以下内容,都是本人近一年写过的东西,也算花了不少时间。所以,源码并不是免费的,但很便宜。有需要的请邮箱联系:[email protected]。另外,可以辅助编写其他网络爬虫工程。
网络爬虫基础学习
包含:(1)java基础方面:
java集合的操作;文本数据的读与写;日志的使用;
(2)java操作mysql数据库方面:基本写法;快速操作写法(QueryRunner);
(3)java网络爬虫方面:HttpClient的使用,即如何获取网页实体内容,关闭流等;Jsoup的使用,即请求网页,解析网页等;部分程序中包含正则表达式;模拟登陆实例演示(人人网);
网络爬虫框架学习,从获取网页内容,解析内容到存储整个流程。整个项目如下图所示:
豆瓣电影爬虫学习
所爬的是豆瓣电影预告片及花絮的ID,名称,以及用户评论内容(评论ID,评论时间,作者等等),例如http://movie.douban.com/subject/10545939/trailer
同时,该工程还包括如何写翻页爬取。
整个工程结果如下所示:
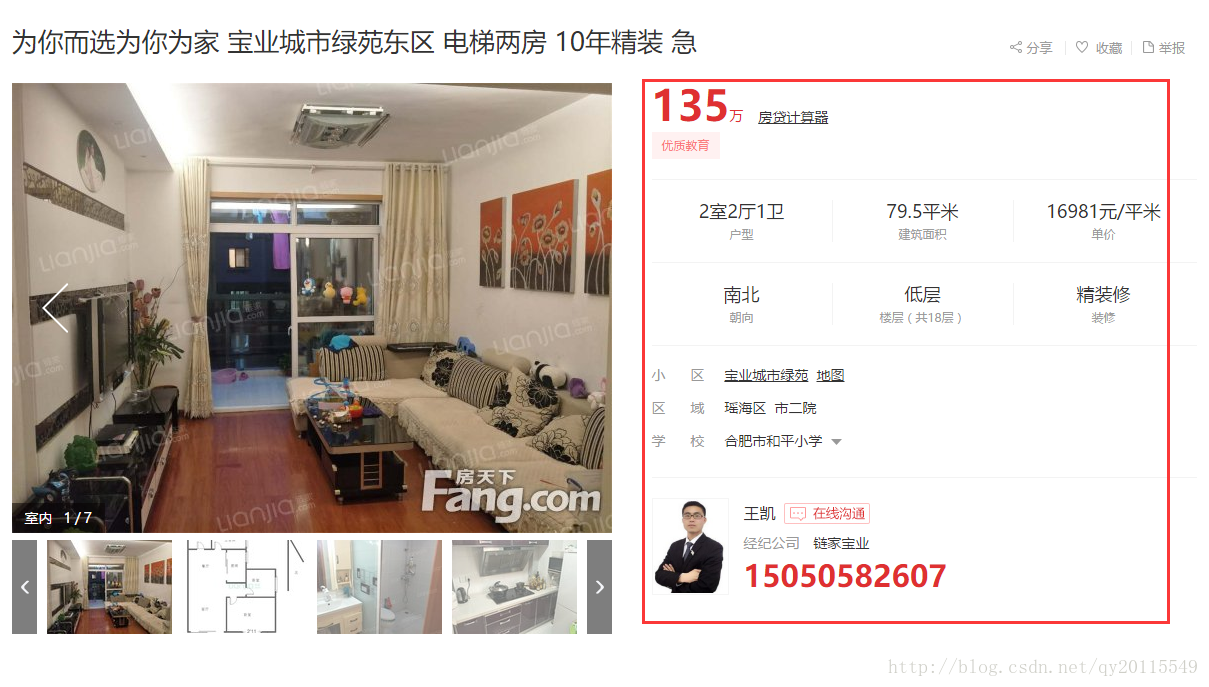
搜房网爬虫
爬取如下信息:
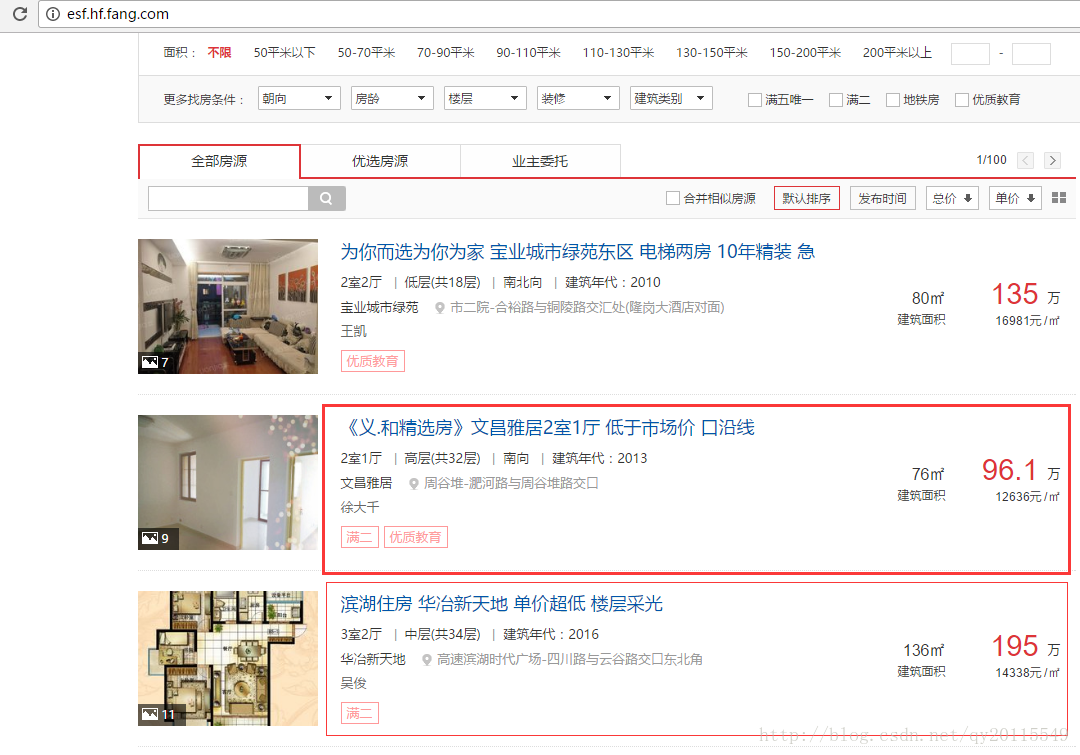
