目录
一、事务处理
1.ACID
2.Concurrency Control并发控制
3.Crash Recovery 崩溃恢复保证Durability
二、数据仓库
1.OLPA
2.行式与列式数据库
三、分布式数据库
(本文是中科院陈世敏老师课程学习笔记)
一、事务处理
1.ACID 数据库
事务:与数据库交互,构成一个完整逻辑的一系列操作。需要满足四条性质:
Atomicity 原子性 要么完全执行,要么完全不执行
Consistency 一致性 从一个正确状态出发到另一个正确状态
Isolation 隔离性 每个事务与其他事务互不影响
Durability 持久性 commit之后,结果持久有效,即使crash也
2.并发控制
2.1 正确性
判断一组并行事务是否正确执行:并行执行的结果=某个顺序的串行执行结果,即serializable
2.2数据冲突引起的问题
+Read uncommitted data 读脏数据 (写读) T2 commit之前 T1 读了T2已经修改的数据
+Unrepeatable reads 不可重复读 (读写) T2 commit之前,T1 写了T2 已经读的数据,T2再读一次的会发现数值不同
+Overwrite uncommitted data 更新数据丢失 (写写) T2 commit之前,T1重写了T2已经修改的数据
isolation level事务隔离级别

这有个比较详细的讲解:http://blog.csdn.net/dong976209075/article/details/8802778
+Read uncommitted 是完全不加锁
+Read committed 可以通过加写锁实现,写的时候别人不可以读,所以避免了读脏数据
+Repeatable Read 可以通过加读锁->单变量实现,共享读但读时候不能有人写,所以避免了不可重复读或者脏数据。
+Serialization 读写锁在多变量之间应用,经常设置一个事务管理模块来协调
2.3两大解决方案
(1)悲观 数据冲突严重,可能有冲突的都排队执行,等待前面完全做完。
(2)乐观 数据竞争很少,不直接修改数据,把修改先保留,结束时检查是否有数据竞争。有的话丢弃数据重新计算。
2.4加锁
(1)2 phase locking 对每个需要访问的数据加锁,如果不能加就等待,直到成功 执行事务 commit前集中解锁 commit
2.5 deadlock解决
(1)死锁避免 规定lock对象的顺序,按照顺序请求,适用于lock对象少
(2)死锁检测 lock对象多,周期地对长期等待的事务检查是否有circular wait 如果有,将死锁环上其中一个abort
2.6 乐观并发控制
不加锁,事务执行分成三个阶段:
读-读数据到私有区,在私有区操作
验证-事务决定提交,检查是否与其他有冲突,如果有终止事务清空私有工作区,重试
写-验证通过,私有区写到公有区
一种做法是:snapshot isolation 事务起时点snapshot -> 读snapshot的数据 -> 临时保存,commit有冲突时first writer win 。但是 有些情况下的snapshot isolation不是可线性化的。

3.Durability 实现
3.1 问题
如果commit 时候,才把所有修改写回硬盘,写多个page中间掉电,会破坏原子性。 如果写完硬盘之后才commit,随机写硬盘时候,等待时间长,性能不高。
3.2 transactional logging 日志
记录一个写操作的全部信息,每个写操作都产生一个事务日志记录,commit会产生一个commit日志记录,abort会产生abort日志记录。日志记录会被append到日志文件末尾。 LSN:log sequence number,递增整数,唯一代表一个记录
tld:transaction ID
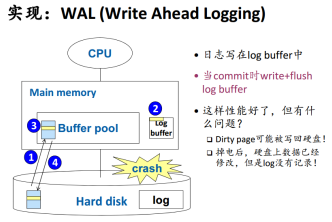
3.3 write-ahead logging
logging总是先于实际操作,记录意向。所以如果能保证日志是durable,我们可以日志中是否有一个事务的commit日志记录。没有的话就需要重做。
日志的durable怎么保证呢?
日志在buffer中也有自己的缓存区,为了避免数据写回了磁盘,但是日志还没有记录的尴尬情况,我们要利用LSN(一个page最新写入的LSN)来确保日志已经flush到硬盘,脏页数据对应操作的LSN‘要迟缓于日志更新的LSN。
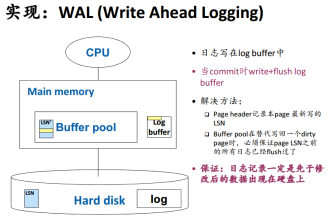
3.4 log truncation
log file不能无限长,找到缓存中尚未写回的脏页的最小LSN,该LSN之前的日志都可以删除了,因为数据已经写到硬盘, transacntion完成。
3.5 checkpoint 检查点
为了使崩溃恢复的时间可控,不需要读整个日志,要定期执行检查点。checkpoint包含一下内容:
+当前活动的事务表:事务的最新日志LSN
+当前脏页表:每个page尚未写回的最早值LSN

