pytorch实战
本文出现的代码在 https://github.com/hudiework/PyTorchOrigin.git的master分支上
学完本课程之后:
- 读读深度学习的花书,夯实理论基础
- 通读一遍PyTorch官方文档,知道提供了什么功能以及文档结构
- 复现经典工作(读代码=》写代码=》读代码=》…循环往复)
- 扩充视野,广泛阅读自己领域内的工作,看看别人的工作有没有自己不会复现的块
线性模型
Overview
- 目标:
- 如何使用PyTorch实现神经网络/深度学习的基础学习系统
- 需求:
- 线性代数、概率论、python
人类智能
- information→infer
- image→prediction
人工智能
算法代替人脑进行处理的过程
监督学习
拿出数据集,打过标签的,知道答案,建立模型,训练模型,得到算法
范围

基于规则的系统

经典机器学习

表示学习
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zmnXcloq-1676948359448)(https://cdn.staticaly.com/gh/hudiework/img@main/4f7a49b9d6e42308ba3589ae6c25af8ca4974a9d.png)]
提取features
维度诅咒
维数增加,数据需求量增大
降维
eg: n维→3维
[ ] = [ ] [ ]
3x1 3xn nx1
找到3xn的矩阵
深度学习

传统策略
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OXGwKIep-1676948370164)(null)]
SVM问题
- 手工设计功能的限制。
- 支持向量机不能很好地处理大数据集。
- 越来越多的应用程序需要处理非结构化数据。
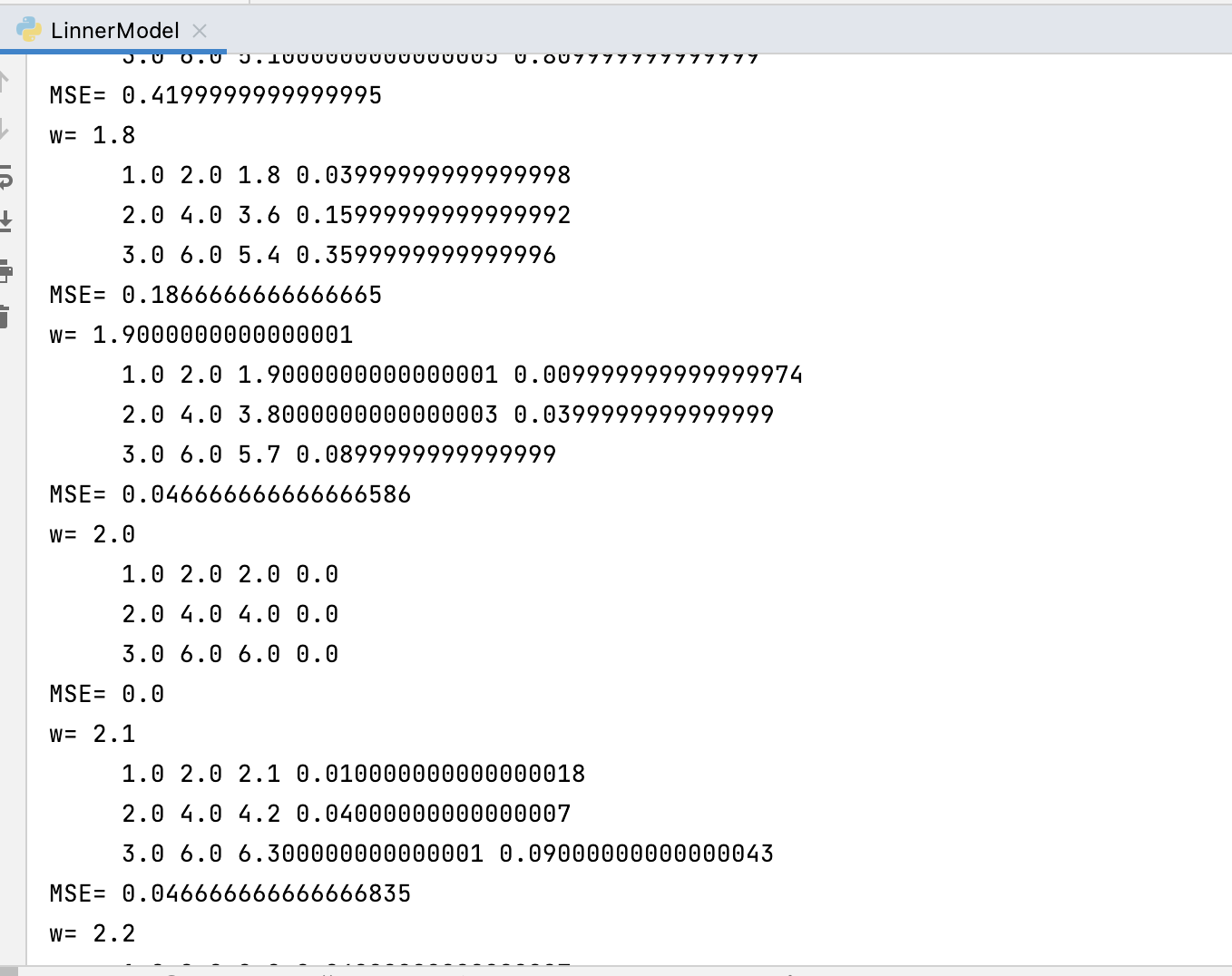
import numpy as np
import matplotlib.pyplot as plt
# 准备数据
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w=0
# define the model
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# prepare two list to draw the graph
w_list = []
mse_list = []
# 穷举过程
for w in np.arange(0.0, 4.1, 0.1):
print("w=", w)
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print('\t', x_val, y_val, y_pred_val, loss_val)
print("MSE=", l_sum / 3)
w_list.append(w)
mse_list.append(l_sum / 3)
# draw the graph
plt.plot(w_list, mse_list)
plt.ylabel("Loss")
plt.xlabel("w")
plt.show()

线性模型课后习题
p5:
- 梯度归零为啥不是在反向传播的后面
可以理解为反向传播是用来算参数的梯度的。
所以要先梯度归零
然后反向传播算出梯度
然后“参数=参数-梯度*学习率”,进行梯度下降更新。
p6:
- F没有定义
import torch.nn.functional as F
但是,torch.nn.functional.sigmoid函数好像要停用了。运行会提示建议更改为torch.sigmoid函数
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# prepare dataset, y=2x+3
x_data = [1.0, 2.0, 3.0]
y_data = [5.0, 7.0, 9.0]
# 生成矩阵坐标
W, B = np.arange(0.0, 4.1, 0.1).round(1), np.arange(0.0, 4.1, 0.1).round(1)
w, b = np.meshgrid(W, B)
def forward(x):
return x * w + b
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
loss_val = loss(x_val, y_val)
l_sum += loss_val
mse = l_sum / len(x_data)
# 绘图
fig = plt.figure()
ax = Axes3D(fig)
surf = ax.plot_surface(w, b, mse, rstride=1, cstride=1, cmap='rainbow')
# 设置下标
ax.set_xlabel('w')
ax.set_ylabel('b')
ax.set_zlabel('Loss')
# 设置颜色条
fig.colorbar(surf, shrink=0.5, aspect=5)
plt.show()