及房屋的具体描述如:http://esf.hf.fang.com/chushou/3_268204940.htm

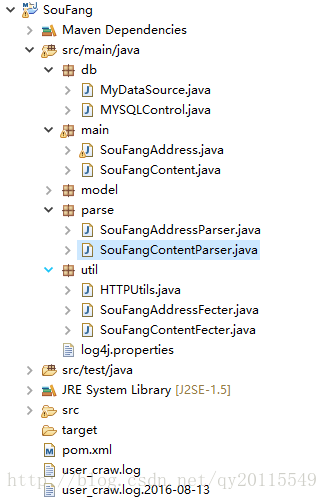
整个工程目录结构如下:
时光网网络爬虫学习
所要爬的数据是时光网,电影预告片及预告片的评论内容。
再者,通过该工程可以学习多线程网络爬虫的设计。
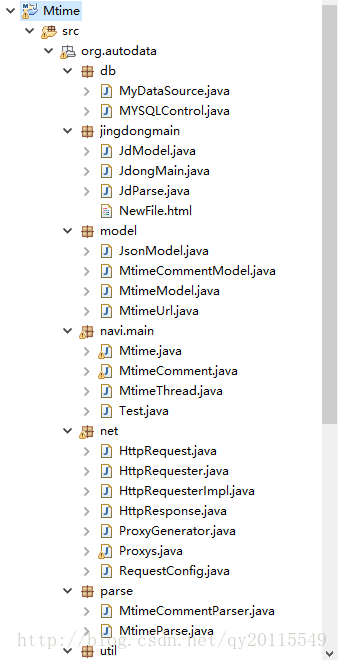
这部分包含两种解析json数据的方法。对于爬取json数据的学习大有益处。工程结构如下:
