Kafka 一个特点就是吞吐量大,而且是大数据场景的首选消息队列。根据真实生产环境数据,Kafka 单机能达到同时生产和消费百万级量级的数据量。
这到底是怎样的一个概念呢?我们结合生产环境中对生产端发送消息的某个测试来说明下。
- 生产环境配置:8 核 CPU,32G 内存,3 台机器分别安装 3 个 Broker,内网带宽很高,网络带宽瓶颈忽略不计。
- 测试方法:每个消息大小设计为 100B,然后分别测试 1、2、3 生产者生产消息,同时 1、2、3 消费者消费消息,最后得出生产和消费成功的消息数和消息字节数。
生产者发送消息的吞吐量
当 3 个 Producer 往 3 个 Broker 发送消息的时候,生产者每秒平均向每台 Broker 生产 100 万条消息。
下面是测试结果:
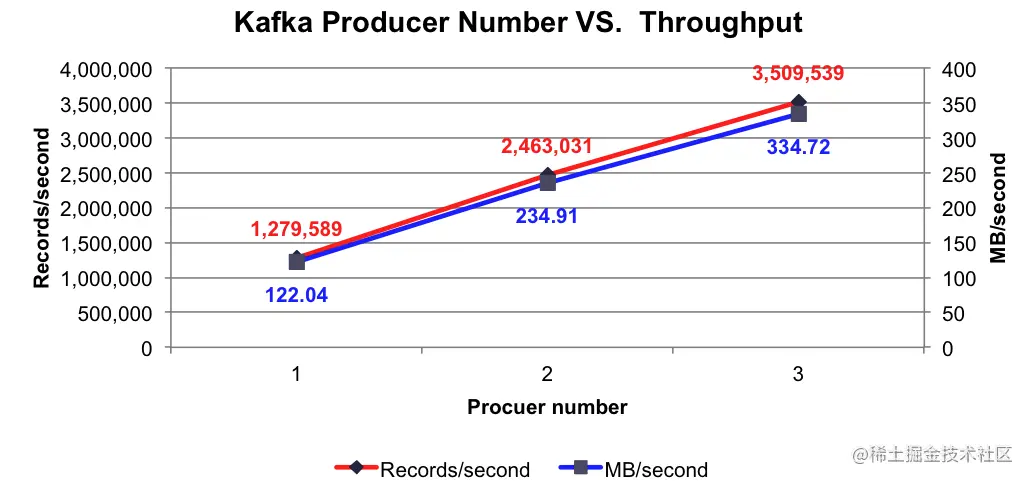
消费者消费消息的吞吐量
下面是测试结果:
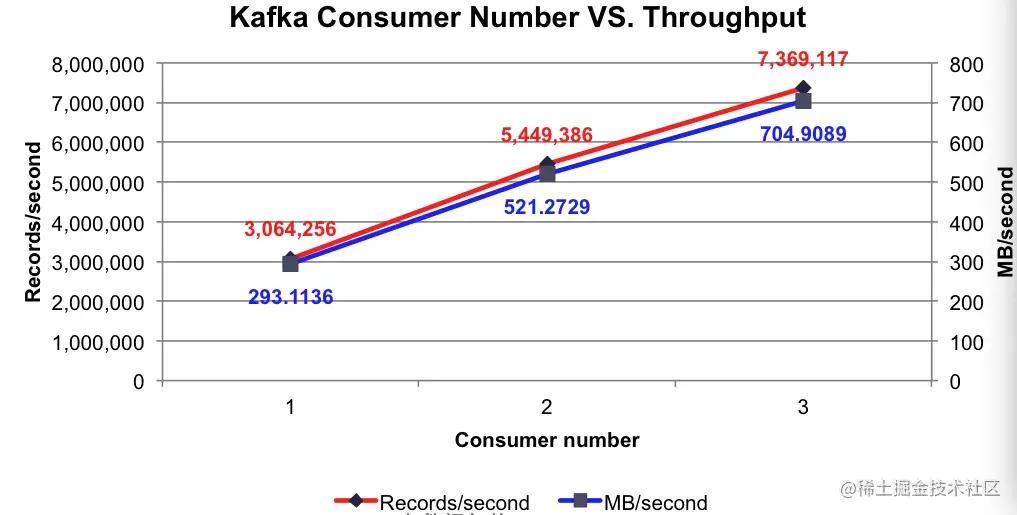
当 3 个 Consumer 向 3 个 Broker 拉取消息的时候,消费者每秒平均向每台 Broker 拉取 200 万条以上的消息。这个效果是不是很赞?