手写数字模型:
运行手写数字识别基础模型

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W2VwLFJg-1676948359450)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230214211100072.png)]
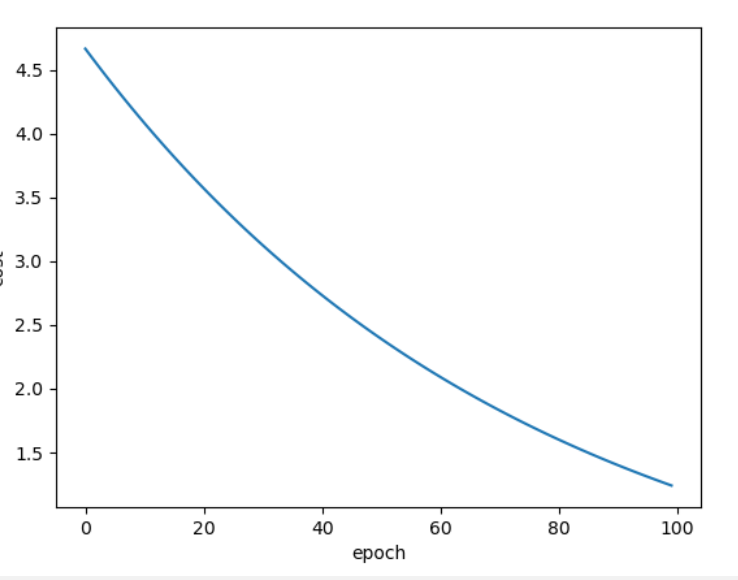
梯度下降算法:
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
loss = (y_pred - y) ** 2
cost += loss
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
cost_list = []
epoch_list = []
print("predict (before trainning)", 4, forward(4))
for epoch in range(100):
epoch_list.append(epoch)
cost_val = cost(x_data, y_data)
cost_list.append(cost_val)
gradient_val = gradient(x_data, y_data)
w -= 0.01 * gradient_val
print("Epoch:", epoch, "w=", w, "loss = ", cost_val)
print("Prediction (after trainning)", 4, forward(4))
plt.plot(epoch_list, cost_list)
plt.xlabel("epoch")
plt.ylabel("cost")
plt.show()

随机梯度下降
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
def gradient(x, y):
y_pred = forward(x)
return 2 * x * (y_pred - y)
lost_list = []
epoch_list = []
print("predict (before trainning)", 4, forward(4))
for epoch in range(100):
epoch_list.append(epoch)
for x, y in zip(x_data, y_data):
loss_val = loss(x, y)
grad = gradient(x, y)
w -= 0.01 * grad
print("Epoch:", epoch, "w=", w, "loss = ", loss_val)
lost_list.append(loss_val)
print("Prediction (after trainning)", 4, forward(4))
plt.plot(epoch_list, lost_list)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()

反向传播
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([1.0], requires_grad=True)
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print("Predict (before)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward()
print("\t grad:", x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_()
print('progress:', epoch, l.item())
print("Predict (after):", 4, forward(4).item())
反向传播 二次方程
import torch
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w1 = torch.tensor([1.0], requires_grad=True)
w2 = torch.tensor([1.0], requires_grad=True)
b = torch.tensor([1.0], requires_grad=True)
def forward(x):
return (x**2) * w1 + x * w2 +b
def loss(x,y):
y_pred = forward(x)
return (y_pred - y) ** 2
cost_list = []
epoch_list = []
print("Predict (before):", 4 , forward(4).item())
for epoch in range(100):
epoch_list.append(epoch)
for x, y in zip(x_data,y_data):
l= loss(x,y)
l.backward()
print("\t grad:",x,y,w1.grad.item(),w2.grad.item(),b.grad.item())
w1.data = w1.data - 0.01 * w1.grad.data
w1.grad.data.zero_()
w2.data = w2.data - 0.01 * w2.grad.data
w2.grad.data.zero_()
b.data = b.data - 0.01 * b.grad.data
b.grad.data.zero_()
print('Progress:', epoch, l.item())
cost_list.append(l.item())
print("Predict (after)", 4, forward(4).item())
plt.plot(epoch_list, cost_list)
plt.xlabel("epoch")
plt.ylabel("cost")
plt.show()
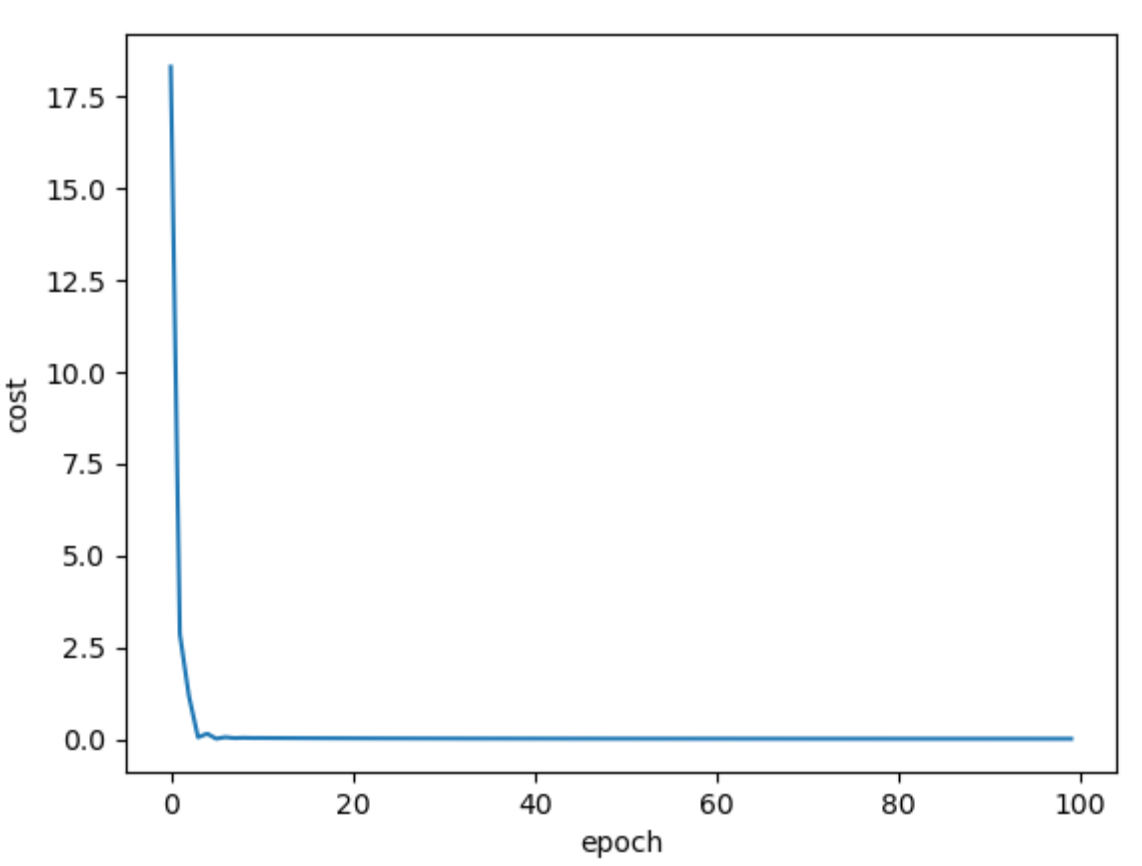
线性模型
训练的过程就是前馈(计算方程 ),反馈(算梯度)以及更新权重
继承Module的类 会自动有一个反馈backward的过程 所以LinearModel类只需要init()和forward()方法即可
实现回归方程的通用四步骤

