相关概念
一、什么是爬虫
爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程。
二、爬虫的分类
1.通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 简单来讲就是尽可能的;把互联网上的所有的网页下载下来,放到本地服务器里形成备分,在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
搜索引擎如何抓取互联网上的网站数据?
- 门户网站主动向搜索引擎公司提供其网站的url
- 搜索引擎公司与DNS服务商合作,获取网站的url
- 门户网站主动挂靠在一些知名网站的友情链接中
2.聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
三、robots.txt协议
如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。但是我们在学习爬虫阶段编写的爬虫程序可以先忽略robots协议。
四、反爬虫
门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。
五、反反爬虫
爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。
六、User-Agent
请求载体身份标识的伪装:
-
User-Agent:请求载体身份标识,通过浏览器发起的请求,请求载体为浏览器,则该请求的User-Agent为浏览器的身份标识,使用爬虫程序发起的请求,则该请求的载体为爬虫程序,则该请求的User-Agent为爬虫程序的身份标识。可以通过判断该值来获知该请求的载体究竟是基于哪款浏览器还是基于爬虫程序。
-
反爬机制:某些门户网站会对访问该网站的请求中的User-Agent进行捕获和判断,如果该请求的UA为爬虫程序,则拒绝向该请求提供数据。
-
反反爬策略:将爬虫程序的UA伪装成某一款浏览器的身份标识。
七、代理
- 什么是代理
-
代理就是第三方代替本体处理相关事务。例如:生活中的代理:代购,中介,微商......
-
-
爬虫中为什么需要使用代理
-
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会会禁止这个IP的访问。所以我们需要设置一些代理IP,每隔一段时间换一个代理IP,就算IP被禁止,依然可以换个IP继续爬取。
-
-
代理的分类:
-
正向代理:代理客户端获取数据。正向代理是为了保护客户端防止被追究责任。
-
反向代理:代理服务器提供数据。反向代理是为了保护服务器或负责负载均衡。
-
-
免费代理ip提供网站
-
http://www.goubanjia.com/
-
西祠代理
-
快代理
-
八、cookie
- 无状态的http协议

- 如上图所示,HTTP协议 是无状态的协议,用户浏览服务器上的内容,只需要发送页面请求,服务器返回内容。对于服务器来说,并不关心,也并不知道是哪个用户的请求。对于一般浏览性的网页来说,没有任何问题。
- 但是,现在很多的网站,是需要用户登录的。以淘宝为例:比如说某个用户想购买一个产品,当点击 “ 购买按钮 ” 时,由于HTTP协议 是无状态的,那对于淘宝来说,就不知道是哪个用户操作的。
- 为了实现这种用户标记,服务器就采用了cookie这种机制来识别具体是哪一个用户的访问。

- 如图,为了实现用户标记,在Http无状态请求的基础之上,我们需要在请求中携带一些用户信息(比如用户名之类,这些信息是服务器发送到本地浏览器的,但是服务器并不存储这些信息),这就是cookie机制。
- 需要注意的是:cookie信息是保存在本地浏览器里面的,服务器上并不存储相关的信息。 在发送请求时,cookie的这些内容是放在 Http协议中的header 字段中进行传输的。
- 几乎现在所有的网站都会发送一些 cookie信息过来,当用户请求中携带了cookie信息,服务器就可以知道是哪个用户的访问了,从而不需要再使用账户和密码登录。
- 但是,刚才也提到了,cookie信息是直接放在Http协议的header中进行传输的,看得出来,这是个隐患!一旦别人获取到你的cookie信息(截获请求,或者使用你的电脑),那么他很容易从cookie中分析出你的用户名和密码。为了解决这个隐患,所以有了session机制。
九、session
- 刚才提到了cookie不安全,所以有了session机制。简单来说(每个框架都不一样,这只是举一个通用的实现策略),整过过程是这样:
- 服务器根据用户名和密码,生成一个session ID,存储到服务器的数据库中。
- 用户登录访问时,服务器会将对应的session ID发送给用户(本地浏览器)。
- 浏览器会将这个session ID存储到cookie中,作为一个键值项。
- 以后,浏览器每次请求,就会将含有session ID的cookie信息,一起发送给服务器。
- 服务器收到请求之后,通过cookie中的session ID,到数据库中去查询,解析出对应的用户名,就知道是哪个用户的请求了。
总结
- cookie 在客户端(本地浏览器),session 在服务器端。cookie是一种浏览器本地存储机制。存储在本地浏览器中,和服务器没有关系。每次请求,用户会带上本地cookie的信息。这些cookie信息也是服务器之前发送给浏览器的,或者是用户之前填写的一些信息。
- Cookie有不安全机制。 你不能把所有的用户信息都存在本地,一旦被别人窃取,就知道你的用户名和密码,就会很危险。所以引入了session机制。
- 服务器在发送id时引入了一种session的机制,很简单,就是根据用户名和密码,生成了一段随机的字符串,这段字符串是有过期时间的。
- 一定要注意:session是服务器生成的,存储在服务器的数据库或者文件中,然后把sessionID发送给用户,用户存储在本地cookie中。每次请求时,把这个session ID带给服务器,服务器根据session ID到数据库中去查询,找到是哪个用户,就可以对用户进行标记了。
- session 的运行依赖 session ID,而 session ID 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,那么同时 session 也会失效(但是可以通过其它方式实现,比如在url中传递 session ID)
- 用户验证这种场合一般会用 session。 因此,维持一个会话的核心就是客户端的唯一标识,即session ID
HTTP协议和HTTPS协议
一、HTTP协议:
1.官方概念:
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。(虽然童鞋们将这条概念都看烂了,但是也没办法,毕竟这就是HTTP的权威官方的概念解释,要想彻底理解,请客观目移下侧......)
2.白话概念:
HTTP协议就是服务器(Server)和客户端(Client)之间进行数据交互(相互传输数据)的一种形式。我们可以将Server和Client进行拟人化,那么该协议就是Server和Client这两兄弟间指定的一种交互沟通方式。
二、HTTP工作原理:
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
三、HTTP四点注意事项:
- HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
- HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
四、HTTP之URL:
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。以下面这个URL为例,介绍下普通URL的各部分组成:http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name从上面的URL可以看出,一个完整的URL包括以下几部分:
- 协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
- 域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用
- 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
- 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
- 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
- 锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
- 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
五、HTTP之Request:
客户端发送一个HTTP请求到服务器的请求消息包括以下组成部分:

报文头:常被叫做请求头,请求头中存储的是该请求的一些主要说明(自我介绍)。服务器据此获取客户端的信息。
常见的请求头:
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间
Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接
X-Requested-With: XMLHttpRequest 代表通过ajax方式进行访问
User-Agent:请求载体的身份标识
报文体:常被叫做请求体,请求体中存储的是将要传输/发送给服务器的数据信息。
六、HTTP之Response:
服务器回传一个HTTP响应到客户端的响应消息包括以下组成部分:

状态码:以“清晰明确”的语言告诉客户端本次请求的处理结果。
HTTP的响应状态码由5段组成:
-
-
- 1xx 消息,一般是告诉客户端,请求已经收到了,正在处理,别急...
