下载javajdk8并配置好环境
1.下载hadoop并解压
tar -zxf hadoop包名2.进入解压好的hadoop配置目录
cd ./hadoop包名/etc/hadoop3.配置文件<configuration></configuration> 注:除路径配置文件中hadoop为主机名自行修改
core-site.xml
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9868</value>
</property>
mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib-examples/*</value>
</property>yarn-site.xml
<!-- Site specific YARN configuration properties -->
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--每个磁盘的磁盘利用率百分比-->
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>95.0</value>
</property>
<!--集群内存-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<!--调度程序最小值-分配-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<!--比率,具体是啥比率还没查...-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>workers文件填几台主机的主机名 如:
hadoop
hadoop1
hadoop2
hadoop3配置sbin
cd ../../sbin配置start-dfs.sh和stop-dfs.sh 第二行
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root配置start-yarn.sh和stop-yarn.sh 第二行
RN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
YARN_RESOURCEMANAGER_USER=root配置环境变量
vim /etc/profile#hadoop
export HADOOP_HOME=/opt/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin4.关机克隆3台虚拟机
给每台机器改名字
vim /etc/hostname修改所有虚拟机hosts ip地址自己改
vim /etc/hosts
全部关机重启
在主机格式化hadoop 如果把系统克隆给别人删除hadoop包下的dsf和logs文件夹再初始化
hadoop namenode -format5.测试hadoop
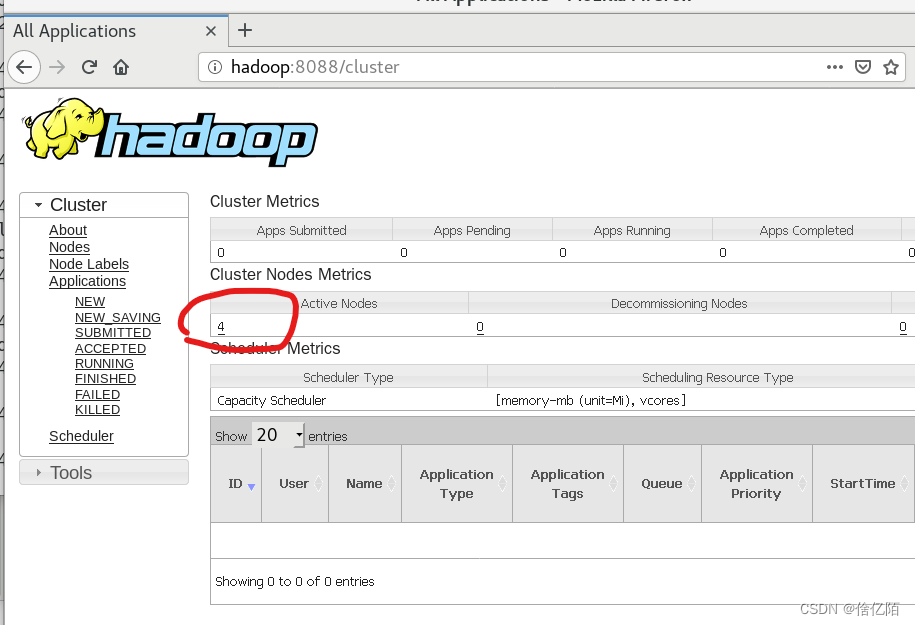
start-all.sh在浏览器
输入 主机名:9870
主机名:8088
看两个网页是否正常,几台电脑几个节点

6.下载hbase包
Apache HBase – Apache HBase Downloads
我选的2.5版本3版本我电脑问题还是hbase优化缺系统表
tar -zxf hbasr包名7.配置hbase
cd ./hbase/confhbase-env.sh 第二行
export JAVA_HOME=/opt/javajdk
# 因为hbase自带的有zk 这里true 是使用 false 是用的外部的
export HBASE_MANAGES_ZK=true
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP=true
hbase-site.xml <configuration></configuration> 注意改主机名目录
<!--开启分布式-->
<!-- HBase数据在HDFS中的存放的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop:8020/hbase</value>
</property>
<!--Hbase的运行模式。false是单机模式,true是分布式模式。
若为false,Hbase和Zookeeper会运行在同一个JVM里面 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<![CDATA[
注释内容(包含其他注释符)
<!-- ZooKeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop,hadoop1,hadoop2,hadoop3</value>
</property>
]]>
<!-- ZooKeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop</value>
</property>
<!-- ZooKeeper快照的存储位置 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hbase/apache-zookeeper-3.6.0-bin/data</value>
</property>
<!-- V2.1版本,在分布式情况下, 设置为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>true</value>
</property>
<!-- acl权限 -->
<property>
<name>hbase.superuser</name>
<value>hadoop</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.rpc.engine</name>
<value>org.apache.hadoop.hbase.ipc.SecureRpcEngine</value>
</property>
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>regionservers改主机名
8.添加hbase环境变量
vim /etc/profile#hbase
export HBASE_HOME=/opt/hbase
export PATH=$HBASE_HOME/bin:$PATH#刷新环境
source /etc/profile9.测试hbase
start-all.sh
start-hbase.sh浏览器输入 主机名:16010