简介
本文首先解释了NoSQL的出现的原因,介绍了NoSQL数据库所依据的理论和原则。然后分别介绍了四种NoSQL数据库的类型,以及其代表产品。并讨论了这四种类型的NoSQL的特点以及适用场景。
需要NoSQL的理由
NoSQL数据库,看起来是不支持SQL查询语句,其实是"Not only SQL",强调了它支持类似于SQL的查询语言。在它背后有一系列有趣的故事。
一般来说,扩展一个系统有两种方法:scale out和scale up。
Scale out也称horizontal scale(横向扩展),是指增加计算节点(简单地理解就是服务器)以提高系统的处理能力。
Scale up也称vertical scale(纵向扩展),是指提高单个计算节点(服务器)的性能以提高系统的处理能力。
Scale up存在一个问题,就是越往上扩展,花费越多,得到的性能提升越小。更重要的是,对于互联网之类的应用,一台超级服务器是不够的。想想Google、Facebook、Twitter、新浪微博、QQ,这样的互联网应用需要部署分布各处的服务器,并要处理大量的海量数据,同时处理来自世界各地的大量的网络请求,并且保证7x24的有效性。这样一台服务器是做不到的。
因此,在包括互联网应用在内的很多情况下,横向扩展的技术是不可代替的。关于数据库的横向扩展,产生了诸如X/Open XA规范、Oracle RAC这样的集群技术,这些技术努力保证关系型数据库的ACID特性。但是人们发现在分布式系统中,尤其是在分布在不同的地理位置的系统中,保证ACID特性非常困难,这样满足不了需求,尤其是对于互联网应用来说。因此就有人想能不能有第二条路。
理论与原则
这第二条路就是NoSQL。
NoSQL数据库不是关系型数据库,它采用的是比关系型数据库更为松散的一致性模型。它具有设计的简洁性、横向可伸缩性以及更好地控制可用性。通常,NoSQL数据库是基于键-值存储,不支持join操作。
在NoSQL中,有一个很重要的支持理论CAP:
C - Consistency 一致性
A - Availability 可用性
P - Partition tolerance 分区容忍
CAP理论用一个简单而不太严谨的说法就是“三选二"理论,即C、A和P三者不能同时满足。既然鱼与熊掌不可兼得,那么只能根据实际要求适当牺牲掉其中的一项。对于像Google,FaceBook这样的Web应用系统来说,数据的可用性和分布式存储是需要优先考虑的。实现了分布式存储才能保证分区容忍。为了保证A和P,即可用性和分区容忍,相对于ACID,人们推出了BASE原则。
BASE就是“Basically Available, Soft state, Eventually consistent(基本可用、软状态、最终一致性)”的首字母缩写。NoSQL满足的是BASE原则。它不保证任何时候的一致性,而是保证了最终一致性。
NoSQL数据库的类型,代表产品,以及适用场景和实际案例
- 键值(Key-Value)数据库
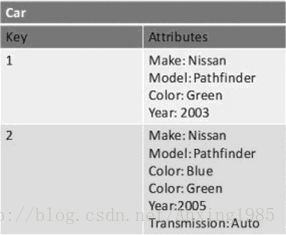 一句话解释:超级大的hash表
一句话解释:超级大的hash表
注:这张hash表很可能分布在多个服务器上,内容有很多很多很多...