- 准备数据集
- 用类设计模型
- 构造损失(量化的指标)和优化器(backward)
- 训练循环
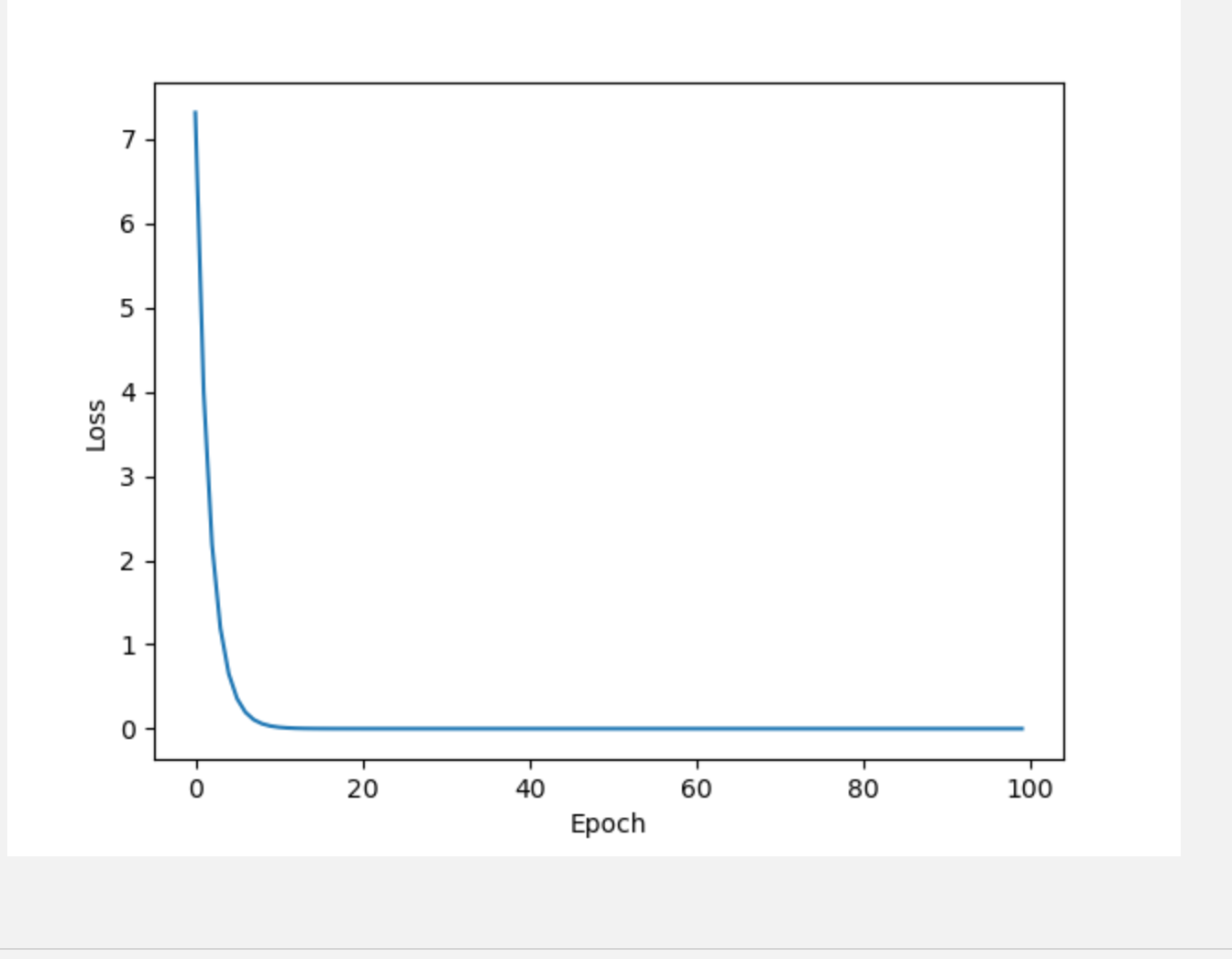
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
x_data = torch.tensor([[1.0],[2.0],[3.0]])
y_data = torch.tensor([[2.0],[4.0],[6.0]])
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel,self).__init__()
self.linear = nn.Linear(1,1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = nn.MSELoss(size_average=False)
optimizer = optim.SGD(model.parameters(),lr=0.01)
epoch_list=[]
loss_list=[]
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss)
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w= ',model.linear.weight.item())
print('b= ',model.linear.bias.item())
x_test = torch.tensor([4.0])
y_test = model(x_test)
print('y_pred= ',y_test.item())
plt.plot(epoch_list, loss_list)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
SGD 图像识别





[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uiHIciaG-1676948373608)(null)]
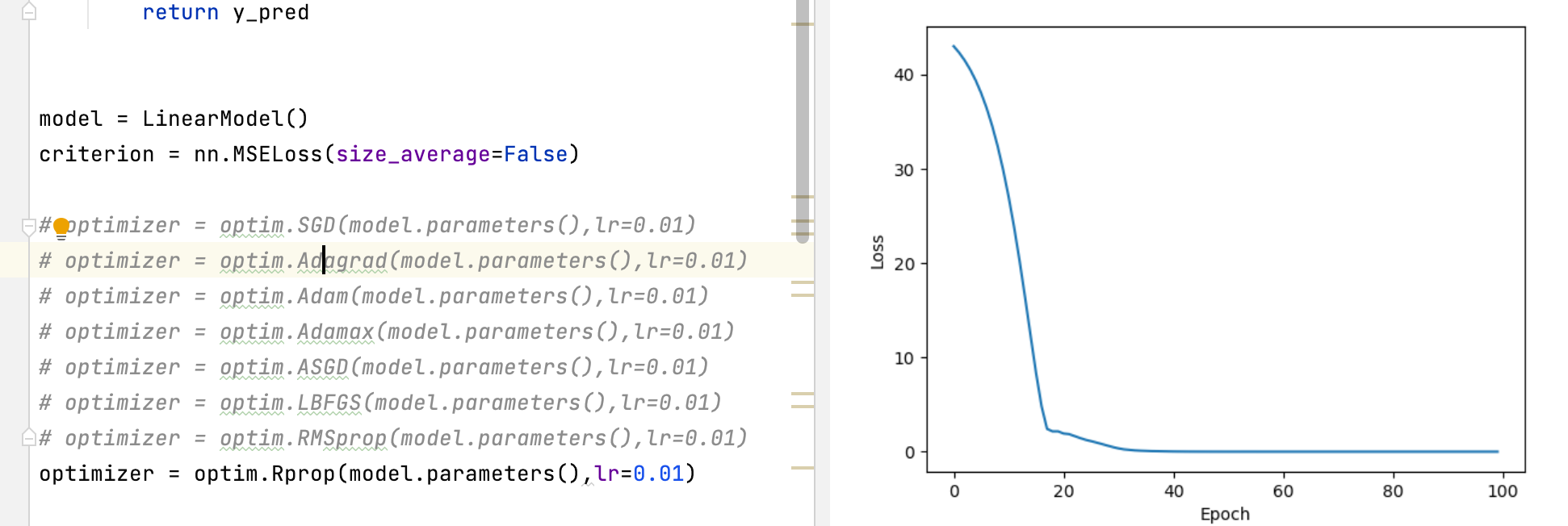
逻辑回归
torchvision包里面自带数据集 MINIST CIFAR10
饱和函数就是 导函数是一条凸函数的 类似正态分布的图像