- 2xx 处理成功,一般表示:请求收悉、我明白你要的、请求已受理、已经处理完成等信息.
- 3xx 重定向到其它地方。它让客户端再发起一个请求以完成整个处理。
- 4xx 处理发生错误,责任在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
- 5xx 处理发生错误,责任在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等。
-
相应头:响应的详情展示
常见的相应头信息:
Location: 服务器通过这个头,来告诉浏览器跳到哪里
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
相应体:根据客户端指定的请求信息,发送给客户端的指定数据
七、HTTPS协议:
1.官方概念:
HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。
2.白话概念:
加密安全版的HTTP协议。

3.HTTPS采用的加密技术
3.1 SSL加密技术
SSL采用的加密技术叫做“共享密钥加密”,也叫作“对称密钥加密”,这种加密方法是这样的,比如客户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密,接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个),密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患:


3.2 非对称秘钥加密技术
“非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。以下是非对称加密的原理图:

但是非对称秘钥加密技术也存在如下缺点:
第一个是:如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而不会被挟持。只要是发送密钥,就有可能有被挟持的风险。
第二个是:非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度
4.https的证书机制
在上面我们讲了非对称加密的缺点,其中第一个就是公钥很可能存在被挟持的情况,无法保证客户端收到的公开密钥就是服务器发行的公开密钥。此时就引出了公开密钥证书机制。数字证书认证机构是客户端与服务器都可信赖的第三方机构。证书的具体传播过程如下:
1:服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起

2:服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。
urllib库
urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求。其常被用到的子模块在Python3中的为urllib.request和urllib.parse,在Python2中是urllib和urllib2。


#!/usr/bin/env python # -*- coding:utf-8 -*- #导包 import urllib.request import urllib.parse if __name__ == "__main__": #指定爬取的网页url url = 'http://www.baidu.com/' #通过urlopen函数向指定的url发起请求,返回响应对象 reponse = urllib.request.urlopen(url=url) #通过调用响应对象中的read函数,返回响应回客户端的数据值(爬取到的数据) # data = reponse.read() #返回的数据为byte类型,并非字符串 # print(data) #打印显示爬取到的数据值。 #decode()作用是将响应中字节(byte)类型的数据值转成字符串类型 data = reponse.read().decode() #使用IO操作将data表示的数据值以'w'权限的方式写入到news.html文件中 with open('./news.html','w') as fp: fp.write(data) print('写入文件完毕') """ #补充说明 urlopen函数原型:urllib.request.urlopen(url, data=None, timeout=<object object at 0x10af327d0>, *, cafile=None, capath=None, cadefault=False, context=None) 在上述案例中我们只使用了该函数中的第一个参数url。在日常开发中,我们能用的只有url和data这两个参数。 url参数:指定向哪个url发起请求 data参数:可以将post请求中携带的参数封装成字典的形式传递给该参数(暂时不需要理解,后期会讲) urlopen函数返回的响应对象,相关函数调用介绍: response.headers():获取响应头信息 response.getcode():获取响应状态码 response.geturl():获取请求的url response.read():获取响应中的数据值(字节类型) """ #爬取网络上某张图片数据,且存储到本地 import urllib.request import urllib.parse #如下两行代码表示忽略https证书,因为下面请求的url为https协议的请求,如果请求不是https则该两行代码可不用。 import ssl ssl._create_default_https_context = ssl._create_unverified_context if __name__ == "__main__": #url是https协议的 url = 'https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1536918978042&di=172c5a4583ca1d17a1a49dba2914cfb9&imgtype=0&src=http%3A%2F%2Fimgsrc.baidu.com%2Fimgad%2Fpic%2Fitem%2F0dd7912397dda144f04b5d9cb9b7d0a20cf48659.jpg' reponse = urllib.request.urlopen(url=url) data = reponse.read()#因为爬取的是图片数据值(二进制数据),则无需使用decode进行类型转换。 with open('./money.jpg','wb') as fp: fp.write(data) print('写入文件完毕') #url的特性:url必须为ASCII编码的数据值。所以我们在爬虫代码中编写url时, #如果url中存在非ASCII编码的数据值,则必须对其进行ASCII编码后,该url方可被使用。 #案例:爬取使用百度根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦’的页面数据) import urllib.request import urllib.parse if __name__ == "__main__": #原始url中存在非ASCII编码的值,则该url无法被使用。 #url = 'http://www.baidu.com/s?ie=utf-8&kw=周杰伦' #处理url中存在的非ASCII数据值 url = 'http://www.baidu.com/s?' #将带有非ASCII的数据封装到字典中,url中非ASCII的数据往往都是'?'后面键值形式的请求参数 param = { 'ie':'utf-8', 'wd':'周杰伦' } #使用parse子模块中的urlencode函数将封装好的字典中存在的非ASCII的数值进行ASCII编码 param = urllib.parse.urlencode(param) #将编码后的数据和url进行整合拼接成一个完整可用的url url = url + param print(url) response = urllib.request.urlopen(url=url) data = response.read() with open('./周杰伦.html','wb') as fp: fp.write(data) print('写入文件完毕') #通过自定义请求对象,用于伪装爬虫程序请求的身份。 #上述案例中,我们是通过request模块中的urlopen发起的请求,该请求对象为urllib中内置的默认请求对象, # 我们无法对其进行UA进行更改操作。urllib还为我们提供了一种自定义请求对象的方式, # 我们可以通过自定义请求对象的方式,给该请求对象中的UA进行伪装(更改)操作。 import urllib.request import urllib.parse import ssl ssl._create_default_https_context = ssl._create_unverified_context if __name__ == "__main__": #原始url中存在非ASCII编码的值,则该url无法被使用。 #url = 'http://www.baidu.com/s?ie=utf-8&kw=周杰伦' #处理url中存在的非ASCII数据值 url = 'http://www.baidu.com/s?' #将带有非ASCII的数据封装到字典中,url中非ASCII的数据往往都是'?'后面键值形式的请求参数 param = { 'ie':'utf-8', 'wd':'周杰伦' } #使用parse子模块中的urlencode函数将封装好的字典中存在的非ASCII的数值进行ASCII编码 param = urllib.parse.urlencode(param) #将编码后的数据和url进行整合拼接成一个完整可用的url url = url + param #将浏览器的UA数据获取,封装到一个字典中。该UA值可以通过抓包工具或者浏览器自带的开发者工具中获取某请求,从中获取UA的值 headers={ 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } #自定义一个请求对象 #参数:url为请求的url。headers为UA的值。data为post请求的请求参数(后面讲) request = urllib.request.Request(url=url,headers=headers) #发送我们自定义的请求(该请求的UA已经进行了伪装) response = urllib.request.urlopen(request) data=response.read() with open('./周杰伦.html','wb') as fp: fp.write(data) print('写入数据完毕')
正则解析
一、常用正则表达式回顾:
单字符:
. : 除换行以外所有字符
[] :[aoe] [a-w] 匹配集合中任意一个字符
\d :数字 [0-9]
\D : 非数字
\w :数字、字母、下划线、中文
\W : 非\w
\s :所有的空白字符包,括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S : 非空白
数量修饰:
* : 任意多次 >=0