东方财富网股票爬虫
由于网站后台的返回数据是json数据,这里针对的是json数据的解析。
同时,由于股票数据要每天下午三点钟以后爬取,所以这里设置了定时任务。同时,该工程还可以判断是否是节假日,从而避免数据的重复爬取。
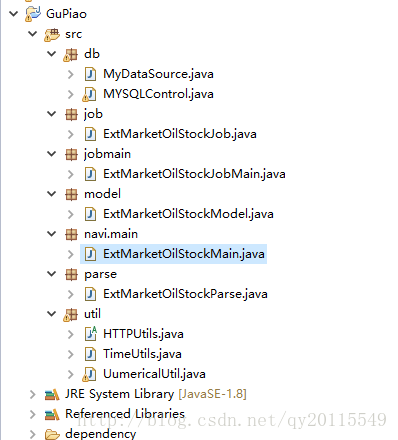
工程结构如下:
汽车之家模拟登陆程序
模拟登陆汽车之家,获取汽车之家注册用户的信息。
工程目录结构如下:
豆瓣模拟登陆(包含如何输入验证码)
模拟登陆,爬取用户的社交用户信息。
整个工程结构如下:
京东网络爬虫
该爬虫的博客为:http://blog.csdn.net/qy20115549/article/details/52203722
前程无忧模拟登陆程序
前程无忧的模拟登陆程序,如下截图:
如图为程序架构:
新浪微博用户的好友列表
整个包含下面几个项目的框架如下:
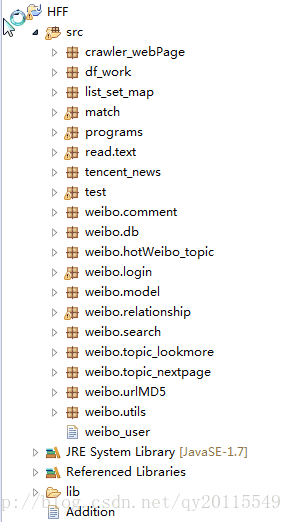
新浪微博用户的所有发帖及评论信息
新浪微博话题数据发帖及评论相关信息
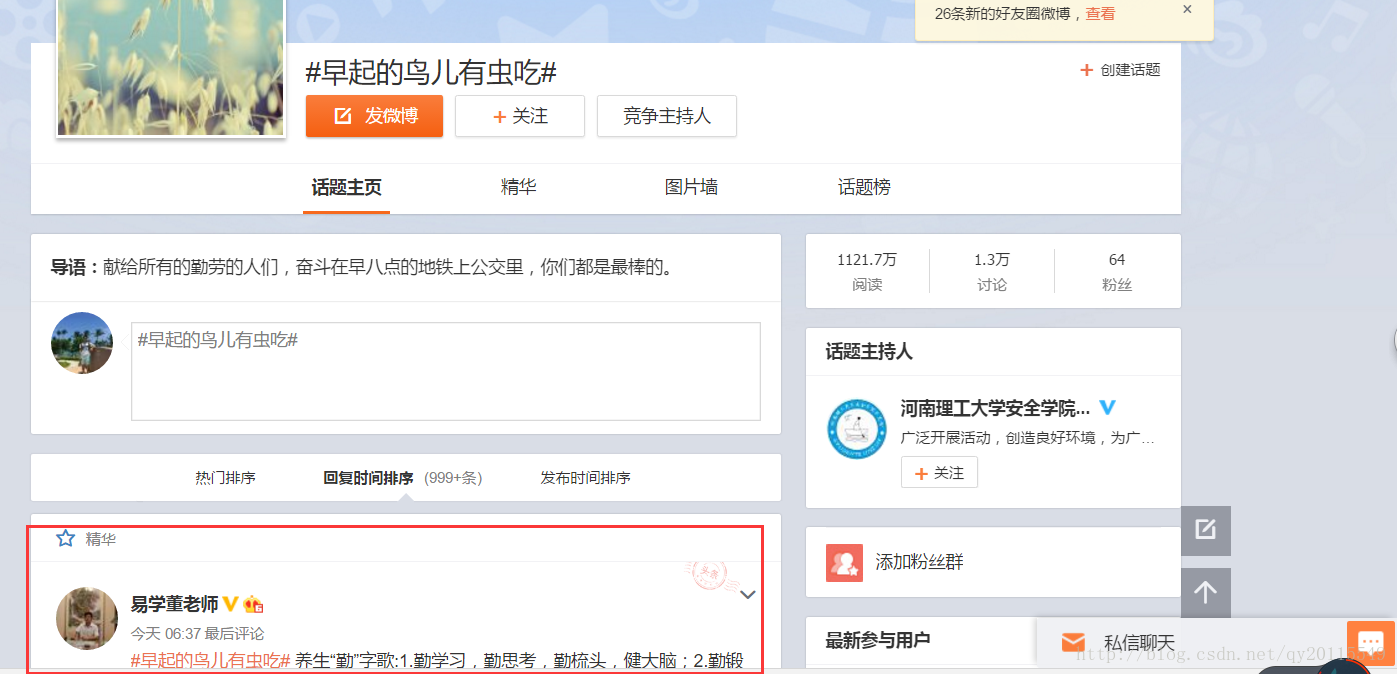
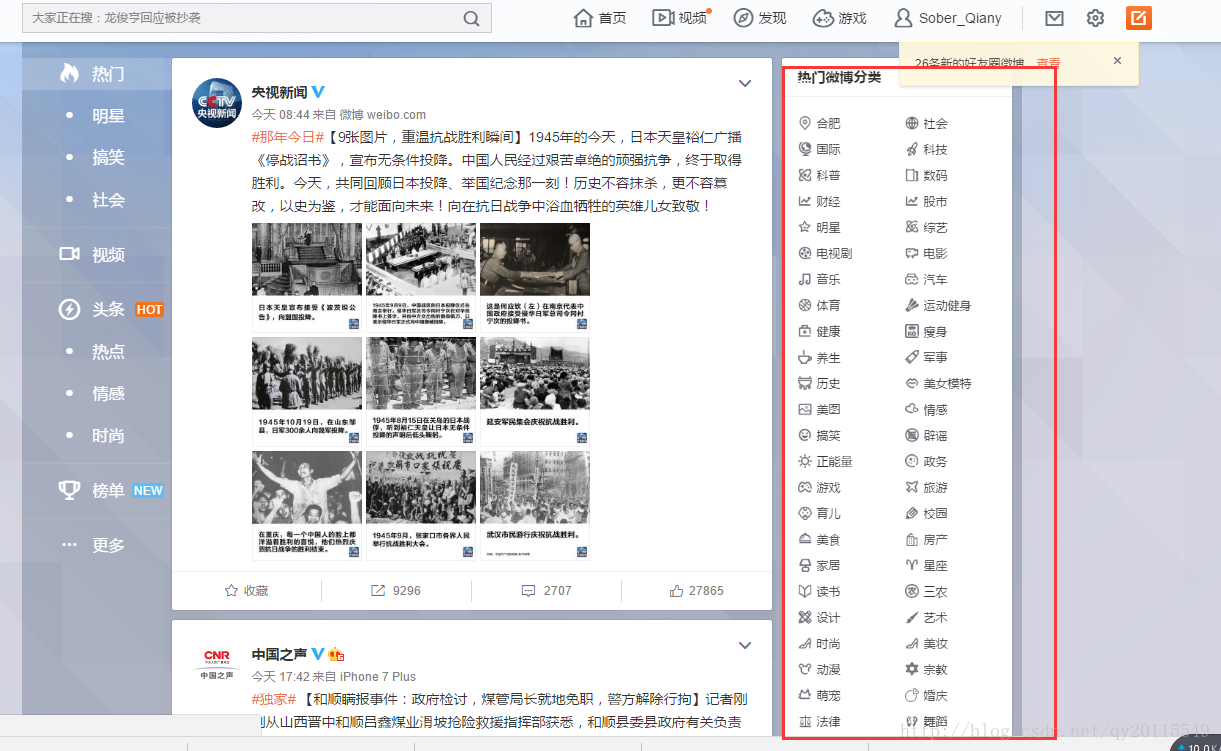