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ffGnobQl-1676948359454)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230215203623731.png)]
.view()等于numpy里面的reshape
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
class LogisticRegressionModel(nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
y_pred = F.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
criterion = nn.BCELoss(size_average=False)
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
x = np.linspace(0, 10, 200)
x_t = torch.Tensor(x).view(200, 1)
y_t = model(x_t)
y = y_t.data.numpy()
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel("Hours")
plt.ylabel("Prob of Pass")
plt.grid()
plt.show()
多维数据的输入
pytorch里面只限定了数据的列数 不限定数据的行数
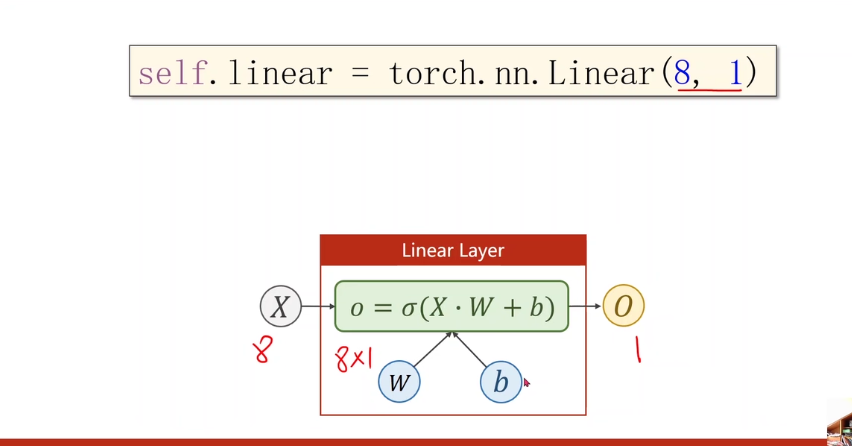
通过引入sigmod函数将8维的空间转化为1维的函数(起到了非线性变换的作用)
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
xy = np.loadtxt("./diabetes.csv.gz", delimiter=",", dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(8, 6)
self.linear2 = nn.Linear(6, 4)
self.linear3 = nn.Linear(4, 1)
self.sigmod = nn.Sigmoid()
def forward(self, x):
x = self.sigmod(self.linear1(x))
x = self.sigmod(self.linear2(x))
x = self.sigmod(self.linear3(x))
return x
model = Model()
criterion = nn.BCELoss(reduction='mean')
optimizer = optim.SGD(model.parameters(),lr=0.1)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('----------Number1------------')
print(model.linear1.weight.data)
print(model.linear1.bias.data)
print('----------Number2------------')
print(model.linear2.weight.data)
print(model.linear2.bias.data)
print('----------Number3------------')
print(model.linear3.weight.data)
print(model.linear3.bias.data)


Titanic数据处理 多维数据未实现
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import pandas as pd
class TitanicDataSet(Dataset):
def __init__(self, filePath):
xy = np.loadtxt(filePath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[1:, [0,2-12]])
self.y_data = torch.from_numpy(xy[1:, [1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
#
# x_data, y_data = TitanicDataSet('./titanic/train.csv')
# print(x_data)
# print("--------")
# print(y_data)
all_df = pd.read_csv(r'./titanic/train.csv',encoding="ISO-8859-1", low_memory=False)
print(all_df)
#把需要的列放进一个列表中,表示选中这些列, 拿到我们需要的数据集
cols = ['Survived', 'Name', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
data= all_df[cols].drop(['Name'], axis=1)
data.head()
# 将性别为female用0代替, male用1代替ß
dict_sex = {
'female': 0, 'male': 1}
data['Sex'] = data['Sex'].map(dict_sex)
# 登船口也和性别处理方法一样
dict_embarked = {
'S': 0, 'C': 1, 'Q': 2}
data['Embarked'] = data['Embarked'].map(dict_embarked)
#该方法可以计算数据中分别有多少个空值
print(data.isnull().sum())
#因为有很多的年龄为空值, 所以我们用这个方法可以用年龄的平均值填充空位
age_mean = data['Age'].mean()
data['Age'] = data['Age'].fillna(age_mean)
#填充fare
fare_mean = data['Fare'].mean()
data['Fare'] = data['Fare'].fillna(fare_mean)
#因为哪个登船口上船对生还率影响不大, 所以用1登船口填充
data['Embarked'] = data['Embarked'].fillna(1)
print(data)
多分类问题(softmax分类器)
import torch
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, shuffle=True, batch_size=batch_size)
# design model
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.l1 = nn.Linear(784, 512)
self.l2 = nn.Linear(512, 256)
self.l3 = nn.Linear(256, 128)
self.l4 = nn.Linear(128, 64)
self.l5 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
x = self.l5(x)
return x
model = Model()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward ,backward ,update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获取一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
# 交叉墒的代价函数outputs (64,10)target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[epoch : %d, batch_idx : %5d loss: %.3f ' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, labels = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
for epoch in range(10):
train(epoch)
test()

卷积神经网络 CNN
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import time
# 准备数据
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.pooling = nn.MaxPool2d(2)
self.fc = nn.Linear(320, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n , 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# trainning cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss : %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set : %d %% ' % (100 * correct / total))
torch.cuda.synchronize()
start = time.time()
for epoch in range(10):
train(epoch)
test()
torch.cuda.synchronize()
end = time.time()
time_elapsed = end - start
print('Trainning complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V3KjMJJD-1676948370554)(null)]
CNN用cuda实现
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import time
# 准备数据
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.pooling = nn.MaxPool2d(2)
self.fc = nn.Linear(320, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n , 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# trainning cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss : %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set : %d %% ' % (100 * correct / total))
torch.cuda.synchronize()
start = time.time()
for epoch in range(10):
train(epoch)
test()
torch.cuda.synchronize()
end = time.time()
time_elapsed = end - start
print('Trainning complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))

