目录
参考链接:
(1)Mask R-CNN网络详解_fcn太阳花的小绿豆_太阳花的小绿豆的博客-CSDN博客
(2)Mask R-CNN详解_mask rcnn_技术挖掘者的博客-CSDN博客
视频讲解:Mask R-CNN网络详解_哔哩哔哩_bilibili
论文地址:https://arxiv.org/abs/1703.06870
2.1 前言
Mask R-CNN是何恺明大神于2017年发表的文章,该论文也获得了ICCV 2017的最佳论文奖(Marr Prize)。Mask R-CNN是一个非常灵活的框架,可以增加不同的分支完成不同的任务,可以完成目标分类、目标检测、语义分割、实例分割、人体姿势识别等多种任务 。
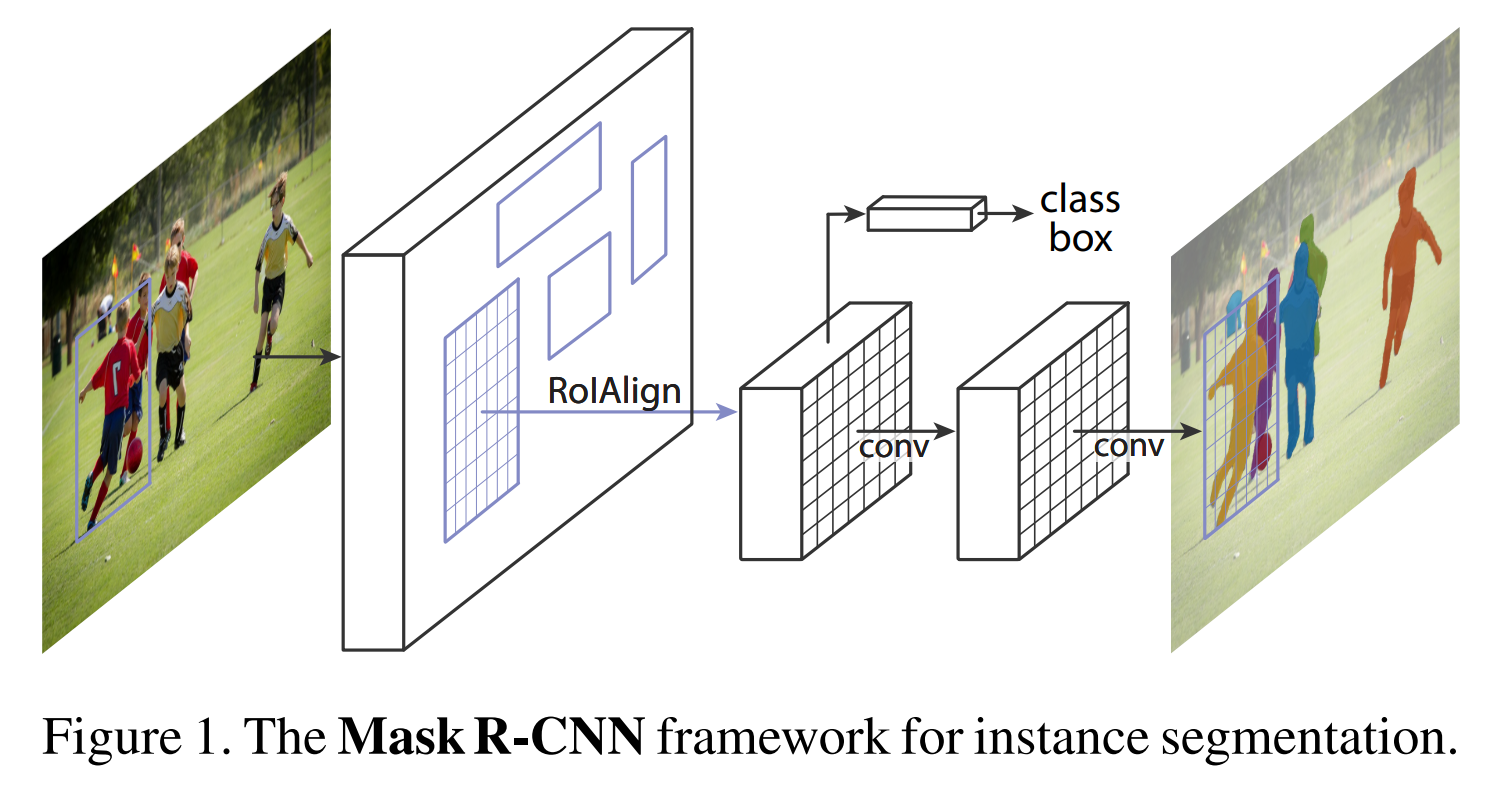
Mask R-CNN是在Faster R-CNN的基础上加了一个用于预测目标分割Mask的分支(即可预测目标的Bounding Boxes信息、类别信息,也可以预测分割Mask信息)。

Mask R-CNN不仅能够同时进行目标检测与分割,还能很容易地扩展到其他任务,比如再同时预测人体关键点信息。

2.2 Mask R-CNN优点
高速和高准确率:为了实现这个目的,作者选用了经典的目标检测算法Faster-rcnn和经典的语义分割算法FCN。Faster-rcnn可以既快又准的完成目标检测的功能;FCN可以精准的完成语义分割的功能,这两个算法都是对应领域中的经典之作。Mask R-CNN比Faster-rcnn复杂,但是最终仍然可以达到5fps的速度,这和原始的Faster-rcnn的速度相当。由于发现了ROI Pooling中所存在的像素偏差问题,提出了对应的ROIAlign策略,加上FCN精准的像素MASK,使得其可以获得高准确率。
简单直观:整个Mask R-CNN算法的思路很简单,就是在原始Faster-rcnn算法的基础上面增加了FCN来产生对应的MASK分支。即Faster-rcnn + FCN,更细致的是 RPN + ROIAlign + Fast-rcnn + FCN。
