "每个块的最大线程数:" << props.maxThreadsPerBlock <<endl;
cout << "内存总线宽度(位)" << props.memoryBusWidth << endl;
cout << "一个块的每个维度的最大尺寸:" << props.maxThreadsDim[0] << ","<< props.maxThreadsDim[1] << "," << props.maxThreadsDim[2] << endl;
cout << "一个网格的每个维度的最大尺寸:" << props.maxGridSize[0] << "," << props.maxGridSize[1] << "," << props.maxGridSize[2] <<endl;
}
}
// Kernel configuration, where a two-dimensional grid and
// three-dimensional blocks are configured.
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 2);
testKernel << <dimGrid, dimBlock >> > (10);
cudaDeviceSynchronize();
return EXIT_SUCCESS;
}
前面输出的不管,我们只看后面32个线程的结果:
[1, 0]: Value is:10
[1, 1]: Value is:10
[1, 2]: Value is:10
[1, 3]: Value is:10
[1, 4]: Value is:10
[1, 5]: Value is:10
[1, 6]: Value is:10
[1, 7]: Value is:10
[0, 0]: Value is:10
[0, 1]: Value is:10
[0, 2]: Value is:10
[0, 3]: Value is:10
[0, 4]: Value is:10
[0, 5]: Value is:10
[0, 6]: Value is:10
[0, 7]: Value is:10
[3, 0]: Value is:10
[3, 1]: Value is:10
[3, 2]: Value is:10
[3, 3]: Value is:10
[3, 4]: Value is:10
[3, 5]: Value is:10
[3, 6]: Value is:10
[3, 7]: Value is:10
[2, 0]: Value is:10
[2, 1]: Value is:10
[2, 2]: Value is:10
[2, 3]: Value is:10
[2, 4]: Value is:10
[2, 5]: Value is:10
[2, 6]: Value is:10
[2, 7]: Value is:10
前面表示线程块,后面表示线程。
大家第一次搞GPU编程的话很容易被绕晕。我来解释一下这个计算方法。其实就是跟用一维数组来模拟多维数组是一个算法。
blockIdx.y * gridDim.x + blockIdx.x表示当前线程所在的线程块在二维线程网格中的唯一标识。其中,gridDim.x表示线程网格在x方向上的线程块数量,blockIdx.x表示当前线程块在x方向上的索引值,blockIdx.y表示当前线程块在y方向上的索引值。
threadIdx.z * blockDim.x * blockDim.y表示当前线程在z方向上的偏移量,即前面所有线程所占用的空间大小。然后,threadIdx.y * blockDim.x表示当前线程在y方向上的偏移量,即当前线程在所在z平面上的偏移量。最后,threadIdx.x表示当前线程在x方向上的偏移量,即当前线程在所在z平面的某一行上的偏移量。
明白这一点之后,我们尝试将每个线程块从8个线程改成12个:
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 3);
testKernel << <dimGrid, dimBlock >> > (12);
运行结果如下:
[0, 0]: Value is:12
[0, 1]: Value is:12
[0, 2]: Value is:12
[0, 3]: Value is:12
[0, 4]: Value is:12
[0, 5]: Value is:12
[0, 6]: Value is:12
[0, 7]: Value is:12
[0, 8]: Value is:12
[0, 9]: Value is:12
[0, 10]: Value is:12
[0, 11]: Value is:12
[1, 0]: Value is:12
[1, 1]: Value is:12
[1, 2]: Value is:12
[1, 3]: Value is:12
[1, 4]: Value is:12
[1, 5]: Value is:12
[1, 6]: Value is:12
[1, 7]: Value is:12
[1, 8]: Value is:12
[1, 9]: Value is:12
[1, 10]: Value is:12
[1, 11]: Value is:12
[3, 0]: Value is:12
[3, 1]: Value is:12
[3, 2]: Value is:12
[3, 3]: Value is:12
[3, 4]: Value is:12
[3, 5]: Value is:12
[3, 6]: Value is:12
[3, 7]: Value is:12
[3, 8]: Value is:12