+ : 至少1次 >=1 ? : 可有可无 0次或者1次 {m} :固定m次 hello{3,} {m,} :至少m次 {m,n} :m-n次 边界: $ : 以某某结尾 ^ : 以某某开头 分组: (ab) 贪婪模式: .* 非贪婪(惰性)模式: .*? re.I : 忽略大小写 re.M :多行匹配 re.S :单行匹配 re.sub(正则表达式, 替换内容, 字符串)#!/usr/bin/env python # -*- coding: utf-8 -*- import re #提取出python key="javapythonc++php" re.findall('python',key)[0] ##################################################################### #提取出hello world key="<html><h1>hello world<h1></html>" re.findall('<h1>(.*)<h1>',key)[0] ##################################################################### #提取170 string = '我喜欢身高为170的女孩' re.findall('\d+',string) ##################################################################### #提取出http://和https:// key='http://www.baidu.com and https://boob.com' re.findall('https?://',key) ##################################################################### #提取出hello key='lalala<hTml>hello</HtMl>hahah' #输出<hTml>hello</HtMl> re.findall('<[Hh][Tt][mM][lL]>(.*)</[Hh][Tt][mM][lL]>',key) ##################################################################### #提取出hit. key='[email protected]'#想要匹配到hit. re.findall('h.*?\.',key) ##################################################################### #匹配sas和saas key='saas and sas and saaas' re.findall('sa{1,2}s',key) ##################################################################### #匹配出i开头的行 string = '''fall in love with you i love you very much i love she i love her''' print(re.findall('.*',string,re.M)[0]) # fall in love with you print(re.findall('.*',string,re.S)[0]) """ fall in love with you i love you very much i love she i love her """ ##################################################################### #匹配全部行 string1 = """<div>静夜思 窗前明月光 疑是地上霜 举头望明月 低头思故乡 </div>""" print(re.findall('.*',string1,re.S)[0]) """ <div>静夜思 窗前明月光 疑是地上霜 举头望明月 低头思故乡 </div> """
#!/usr/bin/env python # -*- coding:utf-8 -*- import requests import re import os if __name__ == "__main__": url = 'https://www.qiushibaike.com/pic/%s/' headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #指定起始也结束页码 page_start = int(input('enter start page:')) page_end = int(input('enter end page:')) #创建文件夹 if not os.path.exists('images'): os.mkdir('images') #循环解析且下载指定页码中的图片数据 for page in range(page_start,page_end+1): print('正在下载第%d页图片'%page) new_url = format(url % page) response = requests.get(url=new_url,headers=headers) #解析response中的图片链接 e = '<div class="thumb">.*?<img src="(.*?)".*?>.*?</div>' pa = re.compile(e,re.S) image_urls = pa.findall(response.text) #循环下载该页码下所有的图片数据 for image_url in image_urls: image_url = 'https:' + image_url image_name = image_url.split('/')[-1] image_path = 'images/'+image_name image_data = requests.get(url=image_url,headers=headers).content with open(image_path,'wb') as fp: fp.write(image_data)
Xpath解析
一、常用xpath表达式:
属性定位:
#找到class属性值为song的div标签
//div[@class="song"]
层级&索引定位:
#找到class属性值为tang的div的直系子标签ul下的第二个子标签li下的直系子标签a
//div[@class="tang"]/ul/li[2]/a 逻辑运算: #找到href属性值为空且class属性值为du的a标签 //a[@href="" and @class="du"] 模糊匹配: //div[contains(@class, "ng")] //div[starts-with(@class, "ta")] 取文本: # /表示获取某个标签下的文本内容 # //表示获取某个标签下的文本内容和所有子标签下的文本内容 //div[@class="song"]/p[1]/text() //div[@class="tang"]//text() 取属性: //div[@class="tang"]//li[2]/a/@href二、代码中使用xpath表达式进行数据解析:
1.下载:pip install lxml
2.导包:from lxml import etree
3.将html文档或者xml文档转换成一个etree对象,然后调用对象中的方法查找指定的节点 2.1 本地文件:tree = etree.parse(文件名) tree.xpath("xpath表达式") 2.2 网络数据:tree = etree.HTML(网页内容字符串) tree.xpath("xpath表达式")三、安装xpath插件在浏览器中对xpath表达式进行验证:可以在插件中直接执行xpath表达式
-
将xpath插件拖动到谷歌浏览器拓展程序(更多工具)中,安装成功
-
启动和关闭插件 ctrl + shift + x
from lxml import etree import requests url='http://www.haoduanzi.com/category-10_2.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', } url_content=requests.get(url,headers=headers).text #使用xpath对url_conten进行解析 #使用xpath解析从网络上获取的数据 tree=etree.HTML(url_content) #解析获取当页所有段子的标题 title_list=tree.xpath('//div[@class="log cate10 auth1"]/h3/a/text()') ele_div_list=tree.xpath('//div[@class="log cate10 auth1"]') text_list=[] #最终会存储12个段子的文本内容 for ele in ele_div_list: #段子的文本内容(是存放在list列表中) text_list=ele.xpath('./div[@class="cont"]//text()') #list列表中的文本内容全部提取到一个字符串中 text_str=str(text_list) #字符串形式的文本内容防止到all_text列表中 text_list.append(text_str) print(title_list) print(text_list)
import requests from lxml import etree from fake_useragent import UserAgent import base64 import urllib.request url = 'http://jandan.net/ooxx' ua = UserAgent(verify_ssl=False,use_cache_server=False).random headers = { 'User-Agent':ua } # headers = { # 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', # } page_text = requests.get(url=url,headers=headers).text #查看页面源码:发现所有图片的src值都是一样的。 #简单观察会发现每张图片加载都是通过jandan_load_img(this)这个js函数实现的。 #在该函数后面还有一个class值为img-hash的标签,里面存储的是一组hash值,该值就是加密后的img地址 #加密就是通过js函数实现的,所以分析js函数,获知加密方式,然后进行解密。 #通过抓包工具抓取起始url的数据包,在数据包中全局搜索js函数名(jandan_load_img),然后分析该函数实现加密的方式。 #在该js函数中发现有一个方法调用,该方法就是加密方式,对该方法进行搜索 #搜索到的方法中会发现base64和md5等字样,md5是不可逆的所以优先考虑使用base64解密 print(page_text) tree = etree.HTML(page_text) #在抓包工具的数据包响应对象对应的页面中进行xpath的编写,而不是在浏览器页面中。 #获取了加密的图片url数据 imgCode_list = tree.xpath('//span[@class="img-hash"]/text()') imgUrl_list = [] for url in imgCode_list: #base64.b64decode(url)为byte类型,需要转成str img_url = 'http:'+base64.b64decode(url).decode() imgUrl_list.append(img_url) for url in imgUrl_list: filePath = url.split('/')[-1] urllib.request.urlretrieve(url=url,filename=filePath) print(filePath+'下载成功')
BeautifulSoup解析
一、环境安装
- 需要将pip源设置为国内源,阿里源、豆瓣源、网易源等
- windows
(1)打开文件资源管理器(文件夹地址栏中)
(2)地址栏上面输入 %appdata%
(3)在这里面新建一个文件夹 pip
(4)在pip文件夹里面新建一个文件叫做 pip.ini ,内容写如下即可