易于使用:整个Mask R-CNN算法非常的灵活,可以用来完成多种任务,包括目标分类、目标检测、语义分割、实例分割、人体姿态识别等多个任务,这将其易于使用的特点展现的淋漓尽致。我很少见到有哪个算法有这么好的扩展性和易用性,值得我们学习和借鉴。除此之外,我们可以更换不同的backbone architecture和Head Architecture来获得不同性能的结果。
2.3 Mask R-CNN框架解析
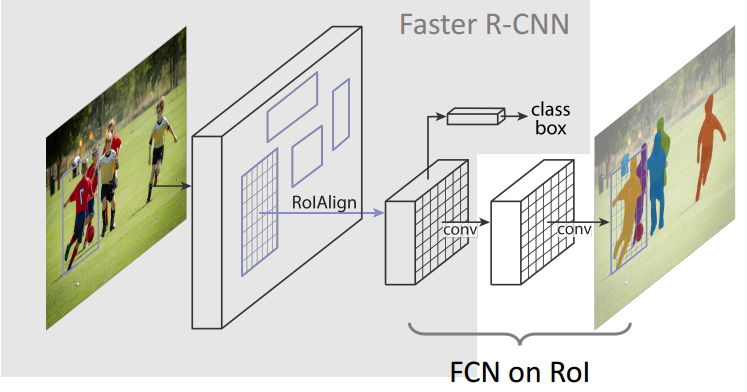
Mask R-CNN算法框架
(1) Mask R-CNN算法步骤
- 首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
- 然后,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
- 接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
- 接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
- 接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
- 最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。
Mask R-CNN的结构也很简单,就是在通过RoIAlign(在原Faster R-CNN中是RoIPool)得到的RoI基础上并行添加一个Mask分支(小型的FCN)。见下图,之前Faster R-CNN是在RoI基础上接上一个Fast R-CNN检测头,即图中class, box分支,现在又并行了一个Mask分支。

注意带和不带FPN结构的Mask R-CNN在Mask分支上略有不同,对于带有FPN结构的Mask R-CNN它的class、box分支和Mask分支并不是共用一个RoIAlign。在训练过程中,对于class, box分支RoIAlign将RPN(Region Proposal Network)得到的Proposals池化到7x7大小,而对于Mask分支RoIAlign将Proposals池化到14x14大小。.
