一、GBDT算法流程:

二、预测身高
已知四组包含年龄、体重、身高的数据,根据年龄、体重预测身高。

测试数据如下:

1、训练阶段:
参数设置:学习率:learning_rate=0.1,迭代次数:n_tree=5,树的深度:max_depth=2(max_depth=3的计算方式一样)。
(1)初始学习器
由于损失函数为平方损失,所以取训练样本标签值的均值=(1.1+1.3+1.7+1.8)/ 4=1.475。
即有。
学习器可以理解为当前模型的预测结果。此处之所以取均值是公式推导得到的。即初始学习器将f_0将所有样本都预测为1.475,误差很大,需要调整。
(2)对迭代轮数m=1,2,...M 。
1)计算负梯度,也就是残差,由于损失函数为平方损失,所以负梯度即残差=标签值-预测值,表格中为label-f_m(x)或res_m-0.1*γ的值。
2)将上述获得的残差作为标签值训练下一颗树。
3)获取每个叶子节点的预测值γ,去拟合残差,本例中的γ计算方式为:叶子包含样本标签值的均值。
3)更新学习器,对每个样本更新学习器。
实际应用场景中:
在残差作为目标值训练树之前,需要寻找回归树的最佳划分点。
方法:遍历每个特征的每个可能取值。从年龄特征的5开始,到体重特征的70结束,分别计算分裂后两组数据的平方损失,左节点平方损失为 ,右节点平方损失为
。找到使平方损失和
最小的那个划分节点,即为最佳划分节点。
例如以age=7为例:SEsum=0+0.140=0.140 遍历特征和体重后所有的划分情况如下表格:
遍历特征和体重后所有的划分情况如下表格:
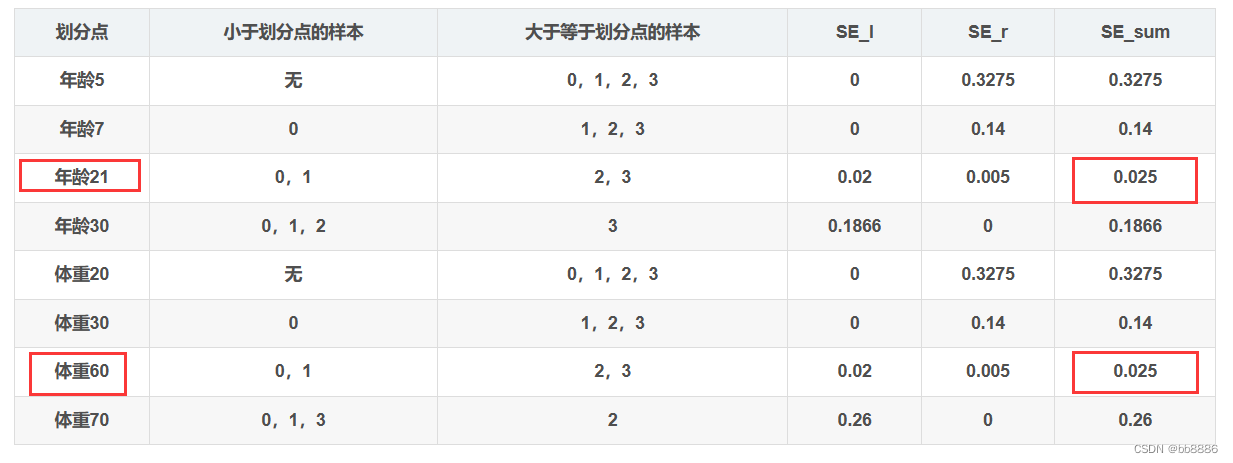
随便选取年龄21或体重60来作为划分点。划分点找到后,进入正题:
步骤一和二:计算残差(res_1 = label – f_0)作为标签值训练第一棵树。
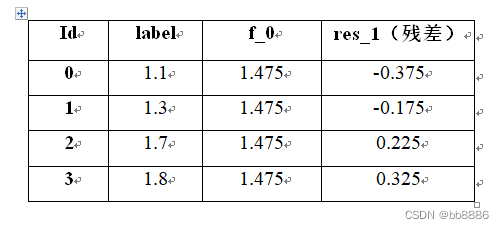
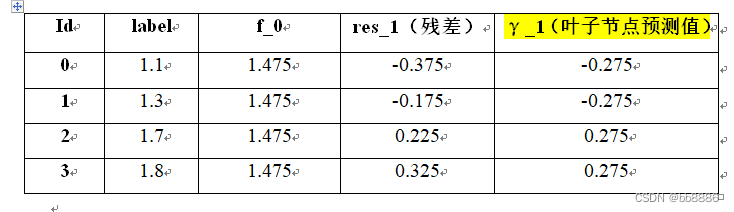
步骤三:计算每个叶子节点的预测值γ(叶子包含样本标签值的均值(-0.375-0.175)/2 = -0.275)。
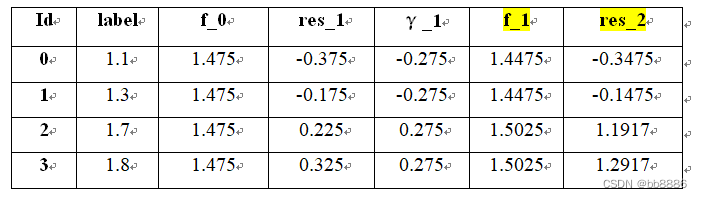
 步骤四:更新学习器(f_1 = f_0+0.1*γ)并计算构建残差(res2 = res1-0.1*γ)作为标签值训练第二棵树。
步骤四:更新学习器(f_1 = f_0+0.1*γ)并计算构建残差(res2 = res1-0.1*γ)作为标签值训练第二棵树。
 循环步骤1~4
循环步骤1~4
第三棵树:
 第四棵树:
第四棵树:

