最近在视频学习Java中并发与高并发的一些相关课程。目前已经学完了这门课程的基础知识部分,为了加深对知识的印象和理解,所以想写篇文章来加深下,也希望能带给读者们一些帮助。因为本人的知识和能力有限,有些知识点理解的不到位,希望大家多多指点和提出建议。
这门课程基础知识主要是分几大块来讲解的:并发与高并发相关概念、CPU多级缓存,缓存一致性、Java内存模型JMM规定,抽象结构同步操作与规则、并发优势和风险、并发模拟工具展示,以下我会对这几个点来进行阐述。
并发
说到并发可能好多人见词知意了,百度百科对其也有解释,但是要进行理解性的思考。所谓并发就是:同时拥有两个或多个线程,如果程序在单核处理器上运行,多个线程将交替地换入或者换出内存,这些线程是同时「 存在 」的,每个线程都处于执行过程中的某个状态,如果运行在多核处理器上,此时,程序中每个线程都将分配到一个处理器核上,因此可以同时运行。也就是说,并发就是多个线程操作相同的物理机中的资源,保证其线程安全,合理的利用资源。有了并发就会有「 高并发 」,可能很多人认为这两个是一种意思。但是其实是有区别的。
高并发(High Concurrency)
是现在互联网设计系统中需要考虑的一个重要因素之一,通常来说,就是通过严谨的设计来保证系统能够同时并行处理很多的请求。这就是大家常说的「 高并发 」。也就是说系统能够在某一时间段内提供很多请求,但是不会影响系统的性能。如果想设计出高可用和高性能的系统,就应该从很多的方面来考虑,例如应该从硬件、软件、编程语言的选择、网络方面的考虑、系统的整体架构、数据结构、算法的优化、数据库的优化等等多方面。这其中的每一点展开来说都要说很多的知识,就不一一展开来说。有兴趣的可以单独了解。
CPU缓存一致性
其实说实话,在学这门课程之前,我对计算机操作系统的一些底层实现逻辑是不关心的,其实这些就是基础,可能在你代码中不会涉及,但是你如果懂操作系统的一些原理,会帮助你写出更加高质量的代码。说到缓存一致性,就得先介绍计算机中的CPU和内存,因为在计算机中内存的计算效率和处理速度和CPU相比起来,差的不是一个量级,所以为了提高计算机的整体处理效率就在内存和CPU之前加了一层高级缓存(cache)用它来作为CPU和内存的一种缓冲:将运算需要使用到的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步回内存之中,这样处理器就无需等待缓慢的内存读写了。
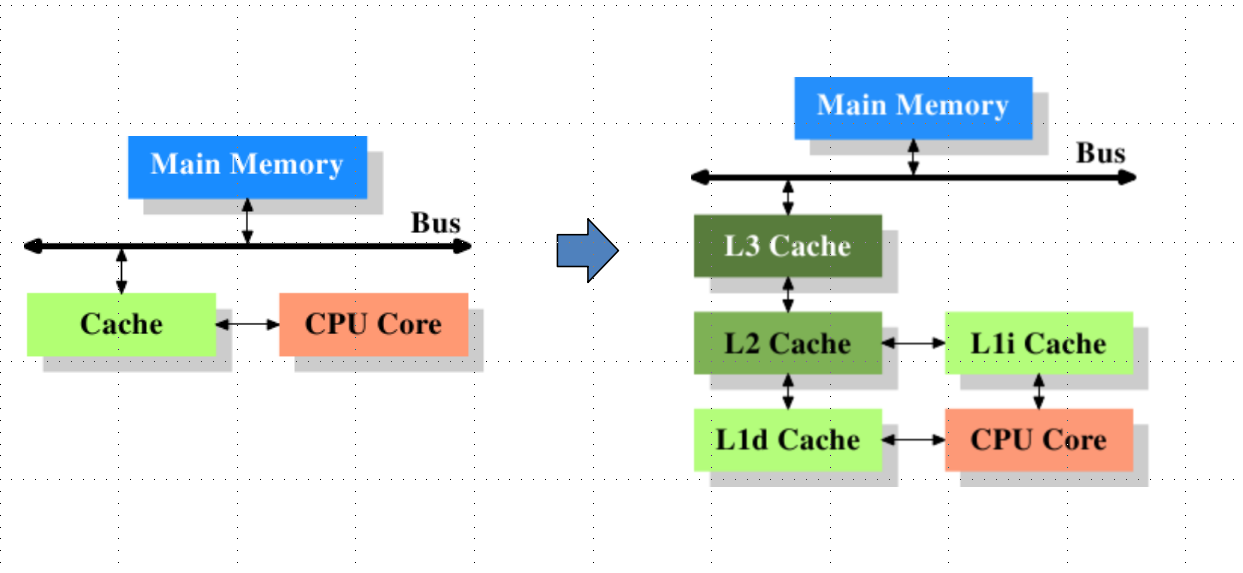
引入了一层高级缓存解决了处理性能上的问题,但是又引发了另一个问题。就是如何保证高级缓存、CPU寄存器(也是一种为了提高运算速度的东西)中的数据和主内存中的数据保持一致呢,这就是所谓的缓存一致性。在多核处理器的计算机当中,每个处理器有自己的高级缓存,而他们却公用一块主内存,也就是上图中的 Main Memory。在他们进行数据读写时,需要一种协议,目前作者了解到的协议大概有:MSI、MESI、MOSI及Dragon Protocol等。此外,为了能使CPU一直处在工作中,工作单元能被充分的利用,处理器可能会对输入代码进行乱序执行(Out-Of-Order Execution)优化。这和Java里面的指令冲排序(Instruction Recorder)相似。