高级CNN
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import time
import matplotlib.pyplot as plt
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branchx1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branchx1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
output = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(output, dim=1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward,update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d , %5d] loss : %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
accuracy = []
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %%' % (100 * correct / total))
accuracy.append(100 * correct / total)
torch.cuda.synchronize()
start = time.time()
for epoch in range(10):
train(epoch)
test()
torch.cuda.synchronize()
end = time.time()
time_elapsed = end - start
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
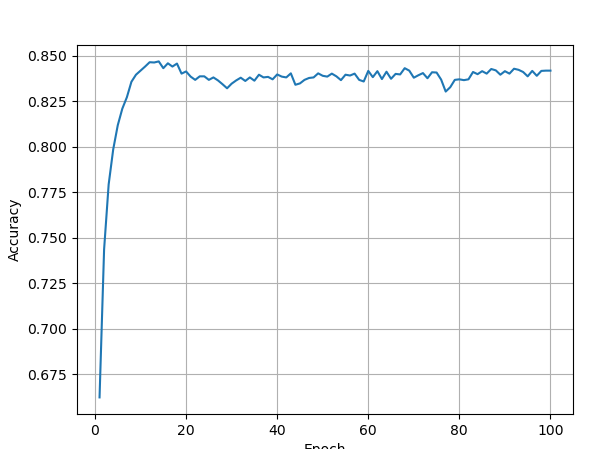
plt.plot(range(10), accuracy)
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.grid()
plt.show()
print("done")
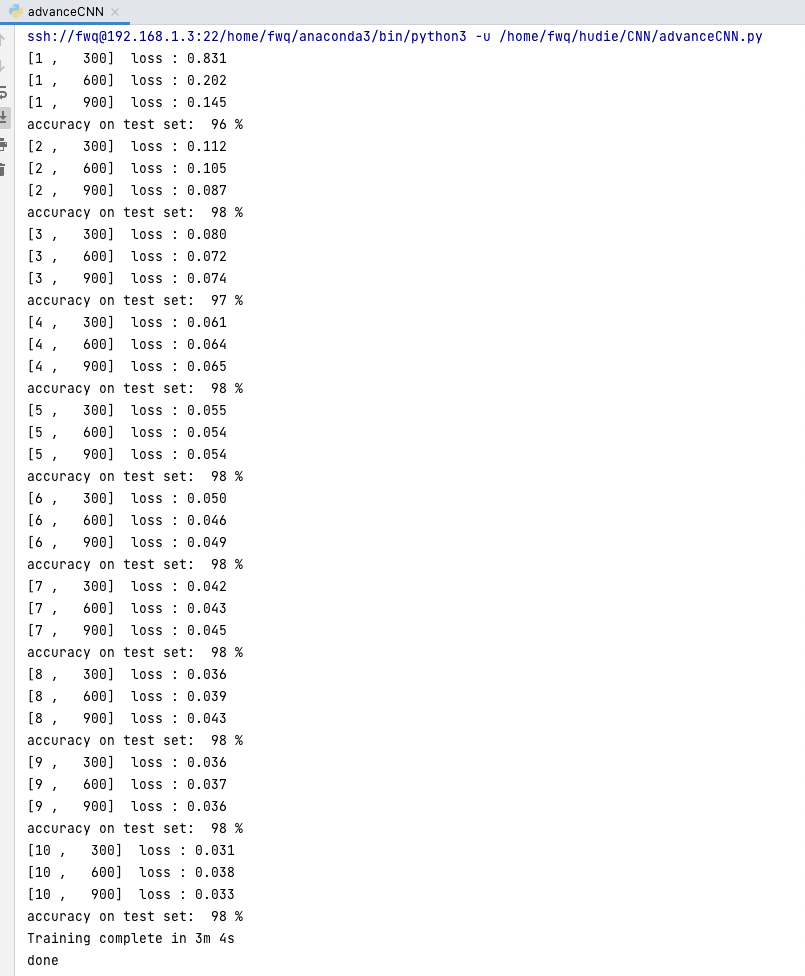
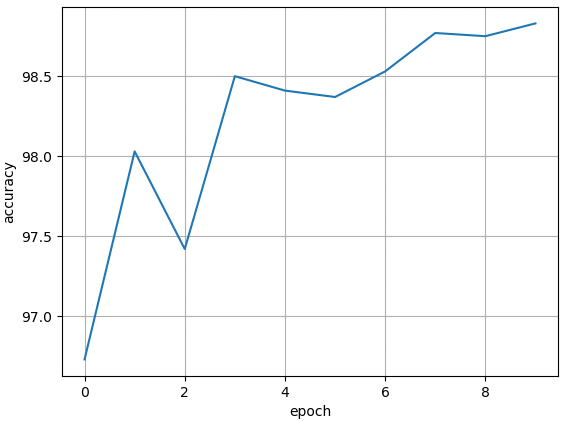
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import time
import matplotlib.pyplot as plt
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y == self.conv2(y)
return F.relu(x + y)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward,update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d , %5d] loss : %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
accuracy = []
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %%' % (100 * correct / total))
accuracy.append(100 * correct / total)
torch.cuda.synchronize()
start = time.time()
for epoch in range(10):
train(epoch)
test()
torch.cuda.synchronize()
end = time.time()
time_elapsed = end - start
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
plt.plot(range(10), accuracy)
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.grid()
plt.show()
print("done")

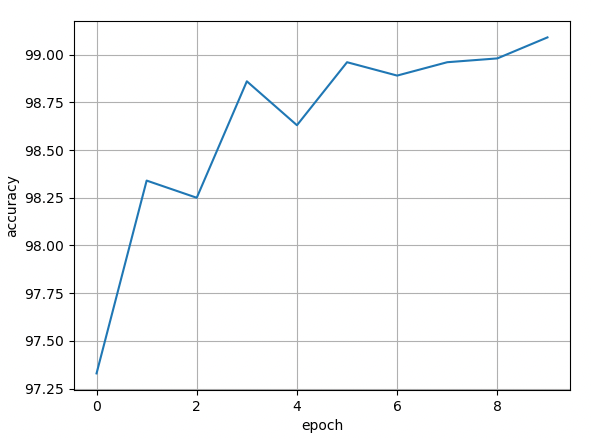
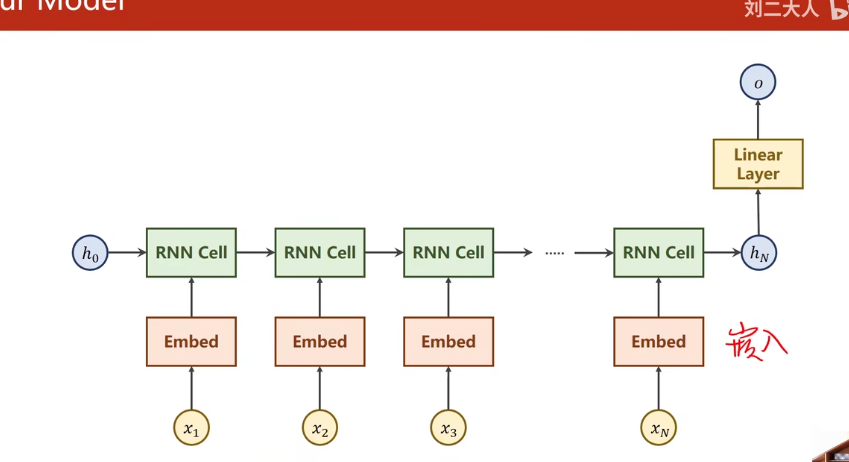
RNN
Dense Deep 要拿到之前若干天钱的数据预测今天是否下雨
卷积层的输入和输出 只和通道还有卷积核的大小有关
全连接层和你变化的数据有关 卷积层的运算看起来复杂 但实际上消费并不高
卷积核 整个图像共享
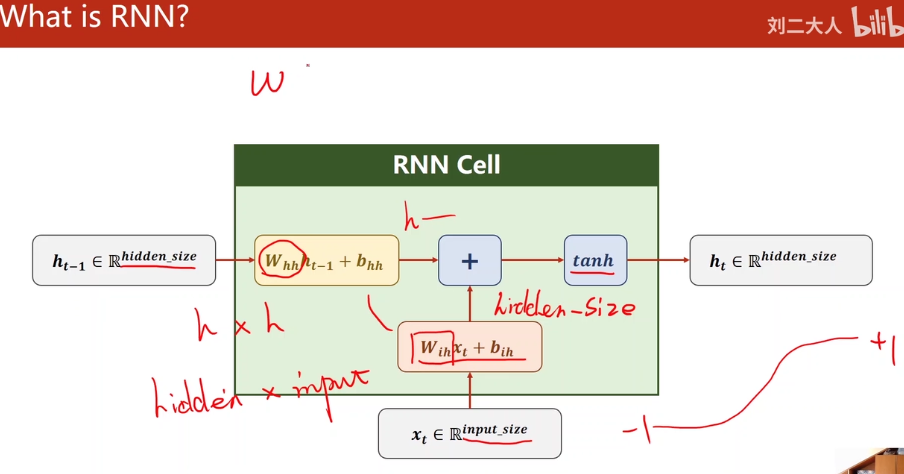
RNN是一种专门处理带有序列模式的数据 其中使用权重共享 来减少需要训练的权重数量
RNNCell(是同一个线性层) ==Linear h0是先验知识
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tYZC78DK-1676948369810)(null)]
先根据字符构造词典
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZlANrYbf-1676948369968)(null)]
独热编码 缺点: 高纬度 分散 硬编码

RNN GRU LTSM
手写循环实现RNN 便于理解RNN的工作流程
import torch
# "需要:初始化h0,输入序列"
batch_size = 1
input_size = 4
hidden_size = 2
seq_len = 3
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
dataset = torch.randn(seq_len, batch_size, input_size) # 构造输入序列
hidden = torch.zeros(batch_size, hidden_size) # 构造全是0的隐层,即初始化h0
for idex, input in enumerate(dataset):
print('=' * 20, idex, '=' * 20)
print('Input size:', input.shape)
hidden = cell(input, hidden)
print('outputs size:', hidden.shape)
print('hidden:', hidden)
使用torch.nn.RNN系统自带的调用
import torch
batch_size = 1
input_size = 4
hidden_size = 2
seq_len = 3
num_layers = 2
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)
print('output size:', out.shape)
print('out:', out)
print('hidden size:', hidden.shape)
print('hidden:', hidden)

例子 通过RNNCell学习序列“hello”→“ohlol”转换的规律
-
构建字典(建立character和index之间的映射关系),通过indices编码得到one-hot向量
-
确定RNN的输出:一个四维向量,再分类器来实现文本序列的重新排列

·```python
import torch import torch.nn as nn import torch.optim as optim input_size = 4 hidden_size = 4 batch_size = 1 # prepare data idx2char = ['e', 'h', 'l', 'o'] x_data = [1, 0, 2, 2, 3] # hello 输入 y_data = [3, 1, 2, 3, 2] # ohlol 目标 one_hot_lookup = [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]] # 分别对应0,1,2,3即e,h,l,o 独热编码 x_one_hot = [one_hot_lookup[x] for x in x_data] inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size) # -1即seqLen labels = torch.LongTensor(y_data).view(-1, 1) # (seqLen,1) # define model class Model(nn.Module): def __init__(self, input_size, hidden_size, batch_size): super(Model, self).__init__() self.input_size = input_size self.hidden_size = hidden_size self.batch_size = batch_size self.rnncell = nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size) def forward(self, input, hidden): hidden = self.rnncell(input, hidden) return hidden def init_hidden(self): return torch.zeros(self.batch_size, self.hidden_size) model = Model(input_size, hidden_size, batch_size) # loss & optimizer criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.1) # training cycle for epoch in range(15): loss = 0 optimizer.zero_grad() hidden = model.init_hidden() # h0 print('predicted string:', end='') for input, label in zip(inputs, labels): hidden = model(input, hidden) loss += criterion(hidden, label) _, idx = hidden.max(dim=1) # hidden是4维的,分别表示e,h,l,o的概率值 print(idx2char[idx.item()], end='') loss.backward() optimizer.step() print(',epoch [%d/15] loss = %.4lf' % (epoch + 1, loss.item()))
实现结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x0Z04sQN-1676948369863)(null)]
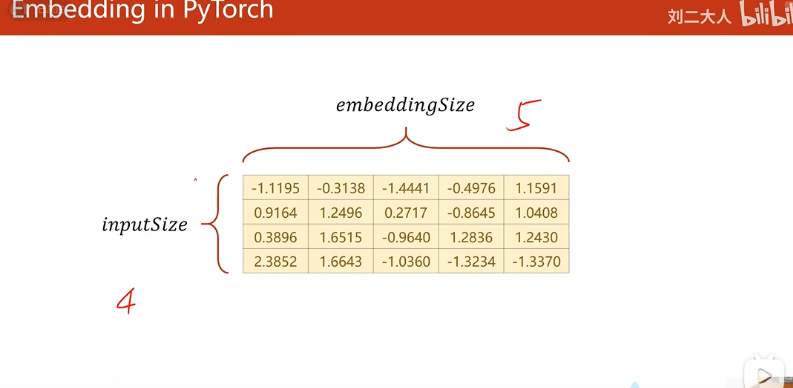
One-hot矩阵是high-dimension、sparse,hardcoded的,通过Embedding将one-hot稀疏矩阵映射成低维、稠密的矩阵
为什么要使用Embedding
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YypSowXQ-1676948359457)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230220115125754.png)]
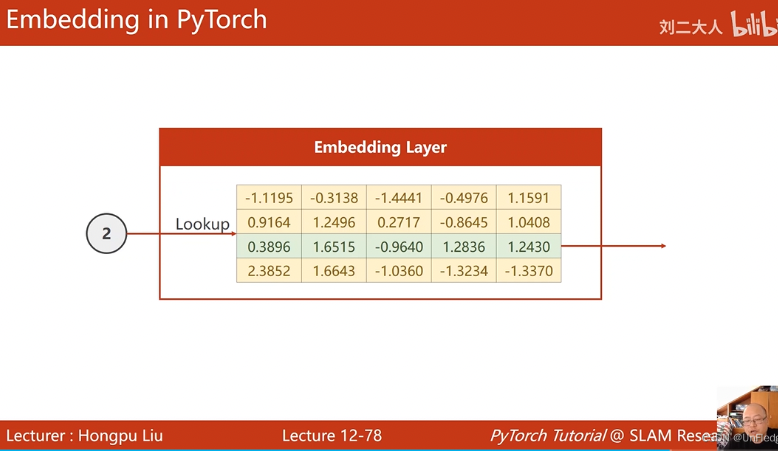