代表产品:Redis, MemcacheDB, Riak
适用场景:储存用户信息,比如会话、配置文件、参数、购物车等等。这些信息一般都和ID(键)挂钩,这种情景下键值数据库是个很好的选择。
实际案例:
- GitHub (Riak)
- Twitter (Redis和Memcached)
- StackOverFlow (Redis)
- 面向文档(Document-Oriented)数据库
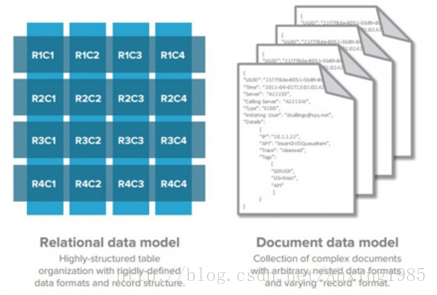 一句话解释: Value是文档
一句话解释: Value是文档
注:Value可以是文档的键值(Key-Value)数据库,而且文档又可以是一个Hash表,Hash表的value又是文档。 ( 文档套文档)文档由XML、JSON或者BSON(binary JSON)等多种形式存储。
代表产品:MongoDB, CouchDB, RavenDB, Terrastore
适用场景:
-
- 日志。企业环境下,每个应用程序都有不同的日志信息。Document-Oriented数据库并没有固定的模式,所以我们可以使用它储存不同的信息。
- 分析。鉴于它的弱模式结构,不改变模式下就可以储存不同的度量方法及添加新的度量。
实际案例:
- SAP (MongoDB)
- Codecademy (MongoDB)
- Foursquare (MongoDB)
![]()
- 列存储(Wide Column Store/Column-Family)数据库
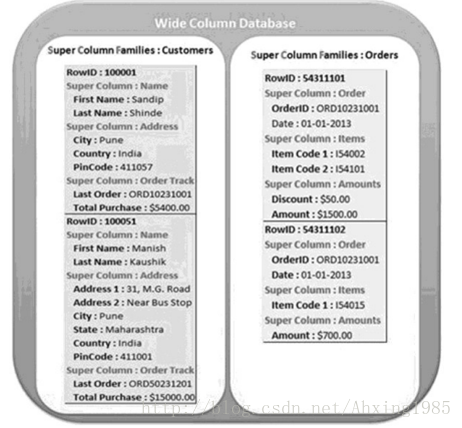 一句话解释:很像SQL的NoSQL。
一句话解释:很像SQL的NoSQL。
注:列存储数据库将数据储存在列族(column family)中,一个列族存储经常被一起查询的相关数据。举个例子,如果我们有一个Person类,我们通常会一起查询他们的姓名和年龄而不是薪资。这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中。
代表产品:BigTable, Hbase, Cassandra, Simple DB
适用场景:
- 日志
因为我们可以将数据储存在不同的列中,每个应用程序可以将信息写入自己的列族中。- 搜索引擎
- 博客平台
我们储存每个信息到不同的列族中。举个例子,标签可以储存在一个,类别可以在一个,而文章则在另一个。
实际案例:
- Ebay (Cassandra, HBase)
- Instagram (Cassandra)
- Facebook (HBase)
![]()
- 图(Graph-Oriented)数据库
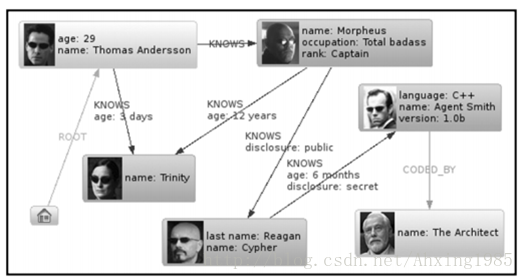 一句话解释:顶点加边的图结构
一句话解释:顶点加边的图结构
注:顶点是实体数据,边是数据之间的联系,支持图的操作和算法。比如我们有三个实体,Steve Jobs、Apple和Next,则会有两个“Founded by”的边将Apple和Next连接到Steve Jobs。
代表产品:Neo4j, InfoGrid, BigData
适用场景:
- 在一些关系性强的数据中
- 推荐引擎
如果我们将数据以图的形式表现,那么将会非常有益于推荐的制定实际案例:
- Adobe (Neo4J)
- Cisco (Neo4J)
- T-Mobile (Neo4J)
用一张有意思的图来加深印象。
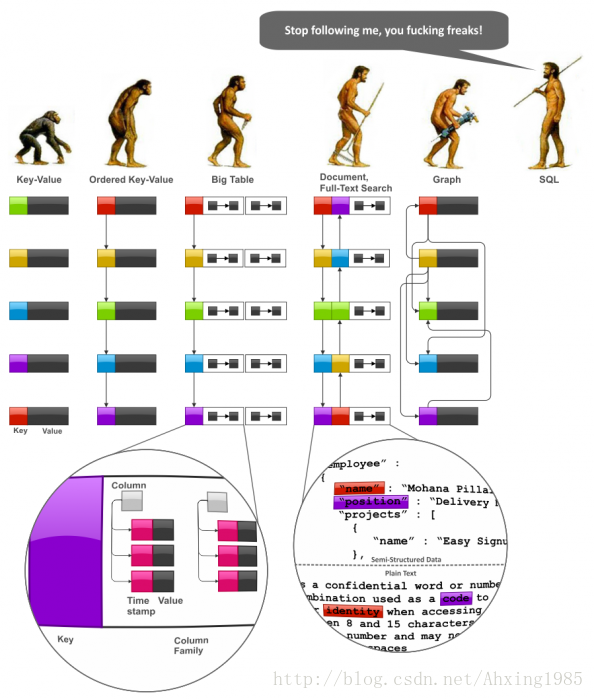
参考: