Datawhale202210——《深入浅出PyTorch》(8、9章)
torchvision+PyTorchVideo+torchtext+transforms实战+ONNX部署
文章目录
前言
这将是完成自己模型搭建的最后一程,同样有很多优秀的前辈支撑着我们继续前进,所以有必要仔细去了解一下PyTorch的生态,最终完成模型部署。
一、PyTorch生态优秀工具
DL的迅猛发展一定离不开开源社区的蓬勃发展,PyTorch作为主流的深度学习框架其生态圈也非常强大。之前的部分已经多次使用到优秀贡献者的工作,后面就专门介绍一下PyTorch的高质工具。
torchvision
" The torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision. "
torchvision的详细组成:
- torchvision.datasets *
- torchvision.models *
- torchvision.tramsforms *
- torchvision.io
- torchvision.ops
- torchvision.utils
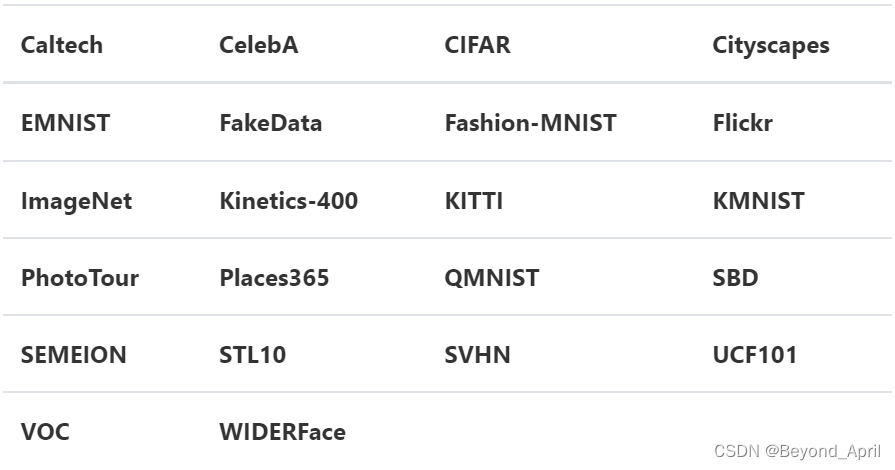
torchvision.datasets包含的数据集
torchvision.models:提供预训练模型,且覆盖很多DL任务

更多信息详见参考文档
torchvision.transforms *:数据预处理
from torchvision import transforms
data_transform = transforms.Compose([
transforms.ToPILImage(), # 这一步取决于后续的数据读取方式,如果使用内置数据集则不需要
transforms.Resize(image_size),
transforms.ToTensor()
])
更多操作详见参考文档
torchvision.io:提供了视频、图片和文件的 IO 操作的功能,包括读取、写入、编解码处理操作.
使用它的过程需要注意以下几点:
- 不同版本之间,torchvision.io有着较大变化,因此在使用时,需要查看下我们的torchvision版本是否存在你想使用的方法。
- 除了read_video()等方法,torchvision.io为我们提供了一个细粒度的视频API torchvision.io.VideoReader() ,它具有更高的效率并且更加接近底层处理。在使用时,我们需要先安装ffmpeg然后从源码重新编译torchvision我们才能我们能使用这些方法。
- 在使用Video相关API时,我们最好提前安装好PyAV这个库。
torchvision.ops:提供了许多计算机视觉的特定操作,包括但不仅限于NMS,RoIAlign(MASK R-CNN中应用的一种方法),RoIPool(Fast R-CNN中用到的一种方法)。
torchvision.utils:提供了一些可视化的方法,可以帮助我们将若干张图片拼接在一起、可视化检测和分割的效果。
更多信息详见参考文档
PyTorchVideo
以视频为信息媒介是各媒体平台的主流,而深度学习也提供了很多有关视频的操作。但长期适应图像工作的DL在处理视频上,仍然有许多问题要解决:
- 计算资源耗费更多,并且没有高质量的model zoo,不能像图片一样进行迁移学习和论文复现。
- 数据集处理较麻烦,但没有一个很好的视频处理工具。
- 随着多模态越来越流行,亟需一个工具来处理其他模态。
为了更好地应对日益强烈的视频处理需求,Meta推出了PyTorchVideo深度学习库。
PyTorchVideo:专注于视频理解工作的深度学习库。PytorchVideo 提供了加速视频理解研究所需的可重用、模块化和高效的组件。PyTorchVideo 是使用PyTorch开发的,支持不同的深度学习视频组件,如视频模型、视频数据集和视频特定转换。
更多信息详见参考文档
torchtext
自然语言处理也是深度学习的一大应用场景,近年来随着大规模预训练模型的应用,深度学习在人机对话、机器翻译等领域的取得了非常好的效果。由于NLP和CV在数据预处理中的不同,因此NLP的工具包torchtext和torchvision等CV相关工具包也有一些功能上的差异。
1.主要组成部分
- 数据处理工具 torchtext.data.functional、torchtext.data.utils
- 数据集 torchtext.data.datasets
- 词表工具 torchtext.vocab
- 评测指标 torchtext.metrics
2.构建数据集
- Field及其使用
tokenize = lambda x: x.split()
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True, fix_length=200)
LABEL = data.Field(sequential=False, use_vocab=False)
其中:
-
sequential设置数据是否是顺序表示的;
-
tokenize用于设置将字符串标记为顺序实例的函数
-
lower设置是否将字符串全部转为小写;
-
fix_length设置此字段所有实例都将填充到一个固定的长度,方便后续处理;
-
use_vocab设置是否引入Vocab object,如果为False,则需要保证之后输入field中的data都是numerical的
-
词汇表(vocab)
这一步的基本思想是收集一个比较大的语料库(尽量与所做的任务相关),在语料库中使用word2vec之类的方法构建词语到向量(或数字)的映射关系,之后将这一映射关系应用于当前的任务,将句子中的词语转为向量表示。
TEXT.build_vocab(train)
- 数据迭代器(DataLoader)
from torchtext.data import Iterator, BucketIterator
# 若只针对训练集构造迭代器
# train_iter = data.BucketIterator(dataset=train, batch_size=8, shuffle=True, sort_within_batch=False, repeat=False)
# 同时对训练集和验证集进行迭代器的构建
train_iter, val_iter = BucketIterator.splits(
(train, valid), # 构建数据集所需的数据集
batch_sizes=(8, 8),
device=-1, # 如果使用gpu,此处将-1更换为GPU的编号
sort_key=lambda x: len(x.comment_text), # the BucketIterator needs to be told what function it should use to group the data.
sort_within_batch=False
)
test_iter = Iterator(test, batch_size=8, device=-1, sort=False, sort_within_batch=False)
- 使用自带数据集
与torchvision类似,torchtext也提供若干常用的数据集方便快速进行算法测试。可以查看官方文档寻找想要使用的数据集。
3.评测指标
torchtext中可以直接调用torchtext.data.metrics.bleu_score来快速实现BLEU,下面是一个官方文档中的一个例子:
from torchtext.data.metrics import bleu_score
candidate_corpus = [['My', 'full', 'pytorch', 'test'], ['Another', 'Sentence']]
references_corpus = [[['My', 'full', 'pytorch', 'test'], ['Completely', 'Different']], [['No', 'Match']]]
bleu_score(candidate_corpus, references_corpus)
二、Transforms实战
问题描述
在运行代码时,出现了以下问题:
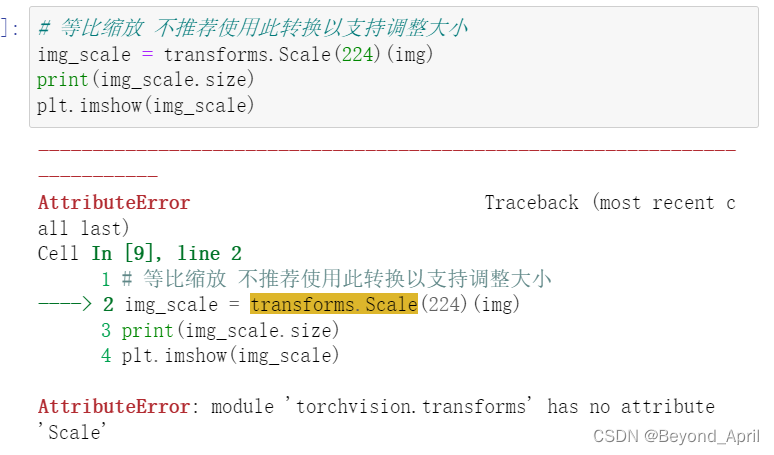
解决办法:
# 等比缩放 不推荐使用此转换以支持调整大小
img_scale = transforms.Resize(224)(img)
print(img_scale.size)
plt.imshow(img_scale)
因为最新版环境中用Resize替代了Scale。
直接上代码(图片结果省略,采用的图片是经典案例lenna)
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
%matplotlib inline
# 加载原始图片
img = Image.open("./lenna.jpg")
print(img.size)
plt.imshow(img)
# 对给定图片进行沿中心切割
# 对图片沿中心放大切割,超出图片大小的部分填0
img_centercrop1 = transforms.CenterCrop((500,500))(img)
print(img_centercrop1.size)
# 对图片沿中心缩小切割,超出期望大小的部分剔除
img_centercrop2 = transforms.CenterCrop((224,224))(img)
print(img_centercrop2.size)
plt.subplot(1,3,1),plt.imshow(img),plt.title("Original")
plt.subplot(1,3,2),plt.imshow(img_centercrop1),plt.title("500 * 500")
plt.subplot(1,3,3),plt.imshow(img_centercrop2),plt.title("224 * 224")
plt.show()
(500, 500)
(224, 224)
# 对图片的亮度,对比度,饱和度,色调进行改变
img_CJ = transforms.ColorJitter(brightness=1,contrast=0.5,saturation=0.5,hue=0.5)(img)
print(img_CJ.size)
plt.imshow(img_CJ)
(512, 512)
img_grey_c3 = transforms.Grayscale(num_output_channels=3)(img)
img_grey_c1 = transforms.Grayscale(num_output_channels=1)(img)
plt.subplot(1,2,1),plt.imshow(img_grey_c3),plt.title("channels=3")
plt.subplot(1,2,2),plt.imshow(img_grey_c1),plt.title("channels=1")
plt.show()
# 等比缩放
img_resize = transforms.Resize(224)(img)
print(img_resize.size)
plt.imshow(img_resize)
(224, 224)
# 等比缩放 不推荐使用此转换以支持调整大小
img_scale = transforms.Resize(224)(img)
print(img_scale.size)
plt.imshow(img_scale)
(224, 224)
# 随机裁剪成指定大小
# 设立随机种子
import torch
torch.manual_seed(31)
# 随机裁剪
img_randowm_crop1 = transforms.RandomCrop(224)(img)
img_randowm_crop2 = transforms.RandomCrop(224)(img)
print(img_randowm_crop1.size)
plt.subplot(1,2,1),plt.imshow(img_randowm_crop1)
plt.subplot(1,2,2),plt.imshow(img_randowm_crop2)
plt.show()
(224, 224)
# 随机左右旋转
# 设立随机种子,可能不旋转
import torch
torch.manual_seed(31)
img_random_H = transforms.RandomHorizontalFlip()(img)
print(img_random_H.size)
plt.imshow(img_random_H)
(512, 512)
# 随机垂直方向旋转
img_random_V = transforms.RandomVerticalFlip()(img)
print(img_random_V.size)
plt.imshow(img_random_V)
(512, 512)
# 随机裁剪成指定大小
img_random_resizecrop = transforms.RandomResizedCrop(224,scale=(0.5,0.5))(img)
print(img_random_resizecrop.size)
plt.imshow(img_random_resizecrop)
(224, 224)
# 对一张图片的操作可能是多种的,我们使用transforms.Compose()将他们组装起来
transformer = transforms.Compose([
transforms.Resize(256),
transforms.transforms.RandomResizedCrop((224), scale = (0.5,1.0)),
transforms.RandomVerticalFlip(),
])
img_transform = transformer(img)
plt.imshow(img_transform)
三、PyTorch的模型部署
ONNX和ONNX Runtime介绍
-
ONNX( Open Neural Network Exchange) 是 Facebook (现Meta)和微软在2017年共同发布的,用于标准描述计算图的一种格式。
-
ONNX通过定义一组与环境和平台无关的标准格式,使AI模型可以在不同框架和环境下交互使用,ONNX可以看作深度学习框架和部署端的桥梁,就像编译器的中间语言一样。
-
目前,在微软,亚马逊 ,Facebook(现Meta) 和 IBM 等公司和众多开源贡献的共同维护下,ONNX 已经对接了下图的多种深度学习框架和多种推理引擎。
-
ONNX Runtime 是由微软维护的一个跨平台机器学习推理加速器,它直接对接ONNX,可以直接读取.onnx文件并实现推理,不需要再把 .onnx 格式的文件转换成其他格式的文件。
-
PyTorch借助ONNX Runtime也完成了部署的最后一公里,构建了 PyTorch --> ONNX --> ONNX Runtime 部署流水线,我们只需要将模型转换为 .onnx 文件,并在 ONNX Runtime 上运行模型即可。
-
安装教程:
# 激活虚拟环境
conda activate env_name # env_name换成环境名称
# 安装onnx
pip install onnx
# 安装onnx runtime
pip install onnxruntime # 使用CPU进行推理
# pip install onnxruntime-gpu # 使用GPU进行推理
模型导出为ONNX
- 调用model.eval()或者model.train(False)
(以确保我们的模型处在推理模式下,避免因为dropout或batchnorm等运算符在推理和训练模式下的不同产生错误。) - 使用torch.onnx.export()把模型转换成 ONNX 格式的函数。
- 通过onnx.checker.check_model()进行检验
实战演示:
import torch.onnx
# 转换的onnx格式的名称,文件后缀需为.onnx
onnx_file_name = "xxxxxx.onnx"
# 我们需要转换的模型,将torch_model设置为自己的模型
model = torch_model
# 加载权重,将model.pth转换为自己的模型权重
# 如果模型的权重是使用多卡训练出来,我们需要去除权重中多的module. 具体操作可以见5.4节
model = model.load_state_dict(torch.load("model.pth"))
# 导出模型前,必须调用model.eval()或者model.train(False)
model.eval()
# dummy_input就是一个输入的实例,仅提供输入shape、type等信息
batch_size = 1 # 随机的取值,当设置dynamic_axes后影响不大
dummy_input = torch.randn(batch_size, 1, 224, 224, requires_grad=True)
# 这组输入对应的模型输出
output = model(dummy_input)
# 导出模型
torch.onnx.export(model, # 模型的名称
dummy_input, # 一组实例化输入
onnx_file_name, # 文件保存路径/名称
export_params=True, # 如果指定为True或默认, 参数也会被导出. 如果你要导出一个没训练过的就设为 False.
opset_version=10, # ONNX 算子集的版本,当前已更新到15
do_constant_folding=True, # 是否执行常量折叠优化
input_names = ['input'], # 输入模型的张量的名称
output_names = ['output'], # 输出模型的张量的名称
# dynamic_axes将batch_size的维度指定为动态,
# 后续进行推理的数据可以与导出的dummy_input的batch_size不同
dynamic_axes={
'input' : {
0 : 'batch_size'},
'output' : {
0 : 'batch_size'}})
import onnx
# 我们可以使用异常处理的方法进行检验
try:
# 当我们的模型不可用时,将会报出异常
onnx.checker.check_model(self.onnx_model)
except onnx.checker.ValidationError as e:
print("The model is invalid: %s"%e)
else:
# 模型可用时,将不会报出异常,并会输出“The model is valid!”
print("The model is valid!")
使用ONNX Runtime进行推理
在上述的步骤中,我们有几个需要注意的点:
- PyTorch模型的输入为tensor,而ONNX的输入为array,因此我们需要对张量进行变换或者直接将数据读取为array格式,我们可以实现下面的方式进行张量到array的转化。
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
- 输入的array的shape应该和我们导出模型的dummy_input的shape相同,如果图片大小不一样,我们应该先进行resize操作。
- run的结果是一个列表,我们需要进行索引操作才能获得array格式的结果。
- 在构建输入的字典时,我们需要注意字典的key应与导出ONNX格式设置的input_name相同,因此我们更建议使用上述的第二种方法构建输入的字典。
以下是推理后的结果:
# 导入onnxruntime
import onnxruntime
# 需要进行推理的onnx模型文件名称
onnx_file_name = "xxxxxx.onnx"
# onnxruntime.InferenceSession用于获取一个 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession(onnx_file_name)
# 构建字典的输入数据,字典的key需要与我们构建onnx模型时的input_names相同
# 输入的input_img 也需要改变为ndarray格式
ort_inputs = {
'input': input_img}
# 我们更建议使用下面这种方法,因为避免了手动输入key
# ort_inputs = {ort_session.get_inputs()[0].name:input_img}
# run是进行模型的推理,第一个参数为输出张量名的列表,一般情况可以设置为None
# 第二个参数为构建的输入值的字典
# 由于返回的结果被列表嵌套,因此我们需要进行[0]的索引
ort_output = ort_session.run(None,ort_inputs)[0]
# output = {ort_session.get_outputs()[0].name}
# ort_output = ort_session.run([output], ort_inputs)[0]
四、参考文档
来自Datawhale的投喂
在线教程链接:
https://datawhalechina.github.io/thorough-pytorch/
Github在线教程:https://github.com/datawhalechina/thorough-pytorch
Gitee在线教程:
https://gitee.com/datawhalechina/thorough-pytorch
b站视频:
https://www.bilibili.com/video/BV1L44y1472Z
(欢迎大家一键三连+关注!)
来自官方的投喂
常见的transforms的API及其使用方法
https://pytorch.org/vision/stable/transforms.html
torchvision.models的官方中文介绍
https://pytorch-cn.readthedocs.io/zh/latest/torchvision/torchvision-models/
torchvision.ops
https://pytorch.org/vision/stable/ops.html
torchviison.utils
https://pytorch.org/vision/stable/utils.html
PyTorchVideo官方介绍
https://github.com/facebookresearch/pytorchvideo/tree/main/tutorials
ONNX官网:
https://onnx.ai/
ONNX GitHub:
https://github.com/onnx/onnx
总结
1.短短14天,对我来说却是在深度学习上迈出了很大的一步,从理论到实战,从教程到写博客,感谢这段时间的坚持。
2.Datawhale的专业性和开源精神的体现让我深受震撼,也同时让我心向往之,希望未来能成为集体的一员。
3.Dennis博士和奇奇同学的并肩前行也是本次学习过程中的重要动力来源,同时其他小伙伴也对我非常重要,有的让我有危机感、有的让我有收获、有的让我感动,
总之,这一步扎实地迈出让我对任重道远的前路有了信心,感谢所有Datawhale小伙伴,特别是领航员邱雯小姐姐和队内的Dennis博士以及奇奇同学。