import torch
import torch.nn as nn
import torch.optim as optim
num_class = 4 # 4个类别,
input_size = 4 # 输入维度
hidden_size = 8 # 隐层输出维度,有8个隐层
embedding_size = 10 # 嵌入到10维空间
num_layers = 2 # 2层的RNN
batch_size = 1
seq_len = 5 # 序列长度5
# prepare data
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # (batch, seq_len) list
y_data = [3, 1, 2, 3, 2] # ohlol
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
# define model
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = nn.Embedding(input_size, embedding_size)
self.rnn = nn.RNN(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc = nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class)
model = Model()
# loss & optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.05)
# training cycle
for epoch in range(15):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print('outputs:', outputs)
_, idx = outputs.max(dim=1)
idx = idx.data.numpy() # reshape to numpy
print('idx', idx)
print('Pridected:', ''.join([idx2char[x] for x in idx]), end='') # end是不自动换行,''.join是连接字符串数组
print(',Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jLaPgJzc-1676948359458)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230220120048286.png)]
RNN Classifier 测试名字归属哪个国家拼写
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qkYXbYWT-1676948359458)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230220120250111.png )]
先通过嵌入层 变成地位稠密的响亮变成独热编码

处理自然语言常用的方法以及流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cRHOpFRD-1676948359459)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230221085621906.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CUngtHfS-1676948369915)(null)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1QL9WYNu-1676948359460)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230221091801798.png)]

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8pId3QHq-1676948359460)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230221091903508.png)]