微博分类所有数据
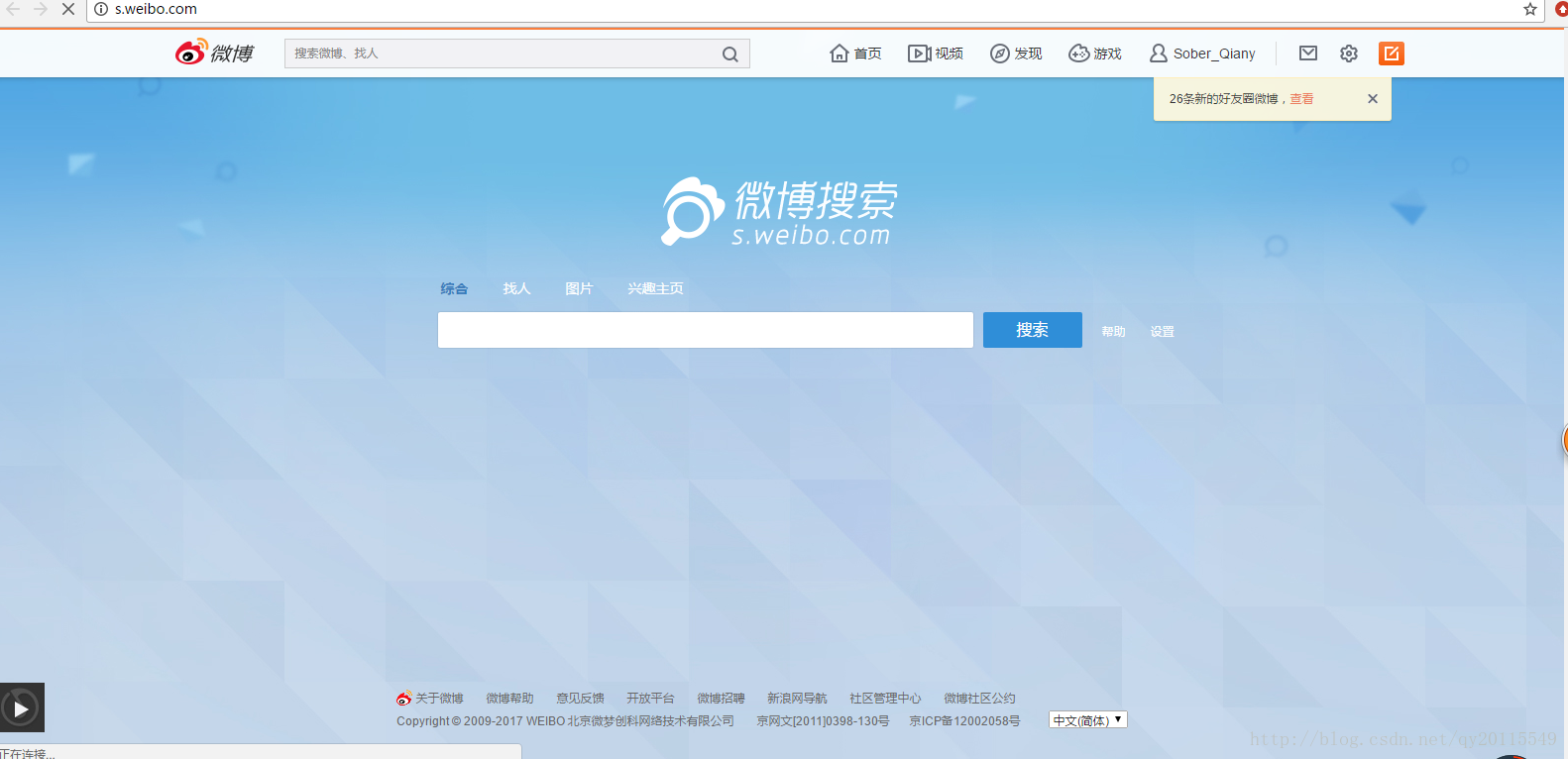
微博提供关键词搜索数据
如下截图,提供关键词,所返回的数据均能爬取。
腾讯数据
网页数据纷繁复杂,比较多。爬过腾讯证券、新闻文本和股票数据。
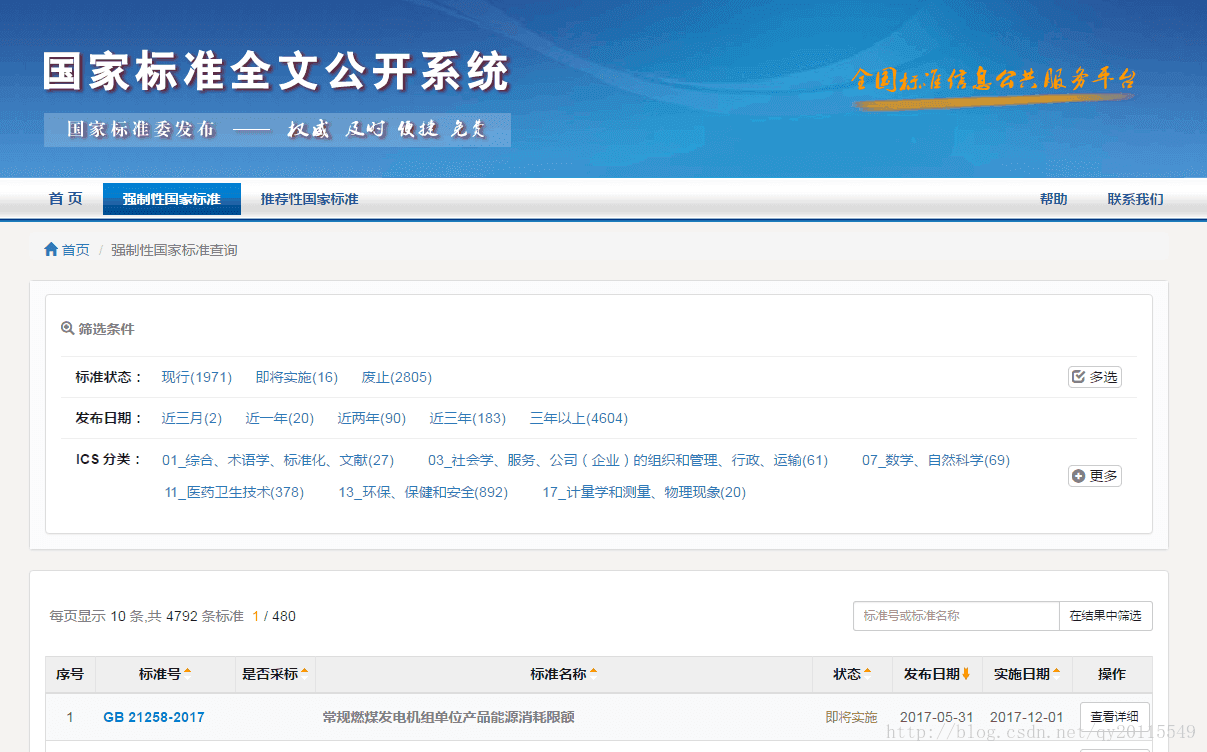
国家标准全文公开系统数据
地址为:http://www.gb688.cn/bzgk/gb/std_list_type?p.p1=1&p.p90=circulation_date&p.p91=desc