[3, 9]: Value is:12
[3, 10]: Value is:12
[3, 11]: Value is:12
[2, 0]: Value is:12
[2, 1]: Value is:12
[2, 2]: Value is:12
[2, 3]: Value is:12
[2, 4]: Value is:12
[2, 5]: Value is:12
[2, 6]: Value is:12
[2, 7]: Value is:12
[2, 8]: Value is:12
[2, 9]: Value is:12
[2, 10]: Value is:12
[2, 11]: Value is:12
下面我们正式开启真并发之旅,在上面的48个线程里同时计算正弦。
在GPU里计算,我们CPU上原来的数学库不顶用了,我们要用GPU自己的,在CUDA中我们用__sinf:
__global__ void testKernel(float val) {
printf("[%d, %d]:\t\tValue is:%f\n", blockIdx.y * gridDim.x + blockIdx.x,
threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x,
__sinf(val* threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x));
}
main函数里也随便改一个:
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 3);
testKernel << <dimGrid, dimBlock >> > (0.5);
运行结果如下:
[0, 0]: Value is:0.000000
[0, 1]: Value is:0.841471
[0, 2]: Value is:0.909297
[0, 3]: Value is:0.141120
[0, 4]: Value is:0.909297
[0, 5]: Value is:0.141120
[0, 6]: Value is:-0.756802
[0, 7]: Value is:-0.958924
[0, 8]: Value is:-0.756802
[0, 9]: Value is:-0.958924
[0, 10]: Value is:-0.279416
[0, 11]: Value is:0.656986
[1, 0]: Value is:0.000000
[1, 1]: Value is:0.841471
[1, 2]: Value is:0.909297
[1, 3]: Value is:0.141120
[1, 4]: Value is:0.909297
[1, 5]: Value is:0.141120
[1, 6]: Value is:-0.756802
[1, 7]: Value is:-0.958924
[1, 8]: Value is:-0.756802
[1, 9]: Value is:-0.958924
[1, 10]: Value is:-0.279416
[1, 11]: Value is:0.656986
[3, 0]: Value is:0.000000
[3, 1]: Value is:0.841471
[3, 2]: Value is:0.909297
[3, 3]: Value is:0.141120
[3, 4]: Value is:0.909297
[3, 5]: Value is:0.141120
[3, 6]: Value is:-0.756802
[3, 7]: Value is:-0.958924
[3, 8]: Value is:-0.756802
[3, 9]: Value is:-0.958924
[3, 10]: Value is:-0.279416
[3, 11]: Value is:0.656986
[2, 0]: Value is:0.000000
[2, 1]: Value is:0.841471
[2, 2]: Value is:0.909297
[2, 3]: Value is:0.141120
[2, 4]: Value is:0.909297
[2, 5]: Value is:0.141120
[2, 6]: Value is:-0.756802
[2, 7]: Value is:-0.958924
[2, 8]: Value is:-0.756802
[2, 9]: Value is:-0.958924
[2, 10]: Value is:-0.279416
[2, 11]: Value is:0.656986
内存与显存间的数据交换
上面我们是传了一个立即数到GPU核函数。我们距离正式能使用GPU进行CUDA编程,就差分配GPU显存和在显存和内存之间复制了。
同malloc类似,CUDA使用cudaMalloc来分配GPU内存,其原型为:
cudaError_t cudaMalloc(void **devPtr, size_t size);
参数解释:
- devPtr: 返回分配的设备内存的指针。
- size: 要分配的内存大小,以字节为单位。
返回值:
- cudaSuccess: 分配成功。
- cudaErrorInvalidValue: size为零或devPtr为NULL。
- cudaErrorMemoryAllocation: 内存分配失败。
一般的用法,记得用完了用cudaFree释放掉:
float* devPtr;
cudaMalloc(&devPtr, size * sizeof(float));
...