那么,Kafka 到底是如何做到这么高的吞吐量的呢?
Kafka 高吞吐架构特点
Kafka 采用了一系列的技术优化来保证高吞吐,这其中包括批量处理、压缩、零拷贝、磁盘顺序读写、页面缓存技术、Reactor 网络架构设计模式等。
- 采用到的技术有很多,这里我讲解的方式会跟前面课程讨论 Kafka 消息可靠性一样,主要从生产端、服务端和消费端三个方面来剖析和讨论。
- 除了讨论 Kafka 设计原理的内容以外,我还会介绍相关的参数配置和对应的源码,必要时也会分享一些可以借鉴的设计思想。
也就是说,我会带着你把 Kafka 高吞吐的设计要点都过一下,只要你能把这些要点搞明白,那么你就会对 Kafka 高吞吐相关的参数配置有更深入的了解。同时,我也会带你学到一些高性能的设计方法,以及操作系统底层的工作模式,这些都非常有利于你以后高效地设计出一个高吞吐的系统。
今天,我们主要讨论高吞吐在生产端上的体现。
生产端
Kafka 高吞吐量的特性在生产端这里是怎么体现的呢?要想回答这个问题,我们得首先了解下生产端是如何发送消息的,这属于铺垫知识。为便于你更好地理解这个过程,我画了如下一张流程图,它详细描述了生产端发送消息的全部流程:

结合该图,我们可以看到发送一条消息需要经历 7 个步骤,步骤比较多,但其实这些步骤可以分为三大块,分别是 KafkaProducer 主线程、RecordAccumulator 缓存和 Sender 子线程。
- KafkaProducer 主线程,主要负责创建信息,并调用拦截器、序列化器、分区器分别对消息进行拦截、序列化和路由分区,然后对消息进行压缩,把压缩过的消息放入 RecordAccumulator 缓存中。
- RecordAccumulator 缓存,为每个分区创建了一个队列,这个队列是要发送到某个分区的消息集合。
- Sender 子线程,是真正发送消息的线程。满足一定条件时,KafkaProducer 主线程会激活 Sender 子线程。Sender 子线程从 RecordAccumulator 缓存中拿到要发送的消息,并把消息交给底层网络组件来发送。对于网络接收和网络发送的数据,网络组件会通过两个缓存集合来维护:completedReceives 是负责保存完成的网络接收的集合,completedSends 是负责保存完成的网络发送的集合。服务端成功响应返回给 Sender 子线程后,Sender 子线程就会删除 RecordAccumulator 缓存内已经发送成功的消息。
介绍完生产端的这个架构设计后,接下来我就从以下三点解释一下这个架构从哪些方面提升了消息的吞吐量。
1. 多线程异步的设计
生产端在异步的设计上体现到了两个方面。
第一个方面,KafkaProducer 主线程和 Sender 子线程各司其职,通过 RecordAccumulator 缓存交互数据。
KafkaProducer 主线程有同步和异步两种发送方式,但是这两者底层的实现是相同的,都是通过 Sender 子线程异步发送消息实现的。不同的地方是同步场景下主线程会等待 Sender 子线程发送完消息再返回,而异步是不等待 Sender 子线程发送完消息就返回了。
KafkaProducer 主线程发送消息时并不是真正的网络发送,而是将消息放入 RecordAccumulator 中缓存,然后主线程就从 send() 方法返回,之后 KafkaProducer 主线程会不断调用 send() 方法把消息缓存到 RecordAccumulator 中,而不去在意消息是否发送出去了。真正发送消息的是 Sender 子线程,Sender 子线程从 RecordAccumulator 缓存中取出消息,然后调用底层网络组件完成消息的发送。
有的同学可能会有疑问:为什么不能把主线程和 Sender 子线程放到一个线程呢?一个线程里会有什么问题呢?