[global] timeout = 6000 index-url = https://mirrors.aliyun.com/pypi/simple/ trusted-host = mirrors.aliyun.com - linux (1)cd ~ (2)mkdir ~/.pip (3)vi ~/.pip/pip.conf (4)编辑内容,和windows一模一样 - 需要安装:pip install bs4 bs4在使用时候需要一个第三方库,把这个库也安装一下 pip install lxml二、基础使用
使用流程:
- 导包:from bs4 import BeautifulSoup
- 使用方式:可以将一个html文档,转化为BeautifulSoup对象,然后通过对象的方法或者属性去查找指定的节点内容
(1)转化本地文件:
- soup = BeautifulSoup(open('本地文件'), 'lxml') (2)转化网络文件: - soup = BeautifulSoup('字符串类型或者字节类型', 'lxml') (3)打印soup对象显示内容为html文件中的内容 基础巩固: (1)根据标签名查找 - soup.a 只能找到第一个符合要求的标签 (2)获取属性 - soup.a.attrs 获取a所有的属性和属性值,返回一个字典 - soup.a.attrs['href'] 获取href属性 - soup.a['href'] 也可简写为这种形式 (3)获取内容 - soup.a.string - soup.a.text - soup.a.get_text() 【注意】如果标签还有标签,那么string获取到的结果为None,而其它两个,可以获取文本内容 (4)find:找到第一个符合要求的标签 - soup.find('a') 找到第一个符合要求的 - soup.find('a', title="xxx") - soup.find('a', alt="xxx") - soup.find('a', class_="xxx") - soup.find('a', id="xxx") (5)find_all:找到所有符合要求的标签 - soup.find_all('a') - soup.find_all(['a','b']) 找到所有的a和b标签 - soup.find_all('a', limit=2) 限制前两个 (6)根据选择器选择指定的内容 select:soup.select('#feng') - 常见的选择器:标签选择器(a)、类选择器(.)、id选择器(#)、层级选择器 - 层级选择器: div .dudu #lala .meme .xixi 下面好多级 div > p > a > .lala 只能是下面一级 【注意】select选择器返回永远是列表,需要通过下标提取指定的对象import requests from bs4 import BeautifulSoup headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } def parse_content(url): #获取标题正文页数据 page_text = requests.get(url,headers=headers).text soup = BeautifulSoup(page_text,'lxml') #解析获得标签 ele = soup.find('div',class_='chapter_content') content = ele.text #获取标签中的数据值 return content if __name__ == "__main__": url = 'http://www.shicimingju.com/book/sanguoyanyi.html' reponse = requests.get(url=url,headers=headers) page_text = reponse.text #创建soup对象 soup = BeautifulSoup(page_text,'lxml') #解析数据 a_eles = soup.select('.book-mulu > ul > li > a') print(a_eles) cap = 1 for ele in a_eles: print('开始下载第%d章节'%cap) cap+=1 title = ele.string content_url = 'http://www.shicimingju.com'+ele['href'] content = parse_content(content_url) with open('./sanguo.txt','w') as fp: fp.write(title+":"+content+'\n\n\n\n\n') print('结束下载第%d章节'%cap)
requests模块
- 什么是requests模块
- requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。在爬虫领域中占据着半壁江山的地位。
- 为什么要使用requests模块
- 因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
- 手动处理url编码
- 手动处理post请求参数
- 处理cookie和代理操作繁琐
- ......
- 使用requests模块:
- 自动处理url编码
- 自动处理post请求参数
- 简化cookie和代理操作
- ......
- 因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
- 如何使用requests模块
- 安装:
- pip install requests
- 使用流程
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据值
- 数据解析(正则解析,xpath解析,bs4解析)
- 持久化存储
- 安装:
- 使用
- 基于requests模块的get请求
- 基于requests模块的post请求
- 基于requests模块ajax的get请求
- 基于requests模块ajax的post请求
- 基于requests模块的cookie操作
- 基于requests模块的代理操作
- 基于multiprocessing.dummy线程池的数据爬取
#!/usr/bin/env python # -*- coding:utf-8 -*- import requests #指定搜索关键字 word = input('enter a word you want to search:') #自定义请求头信息 headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 'Connection':'close', # 表示每次请求成功后断开连接 } #指定url url = 'https://www.sogou.com/web' #封装get请求参数 prams = { 'query':word, 'ie':'utf-8' } #发起请求 response = requests.get(url=url,params=prams,headers=headers) response.encoding='utf-8' #获取响应数据 page_text = response.text with open('./sougou.html','w',encoding='utf-8') as fp: fp.write(page_text)
#!/usr/bin/env python # -*- coding: utf-8 -*- import requests import urllib.request if __name__ == "__main__": #指定ajax-get请求的url(通过抓包进行获取) url = 'https://movie.douban.com/j/chart/top_list?' #定制请求头信息,相关的头信息必须封装在字典结构中 headers = { #定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', } #定制get请求携带的参数(从抓包工具中获取) param = { 'type':'5', 'interval_id':'100:90', 'action':'', 'start':'0', 'limit':'20' } #发起get请求,获取响应对象 response = requests.get(url=url,headers=headers,params=param) #获取响应内容:响应内容为json串 print(response.text)
#!/usr/bin/env python # -*- coding: utf-8 -*- import requests import os url = 'https://accounts.douban.com/login' #封装请求参数 data = { "source": "movie", "redir": "https://movie.douban.com/", "form_email": "15027900535", "form_password": "bobo@15027900535", "login": "登录", } #自定义请求头信息 headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } response = requests.post(url=url,data=data) page_text = response.text with open('./douban111.html','w',encoding='utf-8') as fp: fp.write(page_text)
#!/usr/bin/env python # -*- coding: utf-8 -*- import requests import urllib.request if __name__ == "__main__": #指定ajax-post请求的url(通过抓包进行获取) url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' #定制请求头信息,相关的头信息必须封装在字典结构中 headers = { #定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', } #定制post请求携带的参数(从抓包工具中获取) data = { 'cname':'', 'pid':'', 'keyword':'北京', 'pageIndex': '1', 'pageSize': '10' } #发起post请求,获取响应对象 response = requests.get(url=url,headers=headers,data=data) #获取响应内容:响应内容为json串 print(response.text)
#!/usr/bin/env python # -*- coding: utf-8 -*- import requests from fake_useragent import UserAgent ua = UserAgent(use_cache_server=False,verify_ssl=False).random headers = { 'User-Agent':ua } url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList' pageNum = 3 for page in range(3,5): data = { 'on': 'true', 'page': str(page), 'pageSize': '15', 'productName':'', 'conditionType': '1', 'applyname':'', 'applysn':'' } json_text = requests.post(url=url,data=data,headers=headers).json() all_id_list = [] for dict in json_text['list']: id = dict['ID']#用于二级页面数据获取 #下列详情信息可以在二级页面中获取 # name = dict['EPS_NAME'] # product = dict['PRODUCT_SN'] # man_name = dict['QF_MANAGER_NAME'] # d1 = dict['XC_DATE'] # d2 = dict['XK_DATE'] all_id_list.append(id) #该url是一个ajax的post请求 post_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' for id in all_id_list: post_data = { 'id':id } response = requests.post(url=post_url,data=post_data,headers=headers) #该请求响应回来的数据有两个,一个是基于text,一个是基于json的,所以可以根据content-type,来获取指定的响应数据 if response.headers['Content-Type'] == 'application/json;charset=UTF-8': #print(response.json()) #进行json解析 json_text = response.json() print(json_text['businessPerson'])
#!/usr/bin/env python # -*- coding:utf-8 -*- """ - cookie概念:当用户通过浏览器首次访问一个域名时,访问的web服务器会给客户端发送数据,以保持web服务器与客户端之间的状态保持,这些数据就是cookie。 - cookie作用:我们在浏览器中,经常涉及到数据的交换,比如你登录邮箱,登录一个页面。我们经常会在此时设置30天内记住我,或者自动登录选项。 那么它们是怎么记录信息的呢,答案就是今天的主角cookie了,Cookie是由HTTP服务器设置的,保存在浏览器中,但HTTP协议是一种无状态协议, 在数据交换完毕后,服务器端和客户端的链接就会关闭,每次交换数据都需要建立新的链接。就像我们去超市买东西,没有积分卡的情况下, 我们买完东西之后,超市没有我们的任何消费信息,但我们办了积分卡之后,超市就有了我们的消费信息。cookie就像是积分卡,可以保存积分, 商品就是我们的信息,超市的系统就像服务器后台,http协议就是交易的过程。 - 经过cookie的相关介绍,其实你已经知道了为什么上述案例中爬取到的不是张三个人信息页,而是登录页面。那应该如何抓取到张三的个人信息页呢? 思路: 1.我们需要使用爬虫程序对人人网的登录时的请求进行一次抓取,获取请求中的cookie数据 2.在使用个人信息页的url进行请求时,该请求需要携带 1 中的cookie,只有携带了cookie后, 服务器才可识别这次请求的用户信息,方可响应回指定的用户信息页数据 """ import requests if __name__ == "__main__": #登录请求的url(通过抓包工具获取) post_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=201873958471' #创建一个session对象,该对象会自动将请求中的cookie进行存储和携带 session = requests.session() #伪装UA headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } formdata = { 'email': '17701256561', 'icode': '', 'origURL': 'http://www.renren.com/home', 'domain': 'renren.com', 'key_id': '1', 'captcha_type': 'web_login', 'password': '7b456e6c3eb6615b2e122a2942ef3845da1f91e3de075179079a3b84952508e4', 'rkey': '44fd96c219c593f3c9612360c80310a3', 'f': 'https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Dm7m_NSUp5Ri_ZrK5eNIpn_dMs48UAcvT-N_kmysWgYW%26wd%3D%26eqid%3Dba95daf5000065ce000000035b120219', } #使用session发送请求,目的是为了将session保存该次请求中的cookie session.post(url=post_url,data=formdata,headers=headers) get_url = 'http://www.renren.com/960481378/profile' #再次使用session进行请求的发送,该次请求中已经携带了cookie response = session.get(url=get_url,headers=headers) #设置响应内容的编码格式 response.encoding = 'utf-8' #将响应内容写入文件 with open('./renren.html','w') as fp: fp.write(response.text)
#!/usr/bin/env python # -*- coding:utf-8 -*- import requests import random if __name__ == "__main__": #不同浏览器的UA header_list = [ # 遨游 {"user-agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)"}, # 火狐 {"user-agent": "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"}, # 谷歌 { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"} ] #不同的代理IP proxy_list = [ {"http": "112.115.57.20:3128"}, {'http': '121.41.171.223:3128'} ] #随机获取UA和代理IP header = random.choice(header_list) proxy = random.choice(proxy_list) url = 'http://www.baidu.com/s?ie=UTF-8&wd=ip' #参数3:设置代理 response = requests.get(url=url,headers=header,proxies=proxy) response.encoding = 'utf-8' with open('daili.html', 'wb') as fp: fp.write(response.content) #切换成原来的IP requests.get(url, proxies={"http": ""})
import requests import random from lxml import etree import re from fake_useragent import UserAgent # 安装fake-useragent库:pip install fake-useragent url = 'http://www.pearvideo.com/category_1' # 随机产生UA,如果报错则可以添加如下参数: # ua = UserAgent(verify_ssl=False,use_cache_server=False).random # 禁用服务器缓存: # ua = UserAgent(use_cache_server=False) # 不缓存数据: # ua = UserAgent(cache=False) # 忽略ssl验证: # ua = UserAgent(verify_ssl=False) ua = UserAgent().random headers = { 'User-Agent': ua } # 获取首页页面数据 page_text = requests.get(url=url, headers=headers).text # 对获取的首页页面数据中的相关视频详情链接进行解析 tree = etree.HTML(page_text) li_list = tree.xpath('//div[@id="listvideoList"]/ul/li') detail_urls = [] for li in li_list: detail_url = 'http://www.pearvideo.com/' + li.xpath('./div/a/@href')[0] title = li.xpath('.//div[@class="vervideo-title"]/text()')[0] detail_urls.append(detail_url) for url in detail_urls: page_text = requests.get(url=url, headers=headers).text vedio_url = re.findall('srcUrl="(.*?)"', page_text, re.S)[0] data = requests.get(url=vedio_url, headers=headers).content fileName = str(random.randint(1, 10000)) + '.mp4' # 随机生成视频文件名称 with open(fileName, 'wb') as fp: fp.write(data) print(fileName + ' is over')
import requests import random from lxml import etree import re from fake_useragent import UserAgent #安装fake-useragent库:pip install fake-useragent #导入线程池模块 from multiprocessing.dummy import Pool #实例化线程池对象 pool = Pool() url = 'http://www.pearvideo.com/category_1' #随机产生UA ua = UserAgent().random headers = { 'User-Agent':ua } #获取首页页面数据 page_text = requests.get(url=url,headers=headers).text #对获取的首页页面数据中的相关视频详情链接进行解析 tree = etree.HTML(page_text) li_list = tree.xpath('//div[@id="listvideoList"]/ul/li') detail_urls = []#存储二级页面的url for li in li_list: detail_url = 'http://www.pearvideo.com/'+li.xpath('./div/a/@href')[0] title = li.xpath('.//div[@class="vervideo-title"]/text()')[0] detail_urls.append(detail_url) vedio_urls = []#存储视频的url for url in detail_urls: page_text = requests.get(url=url,headers=headers).text vedio_url = re.findall('srcUrl="(.*?)"',page_text,re.S)[0] vedio_urls.append(vedio_url) #使用线程池进行视频数据下载 func_request = lambda link:requests.get(url=link,headers=headers).content video_data_list = pool.map(func_request,vedio_urls) #使用线程池进行视频数据保存 func_saveData = lambda data:save(data) pool.map(func_saveData,video_data_list) def save(data): fileName = str(random.randint(1,10000))+'.mp4' with open(fileName,'wb') as fp: fp.write(data) print(fileName+'已存储') pool.close() pool.join()
验证码处理
相关的门户网站在进行登录的时候,如果用户连续登录的次数超过3次或者5次的时候,就会在登录页中动态生成验证码。通过验证码达到分流和反爬的效果。
云打码平台处理验证码的实现流程:
- 1.对携带验证码的页面数据进行抓取
- 2.可以将页面数据中验证码进行解析,验证码图片下载到本地
- 3.可以将验证码图片提交给三方平台进行识别,返回验证码图片上的数据值
- 云打码平台:
- 1.在官网中进行注册(普通用户和开发者用户)
- 2.登录开发者用户:
- 1.实例代码的下载(开发文档-》调用实例及最新的DLL-》PythonHTTP实例下载)
- 2.创建一个软件:我的软件-》添加新的软件
-3.使用示例代码中的源码文件中的代码进行修改,让其识别验证码图片中的数据值
#该函数就调用了打码平台的相关的接口对指定的验证码图片进行识别,返回图片上的数据值 def getCode(codeImg): # 云打码平台普通用户的用户名 username = 'bobo328410948' # 云打码平台普通用户的密码 password = 'bobo328410948' # 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得! appid = 6003 # 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得! appkey = '1f4b564483ae5c907a1d34f8e2f2776c' # 验证码图片文件 filename = codeImg # 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html codetype = 3000 # 超时时间,秒 timeout = 20 # 检查 if (username == 'username'): print('请设置好相关参数再测试') else: # 初始化 yundama = YDMHttp(username, password, appid, appkey) # 登陆云打码 uid = yundama.login(); print('uid: %s' % uid) # 查询余额 balance = yundama.balance(); print('balance: %s' % balance) # 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果 cid, result = yundama.decode(filename, codetype, timeout); print('cid: %s, result: %s' % (cid, result)) return result
import requests from lxml import etree import json import time import re #1.对携带验证码的页面数据进行抓取 url = 'https://www.douban.com/accounts/login?source=movie' headers = { 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Mobile Safari/537.36' } page_text = requests.get(url=url,headers=headers).text #2.可以将页面数据中验证码进行解析,验证码图片下载到本地 tree = etree.HTML(page_text) codeImg_url = tree.xpath('//*[@id="captcha_image"]/@src')[0] #获取了验证码图片对应的二进制数据值 code_img = requests.get(url=codeImg_url,headers=headers).content #获取capture_id '<img id="captcha_image" src="https://www.douban.com/misc/captcha?id=AdC4WXGyiRuVJrP9q15mqIrt:en&size=s" alt="captcha" class="captcha_image">' c_id = re.findall('<img id="captcha_image".*?id=(.*?)&.*?>',page_text,re.S)[0] with open('./code.png','wb') as fp: fp.write(code_img) #获得了验证码图片上面的数据值 codeText = getCode('./code.png') print(codeText) #进行登录操作 post = 'https://accounts.douban.com/login' data = { "source": "movie", "redir": "https://movie.douban.com/", "form_email": "15027900535", "form_password": "bobo@15027900535", "captcha-solution":codeText, "captcha-id":c_id, "login": "登录", } print(c_id) login_text = requests.post(url=post,data=data,headers=headers).text with open('./login.html','w',encoding='utf-8') as fp: fp.write(login_text)
Python网络爬虫之图片懒加载技术、selenium和PhantomJS
- 图片懒加载
- selenium
- phantomJs
- 谷歌无头浏览器
一、图片懒加载
-
图片懒加载概念:
-
图片懒加载是一种网页优化技术。图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间。为了解决这种问题,通过前后端配合,使图片仅在浏览器当前视窗内出现时才加载该图片,达到减少首屏图片请求数的技术就被称为“图片懒加载”。
-
-
网站一般如何实现图片懒加载技术呢?
-
在网页源码中,在img标签中首先会使用一个“伪属性”(通常使用src2,original......)去存放真正的图片链接而并非是直接存放在src属性中。当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载。
-
#!/usr/bin/env python # -*- coding:utf-8 -*- #站长素材案例后续分析:通过细致观察页面的结构后发现,网页中图片的链接是存储在了src2这个伪属性中 import requests from lxml import etree if __name__ == "__main__": url = 'http://sc.chinaz.com/tupian/gudianmeinvtupian.html' headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #获取页面文本数据 response = requests.get(url=url,headers=headers) response.encoding = 'utf-8' page_text = response.text #解析页面数据(获取页面中的图片链接) #创建etree对象 tree = etree.HTML(page_text) div_list = tree.xpath('//div[@id="container"]/div') #解析获取图片地址和图片的名称 for div in div_list: image_url = div.xpath('.//img/@src2') #src2伪属性 image_name = div.xpath('.//img/@alt') print(image_url) #打印图片链接 print(image_name)#打印图片名称
二、selenium
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS。
- 下载安装selenium:pip install selenium
- 下载浏览器驱动程序:
- http://chromedriver.storage.googleapis.com/index.html
- 查看驱动和浏览器版本的映射关系:
- http://blog.csdn.net/huilan_same/article/details/51896672
三、浏览器创建
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS。
四、元素定位
webdriver 提供了一系列的元素定位方法,常用的有以下几种:
注意
1、find_element_by_xxx找的是第一个符合条件的标签,find_elements_by_xxx找的是所有符合条件的标签。
2、根据ID、CSS选择器和XPath获取,它们返回的结果完全一致。
3、另外,Selenium还提供了通用方法find_element(),它需要传入两个参数:查找方式By和值。实际上,它就是find_element_by_id()这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID, id),二者得到的结果完全一致。
五、节点交互
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用send_keys()方法,清空文字时用clear()方法,点击按钮时用click()方法。示例如下:
六、动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
七、执行JavaScript
对于某些操作,Selenium API并没有提供。比如,下拉进度条,它可以直接模拟运行JavaScript,此时使用execute_script()方法即可实现,代码如下:
八、获取页面源码数据
通过page_source属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery等)来提取信息了。
九、前进和后退
十、Cookie处理
使用Selenium,还可以方便地对Cookies进行操作,例如获取、添加、删除Cookies等。示例如下:
十一、异常处理
十二、phantomJS
PhantomJS是一款无界面的浏览器,其自动化操作流程和上述操作谷歌浏览器是一致的。由于是无界面的,为了能够展示自动化操作流程,PhantomJS为用户提供了一个截屏的功能,使用save_screenshot函数实现。
十三、谷歌无头浏览器
由于PhantomJs最近已经停止了更新和维护,所以推荐大家可以使用谷歌的无头浏览器,是一款无界面的谷歌浏览器。
十四、selenium规避被检测识别
现在不少大网站有对selenium采取了监测机制。比如正常情况下我们用浏览器访问淘宝等网站的 window.navigator.webdriver的值为
undefined。而使用selenium访问则该值为true。那么如何解决这个问题呢?