cudaFree(devPtr);
分配完内存了,然后就是从内存复制到显存了。同样类似于memcpy,通过cudaMemcpy来完成。
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind);
参数解释:
- dst: 目标内存的指针。
- src: 源内存的指针。
- count: 要拷贝的内存大小,以字节为单位。
- kind: 拷贝的类型,可以是:
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
返回值:
- cudaSuccess: 拷贝成功。
- cudaErrorInvalidValue: count或dst或src为NULL。
- cudaErrorMemoryAllocation: 内存分配失败。
下面我们来写一个用CUDA计算平方根的例子:
const int n = 1024;
size_t size = n * sizeof(float);
float* h_in = (float*)malloc(size);
float* h_out = (float*)malloc(size);
float* d_in, * d_out;
// Initialize input array
for (int i = 0; i < n; ++i) {
h_in[i] = (float)i;
}
// Allocate device memory
cudaMalloc(&d_in, size);
cudaMalloc(&d_out, size);
// Copy input data to device
cudaMemcpy(d_in, h_in, size, cudaMemcpyHostToDevice);
// Launch kernel
int threadsPerBlock = 256;
int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
sqrtKernel << <blocksPerGrid, threadsPerBlock >> > (d_in, d_out, n);
// Copy output data to host
cudaMemcpy(h_out, d_out, size, cudaMemcpyDeviceToHost);
// Verify results
for (int i = 0; i < n; ++i) {
if (fabsf(h_out[i] - sqrtf(h_in[i])) > 1e-5) {
printf("Error: h_out[%d] = %f, sqrtf(h_in[%d]) = %f\n", i, h_out[i], i, sqrtf(h_in[i]));
}
}
printf("Success!\n");
// Free memory
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
大家关注线程块数和线程数这两个,我们这里没有用多维,就是用两个整数计算的:
int threadsPerBlock = 256;
int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
sqrtKernel << <blocksPerGrid, threadsPerBlock >> > (d_in, d_out, n);
我们用4个块,每个块有256个线程。
此时,就不用计算y和z了,只计算x维度就可以:
int i = blockIdx.x * blockDim.x + threadIdx.x;
但是要注意,blockIdx和threadIdx仍然是三维的,y和z维仍然是有效的,只不过它们变成0了。
我们的核函数这样写:
__global__ void sqrtKernel(float* in, float* out, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
out[i] = sqrtf(in[i]);
printf("[%d, %d]:\t\tValue is:%f\n", blockIdx.y * gridDim.x + blockIdx.x,
threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x, out[i]);
}
}
当然了,因为block和thread的y和z都是0,跟只写x是没啥区别的:
__global__ void sqrtKernel(float* in, float* out, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
out[i] = sqrtf(in[i]);
printf("[%d, %d]:\t\tValue is:%f\n", blockIdx.x, threadIdx.x, out[i]);
}
}
使用封装好的库
除了CUDA运行时之外,针对主要的应用场景,NVidia也提供了很多专门的库。
比如针对矩阵运算,就有cuBLAS库。有的库是跟随CUDA工具包一起安装的,比如cuBLAS, cuFFT。也有的库需要专门下载安装,比如cudnn库。
这里强调一下,所谓的库,不是在核函数中要调用的模块,而是将整个需要在核函数里面要实现的功能全封装好了。所以在使用封装库的时候,并不需要nvcc,就是引用一个库就好了。
我们来看一个使用cuBLAS库来计算矩阵乘法的例子。
cuBLAS库来计算矩阵乘法要用到的主要的函数有4个:
- cublasCreate: 创建cublas句柄
- cublasDestroy:释放cublas句柄
- cublasSetVector:在CPU和GPU内存间复制数据
- cublasSgemm:矩阵乘法运算
cublasStatus_t cublasSetVector(int n, int elemSize, const void *x, int incx, void *y, int incy)
其中:
- n 是要拷贝的元素个数
- elemSize是每个元素的大小(以字节为单位)
- x是主机端(CPU)内存中的数据起始地址
- incx是x中相邻元素之间的跨度
- y是GPU设备内存中的数据起始地址
- incy是y中相邻元素之间的跨度
cublasStatus_t cublasSgemm(cublasHandle_t handle,
cublasOperation_t transa, cublasOperation_t transb,
int m, int n, int k,
const float *alpha, const float *A, int lda,
const float *B, int ldb, const float *beta,
float *C, int ldc)
其中:
- handle是cuBLAS句柄;
- transa是A矩阵的转置选项,取值为CUBLAS_OP_N或CUBLAS_OP_T,分别表示不转置和转置;
- transb是B矩阵的转置选项;m、n、k分别是A、B、C矩阵的维度;
- alpha是一个标量值,用于将A和B矩阵的乘积缩放到C矩阵中;
- A是A矩阵的起始地址;
- lda是A矩阵中相邻列之间的跨度;
- B是B矩阵的起始地址;
- ldb是B矩阵中相邻列之间的跨度;
- beta是一个标量值,用于将C矩阵中的值缩放;
- C是C矩阵的起始地址;
- ldc是C矩阵中相邻列之间的跨度。
我们简化写一个例子,主要说明函数的用法:
#include <stdio.h>