第五棵树:

得到最终的学习器

2、测试阶段
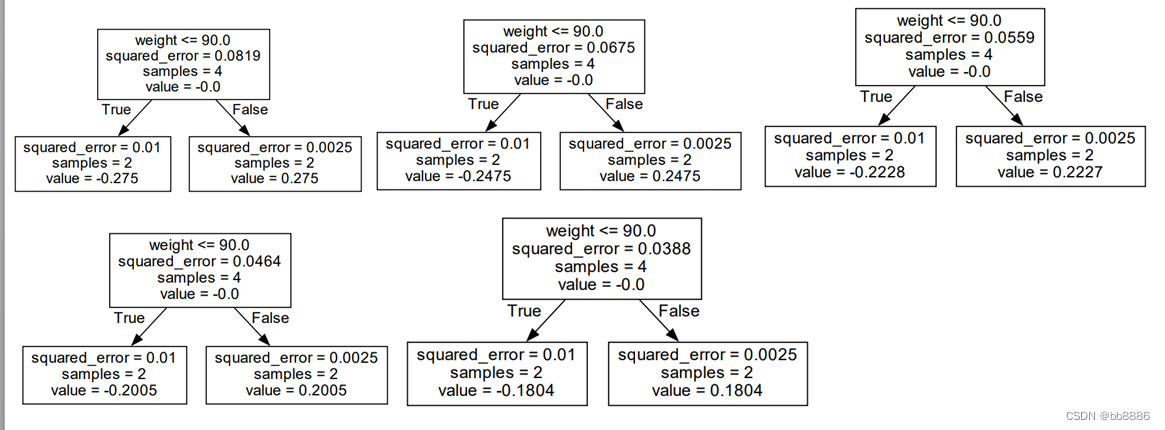
由上面最后一个表格,根据测试数据age=25,weight=65,找到id为2对应的f_5值,为1.5876。
具体地,在f_0中,预测为1.475.
在f_1中,age>21, 叶子节点预测为0.275.
在f_2中,age>21, 叶子节点预测为0.2475.
在f_3中,age>21, 叶子节点预测为0.2227.
在f_4中,age>21, 叶子节点预测为0.2005.
在f_5中,age>21, 叶子节点预测为0.1805.
有公式: 预测值 = 1.475 + 0.1 * (0.275+0.2475+0.2227+0.2005+0.1805) = 1.5876.
3、代码实现并可视化
(1)用DecisionTreeRegressor一步一步实现。
import graphviz
import numpy as np
import pandas as pd
from sklearn import tree
from pydotplus import graph_from_dot_data
from sklearn.tree import DecisionTreeRegressor, export_graphviz
from sklearn.ensemble import GradientBoostingRegressor
data_1 = [[5, 40, 1.1],
[7, 60, 1.3],
[21, 140, 1.7],
[30, 120, 1.8]]
data = pd.DataFrame(data_1, columns=['age', 'weight', '标签'])
X = np.array(data.iloc[:, :-1]).reshape((-1, 2))
y = np.array(data.iloc[:, -1]).reshape((-1, 1))
tree_reg = DecisionTreeRegressor(max_depth=1, random_state=14)
tree_reg.fit(X, y)
# 残差y1作为标签值训练第1棵树
y1 = y - np.array([1.475] * 4).reshape((-1, 1))
tree_reg1 = DecisionTreeRegressor(max_depth=1, random_state=14)
tree_reg1.fit(X, y1)
# 残差y2作为标签值训练第2棵树
y2 = y1 - 0.1 * np.array(tree_reg1.predict(X)).reshape((-1, 1))
tree_reg2 = DecisionTreeRegressor(max_depth=1, random_state=14)
tree_reg2.fit(X, y2)
# 残差y3作为标签值训练第3棵树
y3 = y2 - 0.1 * np.array(tree_reg2.predict(X)).reshape((-1,1))
tree_reg3 = DecisionTreeRegressor(max_depth=1, random_state=14)
tree_reg3.fit(X, y3)
# 残差y4作为标签值训练第4棵树
y4 = y3 - 0.1 * np.array(tree_reg3.predict(X)).reshape((-1,1))
tree_reg4 = DecisionTreeRegressor(max_depth=1, random_state=14)
tree_reg4.fit(X, y4)
# 残差y5作为标签值训练第5棵树
y5 = y4 - 0.1 * np.array(tree_reg4.predict(X)).reshape((-1,1))
tree_reg5 = DecisionTreeRegressor(max_depth=1, random_state=14)
tree_reg5.fit(X, y5)
list = [tree_reg1, tree_reg2, tree_reg3, tree_reg4, tree_reg5]
# DecisionTreeRegressor可视化
for i in range(0, 5):
nodes = export_graphviz(list[i], feature_names=["age","weight"], precision=4)
gra = graphviz.Source(nodes)
gra.render(r"./plot/tree{0}".format(i+1))
(2)用sklearn包的GradientBoostingRegressorGBDT算法包。
estimator = GradientBoostingRegressor(max_depth=1, random_state=14)
estimator.fit(data.iloc[:, :-1], data.iloc[:, -1])
# 可视化
for i in range(5):
# estimator.estimators_[i, 0],代表第i棵树
dot_data = export_graphviz(estimator.estimators_[i, 0], feature_names=["age", "weight"], out_file=None, filled=True, rounded=True, special_characters=True, precision=4)
graph = graph_from_dot_data(dot_data)
graph.write_pdf('./plot/estimator{0}.pdf'.format(i))