只需要设置Chromedriver的启动参数即可解决问题。在启动Chromedriver之前,为Chrome开启实验性功能参数excludeSwitches,它的值为['enable-automation'],完整代码如下:
from selenium import webdriver from time import sleep # 后面是你的浏览器驱动位置,记得前面加r'','r'是防止字符转义的 driver = webdriver.Chrome(r'驱动程序路径') # 用get打开百度页面 driver.get("http://www.baidu.com") # 查找页面的“设置”选项,并进行点击 driver.find_elements_by_link_text('设置')[0].click() sleep(2) # # 打开设置后找到“搜索设置”选项,设置为每页显示50条 driver.find_elements_by_link_text('搜索设置')[0].click() sleep(2) # 选中每页显示50条 m = driver.find_element_by_id('nr') sleep(2) m.find_element_by_xpath('//*[@id="nr"]/option[3]').click() m.find_element_by_xpath('.//option[3]').click() sleep(2) # 点击保存设置 driver.find_elements_by_class_name("prefpanelgo")[0].click() sleep(2) # 处理弹出的警告页面 确定accept() 和 取消dismiss() driver.switch_to_alert().accept() sleep(2) # 找到百度的输入框,并输入 美女 driver.find_element_by_id('kw').send_keys('美女') sleep(2) # 点击搜索按钮 driver.find_element_by_id('su').click() sleep(2) # 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面 driver.find_elements_by_link_text('美女_百度图片')[0].click() sleep(3) # 关闭浏览器 driver.quit()
import requests from selenium import webdriver from lxml import etree import time driver = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver') driver.get('https://qzone.qq.com/') #在web 应用中经常会遇到frame 嵌套页面的应用,使用WebDriver 每次只能在一个页面上识别元素,对于frame 嵌套内的页面上的元素,直接定位是定位是定位不到的。这个时候就需要通过switch_to_frame()方法将当前定位的主体切换了frame 里。 driver.switch_to.frame('login_frame') driver.find_element_by_id('switcher_plogin').click() #driver.find_element_by_id('u').clear() driver.find_element_by_id('u').send_keys('328410948') #这里填写你的QQ号 #driver.find_element_by_id('p').clear() driver.find_element_by_id('p').send_keys('xxxxxx') #这里填写你的QQ密码 driver.find_element_by_id('login_button').click() time.sleep(2) driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') time.sleep(2) driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') time.sleep(2) driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') time.sleep(2) page_text = driver.page_source tree = etree.HTML(page_text) #执行解析操作 li_list = tree.xpath('//ul[@id="feed_friend_list"]/li') for li in li_list: text_list = li.xpath('.//div[@class="f-info"]//text()|.//div[@class="f-info qz_info_cut"]//text()') text = ''.join(text_list) print(text+'\n\n\n') driver.close()
from selenium import webdriver from time import sleep import time if __name__ == '__main__': url = 'https://movie.douban.com/typerank?type_name=%E6%81%90%E6%80%96&type=20&interval_id=100:90&action=' # 发起请求前,可以让url表示的页面动态加载出更多的数据 path = r'C:\Users\Administrator\Desktop\爬虫授课\day05\ziliao\phantomjs-2.1.1-windows\bin\phantomjs.exe' # 创建无界面的浏览器对象 bro = webdriver.PhantomJS(path) # 发起url请求 bro.get(url) time.sleep(3) # 截图 bro.save_screenshot('1.png') # 执行js代码(让滚动条向下偏移n个像素(作用:动态加载了更多的电影信息)) js = 'window.scrollTo(0,document.body.scrollHeight)' bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码 time.sleep(2) bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码 time.sleep(2) bro.save_screenshot('2.png') time.sleep(2) # 使用爬虫程序爬去当前url中的内容 html_source = bro.page_source # 该属性可以获取当前浏览器的当前页的源码(html) with open('./source.html', 'w', encoding='utf-8') as fp: fp.write(html_source) bro.quit()
移动端数据爬取
一、fiddler
1 什么是Fiddler?
Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是web调试的利器。
既然是代理,也就是说:客户端的所有请求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有响应,也都会先经过Fiddler然后发送到客户端,基于这个原因,Fiddler支持所有可以设置http代理为127.0.0.1:8888的浏览器和应用程序。使用了Fiddler之后,web客户端和服务器的请求如下所示:
利用可以设置代理的这个特点,我们就可以对手机APP进行抓包了。怎么设置?不急不急,让我先把Fiddler安装上吧!