#include <cuda_runtime.h>
#include <cublas_v2.h>
int main() {
int m = 1024, n = 1024, k = 1024;
float* h_A = (float*)malloc(m * k * sizeof(float));
float* h_B = (float*)malloc(k * n * sizeof(float));
float* h_C = (float*)malloc(m * n * sizeof(float));
for (int i = 0; i < m * k; ++i) {
h_A[i] = (float)i;
}
for (int i = 0; i < k * n; ++i) {
h_B[i] = (float)i;
}
float* d_A, * d_B, * d_C;
cudaMalloc(&d_A, m * k * sizeof(float));
cudaMalloc(&d_B, k * n * sizeof(float));
cudaMalloc(&d_C, m * n * sizeof(float));
// Copy data from host to device
cublasSetVector(m * k, sizeof(float), h_A, 1, d_A, 1);
cublasSetVector(k * n, sizeof(float), h_B, 1, d_B, 1);
// Initialize cuBLAS
cublasHandle_t handle;
cublasCreate(&handle);
// Do matrix multiplication
const float alpha = 1.0f, beta = 0.0f;
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, m, n, k,
&alpha, d_A, m, d_B, k, &beta, d_C, m);
// Copy data from device to host
cublasGetVector(m * n, sizeof(float), d_C, 1, h_C, 1);
// Free memory
free(h_A);
free(h_B);
free(h_C);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Destroy cuBLAS handle
cublasDestroy(handle);
return 0;
}
当然,上面的只是个例子,没有做错误处理,这样是不对的。
我们参考官方的例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/* Includes, cuda */
#include <cublas_v2.h>
#include <cuda_runtime.h>
#include <helper_cuda.h>
/* Matrix size */
#define N (275)
/* Host implementation of a simple version of sgemm */
static void simple_sgemm(int n, float alpha, const float *A, const float *B,
float beta, float *C) {
int i;
int j;
int k;
for (i = 0; i < n; ++i) {
for (j = 0; j < n; ++j) {
float prod = 0;
for (k = 0; k < n; ++k) {
prod += A[k * n + i] * B[j * n + k];
}
C[j * n + i] = alpha * prod + beta * C[j * n + i];
}
}
}
/* Main */
int main(int argc, char **argv) {
cublasStatus_t status;
float *h_A;
float *h_B;
float *h_C;
float *h_C_ref;
float *d_A = 0;
float *d_B = 0;
float *d_C = 0;
float alpha = 1.0f;
float beta = 0.0f;
int n2 = N * N;
int i;
float error_norm;
float ref_norm;
float diff;
cublasHandle_t handle;
/* Initialize CUBLAS */
printf("simpleCUBLAS test running..\n");
status = cublasCreate(&handle);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! CUBLAS initialization error\n");
return EXIT_FAILURE;
}
/* Allocate host memory for the matrices */
h_A = reinterpret_cast<float *>(malloc(n2 * sizeof(h_A[0])));
if (h_A == 0) {
fprintf(stderr, "!!!! host memory allocation error (A)\n");
return EXIT_FAILURE;
}
h_B = reinterpret_cast<float *>(malloc(n2 * sizeof(h_B[0])));
if (h_B == 0) {
fprintf(stderr, "!!!! host memory allocation error (B)\n");
return EXIT_FAILURE;
}
h_C = reinterpret_cast<float *>(malloc(n2 * sizeof(h_C[0])));
if (h_C == 0) {
fprintf(stderr, "!!!! host memory allocation error (C)\n");
return EXIT_FAILURE;
}
/* Fill the matrices with test data */
for (i = 0; i < n2; i++) {
h_A[i] = rand() / static_cast<float>(RAND_MAX);
h_B[i] = rand() / static_cast<float>(RAND_MAX);
h_C[i] = rand() / static_cast<float>(RAND_MAX);
}
/* Allocate device memory for the matrices */
if (cudaMalloc(reinterpret_cast<void **>(&d_A), n2 * sizeof(d_A[0])) !=
cudaSuccess) {
fprintf(stderr, "!!!! device memory allocation error (allocate A)\n");
return EXIT_FAILURE;
}
if (cudaMalloc(reinterpret_cast<void **>(&d_B), n2 * sizeof(d_B[0])) !=
cudaSuccess) {