在这里,我将Mask R-CNN分解为如下的3个模块,Faster-rcnn、ROIAlign和FCN。然后分别对这3个模块进行讲解,这也是该算法的核心。
(2) Faster-R-CNN
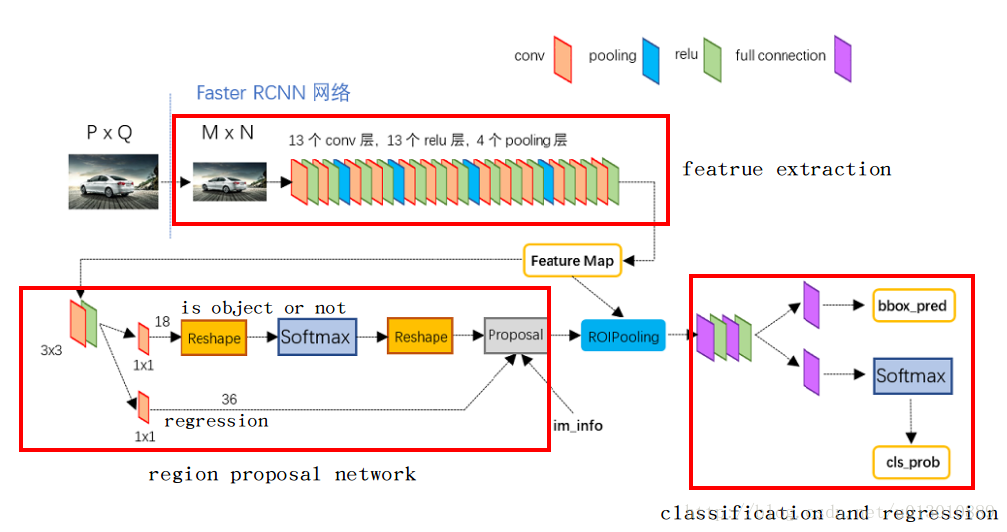
Faster-rcnn主要包括4个关键模块,特征提取网络、生成ROI、ROI分类、ROI回归。
- 特征提取网络:它用来从大量的图片中提取出一些不同目标的重要特征,通常由conv+relu+pool层构成,常用一些预训练好的网络(VGG、Inception、Resnet等),获得的结果叫做特征图;
- 生成ROI:在获得的特征图的每一个点上做多个候选ROI(这里是9),然后利用分类器将这些ROI区分为背景和前景,同时利用回归器对这些ROI的位置进行初步的调整;
- ROI分类:在RPN阶段,用来区分前景(于真实目标重叠并且其重叠区域大于0.5)和背景(不与任何目标重叠或者其重叠区域小于0.1);在Fast-rcnn阶段,用于区分不同种类的目标(猫、狗、人等);
- ROI回归:在RPN阶段,进行初步调整;在Fast-rcnn阶段进行精确调整;
其整体流程如下所示:
- 首先对输入的图片进行裁剪操作,并将裁剪后的图片送入预训练好的分类网络中获取该图像对应的特征图;
- 然后在特征图上的每一个锚点上取9个候选的ROI(3个不同尺度,3个不同长宽比),并根据相应的比例将其映射到原始图像中(因为特征提取网络一般有conv和pool组成,但是只有pool会改变特征图的大小,因此最终的特征图大小和pool的个数相关);
- 接着将这些候选的ROI输入到RPN网络中,RPN网络对这些ROI进行分类(即确定这些ROI是前景还是背景)同时对其进行初步回归(即计算这些前景ROI与真实目标之间的BB的偏差值,包括Δx、Δy、Δw、Δh),然后做NMS(非极大值抑制,即根据分类的得分对这些ROI进行排序,然后选择其中的前N个ROI);
- 接着对这些不同大小的ROI进行ROI Pooling操作(即将其映射为特定大小的feature_map,文中是7x7),输出固定大小的feature_map;
- 最后将其输入简单的检测网络中,然后利用1x1的卷积进行分类(区分不同的类别,N+1类,多余的一类是背景,用于删除不准确的ROI),同时进行BB回归(精确的调整预测的ROI和GT的ROI之间的偏差值),从而输出一个BB集合。
(3) FCN
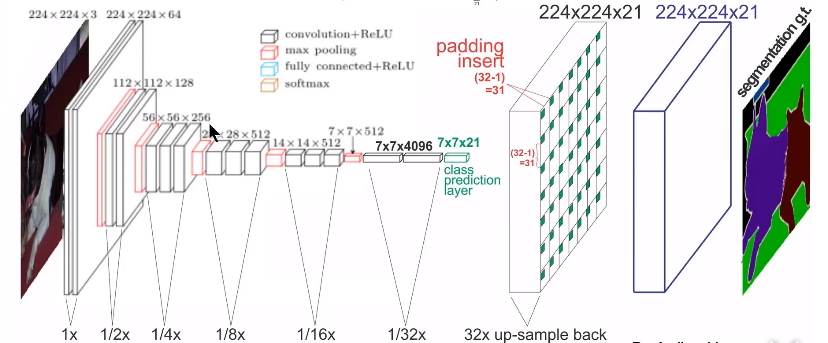
FCN网络架构
FCN算法是一个经典的语义分割算法,可以对图片中的目标进行准确的分割。其总体架构如上图所示,它是一个端到端的网络,主要的模快包括卷积和去卷积,即先对图像进行卷积和池化,使其feature map的大小不断减小;然后进行反卷积操作,即进行插值操作,不断的增大其feature map,最后对每一个像素值进行分类。从而实现对输入图像的准确分割。
(4) ROIPooling和ROIAlign的分析与比较
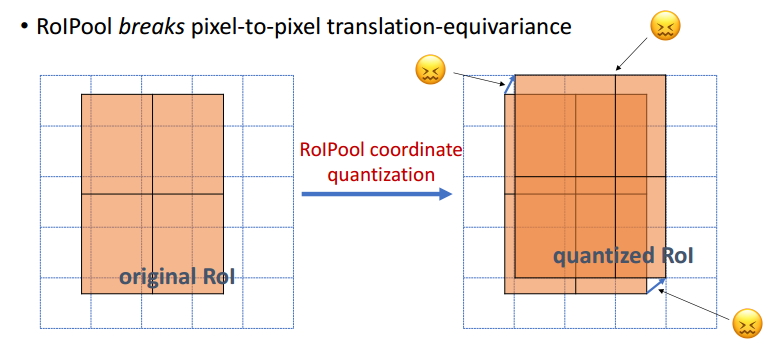
ROI Pooling和ROIAlign对比
ROI Pooling和ROIAlign最大的区别是:前者使用了两次量化操作,而后者并没有采用量化操作,使用了线性插值算法,如上图所示。
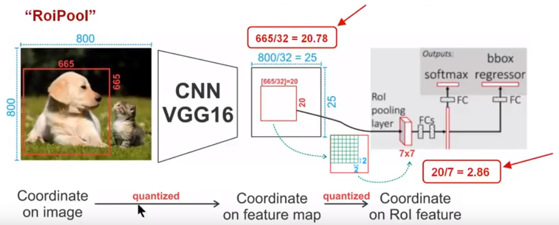
ROI Pooling技术
如上图所示,为了得到固定大小(7X7)的feature map,我们需要做两次量化操作:
- 图像坐标 — feature map坐标,
- feature map坐标 — ROI feature坐标。
我们来说一下具体的细节,如图我们输入的是一张800x800的图像,在图像中有两个目标(猫和狗)