Java内存模型(JMM--Java Memory Model)
Java内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样底层细节。此处的变量与Java编程时所说的变量不一样,指包括了实例字段、静态字段和构成数组对象的元素,但是不包括局部变量与方法参数,后者是线程私有的,不会被共享。
Java内存模型中规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存(可以与前面讲的处理器的高速缓存类比),线程的工作内存中保存了该线程使用到的变量到主内存副本拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要在主内存来完成,线程、主内存和工作内存的交互关系如下图所示。
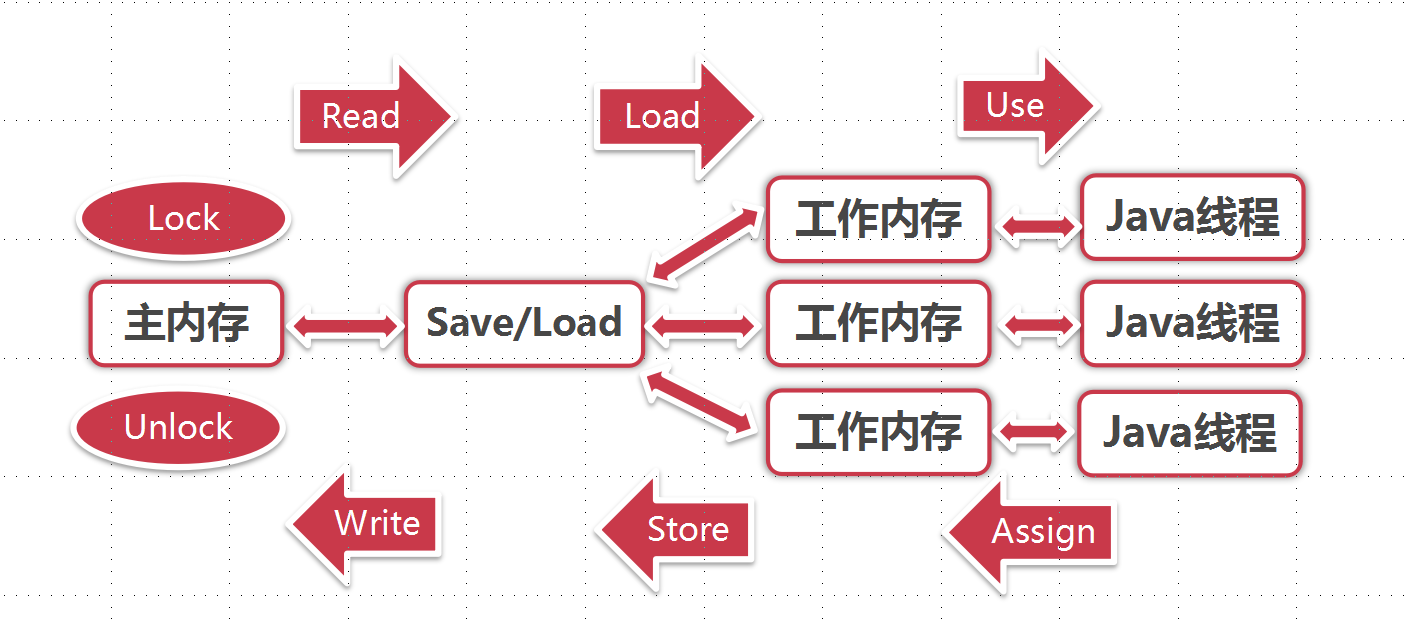
如上图所示,可以看出来内存交互中有八步的操作:lock、Unlock、Read、 Load、 Use、 Assign、 Store、 Write其中Read和Load Store和Write必必须按顺序执行,而没有保证必须是连续执行。另外还有Java内存模型的八项规则:
- 不允许read和load、store和write操作之一单独出现
- 不允许一个线程丢弃它的最近assign的操作,即变量在工作内存中改变了之后必须同步到主内存中。
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存中。
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量。即就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作。
- 一个变量在同一时刻只允许一条线程对其进行lock操作,lock和unlock必须成对出现
- 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值
- 如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量。
- 对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)。
并发的优势和风险
并发模拟工具展示
总结
目前基础知识我能想到的能总结这么多,通过写这篇文章也加深了我对知识的储备,也能让我看到自己知识不足的地方,学习有输入就要输出,希望能帮到那些热爱技术和乐于分享的人吧。当然,我之后会继续分享我所学的。谢谢支持!
文章部分知识参考文章:https://blog.csdn.net/u011080472/article/details/51337422