我有一组数据,在读取的时候不小心将列名放在了表格最后一行,因此表格第一行的列名为默认列名,Var1等等,格式如下。现在的需求是使用最后一行的列名替换掉默认的列名。
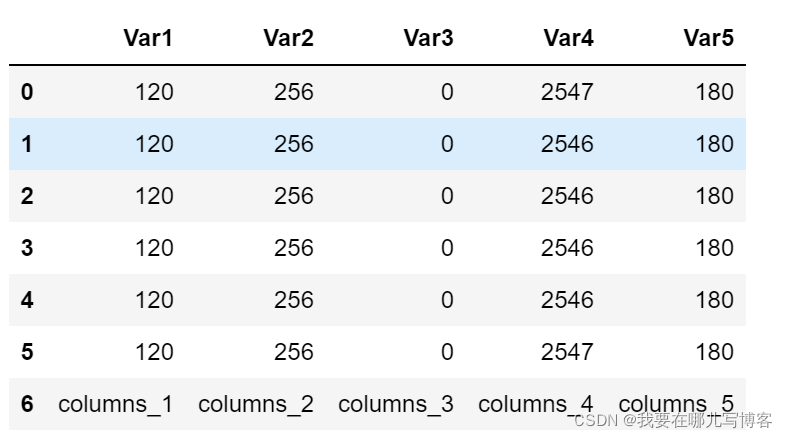
第一步,读取表格
//.csv文件读取办法
data = pd.read_csv('文件名.csv')
第二步,获取表格正确的列名,即最后一行的内容
columns = data.loc[len(data)-1]
columns

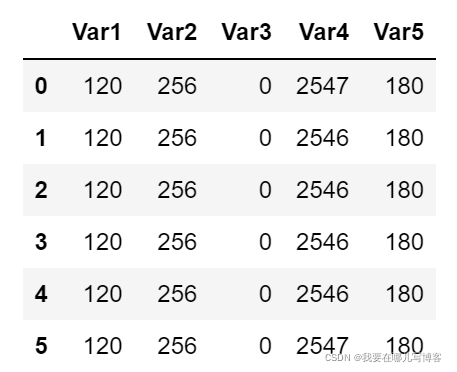
第三步,将上一步获取的真实标签值转化为列表,并替换掉默认的标签值,同时删除最后一行
data.columns = list(data.columns)
data = data.drop([len(data)-1])
data
如果一个文件夹下多个表格需要批量处理,则可使用循环,程序如下
filePath = r'文件夹路径名'
for file in os.listdir(filePath):
excelFile = os.path.join(filePath, file)
data = pd.read_csv(excelFile)
columns = data.loc[len(data)-1]
data.columns = list(columns)
data = data.drop([len(data)-1])
data.to_csv(excelFile, index=False)