实战前的准备工作见Pytorch2onnx2Tensorflow的环境准备win10。
ONNX转Tensorflow:Onnx2Tensorflow实战。
由于实验室的项目应用在安卓端,训练模型时使用的框架是pytorch,得到的是.pth文件,.pth文件包含了训练出来的权重名和权重值。而安卓端现有的深度学习框架只有caffe和tensorflow,又由于caffe相对比较老,官方维护得比较少,所以一般使用tensorflow在安卓上跑。tensorflow在安卓上有两个库:tensorflow-android(旧)和tensorflow-lite(新),其中前者使用的权重格式为.pb(protobuf),.pb文件保存了流图结构和权重值,后者使用的权重格式为.tflite,.pb到.tflite需要另外进行转换。将.pth文件转换为.pb文件分为两步,第一步将.pth文件转换为.onnx文件,其中onnx是一个通用的深度学习框架,第二步将.onnx文件转换为.pb文件。本篇博文介绍的是将基于ssd算法训练得到的.pth文件转换为.onnx文件,下篇博文会介绍如何将.onnx文件转换为.pb文件。
代码
pytorch2onnx代码如下:
import torch
import torch.onnx
from ssd.config import cfg
from ssd.modeling.detector import build_detection_model #加载ssd算法,根据不同模型修改
def pytorch2onnx():
model = build_detection_model(cfg) #建立ssd模型
pthfile = r'F:\Pythonworkspace\models\model_005000.pth'
loaded_model = torch.load(pthfile, map_location='cpu') #加载权值文件
model.load_state_dict(loaded_model['model']) #加载权值文件中的字典
dummy_input1 = torch.randn(1, 3, 300, 300) #随机输入,分别代表(图片数量,通道数,行数,列数),输入的size要和训练模型时的输入size大小一样
# 下面这两句不是必要的
input_names = ["actual_input1"]
output_names = ["output1"]
torch.onnx.export(model, dummy_input1, "model_005000.onnx", verbose=True, input_names=input_names,
output_names=output_names)
if __name__ == "__main__":
pytorch2onnx()
可能遇到的问题及解决方案
KeyError
问题: 
解决方案: 此类问题是因为字典中不存在对应的关键字,比如上述错误loaded_model中不存在’state_dict’关键字,调试发现loaded_model中存放权值信息的是’model’关键字:
因此将’state_dict’更换成’model’关键字即可解决该问题。
RuntimeError
问题: 输入的tensor和模型要求的tensor大小不一样:
解决方案: onnx执行时需要运行一遍模型,出现上述错误时dummy_input1 = torch.randn(1,3,800,800),也就是运行一遍模型时的输入size是(800,800),而ssd算法要求的输入size是(300,300),因此需要将size修正:dummy_input1 = torch.randn(1,3,300,300)。
权值维度和算法要求的维度不匹配
问题: 输入的权值维度和算法要求的维度不匹配,比如权值box_head.predictor.cls_headers.0.weight的输入维度为([12,512,3,3]),分别是([特征图每个通道预测框的数量,通道数,kernal size]),而算法要求的维度为([84,512,3,3])。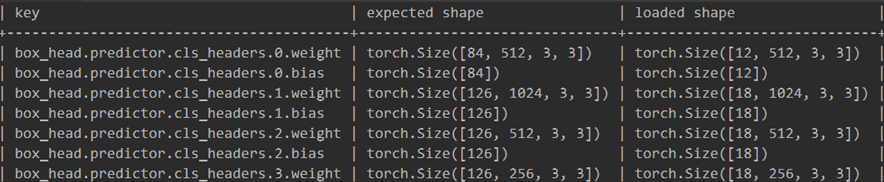
解决方案: 可以看到,只有特征图每个通道预测框的数量的维度不同,原因是ssd算法中该预测框数量的定义为:boxes_pre_location*NUM_CLASSES,其中boxes_pre_location在ssd的六个特征图中的数量分别为[4,6,6,6,4,4],NUM_CLASSES是分类目标的类别数,默认是21,可以得到预测框的数量=boxes_pre_location*NUM_CLASSES=[4,6,6,6,4,4]*21=[84,126,126,126,84,84],正好对应expected shape,而项目中检测的是红绿灯,只有三个类,分别是背景、红灯和绿灯。因此需要将NUM_CLASSES改为3,如此预测框的数量=[4,6,6,6,4,4]*3=[12,18,18,18,12,12],正好对应loaded shape。
总结:只需要令ssd算法中的NUM_CLASSES=3。
onnx不支持的输出格式"Container"
问题: 以Container格式输出报错: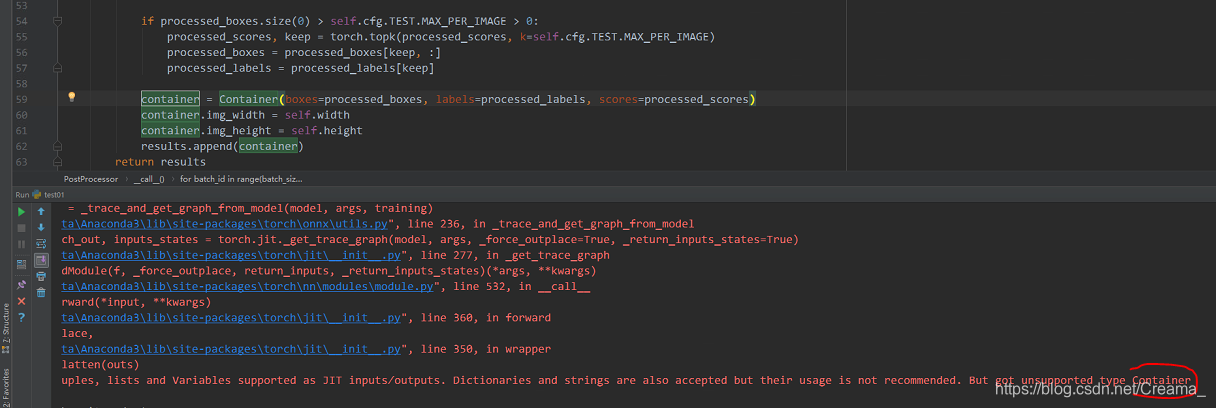
解决方案: Container是ssd算法中自定义的一个数据类型,类似dict,而onnx不支持Container格式输出,所以将数据存储在dict中输出即可:
onnx不支持的深度学习操作
onnx模型仅支持部分常见深度学习操作,具体见torch.onnx中文文档,上面有onnx的简介、使用示例、局限性、支持的运算符和功能函数。
有问题欢迎在评论区留言,本人水平有限,有错误希望大家指正。