生产端发送消息有两个过程:创建消息和网络发送消息。这两个过程都有可能出现阻塞,比如,消息的创建依赖远程数据库或缓存,如果网络不好,线程就会阻塞在消息创建上;而生产端和服务端的通信不好时,也会导致出现阻塞的问题。如果这两个过程放到一个线程里的话,那么其中有一个发送阻塞,就会影响另一个过程的执行。
但是如果我们把创建消息交给主线程负责,发送消息交给子线程负责,这样这两个过程相互不影响,同时有缓存作为缓冲,很好地起到“削峰填谷”的作用。
2. Sender 子线程和 Kafka 底层通信模块解耦。
Sender 子线程最终是调用 Kafka 底层通信模块实现消息的发送和接收的。
我们知道 Java NIO 本质上是调用了 Linux 通信模块,Kafka 底层封装了 Java NIO 组件,特别是 org.apache.kafka.common.network.Selector(简称 KSelector)封装了 Java NIO 的 Selector 类,KSelector 在 Selector 的基础上增加了两个集合做缓冲,分别是 completedReceives 集合和 completedSends 集合,KSelector 发送成功和接收成功的消息都会放到这两个集合里。而 Sender 子线程通过 while(true) 循环不断地尝试从这两个集合获取消息,从而实现了这两个组件的解耦,道理也是一样,也是起到“削峰填谷”的作用,进而有利于高吞吐。
3. 在缓存中批量地获取数据,并做到高效的空间利用
这一点与 RecordAccumulator 类的设计关系很大,RecordAccumulator 类的设计图如下:

由图可以看到,在 RecordAccumulator 中有一个 CopyOnWriteMap 集合 batches。key 是主题分区,value 是 ProducerBatch 队列,每个分区都对应一个队列。队列中的元素是批次 ProducerBatch,消息就是封装在这些批次里进行缓存的。而消息发送的最小单位是 batch,也就是说一次消息发送可能不止一条消息,这样的设计大大减少了网络请求的次数,从而提升了网络读写的效率,进而提高了吞吐量。
接下来我们再来分析下消息的发送时机和逻辑。代码在 RecordAccumulator.drain() 方法内,其源码和源码注释如下:
`//五个判断条件决定是否是能发送的 boolean sendable = full || expired || exhausted || closed || flushInProgress();
//能发送且没有正在退避 if (sendable && !backingOff) {
//如果是能发送就加入readyNodes集合
readyNodes.add(leader); } else {
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
//还剩多久:需要等待的时间-已经等待的时间
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs); }`
这里我重点解释下决定是否发送的布尔型变量 sendable 的判断逻辑:五个判断条件只要有一个满足就能发送消息。这五个条件可总结为如下。
- full:deque 是否大于 1,或 deque 的第一个 ProducerBatch 是否满了。
- expired:ProducerBatch 在 deque 里是否超时。
- exhausted:BufferPool 是否正在释放空间。
- closed:生产者是否准备正常关闭了。
- flushInProgress:是否在 flush 操作,这个 flush 是把暂存消息立即发送的标记。
第一个判断条件是 deque 是否大于 1,或 deque 的第一个 ProducerBatch 是否满了,在 Broker 负载没满的情况下,deque 的第一个 ProducerBatch 是否满了是大部分情况下发送消息的时机。所以说,生产者发送消息并不是一条条发送的,而是一个一个 batch 发送的。
接下来我们再分析下生产端高效的空间利用特性。
缓存的空间分配是由 BufferPool 组件完成的,下面是其工作原理图:

整个 BufferPool 的大小默认为 32M,内部内存区域分为两块:固定大小内存块集合 free 和非池化缓存 nonPooledAvailableMemory。固定大小内存块默认大小为 16K。当 ProducerBatch 向 BufferPool 申请一个大小为 size 的内存块时,BufferPool 会根据 size 的大小判断由哪个内存区域分配内存块。
当 ProducerBatch 的数据发送成功后,ProducerBatch 并不会销毁,而是继续留在集合 free 中,这样需要 ProducerBatch 的时候就直接从集合中拿出,就不用频繁地销毁和重建了。其实 ProducerBatch 的底层是 Java NIO ByteBuffer,ByteBuffer 的创建和销毁是很消耗 CPU 资源的,这样的设计实现了 ByteBuffer 的重用,从而大大减少了对资源的消耗。