fprintf(stderr, "!!!! device memory allocation error (allocate B)\n");
return EXIT_FAILURE;
}
if (cudaMalloc(reinterpret_cast<void **>(&d_C), n2 * sizeof(d_C[0])) !=
cudaSuccess) {
fprintf(stderr, "!!!! device memory allocation error (allocate C)\n");
return EXIT_FAILURE;
}
/* Initialize the device matrices with the host matrices */
status = cublasSetVector(n2, sizeof(h_A[0]), h_A, 1, d_A, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (write A)\n");
return EXIT_FAILURE;
}
status = cublasSetVector(n2, sizeof(h_B[0]), h_B, 1, d_B, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (write B)\n");
return EXIT_FAILURE;
}
status = cublasSetVector(n2, sizeof(h_C[0]), h_C, 1, d_C, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (write C)\n");
return EXIT_FAILURE;
}
/* Performs operation using plain C code */
simple_sgemm(N, alpha, h_A, h_B, beta, h_C);
h_C_ref = h_C;
/* Performs operation using cublas */
status = cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N, &alpha, d_A,
N, d_B, N, &beta, d_C, N);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! kernel execution error.\n");
return EXIT_FAILURE;
}
/* Allocate host memory for reading back the result from device memory */
h_C = reinterpret_cast<float *>(malloc(n2 * sizeof(h_C[0])));
if (h_C == 0) {
fprintf(stderr, "!!!! host memory allocation error (C)\n");
return EXIT_FAILURE;
}
/* Read the result back */
status = cublasGetVector(n2, sizeof(h_C[0]), d_C, 1, h_C, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (read C)\n");
return EXIT_FAILURE;
}
/* Check result against reference */
error_norm = 0;
ref_norm = 0;
for (i = 0; i < n2; ++i) {
diff = h_C_ref[i] - h_C[i];
error_norm += diff * diff;
ref_norm += h_C_ref[i] * h_C_ref[i];
}
error_norm = static_cast<float>(sqrt(static_cast<double>(error_norm)));
ref_norm = static_cast<float>(sqrt(static_cast<double>(ref_norm)));
if (fabs(ref_norm) < 1e-7) {
fprintf(stderr, "!!!! reference norm is 0\n");
return EXIT_FAILURE;
}
/* Memory clean up */
free(h_A);
free(h_B);
free(h_C);
free(h_C_ref);
if (cudaFree(d_A) != cudaSuccess) {
fprintf(stderr, "!!!! memory free error (A)\n");
return EXIT_FAILURE;
}
if (cudaFree(d_B) != cudaSuccess) {
fprintf(stderr, "!!!! memory free error (B)\n");
return EXIT_FAILURE;
}
if (cudaFree(d_C) != cudaSuccess) {
fprintf(stderr, "!!!! memory free error (C)\n");
return EXIT_FAILURE;
}
/* Shutdown */
status = cublasDestroy(handle);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! shutdown error (A)\n");
return EXIT_FAILURE;
}
if (error_norm / ref_norm < 1e-6f) {
printf("simpleCUBLAS test passed.\n");
exit(EXIT_SUCCESS);
} else {
printf("simpleCUBLAS test failed.\n");
exit(EXIT_FAILURE);
}
}
一些更高级的特性
有了上面的基础,我们就可以写一些可以运行在GPU上的代码了。
结束之前,我们再看几个稍微高级一点的特性。
__device__关键字
之前我们学习核函数的__global__关键字。核函数既可以被CPU端调用,也可以被GPU调用。
如果我们想编写只能在GPU上运行的函数,我们就可以使用__device__.
使用__device__定义的函数或变量只能在设备代码中使用,无法在主机端代码中使用。在CUDA程序中,通常使用__host__和__device__关键字来指定函数或变量在主机端和设备端的执行位置。使用__device__定义的函数或变量可以在设备代码中被其他函数调用,也可以在主机端使用CUDA API将数据从主机内存传输到设备内存后,由设备上的函数处理。
GPU函数的内联
与CPU函数一样,GPU上的函数也可以内联,使用__forceinline__关键字。
并发的"?:"三目运算符
在C语言中,"?:"三目运算符只能做一次判断。
现在来到了GPU的世界,并发能力变强了,可以做多次判断了。
我们来看个例子:
__device__ __forceinline__ int qcompare(unsigned &val1, unsigned &val2) {
return (val1 > val2) ? 1 : (val1 == val2) ? 0 : -1;
}
PTX汇编
在上一篇我们学习SIMD指令的时候,我们基本都要内联汇编。那么在CUDA里面是不是有汇编呢?