Fiddler下载地址:https://www.telerik.com/fiddler
傻瓜式安装,一键到底。Fiddler软件界面如图所示:
二、手机APP抓包设置
1. Fiddler设置
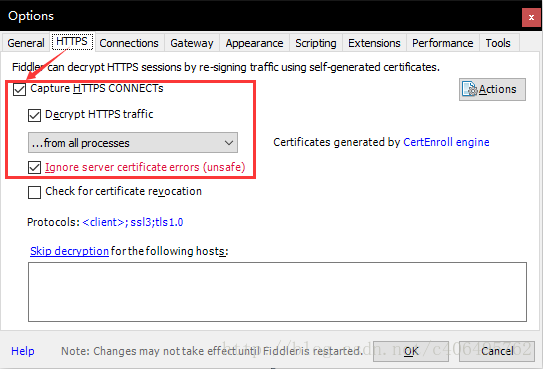
打开Fiddler软件,打开工具的设置。(Fiddler软件菜单栏:Tools->Options)
在HTTPS中设置如下:
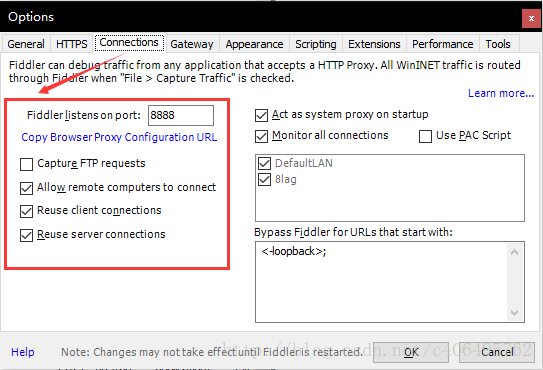
在Connections中设置如下,这里使用默认8888端口,当然也可以自己更改,但是注意不要与已经使用的端口冲突:
Allow remote computers to connect:允许别的机器把请求发送到fiddler上来
2.安全证书下载
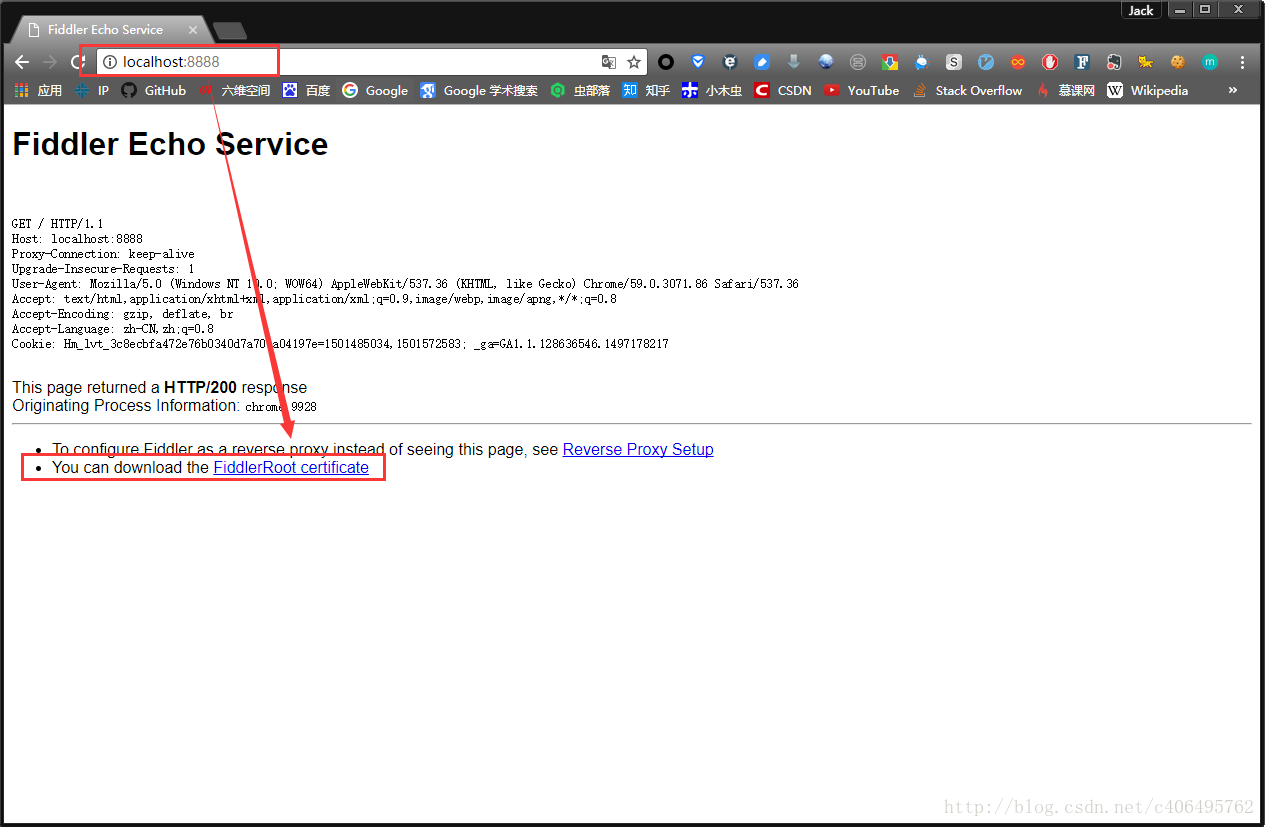
在电脑浏览器中输入地址:http://localhost:8888/,点击FiddlerRoot certificate,下载安全证书:
3.安全证书安装
证书是需要在手机上进行安装的,这样在电脑Fiddler软件抓包的时候,手机使用电脑的网卡上网才不会报错。
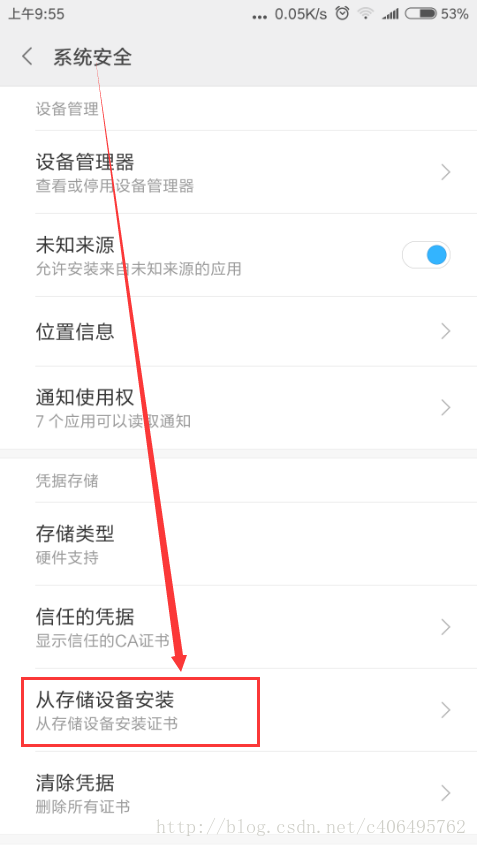
Android手机安装:把证书放入手机的内置或外置存储卡上,然后通过手机的"系统安全-》从存储设备安装"菜单安装证书。
然后找到拷贝的FiddlerRoot.cer进行安装即可。安装好之后,可以在信任的凭证中找到我们已经安装好的安全证书。
苹果手机安装:
- 保证手机网络和fiddler所在机器网络是同一个网段下的
- 在safari中访问http://fiddle机器ip:fiddler端口,进行证书下载。然后进行安装证书操作。
- 在手机中的设置-》通用-》关于本机-》证书信任设置-》开启fiddler证书信任
4、局域网设置
想要使用Fiddler进行手机抓包,首先要确保手机和电脑的网络在一个内网中,可以使用让电脑和手机都连接同一个路由器。当然,也可以让电脑开放WIFI热点,手机连入。这里,我使用的方法是,让手机和电脑同时连入一个路由器中。最后,让手机使用电脑的代理IP进行上网。
在手机上,点击连接的WIFI进行网络修改,添加代理。进行手动设置,ip和端口号都是fiddler机器的ip和fiddler上设置的端口号。
5、Fiddler手机抓包测试
上述步骤都设置完成之后,用手机浏览器打开百度首页,我们就可以顺利抓包了