# 引入torch
import torch
# 引入time计时
import time
# 引入math数学函数
import math
# 引入numpy
import numpy as np
# 引入plt
import matplotlib.pyplot as plt
# 从torch的工具的数据引入数据集,数据加载器
from torch.utils.data import Dataset, DataLoader
# 从torch的神经网络的数据的rnn中引入包装填充好的序列。作用是将填充的pad去掉,然后根据序列的长短进行排序
from torch.nn.utils.rnn import pack_padded_sequence
# 引入gzip 压缩文件
import gzip
# 引入csv模块
import csv
# 隐层数是100
HIDDEN_SIZE = 100
# batch的大小时256
BATCH_SIZE = 256
# 应用2层的GRU
N_LAYER = 2
# 循环100
N_EPOCHS = 100
# 字符数量时128
N_CHARS = 128
# 不使用GPU
USE_GPU = True
# 定义名字数据集的类,继承自数据集
class NameDataset(Dataset):
# 自身初始化,是训练集为真
def __init__(self, is_train_set=True):
# 文件名是训练集。如果训练为真,否则是测试集
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
# 用gzip打开文件名,操作text文本的时候使用'rt',作为f
with gzip.open(filename, 'rt') as f:
# 阅读器是用csv的阅读器阅读文件
reader = csv.reader(f)
# 将文件设成一个列表
rows = list(reader)
# 自身名字是文件的第一列都是名字,提取第一列,对于r在rs中时
self.names = [row[0] for row in rows]
# 长度是名字的长度
self.len = len(self.names)
# 国家是第二列
self.countries = [row[1] for row in rows]
# 将国家变成集合,去除重复的元素,然后进行排序,然后接着再变回列表
self.country_list = list(sorted(set(self.countries)))
# 得到国家的词典,将列表转化成词典(有索引)
self.country_dict = self.getCountryDict()
# 长度是国家的长度
self.country_num = len(self.country_list)
# 定义 获得项目类,提供索引访问,自身,索引
def __getitem__(self, index):
# 返回 带索引的名字,带索引的国家,代入,得到带国家的词典
return self.names[index], self.country_dict[self.countries[index]]
# 定义长度
def __len__(self):
# 返回长度
return self.len
# 定义获得国家词典
def getCountryDict(self):
# 现设一个空字典
country_dict = dict()
# idx表示进行多少次的迭代,country_name是国家名,用列举的方法将国家列表的数据提取出来,从0开始
for idx, country_name in enumerate(self.country_list, 0):
# 构造键值对,将国家名代入国家列表中等于1,2,3.
country_dict[country_name] = idx
# 返回国家列表
return country_dict
# 定义 索引返回国家字符串,自身索引
def idx2country(self, index):
# 返回 自身,将索引代入国家列表得到字符串
return self.country_list[index]
# 获得国家数量
def getCountriesNum(self):
# 返回自身国家数量
return self.country_num
# 将训练集为真,代入名字数据集模型中得到训练集
trainset = NameDataset(is_train_set=True)
# 将训练集,batch的大小等于batch的大小,shuffle为真将数据打乱。代入到数据加载器中。得到训练加载器
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
# 将训练集为假,代入名字数据集模型中得到测试集
testset = NameDataset(is_train_set=False)
# 将测试集,batch的大小等于batch的大小,shuffle为假不把数据打乱。代入到数据加载器中。得到测试加载器
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False)
# 训练集的获得国家数量得到国家数量
N_COUNTRY = trainset.getCountriesNum()
# 创建tensor
def create_tensor(tensor):
# 如果使用GPU
if USE_GPU:
# 使用第一个GPU代入到设置,得到设置
device = torch.device("cuda:0")
# 让张量在设置里面跑
tensor = tensor.to(device)
# 返回张量
return tensor
# 将RNN分类器分成一个类,继承自Module模块
class RNNClassifier(torch.nn.Module):
# 定义自身初始化,输入的大小,隐层的大小,输出的大小,层数是1,bidirectional为真设成双向的。
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
# 父类初始化
super(RNNClassifier, self).__init__()
# 自身隐层等于隐层
self.hidden_size = hidden_size
# 自身层数等于层数
self.n_layers = n_layers
# 自身方向数量是如果bidirectional为真则是2,否则是1
self.n_directions = 2 if bidirectional else 1
# 将输入的大小和隐层的大小代入嵌入层得到自身嵌入层
self.embedding = torch.nn.Embedding(input_size, hidden_size)
# 隐层的大小是输入,隐层的大小是输出,层数,双向代入GRU模型中,得到gru
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional)
# 因为是双向的,所以隐层×双向,输出的大小代入线性模型,得到,激活函数。
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)
# 初始化h0,自身batch的大小
def _init_hidden(self, batch_size):
# 将层数×方向数,batch的大小,隐层的大小归零,得到h0
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size)
# 返回 创建张量的隐层
return create_tensor(hidden)
# 定义前馈计算,自身,输入,序列的长度
def forward(self, input, seq_lengths):
# 将输入进行转置,B*S--S*B
input = input.t()
# 输入的第二列是batch的大小
batch_size = input.size(1)
# 将batch的大小代入到自身初始隐层中,得到隐层的大小
hidden = self._init_hidden(batch_size)
# 将输入的大小代入到自身嵌入层得到嵌入层
embedding = self.embedding(input)
# 将嵌入层和序列的长度代入pack_padded_sequence中,先将嵌入层多余的零去掉,然后排序,打包出来,得到GRU的输入。
gru_input = pack_padded_sequence(embedding, seq_lengths)
# 将输入和隐层代入gru,得到输出和隐层
output, hidden = self.gru(gru_input, hidden)
# 如果是双向的
if self.n_directions == 2:
# 将隐层的最后一个和隐层的最后第二个拼接起来,按照维度为1的方向拼接起来。得到隐层
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
# 否则
else:
# 隐层就只有最后一个
hidden_cat = hidden[-1]
# 将隐层代入激活函数得到输出
fc_output = self.fc(hidden_cat)
# 返回输出
return fc_output
# 定义名字到列表
def name2list(name):
# 对于c在名字里,将c转变为ASC11值
arr = [ord(c) for c in name]
# 返回arr和长度
return arr, len(arr)
# 定义制作张量 名字 国家
def make_tensors(names, countries):
# 将名字代入到模型中得到ASC11值,对于名字在名字中,得到序列和长度
sequences_and_lengths = [name2list(name) for name in names]
# 将第一列取出来得到名字序列
name_sequences = [sl[0] for sl in sequences_and_lengths]
# 将第二列转换成长tensor得到序列的长度
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths])
# 将国家变为长整型数据
countries = countries.long()
# 将名字序列的长度,序列长度的最大值的长整型归零。得到序列的张量
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
# 对于索引,序列和序列长度 在名字序列和名字长度中遍历,从零开始
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
# 将序列变成长张量,等于序列张量,idx是索引,第1,2,3.。。。,
#:seq_len是按照从小到大排序的序列长度,这样就将序列复制到空序列中了。
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
# 将序列长度按照维度为0,进行排序,下降是真,得到序列长度和索引
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
# 将索引赋值给序列张量
seq_tensor = seq_tensor[perm_idx]
# 将索引赋值给国家
countries = countries[perm_idx]
# 返回序列张量,序列长度,国家。创建tensor
return create_tensor(seq_tensor), \
create_tensor(seq_lengths), \
create_tensor(countries)
# 定义time_since模块
def time_since(since):
# 现在的时间减去开始的时间的到时间差
s = time.time() - since
# Math.floor() 返回小于或等于一个给定数字的最大整数。计算分钟数
m = math.floor(s / 60)
# 减去分钟数乘以60就是剩下的秒数
s -= m * 60
# 返回分秒
return '%dm %ds' % (m, s)
# 定义训练模型
def trainModel():
# 损失设为0
total_loss = 0
# 对于i,名字和国家在训练加载器中遍历,从1开始
for i, (names, countries) in enumerate(trainloader, 1):
# 将名字和国家代入到make_tensors模型中得到输入,序列长度,目标
inputs, seq_lengths, target = make_tensors(names, countries)
# 将输入和序列长度代入到分类器中得到输出
output = classifier(inputs, seq_lengths.cpu())
# 将输出和目标代入到损失标准器中得到损失
loss = criterion(output, target)
# 梯度归零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新
optimizer.step()
# 损失标量相加得到总的损失
total_loss += loss.item()
# 如果i能被10整除
if i % 10 == 0:
# 以f开头表示在字符串内支持大括号内的python 表达式。将开始的时间代入time_since中得到分秒,循环次数,end是不换行加空格
print(f'[{
time_since(start)}]) Epoch {
epoch}', end='')
# f,i×输入的长度除以训练集的长度
print(f'[{
i * len(inputs)}/{
len(trainset)}]', end='')
# 总损失除以i×输入的长度,得到损失
print(f'loss={
total_loss / (i * len(inputs))}')
# 返回总损失
return total_loss
# 定义测试模型
def testModel():
# 初始正确的为0
correct = 0
# 总长是测试集的长度
total = len(testset)
# 打印,,,
print("evaluating trained model ...")
# 不用梯度
with torch.no_grad():
# 对于i,名字和国家在测试加载器中遍历,从1开始
for i, (name, countries) in enumerate(testloader, 1):
# 将名字和国家代入到make_tensors模型中得到输入,序列长度,目标
inputs, seq_lengths, target = make_tensors(name, countries)
# 将输入和序列长度代入到分类器中得到输出
output = classifier(inputs, seq_lengths.cpu())
# 按照维度为1的方向,保持输出的维度为真,取输出的最大值的第二个结果,得到预测值
pred = output.max(dim=1, keepdim=True)[1]
# view_as将target的张量变成和pred同样形状的张量,eq是等于,预测和目标相等。标量求和
correct += pred.eq(target.view_as(pred)).sum().item()
# 100×正确除以错误,小数点后保留两位,得到百分比
percent = '%.2f' % (100 * correct / total)
# 测试集正确率
print(f'Test set: Accuracy {
correct}/{
total} {
percent}%')
# 返回正确除以总数
return correct / total
# 封装到if语句里面
if __name__ == '__main__':
# 实例化分类器,字符的长度,隐层的大小,国家的数量,层数
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
# 如果使用GPU
if USE_GPU:
# 设置使用第一个GPU
device = torch.device("cuda:0")
# 让分类器进到设置里面跑
classifier.to(device)
# 标准器是交叉熵损失
criterion = torch.nn.CrossEntropyLoss()
# 优化器是Adam。分类器的大部分参数,学习率是0.001
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)
# 开始时时间的时间
start = time.time()
# 打印循环次数
print("Training for %d epochs..." % N_EPOCHS)
# 空列表
acc_list = []
# 对于循环在1到循环次数中。
for epoch in range(1, N_EPOCHS + 1):
# 训练模型
trainModel()
# 测试模型
acc = testModel()
# 将测试结果加到列表中
acc_list.append(acc)
# 循环,起始是1,列表长度+1是终点。步长是1
epoch = np.arange(1, len(acc_list) + 1, 1)
# 将数据变成一个矩阵
acc_list = np.array(acc_list)
# 循环,列表
plt.plot(epoch, acc_list)
# x标签
plt.xlabel('Epoch')
# y标签
plt.ylabel('Accuracy')
# 绿色
plt.grid()
# 展示
plt.show()