答案是肯定的,既然要做性能优化,那么肯定要挖掘一切潜力。
不过,为了避免跟架构过于相关,NVidia给我们提供的是一种中间指令格式PTX(Parallel Thread Execution)。
PTX assembly是CUDA的一种中间汇编语言,它是一种与机器无关的指令集架构(ISA),用于描述GPU上的并行线程执行。PTX assembly可以被编译成特定GPU家族的实际执行的机器码。使用PTX assembly可以实现跨GPU的兼容性和性能优化。
我们来看一段内嵌汇编:
static __device__ __forceinline__ unsigned int __qsflo(unsigned int word) {
unsigned int ret;
asm volatile("bfind.u32 %0, %1;" : "=r"(ret) : "r"(word));
return ret;
}
其中用到的bfind.u32指令用于查找一个无符号整数中最右边的非零位(即最低有效位),并返回其位位置。该指令将无符号整数作为操作数输入,并将最低有效位的位位置输出到目的操作数中。
“=r”(ret)表示输出寄存器,返回结果保存在ret中。
“r”(word)表示输入寄存器,将参数word作为输入。
GPU特有的算法
最后一点要强调的时,很多时候将代码并行化,并不是简简单单的从CPU转到GPU,而很有可能是要改变算法。
比如,quicksort是一个(nlog(n))的算法,而bitonic sort是个 ( n l o g 2 ( n ) ) (nlog^2(n)) (nlog2(n))的算法。但是,bitonic sort更适合于在GPU加速。所以我们在CPU上的quicksort改成bitonic sort算法会更好一些。
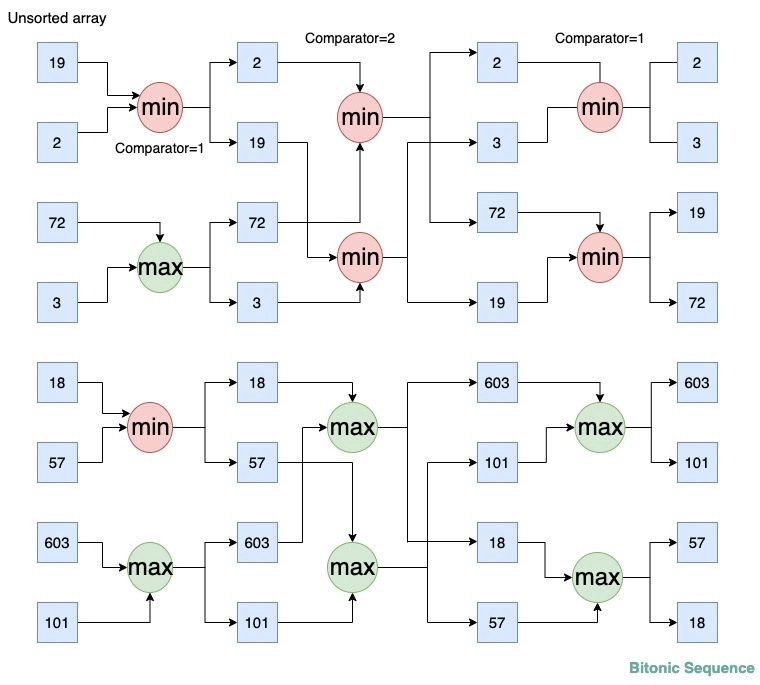
小结
在Intel CPU还是8+4核20线程的时候,GTX 1060显卡做到1280个CUDA核,3060是3584个CUDA核,3090是10496个CUDA核,4090有16384个CUDA核。每个CUDA核上可以起比如1024个线程。
所以,如果有大量可以并发的任务,应该毫不犹豫地将其写成核函数放到GPU上去运行。
GPU编程既没有那么复杂,完全可以快速上手像写CPU程序一样去写。但也不是那么简单,适合GPU可能需要改用特殊的算法。
而基于大量简单Transformers组成的大模型,恰恰是适合高并发的计算。