3.6 Crash recovery
(1)~(3)是ARIES算法:
(1)分析阶段
找到最后一个检查点->找到日志崩溃点(如果日志是循环写,检查校验码,找出LSN变小的位置)->确定崩溃时的活跃事务和脏页,从最后一个检查点开始正向扫描,遇到commit,begin等更新,记录脏页LSN。
(2)Redo-恢复系统到崩溃前瞬间状态
找到脏页最早LSN(之前的已经存盘成功),从这个LSN开始正向读日志,Redo每个修改。对每个记录来说:
+涉及的页不在脏页里(可能已经写入硬盘),跳过
+数据页的LSN>=日志的LSN(存入硬盘的数据页已经包含了这个修改),跳过
+其他情况,修改数据页
(3)Undo清除未提交的事务的修改
对于所有在崩溃时活跃的事务,找出该事务最新LSN,通过反向链表读这个事务的所有日志记录。undo所有未提交事务的修改(数据页LSN>=日志LSN,才进行undo)。
(4)介质故障恢复
二、数据仓库
1、 数据仓库:面向分析,数据可不具有实时性,不像数据库一样有很多操作,主要是读,数据量大。
2、 OLPA(online analytical processing)联机分析处理:在数据仓库基础上实现。
3、 数据立方体操作:
(1)Rollup 细粒度到粗粒度,如某一维度求和
(2)drill down 反之,分解
(3)slice 切片 取某一维度
(4)dice 切块 多维选值
4、行/列存储
行

列
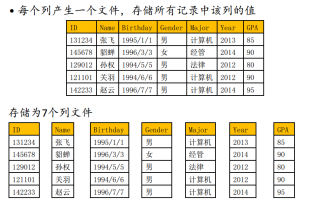
列式存储适合于涉及少数几个行,这种情况行式存储会有很多无用数据,而且列存储更容易压缩。缺点是拼装需要代价,两个解决思路:
+数据行列各存一份
三、分布式数据库
1.系统机构
(1)shared memory
多核多芯片。
(2)shared disk
多台机器相同的数据存储设备。
(3)shared nothing
因特网通信。

关键技术:
+partitioning 划分
把数据分不到不用服务器上,常horizontal partitioning,hash函数,使得各个机器区间不重合。
+Replication 备份
2.查询处理
(1)有些查询操作如filter和projection可以并行执行
(2)join 如果partition key就是join key可以并行执行,类似GRACE.不是时候,在join key上进行分布式partition,使同一个划分放在 同一个机器上,需要大量数据传输。过滤掉没有匹配对象的记录,不发送可以减小开销,做法是把S.a发送到R所在的机器,要join的R.b没 有匹配记录的过滤掉。
3.事务处理
3.1处理2 Phase Commit流程
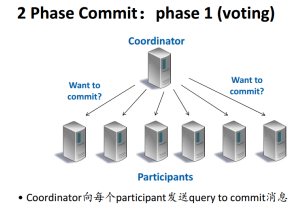
C->P 发送query to commit
P ->C P根据自己情况回答
C等到所有yes回答,发送commit,至少一个no事务将abort
P向C回复ack
3.2崩溃恢复
分布式数据库如果崩溃了,恢复日志可能出现的情况:
+有commit或者abort记录:事务处理结果已经收到,进行相应本地commit或abort
+有prepare,而没有commit或者abort:结果未知,需要和coordinator联系
+没有prepare/commit/abort:本地abort