第一次的量化误差:狗的大小为665x665,经过VGG16网络后,我们可以获得对应的feature map,如果我们对卷积层进行Padding操作,我们的图片经过卷积层后保持原来的大小,但是由于池化层的存在,我们最终获得feature map 会比原图缩小一定的比例,这和Pooling层的个数和大小有关。在该VGG16中,我们使用了5个池化操作,每个池化操作都是2Pooling,因此我们最终获得feature map的大小为800/32 x 800/32 = 25x25(是整数),但是将狗对应到feature map上面,我们得到的结果是665/32 x 665/32 = 20.78 x 20.78,结果是浮点数,含有小数,但是我们的像素值可没有小数,那么作者就对其进行了量化操作(即取整操作),即其结果变为20 x 20。;
第二次量化误差:然而我们的feature map中有不同大小的ROI,但是我们后面的网络却要求我们有固定的输入,因此,我们需要将不同大小的ROI转化为固定的ROI feature,在这里使用的是7x7的ROI feature,那么我们需要将20 x 20的ROI映射成7 x 7的ROI feature,其结果是 20 /7 x 20/7 = 2.86 x 2.86,同样是浮点数,含有小数点,我们采取同样的操作对其进行取整。
其实,这里引入的误差会导致图像中的像素和特征中的像素的偏差,即将feature空间的ROI对应到原图上面会出现很大的偏差。原因如下:比如用我们第二次引入的误差来分析,本来是2,86,我们将其量化为2,这期间引入了0.86的误差,看起来是一个很小的误差呀,但是你要记得这是在feature空间,我们的feature空间和图像空间是有比例关系的,在这里是1:32,那么对应到原图上面的差距就是0.86 x 32 = 27.52。这个差距不小吧,这还是仅仅考虑了第二次的量化误差。这会大大影响整个检测算法的性能,因此是一个严重的问题。
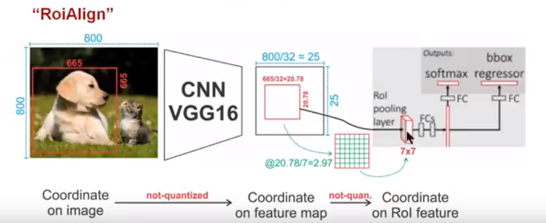
ROIAlign技术
如上图所示,为了得到为了得到固定大小(7X7)的feature map,ROIAlign技术并没有使用量化操作,即我们不想引入量化误差,比如665 / 32 = 20.78,我们就用20.78,不用什么20来替代它,比如20.78 / 7 = 2.97,我们就用2.97,而不用2来代替它。这就是ROIAlign的初衷。那么我们如何处理这些浮点数呢,我们的解决思路是使用“双线性插值”算法。
双线性插值是一种比较好的图像缩放算法,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。

双线性插值示意图
如上图所示,蓝色的虚线框表示卷积后获得的feature map,黑色实线框表示ROI feature,最后需要输出的大小是2x2,那么我们就利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,最后得到相应的输出。这些蓝点是2x2Cell中的随机采样的普通点,作者指出,这些采样点的个数和位置不会对性能产生很大的影响,你也可以用其它的方法获得。然后在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。我们的整个过程中没有用到量化操作,没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。
(5) Mask R-CNN损失
Mask R-CNN的损失就是在Faster R-CNN的基础上加上了Mask分支上的损失,即:

关于Mask R-CNN的源码解析请参考其他博文